新闻网大数据实时分析可视化系统项目——12、Hive与HBase集成进行数据分析
(一)Hive 概述

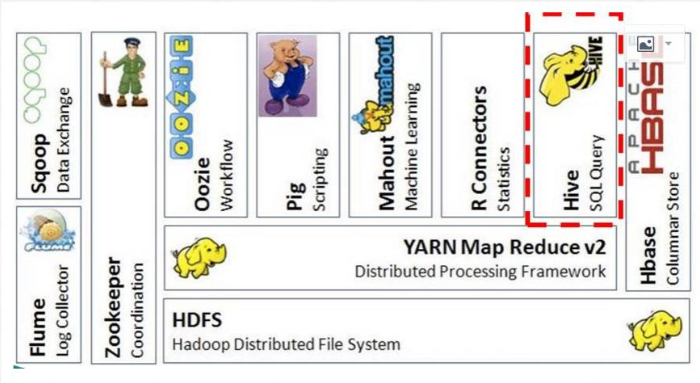
(二)Hive在Hadoop生态圈中的位置
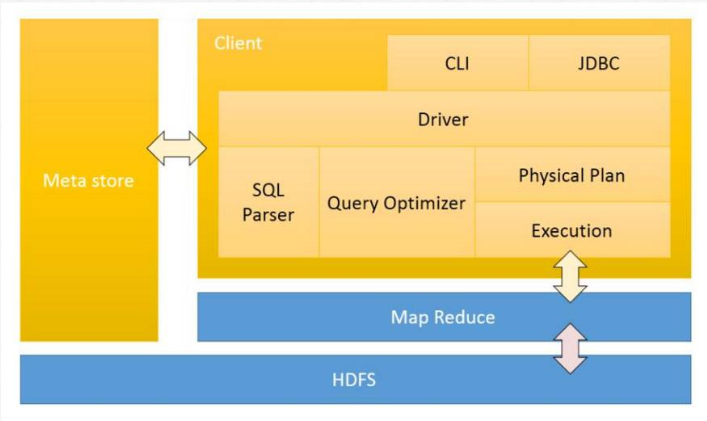
(三)Hive 架构设计

(四)Hive 的优点及应用场景

(五)Hive 的下载和安装部署
1.Hive 下载
Apache版本的Hive。
Cloudera版本的Hive。
这里选择下载Apache稳定版本apache-hive-0.13.1-bin.tar.gz,并上传至bigdata-pro03.kfk.com节点的/opt/softwares/目录下。
2.解压安装hive
tar -zxf apache-hive-0.13.1-bin.tar.gz -C /opt/modules/
3.修改hive-log4j.properties配置文件
cd /opt/modules/hive-0.13.1-bin/conf
mv hive-log4j.properties.template hive-log4j.properties
vi hive-log4j.properties
#日志目录需要提前创建
hive.log.dir=/opt/modules/hive-0.13.1-bin/logs
4.修改hive-env.sh配置文件
mv hive-env.sh.template hive-env.sh
vi hive-env.sh
export HADOOP_HOME=/opt/modules/hadoop-2.5.0
export HIVE_CONF_DIR=/opt/modules/hive-0.13.1-bin/conf
5.首先启动HDFS,然后创建Hive的目录
bin/hdfs dfs -mkdir -p /user/hive/warehouse
bin/hdfs dfs -chmod g+w /user/hive/warehouse
6.启动hive
./hive
#查看数据库
show databases;
#使用默认数据库
use default;
#查看表
show tables;
(六)Hive 与MySQL集成
1.在/opt/modules/hive-0.13.1-bin/conf目录下创建hive-site.xml文件,配置mysql元数据库。
vi hive-site.xml
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://bigdata-pro01.kfk.com/metastore?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
2.设置用户连接
1)查看用户信息
mysql -uroot -p123456
show databases;
use mysql;
show tables;
select User,Host,Password from user;
2)更新用户信息
update user set Host='%' where User = 'root' and Host='localhost'
3)删除用户信息
delete from user where user='root' and host='127.0.0.1'
select User,Host,Password from user;
delete from user where host='localhost'
4)刷新信息
flush privileges;
3.拷贝mysql驱动包到hive的lib目录下
cp mysql-connector-java-5.1.27.jar /opt/modules/hive-0.13.1/lib/
4.保证第三台集群到其他节点无秘钥登录
(七)Hive 服务启动与测试
1.启动HDFS和YARN服务
2.启动hive
./hive
3.通过hive服务创建表
CREATE TABLE stu(id INT,name STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
4.创建数据文件
vi /opt/datas/stu.txt
00001 zhangsan
00002 lisi
00003 wangwu
00004 zhaoliu
5.加载数据到hive表中
load data local inpath '/opt/datas/stu.txt' into table stu;
(八)Hive与HBase集成
1.在hive-site.xml文件中配置Zookeeper,hive通过这个参数去连接HBase集群。
<property>
<name>hbase.zookeeper.quorum</name> <value>bigdata-pro01.kfk.com,bigdata-pro02.kfk.com,bigdata-pro03.kfk.com</value>
</property>
2.将hbase的9个包拷贝到hive/lib目录下。如果是CDH版本,已经集成好不需要导包。

3.创建与HBase集成的Hive的外部表
create external table weblogs(id string,datatime string,userid string,searchname string,retorder string,cliorder string,cliurl string) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES("hbase.columns.mapping" = ":key,info:datatime,info:userid,info:searchname,info:retorder,info:cliorder,info:cliurl") TBLPROPERTIES("hbase.table.name" = "weblogs");
#查看hbase数据记录
select count(*) from weblogs;
4.hive 中beeline和hiveserver2的使用
1)启动hiveserver2
bin/hiveserver2
2)启动beeline
bin/beeline
#连接hive2服务
!connect jdbc:hive2//bigdata-pro03.kfk.com:10000
#查看表
show tables;
#查看前10条数据
select * from weblogs limit 10;
新闻网大数据实时分析可视化系统项目——12、Hive与HBase集成进行数据分析的更多相关文章
- 新闻网大数据实时分析可视化系统项目——18、Spark SQL快速离线数据分析
1.Spark SQL概述 1)Spark SQL是Spark核心功能的一部分,是在2014年4月份Spark1.0版本时发布的. 2)Spark SQL可以直接运行SQL或者HiveQL语句 3)B ...
- 新闻网大数据实时分析可视化系统项目——9、Flume+HBase+Kafka集成与开发
1.下载Flume源码并导入Idea开发工具 1)将apache-flume-1.7.0-src.tar.gz源码下载到本地解压 2)通过idea导入flume源码 打开idea开发工具,选择File ...
- 新闻网大数据实时分析可视化系统项目——2、linux环境准备与设置
1.Linux系统常规设置 1)设置ip地址 使用界面修改ip比较方便,如果Linux没有安装操作界面,需要使用命令:vi /etc/sysconfig/network-scripts/ifcfg-e ...
- 新闻网大数据实时分析可视化系统项目——13、Cloudera HUE大数据可视化分析
1.Hue 概述及版本下载 1)概述 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python ...
- 新闻网大数据实时分析可视化系统项目——19、Spark Streaming实时数据分析
1.Spark Streaming功能介绍 1)定义 Spark Streaming is an extension of the core Spark API that enables scalab ...
- 新闻网大数据实时分析可视化系统项目——21、大数据Web可视化分析系统开发
1.基于业务需求的WEB系统设计 2.下载Tomcat并创建Web工程并配置相关服务 下载tomcat,解压并启动tomcat服务. 1)新建web app项目 创建好之后的效果 2)对tomcat进 ...
- 新闻网大数据实时分析可视化系统项目——15、基于IDEA环境下的Spark2.X程序开发
1.Windows开发环境配置与安装 下载IDEA并安装,可以百度一下免费文档. 2.IDEA Maven工程创建与配置 1)配置maven 2)新建Project项目 3)选择maven骨架 4)创 ...
- 新闻网大数据实时分析可视化系统项目——8、Flume数据采集准备
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并 ...
- 新闻网大数据实时分析可视化系统项目——7、Kafka分布式集群部署
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.Spa ...
随机推荐
- Django 实现下载功能时中文文件名问题
先上最终解决代码(有待验证各浏览器效果): def download_file(request, file_path): file_name = os.path.basename(file_path) ...
- 兵贵神速!掌握这10个Python技巧,让你代码工作如鱼得水
主题 Python 1000个读者心中有1000个哈姆雷特,要问1000个程序员“什么才是最好的语言”,Java.Python.PHP.C++ 也都有自己的位置.但要问编程语言流行指数之王非,那真的非 ...
- Dism++ 更新管理提示“无法连接服务器”
Dism++ 更新管理提示"无法连接服务器" 下载wsusscn3.cab,放入Dism++安装目录下Config文件夹中.
- layer.open({}) 子页面传参并调用父页面的方法
闲话少说先看效果!!! 说明适用场景:在a.jsp页面,点击查看一个文件,layer.open弹出b.jsp页面,在b.jsp页面可以修改文件的名称(其实是去改了数据库),但是关闭弹窗的后,要求不刷新 ...
- Maven与Nexus
开始在使用Maven时,总是会听到nexus这个词,一会儿maven,一会儿nexus,当时很是困惑,nexus是什么呢,为什么它总是和maven一起被提到呢? 我们一步一步来了解吧. 一.了解Mav ...
- 高级T-SQL进阶系列 (一)【上篇】:使用 CROSS JOIN 介绍高级T-SQL
[译注:此文为翻译,由于本人水平所限,疏漏在所难免,欢迎探讨指正] 原文连接:传送门 这是一个新进阶系列的第一篇文章,我们将浏览Transact-SQL(T-SQL)的更多高级特性.这个进阶系列将会包 ...
- .NET Runtime at IP 791F7E06 (79140000) with exit code 80131506.
事件類型: 錯誤 事件來源: .NET Runtime 事件類別目錄: 無 事件識別碼: 1023 日期: 2015/12/15 時間: 上午 10:18:52 使用者: N/A 電腦: KM-ERP ...
- 人物 - 安迪·葛洛夫,Andrew Stephen Grove,Andy Grove
安德鲁·史蒂芬·格罗夫英语:Andrew Stephen Grove,昵称安迪·格罗夫(Andy Grove) 1. 前Intel的CEO 2. 1985 年将英特尔带入计算机处理器市场,帮助Inte ...
- jackson处理日期异常
原 jackson处理日期异常 2018年01月09日 10:50:19 阅读数:70 1.异常信息 2.原因 默认情况下,fasterxml json只支持几种format,但是肯定不支持" ...
- 3分钟让你的Eclipse拥有自动代码提示功能
第一步:Window->Preferences->Java 第二步:Java->Editor->Content Assist->Auto Activation->将 ...