Kylin 初入门 | 从下载安装到体验查询
本文旨在为 Kylin 新手用户提供一份从下载安装到体验亚秒级查询的完整流程。文章分为两个部分,分别介绍了有 Hadoop 环境(基于 Hadoop 环境的安装)和没有 Hadoop 环境(从 Docker 镜像安装)两种场景下 Kylin的安装使用,用户可以根据自己的环境选择其中的任意一种方式。
用户可以按照文章里的步骤对 Kylin 进行初步的了解和体验,掌握 Kylin 的基本使用技能,然后结合自己的业务场景使用 Kylin 来设计模型,加速查询。
01 从 Docker 镜像安装使用 Kylin
为了让用户方便地试用 Kylin,蚂蚁金服的朱卫斌同学向社区贡献了「Kylin Docker Image」。该镜像中,Kylin 依赖的各个服务均已正确的安装及部署,包括:
- Jdk 1.8
- Hadoop 2.7.0
- Hive 1.2.1
- Hbase 1.1.2
- Spark 2.3.1
- Zookeeper 3.4.6
- Kafka 1.1.1
- Mysql
- Maven 3.6.1
我们已将面向用户的 Kylin 镜像上传至 Docker 仓库,用户无需在本地构建镜像,只需要安装 Docker,就可以体验 Kylin 的一键安装。
Step 1.
首先执行以下命令从 Docker 仓库 pull 镜像:
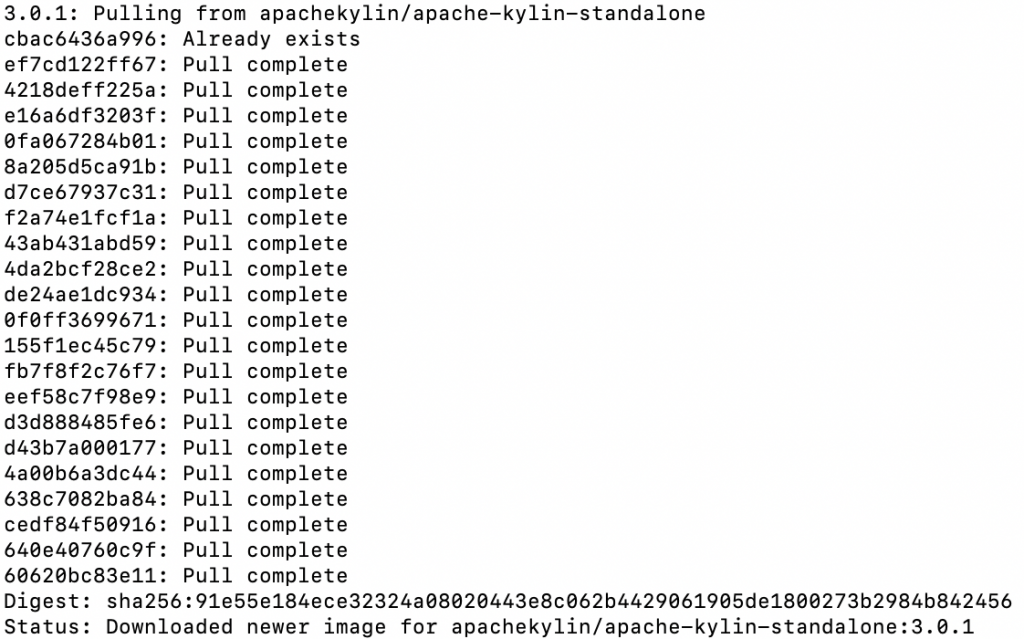
docker pull apachekylin/apache-kylin-standalone:3.0.1
此处的镜像包含的是 Kylin 最新版本 Kylin v3.0.1。由于该镜像中包含了所有 Kylin 依赖的大数据组件,所以拉取镜像需要的时间较长,请耐心等待。Pull 成功后显示如下:
Step 2.执行以下命令来启动容器:
docker run -d \
-m 8G \
-p 7070:7070 \
-p 8088:8088 \
-p 50070:50070 \
-p 8032:8032 \
-p 8042:8042 \
-p 16010:16010 \
apachekylin/apache-kylin-standalone:3.0.1
容器会很快启动,由于容器内指定端口已经映射到本机端口,可以直接在本机浏览器中打开各个服务的页面,如:
- Kylin 页面:http://127.0.0.1:7070/kylin/
- Hdfs NameNode 页面:http://127.0.0.1:50070
- Yarn ResourceManager 页面:http://127.0.0.1:8088
- HBase 页面:http://127.0.0.1:60010
容器启动时,会自动启动以下服务:
- NameNode, DataNode
- ResourceManager, NodeManager
- HBase
- Kafka
- Kylin
并自动运行 $KYLIN_HOME/bin/sample.sh 及在 Kafka 中创建 kylin_streaming_topic topic 并持续向该 topic 中发送数据。这是为了让用户启动容器后,就能体验以批和流的方式的方式构建 Cube 并进行查询。用户可以通过 docker exec 命令进入容器,容器内相关环境变量如下:
- JAVA_HOME=/home/admin/jdk1.8.0_141
- HADOOP_HOME=/home/admin/hadoop-2.7.0
- KAFKA_HOME=/home/admin/kafka_2.11-1.1.1
- SPARK_HOME=/home/admin/spark-2.3.1-bin-hadoop2.6
- HBASE_HOME=/home/admin/hbase-1.1.2
- HIVE_HOME=/home/admin/apache-hive-1.2.1-bin
- KYLIN_HOME=/home/admin/apache-kylin-3.0.0-alpha2-bin-hbase1x
登陆 Kylin 后,用户可以使用 sample cube 来体验 cube 的构建和查询,也可以按照下面“基于 Hadoop 环境安装使用 Kylin ”中从 Step 8 之后的教程来创建并查询属于自己的 model 和 cube。
02 基于 Hadoop 环境安装使用 Kylin
对于已经有稳定 Hadoop 环境的用户,可以下载 Kylin 的二进制包将其部署安装在自己的 Hadoop 集群。安装之前请根据以下要求进行环境检查。
环境检查
(1)前置条件:
Kylin 依赖于 Hadoop 集群处理大量的数据集。你需要准备一个配置好 HDFS,YARN,MapReduce,Hive, HBase,Zookeeper 和其他服务的 Hadoop 集群供 Kylin 运行。
Kylin 可以在 Hadoop 集群的任意节点上启动。方便起见,你可以在 master 节点上运行 Kylin。但为了更好的稳定性,我们建议你将 Kylin 部署在一个干净的 Hadoop client 节点上,该节点上 Hive,HBase,HDFS 等命令行已安装好且 client 配置(如 core-site.xml,hive-site.xml,hbase-site.xml及其他)也已经合理的配置且其可以自动和其它节点同步。
运行 Kylin 的 Linux 账户要有访问 Hadoop 集群的权限,包括创建/写入 HDFS 文件夹,Hive 表, HBase 表和提交 MapReduce 任务的权限。
(2)硬件要求:
运行 Kylin 的服务器建议最低配置为 4 core CPU,16 GB 内存和 100 GB 磁盘。
(3)操作系统要求:
CentOS 6.5+ 或 Ubuntu 16.0.4+
(4)软件要求:
Hadoop 2.7+,3.0-3.1
Hive 0.13+,1.2.1+
HBase 1.1+,2.0(从 Kylin 2.5 开始支持)
JDK: 1.8+
建议使用集成的 Hadoop 环境进行 Kylin 的安装与测试,比如 Hortonworks HDP 或 Cloudera CDH ,Kylin发布前在 Hortonworks HDP 2.2-2.6 and 3.0, Cloudera CDH 5.7-5.11 and 6.0,AWS EMR 5.7-5.10,Azure HDInsight 3.5-3.6 上测试通过。
安装使用
当你的环境满足上述前置条件时 ,你可以开始安装使用 Kylin。
Step 1. 下载 Kylin 压缩包
从 https://kylin.apache.org/download/ 下载一个适用于你的 Hadoop 版本的二进制文件。目前最新版本是 Kylin 3.0.1和 Kylin 2.6.5,其中 3.0 版本支持实时摄入数据进行预计算的功能。如果你的 Hadoop 环境是 CDH 5.7,可以使用如下命令行下载 Kylin 3.0.0:
cd /usr/local/
wget http://apache.website-solution.net/kylin/apache-kylin-3.0.0/apache-kylin-3.0.0-bin-cdh57.tar.gz
Step 2. 解压 Kylin
解压下载得到的 Kylin 压缩包,并配置环境变量 KYLIN_HOME 指向解压目录:
tar -zxvf apache-kylin-3.0.0-bin-cdh57.tar.gz
cd apache-kylin-3.0.0-bin-cdh57
export KYLIN_HOME=`pwd`
Step 3. 下载 Spark
由于 Kylin 启动时会对 Spark 环境进行检查,所以你需要设置 SPARK_HOME:
export SPARK_HOME=/path/to/spark
如果你没有已经下载好的 Spark 环境,也可以使用 Kylin 自带脚本下载 Spark:
$KYLIN_HOME/bin/download-spark.sh
脚本会将解压好的Spark放在 $KYLIN_HOME 目录下,如果系统中没有设置 SPARK_HOME,启动 Kylin 时会自动找到 $KYLIN_HOME 目录下的 Spark。
Step 4. 环境检查
Kylin 运行在 Hadoop 集群上,对各个组件的版本、访问权限及 CLASSPATH 等都有一定的要求,为了避免遇到各种环境问题,你可以运行 $KYLIN_HOME/bin/check-env.sh 脚本来进行环境检测,如果你的环境存在任何的问题,脚本将打印出详细报错信息。如果没有报错信息,代表你的环境适合 Kylin 运行。
Step 5. 启动 Kylin
运行 $KYLIN_HOME/bin/kylin.sh start 脚本来启动 Kylin,如果启动成功,命令行的末尾会输出如下内容:
A new Kylin instance is started by root. To stop it, run 'kylin.sh stop'
Check the log at /usr/local/apache-kylin-3.0.0-bin-cdh57/logs/kylin.log
Web UI is at http://<hostname>:7070/kylin
Kylin 启动的默认端口是 7070,可以使用 $KYLIN_HOME/bin/ kylin-port-replace-util.sh set number 来修改端口,修改后的端口是 7070+number。
Step 6. 访问 Kylin
Kylin 启动后,你可以通过浏览器 http://:port/kylin 进行访问。其中 为具体的机器名、IP 地址或域名,port 为 Kylin 端口,默认为 7070。初始用户名和密码是 ADMIN/KYLIN。服务器启动后,可以通过查看 $KYLIN_HOME/logs/kylin.log 获得运行时日志。
Step 7. 创建 Sample Cube
Kylin 提供了一个创建样例 Cube 的脚本,以供用户快速体验 Kylin。在命令行运行
$KYLIN_HOME/bin/sample.sh
完成后登陆 Kylin,点击 System->Configuration->Reload Metadata 来重载元数据。
元数据重载完成后,你可以在左上角的 Project 中看到一个名为 learn_kylin 的项目,它包含 kylin_sales_cube 和 kylin_streaming_cube, 它们分别为 batch cube 和 streaming cube。你可以直接对 kylin_sales_cube 进行构建,构建完成后就可以查询。对于 kylin_streaming_cube,需要设置 KAFKA_HOME,然后执行 ${KYLIN_HOME}/bin/sample-streaming.sh,该脚本会在 localhost:9092 broker 中创建名为 kylin_streaming_topic 的 Kafka Topic,它也会每秒随机发送 100 条 messages 到 kylin_streaming_topic,然后你可以对 kylin_streaming_cube 进行构建。
关于 sample cube,可以参考http://kylin.apache.org/cn/docs/tutorial/kylin_sample.html。
当然,你也可以根据下面的教程来尝试创建自己的 Cube。
Step 8. 创建 Project
登陆 kylin 后,点击左上角的 + 号来创建 Project。

Step 9. 加载 Hive 表
点击 Model->Data Source->Load Table From Tree,Kylin 会读取到 Hive 数据源中的表,并以树状方式显示出来,你可以选择自己要使用的表,然后点击 Sync 进行将其加载到 Kylin。

随后,它们会出现在 Data Source 的 Tables 目录中
Step 10. 创建模型
点击 Model->New->New Model:

输入 Model Name 点击 Next 进行下一步,选择 Fact Table 和 Lookup Table,添加 Lookup Table 时需要设置与事实表的 JOIN 条件。
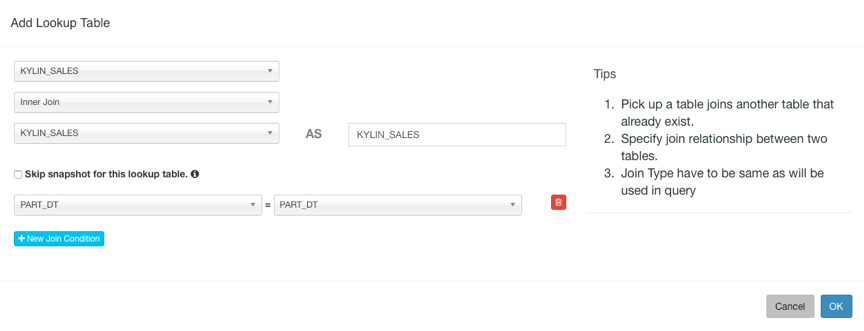
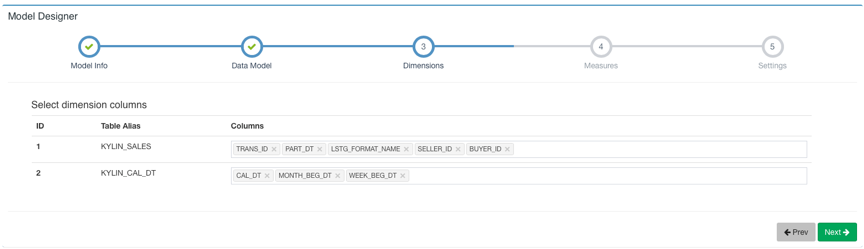
然后点击 Next 到下一步选择 Dimension:
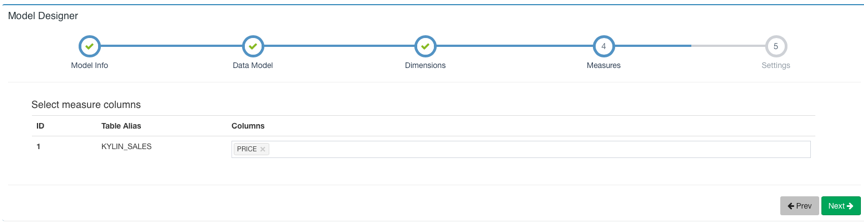
Next 下一步选择 Measure:
Next 下一步设置时间分区列和过滤条件,时间分区列用于增量构建时选择时间范围,如果不设置时间分区列则代表该 model 下的 cube 都是全量构建。过滤条件会在打平表时用于 where 条件。
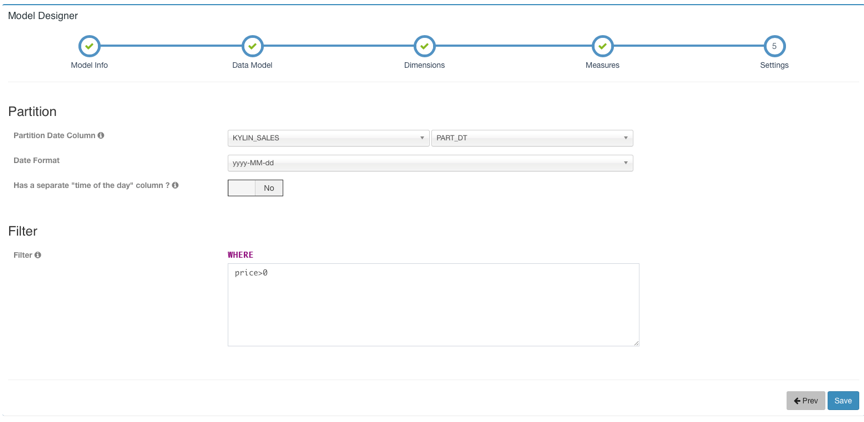
然后点击 Save 保存模型。
Step 11. 创建 Cube
Model->New->New Cube
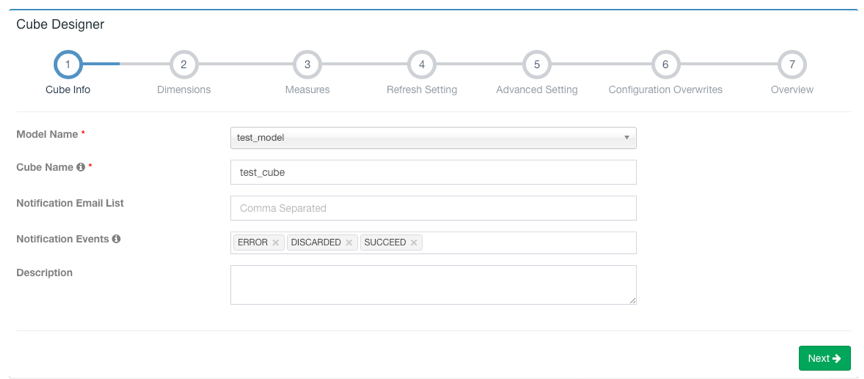
点击 Next 到下一步添加 Dimension,Lookup Table 的维度可以设置为 Normal(普通维度)或者 Derived(衍生维度)两种类型,默认设置为衍生维度,衍生维度代表该列可以从所属维度表的主键中衍生出来,所以实际上只有主键列会被 Cube 加入计算。

点击 Next 到下一步,点击 +Measure 来添加需要预计算的度量。Kylin 会默认创建一个 Count(1) 的度量。Kylin 支持 SUM、MIN、MAX、COUNT、COUNT_DISTINCT、TOP_N、EXTENDED_COLUMN、PERCENTILE 八种度量。请为 COUNT_DISTINCT 和 TOP_N 选择合适的返回类型,这关系到 Cube 的大小。添加完成之后点击 ok,该 Measure 将会显示在 Measures 列表中。
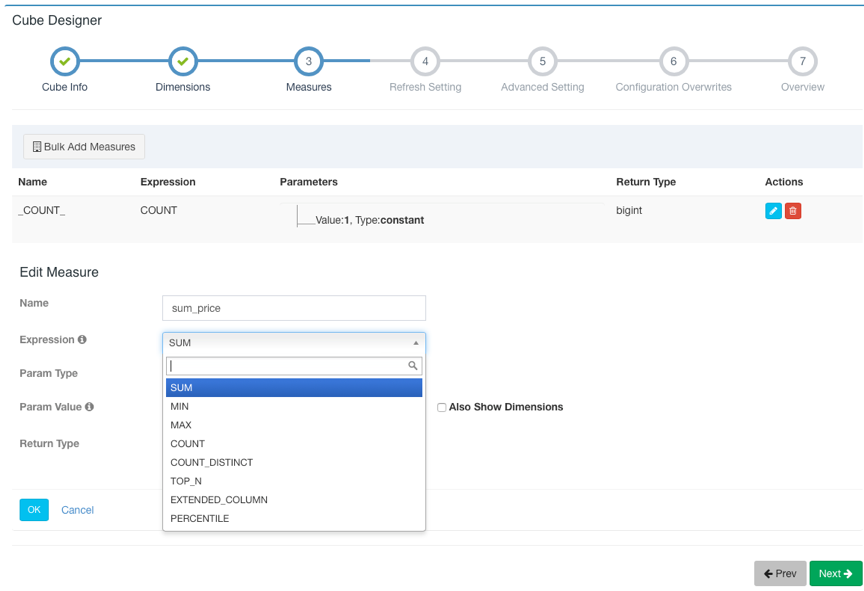
添加完所有 Measure 后,点击 Next 进行下一步,这一页是关于 Cube 数据刷新的设置。在这里可以设施自动合并的阈值(Auto Merge Thresholds)、数据保留的最短时间(Retention Threshold)以及第一个 Segment 的起点时间。

点击 Next 跳转到下一页高级设置。在这里可以设置聚合组、RowKeys、Mandatory Cuboids、Cube Engine 等。关于高级设置的详细信息,可以参考 http://kylin.apache.org/cn/docs/tutorial/create_cube.html 页面中的步骤 5,其中对聚合组等设置进行了详细介绍。关于更多维度优化,可以阅读http://kylin.apache.org/blog/2016/02/18/new-aggregation-group/。

对于高级设置不是很熟悉时可以先保持默认设置,点击 Next 跳转到 Kylin Properties 页面,你可以在这里重写 cube 级别的 Kylin 配置项,定义覆盖的属性,配置项请参考:http://kylin.apache.org/cn/docs/install/configuration.html。
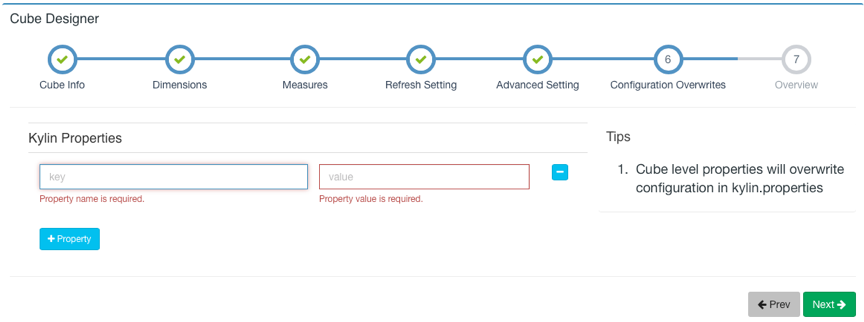
配置完成后,点击 Next 按钮到下一页,这里可以预览你正在创建的 Cube 的基本信息,并且可以返回之前的步骤进行修改。如果没有需要修改的部分,就可以点击 Save 按钮完成 Cube 创建。之后,这个 Cube 将会出现在你的 Cube 列表中。
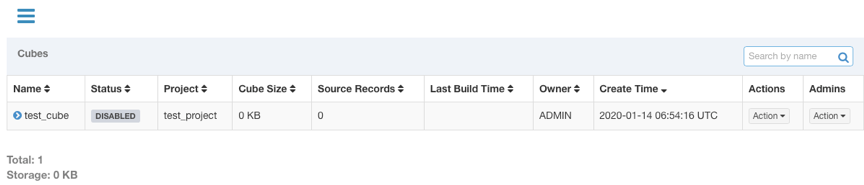
Step 12. 构建 Cube
上一个步骤创建好的Cube只有定义,而没有计算好的数据,它的状态是“DISABLED”,是不可以查询的。要想让 Cube 有数据,还需要对它进行构建。Cube 的构建方式通常有两种:全量构建和增量构建。点击要构建的 Cube 的 Actions 列下的 Action 展开,选择 Build,如果 Cube 所属 Model 中没有设置时间分区列,则默认全量构建,点击 Submit 直接提交构建任务。如果设置了时间分区列,则会出现如下页面,在这里你要选择构建数据的起止时间:

设置好起止时间后,点击 Submit 提交构建任务。然后你可以在 Monitor 页面观察构建任务的状态。Kylin 会在页面上显示每一个步骤的运行状态、输出日志以及 MapReduce 任务。可以在 ${KYLIN_HOME}/logs/kylin.log 中查看更详细的日志信息。
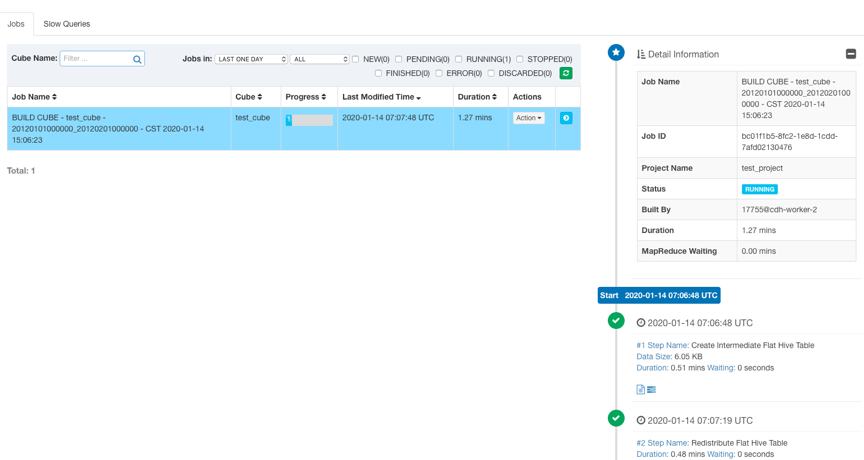
任务构建完成后,Cube 状态会变成 READY,并且可以看到 Segment 的信息。

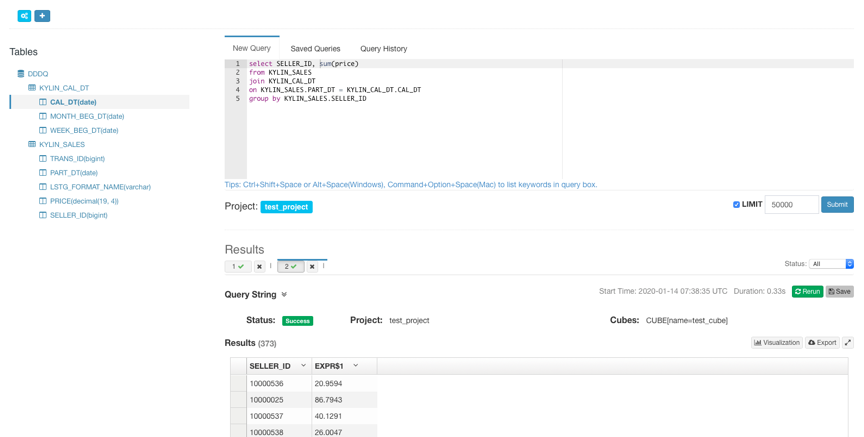
Step 13. 查询 Cube
Cube 构建完成后,在 Insight 页面的 Tables 列表下面可以看到构建完成的 Cube 的 table,并可以对其进行查询。查询语句击中 Cube 后,会返回存储在 HBase 中的预计算结果。
恭喜,进行到这里你已经具备了使用 Kylin 的基本技能,可以去发现和探索更多更强大的功能了。
Kylin 初入门 | 从下载安装到体验查询的更多相关文章
- WPS Office 2012专业版与WPS2019政府云办公增强版下载安装与体验
WPS Office 2012专业版与WPS2019政府云办公增强版下载安装与体验 一.WPS Office 2012专业版. 优点:没有广告,很清爽,界面很人性化.是我于2019年11月找出来安装测 ...
- Jenkins简单入门:下载-安装-配置-构建
Jenkins简单配置流程 官网下载地址:https://jenkins.io/index.html 1.下载安装Jenkins (1)点击Download Jenkins进入下载页 (2)根据自己运 ...
- Python 3.6.3 官网 下载 安装 测试 入门教程 (windows)
1. 官网下载 Python 3.6.3 访问 Python 官网 https://www.python.org/ 点击 Downloads => Python 3.6.3 下载 Python ...
- PyCharm 2017 官网 下载 安装 设置 配置 (主题 字体 字号) 使用 入门 教程
一.安装 Python 3.6 首先,要安装好 Python 3.6.如果你还没有安装,可以参考咪博士之前的教程 Python 3.6.3 官网 下载 安装 测试 入门教程 (windows) 二.官 ...
- hadoop入门篇-hadoop下载安装教程(附图文步骤)
在前几篇的文章中分别就虚拟系统安装.LINUX系统安装以及hadoop运行服务器的设置等内容写了详细的操作教程,本篇分享的是hadoop的下载安装步骤. 在此之前有必要做一个简单的说明:分享的所有内容 ...
- JAVA、JDK等入门概念,下载安装JAVA并配置环境变量
一.概念 Java是一种可以撰写跨平台应用程序的面向对象的程序设计语言,具体介绍可查阅百度JAVA百科,这里不再赘述. Java分为三个体系,分别为: Java SE(J2SE,Java2 Platf ...
- Linux入门学习教程:虚拟机体验之KVM篇
本文中可以学习到的命令: 1. aptitude 是apt-get 不会产生垃圾的版本 2. dpkg -L virtualbox 显示属于该包的文件 lsmod | grep kvmfi ...
- Linux_Ununtu 16.04 的下载安装并部署.Net Core 网站
第一次接触Linux也难免有些懵逼,因为公司项目必须用.Net Core 开发一个后端服务应用:第一次用Linux给我的感觉就像在用2000年的手机一样:没用智能的操作:让人崩溃的用户体验.说多了都是 ...
- Android检查更新下载安装
检查更新是任何app都会用到功能,任何一个app都不可能第一个版本就能把所有的需求都能实现,通过不断的挖掘需求迭代才能使app变的越来越好.检查更新自动下载安装分以下几个步骤: 请求服务器判断是否有最 ...
随机推荐
- css3 scale 缩放出现 1px 问题
问题描述 先来一段html代码 <div class="container"> <div class="parent"> <div ...
- 简说Python之flask-SQLAlchmey的web应用
目录 原生语句操作MySQL数据库 1.安装MySQL 2.MySQL设置用户和权限 3.用PyMySQL操纵MySQL数据库 4. CRUD增,删,改,查 使用SQLAlchemy 1.安装SQLA ...
- 关于编码和解码问题——encode、decode
一.背景和问题 近期在做一个关于声卡录音的项目,开发环境是win10 64位家庭中文版,pycharm2019.1,python3.6(Anaconda3),python模块pyaud ...
- [UWP]抄抄《CSS 故障艺术》的动画
1. 前言 什么是故障艺术(Glitch Art 风)?我们熟知的抖音的 LOGO 正是故障艺术其中一种表现形式.它有一种魔幻的感觉,看起来具有闪烁.震动的效果,很吸引人眼球.故障艺术它模拟了画面信号 ...
- thinkPHP渗透之经验决定成败
如上图,目标就一个登陆框,最近 Thinkphp 程序很多,根据后台地址结构,猜测可能是 ThinkPHP ,随手输入 xxx 得到 thinkPHP 报错页面,确定目标程序和版本. 然后上 5.X ...
- C语言实现strcat / strlen / strcmp / strcpy
主要考虑两点: 返回值对使用的便利性. 边界,null的判断. strcat char *m_strcat(char *des, const char *src) { assert((des != N ...
- 关于Web2.0
前言:本来是想写HTML的,发现没什么好写的,就简单写一下Web2.0好了 什么是Web 2.0: "Web 2.0 is the business revolution in the co ...
- abp(net core)+easyui+efcore实现仓储管理系统——入库管理之六(四十二)
abp(net core)+easyui+efcore实现仓储管理系统目录 abp(net core)+easyui+efcore实现仓储管理系统——ABP总体介绍(一) abp(net core)+ ...
- [暴力] Educational Codeforces Round 71 (Rated for Div. 2) B. Square Filling (1207B)
题目:http://codeforces.com/contest/1207/problem/B B. Square Filling time limit per test 1 second mem ...
- promise的优势
通过不同的方式读取在 files 文件夹下的三个文件来引出 promise 在处理异步时与回调函数相比的优势,files 文件夹有三个文件 a.json,b.json,c.json. // a.jso ...