第六篇 ORM 操作大全
阅读目录(Content)
一 对象关系映射ORM概念
对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术。
简单的说,ORM是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系数据库中。
ORM在业务逻辑层和数据库层之间充当了桥梁的作用
二 Django连接MySQL
1.创建数据库(注意设置 数据库的字符编码)
create database student default character set utf8 collate utf8_general_ci;
2.修改project中的settings.py文件中的设置 连接MySQL数据库(Django默认使用的是sqllite数据库)
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME':'student',
'USER': 'root',
'PASSWORD': '123123',
'HOST': '127.0.0.1',
'PORT': '3306',
}
}
扩展:查看ORM操作执行原生的SQL语句
在project中的settings.py文件增加
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
3、修改project 中的__init__py 文件设置 Django默认连接MySQL的方式
import pymysql
pymysql.install_as_MySQLdb()
4、setings文件注册APP
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app01.apps.App01Config', ]
5、models.py创建表
class Publisher(models.Model):
id = models.AutoField(primary_key=True)
publishName = models.CharField(max_length=32)
address = models.CharField(max_length=32)
6、进行数据迁移
6.1、在 winds cmd 或者 PyCharm Terminal 的项目的manage.py目录下执行
python manage.py makemigrations python manage.py migrate
扩展:修改表之后常见‘ 报错 ’
You are trying to add a non-nullable field 'tele' to publisher without a default; we can't do that (the database needs something
to populate existing rows).
Please select a fix:
1) Provide a one-off default now (will be set on all existing rows with a null value for this column)
2) Quit, and let me add a default in models.py
Select an option:
这个报错:因为表创建好之后,新增字段没有设置默认值,或者原来表中字段设置了不能为空参数,修改后的表结构和目前的数据冲突导致;
三、modles.py创建表
ORM字段介绍
Django提供了很多字段类型,比如URL/Email/IP/ 但是mysql数据没有这些类型,这类型存储到数据库上本质是字符串数据类型,其主要目的是为了封装底层SQL语句;
常用字段
1 AutoField
int自增列,必须填入参数 primary_key=True。当model中如果没有自增列,则自动会创建一个列名为id的列。
2 IntegerField
一个整数类型,范围在 -2147483648 to 2147483647
3 CharField
字符类型,必须提供max_length参数, max_length表示字符长度。
4 DateField
日期字段,日期格式 YYYY-MM-DD,相当于Python中的datetime.date()实例。
5 DateTimeField
日期时间字段,格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ],相当于Python中的datetime.datetime()实例
细分
1.字符串类(以下都是在数据库中本质都是字符串数据类型,此类字段只是在Django自带的admin中生效)
class Publisher(models.Model):
id = models.AutoField(primary_key=True)
publishName = models.CharField(max_length=32)
address = models.CharField(max_length=32)
tele = models.CharField(max_length=32)
models.py
EmailField(CharField):
IPAddressField(Field)
URLField(CharField)
SlugField(CharField)
UUIDField(Field)
FilePathField(Field)
FileField(Field)
ImageField(FileField)
CommaSeparatedIntegerField(CharField)
models.CharField 对应的是MySQL的varchar数据类型
char 和 varchar的区别 :
char和varchar的共同点是存储数据的长度,不能 超过max_length限制,
不同点是varchar根据数据实际长度存储,char按指定max_length()存储数据;所有前者更节省硬盘空间;
2.时间字段
models.DateTimeField(null=True) date=models.DateField()
3.数字字段
(max_digits=30,decimal_places=10)总长度30小数位 10位)
数字:
num = models.IntegerField()
num = models.FloatField() 浮点
price=models.DecimalField(max_digits=8,decimal_places=3) 精确浮点
4.枚举字段
choice=(
(1,'男人'),
(2,'女人'),
(3,'其他')
)
lover=models.IntegerField(choices=choice) #枚举类型
扩展
在数据库存储枚举类型,比外键有什么优势?
1、无需连表查询性能低,省硬盘空间(选项不固定时用外键)
2、在modle文件里不能动态增加(选项一成不变用Django的choice)
其他字段
db_index = True 表示设置索引
unique(唯一的意思) = True 设置唯一索引 联合唯一索引
class Meta:
unique_together = (
('email','ctime'),
)
联合索引(不做限制)
index_together = (
('email','ctime'),
)
ManyToManyField(RelatedField) #多对多操作
字段合集
db_index = True 表示设置索引
unique(唯一的意思) = True 设置唯一索引 联合唯一索引
class Meta:
unique_together = (
('email','ctime'),
)
联合索引(不做限制)
index_together = (
('email','ctime'),
)
ManyToManyField(RelatedField) #多对多操作
字段合集
自定义字段(了解为主)
class UnsignedIntegerField(models.IntegerField):
def db_type(self, connection):
return 'integer UNSIGNED'
自定义char类型字段:
class FixedCharField(models.Field):
"""
自定义的char类型的字段类
"""
def __init__(self, max_length, *args, **kwargs):
self.max_length = max_length
super(FixedCharField, self).__init__(max_length=max_length, *args, **kwargs) def db_type(self, connection):
"""
限定生成数据库表的字段类型为char,长度为max_length指定的值
"""
return 'char(%s)' % self.max_length class Class(models.Model):
id = models.AutoField(primary_key=True)
title = models.CharField(max_length=25)
# 使用自定义的char类型的字段
cname = FixedCharField(max_length=25)
创建的表结构:
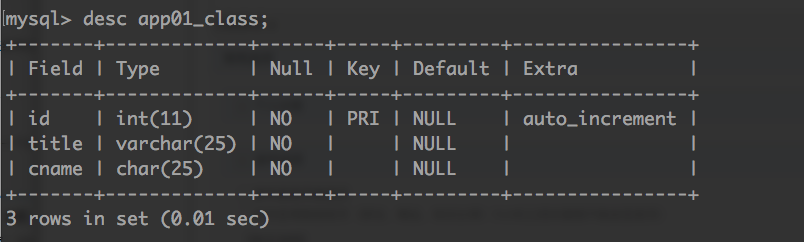
附ORM字段与数据库实际字段的对应关系
对应关系:
'AutoField': 'integer AUTO_INCREMENT',
'BigAutoField': 'bigint AUTO_INCREMENT',
'BinaryField': 'longblob',
'BooleanField': 'bool',
'CharField': 'varchar(%(max_length)s)',
'CommaSeparatedIntegerField': 'varchar(%(max_length)s)',
'DateField': 'date',
'DateTimeField': 'datetime',
'DecimalField': 'numeric(%(max_digits)s, %(decimal_places)s)',
'DurationField': 'bigint',
'FileField': 'varchar(%(max_length)s)',
'FilePathField': 'varchar(%(max_length)s)',
'FloatField': 'double precision',
'IntegerField': 'integer',
'BigIntegerField': 'bigint',
'IPAddressField': 'char(15)',
'GenericIPAddressField': 'char(39)',
'NullBooleanField': 'bool',
'OneToOneField': 'integer',
'PositiveIntegerField': 'integer UNSIGNED',
'PositiveSmallIntegerField': 'smallint UNSIGNED',
'SlugField': 'varchar(%(max_length)s)',
'SmallIntegerField': 'smallint',
'TextField': 'longtext',
'TimeField': 'time',
'UUIDField': 'char(32)',
对应关系
字段参数
null
用于表示某个字段可以为空
unique
如果设置为unique=True 则该字段在此表中必须是唯一的
db_index
如果db_index=True 则代表着为此字段设置索引
default
为该字段设置默认值
DateField和DateTimeField
auto_now_add
配置auto_now_add=True,创建数据记录的时候会把当前时间添加到数据库
auto_now
配置上auto_now=True,每次更新数据记录的时候会更新该字段
四、关系字段
1 ForeignKey
外键类型在ORM中用来表示外键关联关系,一般把ForeignKey字段设置在 '一对多'中'多'的一方。
ForeignKey可以和其他表做关联关系同时也可以和自身做关联关系。
字段参数
to
设置要关联的表
to_field
设置要关联的表的字段
related_name
反向操作时,使用的字段名,用于代替原反向查询时的'表名_set'。
例如
class Classes(models.Model):
name = models.CharField(max_length=) class Student(models.Model):
name = models.CharField(max_length=)
theclass = models.ForeignKey(to="Classes")
当我们要查询某个班级关联的所有学生(反向查询)时,我们会这么写
models.Classes.objects.first().student_set.all()
当我们在ForeignKey字段中添加了参数 related_name 后
class Student(models.Model):
name = models.CharField(max_length=)
theclass = models.ForeignKey(to="Classes", related_name="students")
当我们要查询某个班级关联的所有学生(反向查询)时,我们会这么写
models.Classes.objects.first().students.all()
related_query_name
反向查询操作时,使用的连接前缀,用于替换表名。
on_delete
当删除关联表中的数据时,当前表与其关联的行的行为。
models.CASCADE
删除关联数据,与之关联也删除
models.DO_NOTHING
删除关联数据,引发错误IntegrityError
models.PROTECT
删除关联数据,引发错误ProtectedError
models.SET_NULL
删除关联数据,与之关联的值设置为null(前提FK字段需要设置为可空)
models.SET_DEFAULT
删除关联数据,与之关联的值设置为默认值(前提FK字段需要设置默认值)
models.SET
删除关联数据,
a. 与之关联的值设置为指定值,设置:models.SET(值)
b. 与之关联的值设置为可执行对象的返回值,设置:models.SET(可执行对象)
def func():
return class MyModel(models.Model):
user = models.ForeignKey(
to="User",
to_field="id",
on_delete=models.SET(func)
)
db_constraint
是否在数据库中创建外键约束,默认为True
2 OneToOneField
一对一字段。
通常一对一字段用来扩展已有字段。
字段参数
to
设置要关联的表。
to_field
设置要关联的字段。
on_delete
同ForeignKey字段。
3 ManyToManyField
用于表示多对多的关联关系。在数据库中通过第三张表来建立关联关系。
字段参数
to
设置要关联的表
related_name
同ForeignKey字段。
related_query_name
同ForeignKey字段。
symmetrical
仅用于多对多自关联时,指定内部是否创建反向操作的字段。默认为True。
举个例子:
class Person(models.Model):
name = models.CharField(max_length=)
friends = models.ManyToManyField("self")
此时,person对象就没有person_set属性
class Person(models.Model):
name = models.CharField(max_length=)
friends = models.ManyToManyField("self", symmetrical=False)
此时,person对象现在就可以使用person_set属性进行反向查询
through
在使用ManyToManyField字段时,Django将自动生成一张表来管理多对多的关联关系。
但我们也可以手动创建第三张表来管理多对多关系,此时就需要通过through来指定第三张表的表名。
through_fields
设置关联的字段。
db_table
默认创建第三张表时,数据库中表的名称
4 元信息
ORM对应的类里面包含另一个Meta类,而Meta类封装了一些数据库的信息。主要字段如下:
db_table
ORM在数据库中的表名默认是 app_类名,可以通过db_table可以重写表名。
index_together
联合索引。
unique_together
联合唯一索引。
ordering
指定默认按什么字段排序。
只有设置了该属性,我们查询到的结果才可以被reverse()
五、ORM单表操作
1、orm操作前戏
orm使用方式:
orm操作可以使用类实例化,obj.save的方式,也可以使用create()的形式
QuerySet数据类型介绍
QuerySet与惰性机制
所谓惰性机制:Publisher.objects.all()或者.filter()等都只是返回了一个QuerySet(查询结果集对象),它并不会马上执行sql,而是当调用QuerySet的时候才执行。
QuerySet特点:
<1> 可迭代的
<2> 可切片
<3>惰性计算和缓存机制
def queryset(request):
books=models.Book.objects.all()[:] #切片 应用分页
books = models.Book.objects.all()[::]
book= models.Book.objects.all()[] #索引
print(book.title)
for obj in books: #可迭代
print(obj.title)
books=models.Book.objects.all() #惰性计算--->等于一个生成器,不应用books不会执行任何SQL操作
# query_set缓存机制1次数据库查询结果query_set都会对应一块缓存,再次使用该query_set时,不会发生新的SQL操作;
#这样减小了频繁操作数据库给数据库带来的压力;
authors=models.Author.objects.all()
for author in authors:
print(author.name)
print('-------------------------------------')
models.Author.objects.filter(id=).update(name='张某')
for author in authors:
print(author.name)
#但是有时候取出来的数据量太大会撑爆缓存,可以使用迭代器优雅得解决这个问题;
models.Publish.objects.all().iterator()
return HttpResponse('OK')
增加和查询操作
增
def orm(request):
orm2添加一条记录的方法
单表
、表.objects.create()
models.Publish.objects.create(name='浙江出版社',addr="浙江.杭州")
models.Classify.objects.create(category='武侠')
models.Author.objects.create(name='金庸',sex='男',age=,university='东吴大学')
、类实例化:obj=类(属性=XX) obj.save()
obj=models.Author(name='吴承恩',age=,sex='男',university='龙溪学院')
obj.save() 1对多
、表.objects.create()
models.Book.objects.create(title='笑傲江湖',price=,date=,classify_id=, publish_id=)
、类实例化:obj=类(属性=X,外键=obj)obj.save()
classify_obj=models.Classify.objects.get(category='武侠')
publish_obj=models.Publish.objects.get(name='河北出版社')
注意以上获取得是和 book对象 向关联的(外键)的对象
book_obj=models.Book(title='西游记',price=,date=,classify=classify_obj,publish=publish_obj)
book_obj.save() 多对多
如果两表之间存在双向1对N关系,就无法使用外键来描述其关系了;
只能使用多对多的方式,新增第三张表关系描述表;
book=models.Book.objects.get(title='笑傲江湖')
author1=models.Author.objects.get(name='金庸')
author2=models.Author.objects.get(name='张根')
book.author.add(author1,author2) 书籍和作者是多对多关系,
切记:如果两表之间存在多对多关系,例如书籍相关的所有作者对象集合,作者也关联的所有书籍对象集合
book=models.Book.objects.get(title='西游记')
author=models.Author.objects.get(name='吴承恩')
author2 = models.Author.objects.get(name='张根')
book.author.add(author,author2)
#add() 添加
#clear() 清空
#remove() 删除某个对象
return HttpResponse('OK')
删
如上
改
# 修改方式1 update()
models.Book.objects.filter(id=).update(price=) #修改方式2 obj.save()
book_obj=models.Book.objects.get(id=)
book_obj.price=
book_obj.save()
查
def ormquery(request):
books=models.Book.objects.all() #------query_set对象集合 [对象1、对象2、.... ]
books=models.Book.objects.filter(id__gt=,price__lt=)
book=models.Book.objects.get(title__endswith='金') #---------单个对象,没有找到会报错
book1 = models.Book.objects.filter(title__endswith='金').first()
book2 = models.Book.objects.filter(title__icontains='瓶').last()
books=models.Book.objects.values('title','price', #-------query_set字典集合 [{一条记录},{一条记录} ]
'publish__name',
'date',
'classify__category', #切记 正向连表:外键字段___对应表字段
'author__name', #反向连表: 小写表名__对应表字段
'author__sex', #区别:正向 外键字段__,反向 小写表名__
'author__age',
'author__university') books=models.Book.objects.values('title','publish__name').distinct()
#exclude 按条件排除。。。
#distinct()去重, exits()查看数据是否存在? 返回 true 和false
a=models.Book.objects.filter(title__icontains='金').
return HttpResponse('OK')
连表查询
反向连表查询:
、通过object的形式反向连表, obj.小写表名_set.all()
publish=models.Publish.objects.filter(name__contains='湖南').first()
books=publish.book_set.all()
for book in books:
print(book.title)
通过object的形式反向绑定外键关系
authorobj = models.Author.objects.filter(id=).first()
objects = models.Book.objects.all()
authorobj.book_set.add(*objects)
authorobj.save() 、通过values双下滑线的形式,objs.values("小写表名__字段")
注意对象集合调用values(),正向查询是外键字段__XX,而反向是小写表名__YY看起来比较容易混淆;
books=models.Publish.objects.filter(name__contains='湖南').values('name','book__title')
authors=models.Book.objects.filter(title__icontains='我的').values('author__name')
print(authors)
fifter()也支持__小写表名语法进行连表查询:在publish标查询 出版过《笑傲江湖》的出版社
publishs=models.Publish.objects.filter(book__title='笑傲江湖').values('name')
print(publishs)
查询谁(哪位作者)出版过的书价格大于200元
authors=models.Author.objects.filter(book__price__gt=).values('name')
print(authors)
通过外键字段正向连表查询,出版自保定的书籍;
city=models.Book.objects.filter(publish__addr__icontains='保定').values('title')
print(city)
1、基本操作
# 增
#
# models.Tb1.objects.create(c1='xx', c2='oo') 增加一条数据,可以接受字典类型数据 **kwargs # obj = models.Tb1(c1='xx', c2='oo')
# obj.save() # 查
#
# models.Tb1.objects.get(id=) # 获取单条数据,不存在则报错(不建议)
# models.Tb1.objects.all() # 获取全部
# models.Tb1.objects.filter(name='seven') # 获取指定条件的数据 # 删
#
# models.Tb1.objects.filter(name='seven').delete() # 删除指定条件的数据 # 改
# models.Tb1.objects.filter(name='seven').update(gender='') # 将指定条件的数据更新,均支持 **kwargs
# obj = models.Tb1.objects.get(id=)
# obj.c1 = ''
# obj.save() # 修改单条数据
2、进阶操作(了不起的双下划线)
利用双下划线将字段和对应的操作连接起来
# 获取个数
#
# models.Tb1.objects.filter(name='seven').count() # 大于,小于
#
# models.Tb1.objects.filter(id__gt=) # 获取id大于1的值
# models.Tb1.objects.filter(id__gte=) # 获取id大于等于1的值
# models.Tb1.objects.filter(id__lt=) # 获取id小于10的值
# models.Tb1.objects.filter(id__lte=) # 获取id小于10的值
# models.Tb1.objects.filter(id__lt=, id__gt=) # 获取id大于1 且 小于10的值 # in
#
# models.Tb1.objects.filter(id__in=[, , ]) # 获取id等于11、、33的数据
# models.Tb1.objects.exclude(id__in=[, , ]) # not in # isnull
# Entry.objects.filter(pub_date__isnull=True) # contains
#
# models.Tb1.objects.filter(name__contains="ven")
# models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感
# models.Tb1.objects.exclude(name__icontains="ven") # range
#
# models.Tb1.objects.filter(id__range=[, ]) # 范围bettwen and # 其他类似
#
# startswith,istartswith, endswith, iendswith, # order by
#
# models.Tb1.objects.filter(name='seven').order_by('id') # asc
# models.Tb1.objects.filter(name='seven').order_by('-id') # desc # group by
#
# from django.db.models import Count, Min, Max, Sum
# models.Tb1.objects.filter(c1=).values('id').annotate(c=Count('num'))
# SELECT "app01_tb1"."id", COUNT("app01_tb1"."num") AS "c" FROM "app01_tb1" WHERE "app01_tb1"."c1" = GROUP BY "app01_tb1"."id" # limit 、offset
#
# models.Tb1.objects.all()[:] # regex正则匹配,iregex 不区分大小写
#
# Entry.objects.get(title__regex=r'^(An?|The) +')
# Entry.objects.get(title__iregex=r'^(an?|the) +') # date
#
# Entry.objects.filter(pub_date__date=datetime.date(, , ))
# Entry.objects.filter(pub_date__date__gt=datetime.date(, , )) # year
#
# Entry.objects.filter(pub_date__year=)
# Entry.objects.filter(pub_date__year__gte=) # month
#
# Entry.objects.filter(pub_date__month=)
# Entry.objects.filter(pub_date__month__gte=) # day
#
# Entry.objects.filter(pub_date__day=)
# Entry.objects.filter(pub_date__day__gte=) # week_day
#
# Entry.objects.filter(pub_date__week_day=)
# Entry.objects.filter(pub_date__week_day__gte=) # hour
#
# Event.objects.filter(timestamp__hour=)
# Event.objects.filter(time__hour=)
# Event.objects.filter(timestamp__hour__gte=) # minute
#
# Event.objects.filter(timestamp__minute=)
# Event.objects.filter(time__minute=)
# Event.objects.filter(timestamp__minute__gte=) # second
#
# Event.objects.filter(timestamp__second=)
# Event.objects.filter(time__second=)
# Event.objects.filter(timestamp__second__gte=)
3、其他操作
# extra
#
# extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
# Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(,))
# Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
# Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"])
# Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(,), order_by=['-nid']) # F
#
# from django.db.models import F
# models.Tb1.objects.update(num=F('num')+) # Q
#
# 方式一:
# Q(nid__gt=)
# Q(nid=) | Q(nid__gt=)
# Q(Q(nid=) | Q(nid__gt=)) & Q(caption='root')
# 方式二:
# con = Q()
# q1 = Q()
# q1.connector = 'OR'
# q1.children.append(('id', ))
# q1.children.append(('id', ))
# q1.children.append(('id', ))
# q2 = Q()
# q2.connector = 'OR'
# q2.children.append(('c1', ))
# q2.children.append(('c1', ))
# q2.children.append(('c1', ))
# con.add(q1, 'AND')
# con.add(q2, 'AND')
#
# models.Tb1.objects.filter(con) # 执行原生SQL
#
# from django.db import connection, connections
# cursor = connection.cursor() # cursor = connections['default'].cursor()
# cursor.execute("""SELECT * from auth_user where id = %s""", [])
# row = cursor.fetchone()
六、ORM连表操作
我们在学习django中的orm的时候,我们可以把一对多,多对多,分为正向和反向查找两种方式。
正向查找:ForeignKey在 UserInfo表中,如果从UserInfo表开始向其他的表进行查询,这个就是正向操作,反之如果从UserType表去查询其他的表这个就是反向操作。
- 一对多:models.ForeignKey(其他表)
- 多对多:models.ManyToManyField(其他表)
- 一对一:models.OneToOneField(其他表)
正向连表操作总结:
所谓正、反向连表操作的认定无非是Foreign_Key字段在哪张表决定的,
Foreign_Key字段在哪张表就可以哪张表使用Foreign_Key字段连表,反之没有Foreign_Key字段就使用与其关联的 小写表名;
1对多:对象.外键.关联表字段,values(外键字段__关联表字段)
多对多:外键字段.all()
反向连表操作总结:
通过value、value_list、fifter 方式反向跨表:小写表名__关联表字段
通过对象的形式反向跨表:小写表名_set().all()
应用场景:
一对多:当一张表中创建一行数据时,有一个单选的下拉框(可以被重复选择)
例如:创建用户信息时候,需要选择一个用户类型【普通用户】【金牌用户】【铂金用户】等。
多对多:在某表中创建一行数据是,有一个可以多选的下拉框
例如:创建用户信息,需要为用户指定多个爱好
一对一:在某表中创建一行数据时,有一个单选的下拉框(下拉框中的内容被用过一次就消失了
例如:原有含10列数据的一张表保存相关信息,经过一段时间之后,10列无法满足需求,需要为原来的表再添加5列数据
1、1对多
如果A表的1条记录对应B表中N条记录成立,两表之间就是1对多关系;在1对多关系中 A表就是主表,B表为子表,ForeignKey字段就建在子表;
如果B表的1条记录也对应A表中N条记录,两表之间就是双向1对多关系,也称为多对多关系;
在orm中设置如果 A表设置了外键字段user=models.ForeignKey('UserType')到B表(注意外键表名加引号)
就意味着 写在写A表的B表主键, (一列),代表B表的多个(一行)称为1对多,
查询
总结:利用orm获取 数据库表中多个数据
获取到的数据类型本质上都是 queryset类型,
类似于列表,
内部有3种表现形式(对象,字典,列表)
modle.表名.objects.all()
modle.表名.objects.values()
modle.表名.objects.values()
跨表
正操作
所以表间只要有外键关系就可以一直点下去。。。点到天荒地老
所以可以通过obj.外键.B表的列表跨表操作(注意!!orm连表操作必须选拿单个对象,不像SQL中直接表和表join就可以了)
print(obj.cls.title)
foreignkey字段在那个表里,那个表里一个"空格"代表那个表的多个(一行)
class UserGroup(models.Model):
"""
部门
"""
title = models.CharField(max_length=)
class UserInfo(models.Model):
"""
员工4
"""
nid = models.BigAutoField(primary_key=True)
user = models.CharField(max_length=)
password = models.CharField(max_length=)
age = models.IntegerField(default=)
# ug_id
ug = models.ForeignKey("UserGroup",null=True)
1. 在取得时候跨表
q = UserInfo.objects.all().first()
q.ug.title
2. 在查的时候就跨表了
UserInfo.objects.values('nid','ug_id')
UserInfo.objects.values('nid','ug_id','ug__title') #注意正向连表是 外键__外键列 反向是小写的表名
3. UserInfo.objects.values_list('nid','ug_id','ug__title')
反向连表:
反向操作无非2种方式:
1、通过对象的形式反向跨表:小写表面_set().all()
2、通过value和value_list方式反向跨表:小写表名__字段
1. 小写的表名_set 得到有外键关系的对象
obj = UserGroup.objects.all().first()
result = obj.userinfo_set.all() [userinfo对象,userinfo对象,]
2. 小写的表名 得到有外键关系的列 #因为使用values取值取得是字典的不是对象,所以需要 小写表名(外键表)__
v = UserGroup.objects.values('id','title')
v = UserGroup.objects.values('id','title','小写的表名称')
v = UserGroup.objects.values('id','title','小写的表名称__age')
3. 小写的表名 得到有外键关系的列
v = UserGroup.objects.values_list('id','title')
v = UserGroup.objects.values_list('id','title','小写的表名称')
v = UserGroup.objects.values_list('id','title','小写的表名称__age')
1对多自关联( 由原来的2张表,变成一张表! )
想象有第二张表,关联自己表中的 行
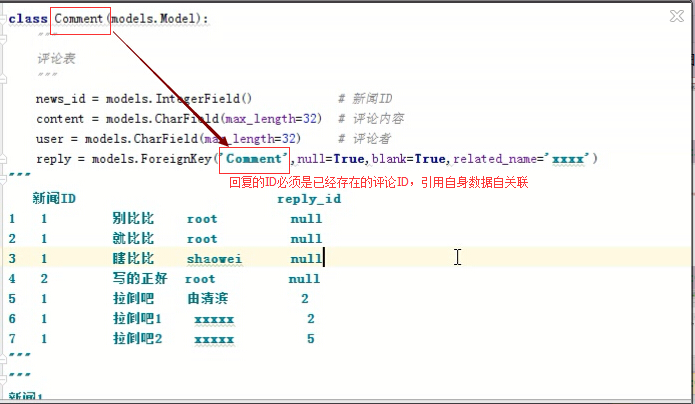
class Comment(models.Model):
"""
评论表
"""
news_id = models.IntegerField() # 新闻ID
content = models.CharField(max_length=) # 评论内容
user = models.CharField(max_length=) # 评论者
reply = models.ForeignKey('Comment',null=True,blank=True,related_name='xxxx') #回复ID
2、 多对多:
1、自己写第3张关系表
ORM多对多查询:
女士表:
男生表:

男女关系表

多对跨表操作
#获取方少伟有染的女孩
obj=models.Boy.objects.filter(name='方少伟').first()
obj_list=obj.love_set.all()
for row in obj_list:
print(row.g.nike) # 获取和苍井空有染的男孩
obj=models.Girl.objects.filter(nike='苍井空').first()
user_list=obj.love_set.all()
for row in user_list:
print(row.b.name)
多对多关系表 数据查找思路
1、找到该对象
2.通过该对象 反向操作 找到第三张关系表
3.通过第三张关系表 正向操作 找到 和该对象有关系对象
总结(只要对象1和对象2 中间有关系表建立了关系; 对象1反向操作 到关系表 ,关系表正向操作到对象2,反之亦然
2、第3张关系表不用写(m=models.ManyToManyField(' 要关联的表') 自动生成 )

由于 DjangoORM中一个类名对应一张表,要想操作表就modles.类直接操作那张表,但使用ManyToManyField字段生成 “第三张”关系表怎么操作它呢?
答案:通过单个objd对象 间接操作
class Boy(models.Model):
name = models.CharField(max_length=)
m = models.ManyToManyField('Girl',through="Love",through_fields=('b','g',)) class Girl(models.Model):
nick = models.CharField(max_length=)
m = models.ManyToManyField('Boy')
正向操作: obj.m.all()
obj = models.Boy.objects.filter(name='方少伟').first()
print(obj.id,obj.name)
obj.m.add()
obj.m.add(,)
obj.m.add(*[,]) obj.m.remove()
obj.m.remove(,)
obj.m.remove(*[,]) obj.m.set([,]) q = obj.m.all()
# [Girl对象]
print(q)
obj = models.Boy.objects.filter(name='方少伟').first()
girl_list = obj.m.all() obj = models.Boy.objects.filter(name='方少伟').first()
girl_list = obj.m.all()
girl_list = obj.m.filter(nick='小鱼')
print(girl_list) obj = models.Boy.objects.filter(name='方少伟').first()
obj.m.clear()
反向操作 :obj.小写的表名_set
多对多和外键跨表一样都是 小写的表名_set
3、既自定义第三张关系表 也使用ManyToManyField('Boy')字段(杂交类型)
ManyToManyField()字段创建第3张关系表,可以使用字段跨表查询,但无法直接操作第3张表,
自建第3表关系表可以直接操作,但无法通过字段 查询,我们可以把他们结合起来使用;
作用:
1、既可以使用字段跨表查询,也可以直接操作第3张关系表
2、obj.m.all() 只有查询和清空 方法
class UserInfo(AbstractUser):
"""
用户信息
"""
nid = models.BigAutoField(primary_key=True)
nickname = models.CharField(verbose_name='昵称', max_length=)
telephone = models.CharField(max_length=, blank=True, null=True, unique=True, verbose_name='手机号码')
avatar = models.FileField(verbose_name='头像', upload_to='upload/avatar/')
create_time = models.DateTimeField(verbose_name='创建时间',auto_now_add=True) fans = models.ManyToManyField(verbose_name='粉丝们',
to='UserInfo',
through='UserFans', through_fields=('user', 'follower')) def __str__(self):
return self.username class UserFans(models.Model):
"""
互粉关系表
"""
nid = models.AutoField(primary_key=True)
user = models.ForeignKey(verbose_name='博主', to='UserInfo', to_field='nid', related_name='users')
follower = models.ForeignKey(verbose_name='粉丝', to='UserInfo', to_field='nid', related_name='followers') class Meta:
unique_together = [
('user', 'follower'),
] through='UserFans'指定第3张关系表的表名
through_fields 指定第3张关系表的字段
class Boy(models.Model):
name = models.CharField(max_length=)
m = models.ManyToManyField('Girl',through="Love",through_fields=('b','g',))
# 查询和清空 class Girl(models.Model):
nick = models.CharField(max_length=)
# m = models.ManyToManyField('Boy') class Love(models.Model):
b = models.ForeignKey('Boy')
g = models.ForeignKey('Girl') class Meta:
unique_together = [
('b','g'),
外键反向查找别名(方便反向查找)
在写ForeignKey字段的时候,如果想要在反向查找时不使用默认的 小写的表名_set,就在定义这个字段的时间加related参数!
related_name、related_query_name 字段=什么别名 反向查找时就使用什么别名!
反向查找:
设置了related_query_name 反向查找时就是obj.别名_set.all()保留了_set
related_query_name
from django.db import models class Userinfo(models.Model):
nikename=models.CharField(max_length=)
username=models.CharField(max_length=)
password=models.CharField(max_length=)
sex=((,'男'),(,'女'))
gender=models.IntegerField(choices=sex) '''把男女表混合在一起,在代码层面控制第三张关系表的外键关系 '''
#写到此处问题就来了,原来两个外键 对应2张表 2个主键 可以识别男女
#现在两个外键对应1张表 反向查找 无法区分男女了了
# object对象女.U2U.Userinfo.set object对象男.U2U.Userinfo.set
#所以要加related_query_name对 表中主键 加以区分
#查找方法
# 男 obj.a._set.all()
# 女:obj.b._set.all()
class U2U(models.Model):
b=models.ForeignKey(Userinfo,related_query_name='a')
g=models.ForeignKey(Userinfo,related_query_name='b')
related_name
反向查找:
设置了relatedname就是 反向查找时就说 obj.别名.all()
from django.db import models class Userinfo(models.Model):
nikename=models.CharField(max_length=)
username=models.CharField(max_length=)
password=models.CharField(max_length=)
sex=((,'男'),(,'女'))
gender=models.IntegerField(choices=sex) '''把男女表混合在一起,在代码层面控制第三张关系表的外键关系 '''
#写到此处问题就来了,原来两个外键 对应2张表 2个主键 可以识别男女
#现在两个外键对应1张表 反向查找 无法区分男女了了
# object对象女.U2U.Userinfo.set object对象男.U2U.Userinfo.set
#所以要加related_query_name设置反向查找命名对 表中主键 加以区分
#查找方法
# 男 obj.a.all()
# 女:obj.b.all()
class U2U(models.Model):
b=models.ForeignKey(Userinfo,related_name='a')
g=models.ForeignKey(Userinfo,related_name='b')
操作
from django.shortcuts import render,HttpResponse
from app01 import models
# Create your views here. def index(request):
#查找 ID为1男孩 相关的女孩
boy_obj=models.Userinfo.objects.filter(id=).first() res= boy_obj.boy.all()#得到U2U的对象再 正向跨表
#原来跨表 boy_obj.小写表名.all()
# 现在设置了related_name(别名) 直接res= boy_obj.boy.all()跨表 for obj in res:
print(obj.g.nikename)
return HttpResponse('OK')
多对多自关联(由原来的3张表,变成只有2张表)
把两张表通过 choices字段合并为一张表
‘第三张关系表’ 使用models.ManyToManyField('Userinfo')生成
特性:
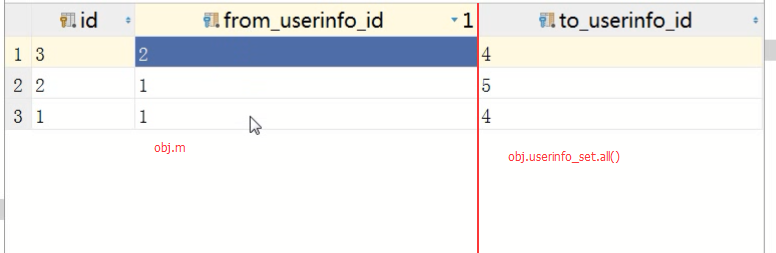
obj = models.UserInfo.objects.filter(id=1).first() 获取对象
1、查询第三张关系表前面那一列:obj.m
select xx from xx where from_userinfo_id = 1
2、查询第三张关系表后面那一列:obj.userinfo_set
select xx from xx where to_userinfo_id = 1
class Userinfo(models.Model):
nikename=models.CharField(max_length=)
username=models.CharField(max_length=)
password=models.CharField(max_length=)
sex=((,'男'),(,'女'))
gender=models.IntegerField(choices=sex)
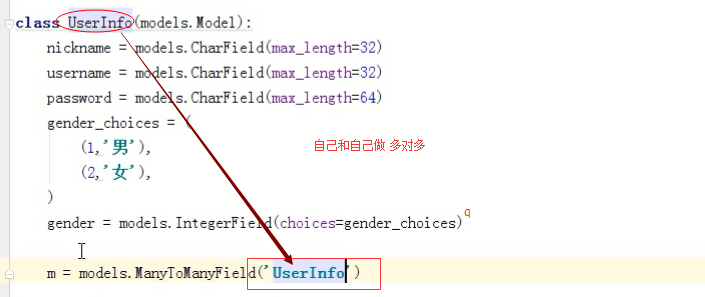
m=models.ManyToManyField('Userinfo')
查找方法
def index(request):
# 多对多自关联 之通过男士查询女生
boy_obj=models.Userinfo.objects.filter(id=).first()
res=boy_obj.m.all()
for row in res:
print(row.nikename)
return HttpResponse('OK')
#多对多自关联 之通过女士查询男生
girl_obj=models.Userinfo.objects.filter(id=).first()
res=girl_obj.userinfo_set.all()
for obj in res:
print(obj.nikename)
return HttpResponse('OK')
多对多自关联特性
ManyToManyField生成的第三张表
七、浅谈ORM查询性能
普通查询 obj_list=models.Love.objects.all()
for row in obj_list: #for循环10次发送10次数据库查询请求
print(row.b.name) 这种查询方式第一次发送 查询请求每for循环一次也会发送查询请求 、select_related:结果为对象 注意query_set类型的对象 都有该方法 原理: 查询时主动完成连表形成一张大表,for循环时不用额外发请求; 试用场景: 节省硬盘空间,数据量少时候适用相当于做了一次数据库查询; obj_list=models.Love.objects.all().select_related('b')
for row in obj_list:
print(row.b.name) 、prefetch_related:结果都对象是 原理:虽好,但是做连表操作依然会影响查询性能,所以出现prefetch_related
prefetch_related:不做连表,多次单表查询外键表 去重之后显示, 2次单表查询(有几个外键做几次1+N次单表查询, 适用场景:效率高,数据量大的时候试用 obj_list=models.Love.objects.all().prefetch_related('b')
for obj in obj_list:
print(obj.b.name) 、update()和对象.save()修改方式的性能PK
修改方式1
models.Book.objects.filter(id=).update(price=)
方式2
book_obj=models.Book.objects.get(id=)
book_obj.price=
book_obj.save() 执行结果:
(0.000) BEGIN; args=None
(0.000) UPDATE "app01_book" SET "price" = '3.000' WHERE "app01_book"."id" = ; args=('3.000', )
(0.000) SELECT "app01_book"."id", "app01_book"."title", "app01_book"."price", "app01_book"."date", "app01_book"."publish_id", "app01_book"."classify_id" FROM "app01_book" WHERE "app01_book"."id" = ; args=(,)
(0.000) BEGIN; args=None
(0.000) UPDATE "app01_book" SET "title" = '我的奋斗', "price" = '5.000', "date" = '1370-09-09', "publish_id" = , "classify_id" = WHERE "app01_book"."id" = ; args=('我的奋斗', '5.000', '1370-09-09', , , )
[/Aug/ ::] "GET /fandq/ HTTP/1.1" 结论: update() 方式1修改数据的方式,比obj.save()性能好;
八、分组和聚合查询
1、aggregate(*args,**kwargs) 聚合函数
通过对QuerySet进行计算,返回一个聚合值的字典。aggregate()中每一个参数都指定一个包含在字典中的返回值。即在查询集上生成聚合
from django.db.models import Avg,Sum,Max,Min
#求书籍的平均价
ret=models.Book.objects.all().aggregate(Avg('price'))
#{'price__avg': 145.23076923076923} #参与西游记著作的作者中最老的一位作者
ret=models.Book.objects.filter(title__icontains='西游记').values('author__age').aggregate(Max('author__age'))
#{'author__age__max': } #查看根哥出过得书中价格最贵一本
ret=models.Author.objects.filter(name__contains='根').values('book__price').aggregate(Max('book__price'))
#{'book__price__max': Decimal('234.000')}
2、annotate(*args,**kwargs) 分组函数
查看每一位作者出过的书中最贵的一本(按作者名分组 values() 然后annotate 分别取每人出过的书价格最高的)
ret=models.Book.objects.values('author__name').annotate(Max('price'))
# < QuerySet[
# {'author__name': '吴承恩', 'price__max': Decimal('234.000')},
# {'author__name': '吕不韦','price__max': Decimal('234.000')},
# {'author__name': '姜子牙', 'price__max': Decimal('123.000')},
# {'author__name': '亚微',price__max': Decimal('123.000')},
# {'author__name': '伯夷 ', 'price__max': Decimal('2010.000')},
# {'author__name': '叔齐','price__max': Decimal('200.000')},
# {'author__name': '陈涛', 'price__max': Decimal('234.000')},
# {'author__name': '高路川', price__max': Decimal('234.000')}
# ] > #查看每本书的作者中最老的 按作者姓名分组 分别求出每组中年龄最大的
ret=models.Book.objects.values('author__name').annotate(Max('author__age'))
# < QuerySet[
# {'author__name': '吴承恩', 'author__age__max': },
# {'author__name': '张X', 'author__age__max': },
# { 'author__name': '张X杰', 'author__age__max': },
# {'author__name': '方X伟', 'author__age__max': },
# {'author__name': '游X兵', 'author__age__max': },
# {'author__name': '金庸', 'author__age__max': },
# { 'author__name': 'X涛', 'author__age__max': },
# {'author__name': '高XX', 'author__age__max': }
# ] > #查看 每个出版社 出版的最便宜的一本书
ret=models.Book.objects.values('publish__name').annotate(Min('price'))
# < QuerySet[
# {'publish__name': '北大出版社','price__min': Decimal('67.000')},
# {'publish__name': '山西出版社','price__min': Decimal('34.000')},
# {'publish__name': '河北出版社', 'price__min': Decimal('123.000')},
# {'publish__name': '浙江出版社', 'price__min': Decimal('2.000')},
# {'publish__name': '湖北出版社', 'price__min': Decimal('124.000')},
# {'publish__name': '湖南出版社',price__min': Decimal('15.000')}
# ] >
九、F查询与Q查询
仅仅靠单一的关键字参数查询已经很难满足查询要求。此时Django为我们提供了F和Q查询:
1、F 可以获取对象中的字段的属性(列),并对其进行操作;
from django.db.models import F,Q
#F 可以获取对象中的字段的属性(列),并且对其进行操作;
models.Book.objects.all().update(price=F('price')+) #对图书馆里的每一本书的价格 上调1块钱
2、Q多条件组合查询
Q()可以使orm的fifter()方法支持, 多个查询条件,使用逻辑关系(&、|、~)包含、组合到一起进行多条件查询;
语法:
fifter(Q(查询条件1)| Q(查询条件2))
fifter(Q(查询条件2)& Q(查询条件3))
fifter(Q(查询条件4)& ~Q(查询条件5))
fifter(Q(查询条件6)| Q(Q(查询条件4)& ~ Q(Q(查询条件5)& Q(查询条件3)))包含
from django.db.models import F,Q
、F 可以获取对象中的字段的属性(列),并且对其进行操作;
# models.Book.objects.all().update(price=F('price')+)
、Q多条件组合查询
#如果 多个查询条件 涉及到逻辑使用 fifter(,隔开)可以表示与,但没法表示或非得关系
#查询 书名包含作者名的书
book=models.Book.objects.filter(title__icontains='伟',author__name__contains='伟').values('title')
#如何让orm 中得 fifter 支持逻辑判断+多条件查询? Q()登场
book=models.Book.objects.filter(Q(title__icontains='E') & Q(author__name__contains='E')).values('title')
book=models.Book.objects.filter(Q(author__name__contains='伟') & ~Q(title__icontains='E')).values('title') #多条件包含组合查询
#查询作者姓名中包含 A/B/C/书名包含伟3字 并且出版社地址以XX开头的书
book=models.Book.objects.filter(
Q(
Q(author__name__contains='A') |
Q(author__name__contains='B') |
Q(title__icontains='伟')|
Q(author__name__contains='C')
)
&
Q(publish__addr__contains='XX')
).values('title')
print(book)
return HttpResponse('OK')
注意:Q查询条件和非Q查询条件混合使用注意,不包Q()的查询条件一点要放在Q(查询条件)后面

第六篇 ORM 操作大全的更多相关文章
- Django中的app及mysql数据库篇(ORM操作)
Django常见命令 在Django的使用过程中需要使用命令让Django进行一些操作,例如创建Django项目.启动Django程序.创建新的APP.数据库迁移等. 创建Django项目 一把我们都 ...
- Django基础07篇 ORM操作
1.新增(类似数据库操作的insert) # 新增 #方式一: models.Category.objects.create(name='MySQL') #方式二: c = models.Catego ...
- Linux操作系统常用命令合集——第六篇-软件包操作(2个命令)
一.前言介绍 软件包即程序包 程序包管理 关键词:rpm程序包管理.YUM仓库管理.源码编译安装 程序包管理: 将编译好的应用程序的各组成文件打包一个或几个程序包文件,从而方便快捷地实现程序包的安装. ...
- Django之Models与ORM操作
一.models例子 from django.db import models class User(models.Model): """ 用户表 "" ...
- Python之路【第十六篇】:Django【基础篇】
Python之路[第十六篇]:Django[基础篇] Python的WEB框架有Django.Tornado.Flask 等多种,Django相较与其他WEB框架其优势为:大而全,框架本身集成了O ...
- Redis篇之操作、lettuce客户端、Spring集成以及Spring Boot配置
Redis篇之操作.lettuce客户端.Spring集成以及Spring Boot配置 目录 一.Redis简介 1.1 数据结构的操作 1.2 重要概念分析 二.Redis客户端 2.1 简介 2 ...
- 第六篇 :微信公众平台开发实战Java版之如何自定义微信公众号菜单
我们来了解一下 自定义菜单创建接口: http请求方式:POST(请使用https协议) https://api.weixin.qq.com/cgi-bin/menu/create?access_to ...
- 第六篇 Replication:合并复制-发布
本篇文章是SQL Server Replication系列的第六篇,详细内容请参考原文. 合并复制,类似于事务复制,包括一个发布服务器,一个分发服务器和一个或多个订阅服务器.每一个发布服务器上可以定义 ...
- 第六篇 Integration Services:初级工作流管理
本篇文章是Integration Services系列的第六篇,详细内容请参考原文. 简介在前几篇文章中,我们关注使用增量加载方式加载数据.在本篇文章,我们将关注使用优先约束管理SSIS控制流中的工作 ...
随机推荐
- 无需密码攻击 Microsoft SQL Server
最近的一次渗透测试里,在我们捕获的一些数据包中发现了一些未经加密的 Microsoft SQL Server(MSSQL) 流量.起初,我们认为这样就可以直接嗅探到认证凭证,然而,MSSQL 加密了认 ...
- Date.parse在IE/Firefox下有兼容性问题
原因: IE和Firefox是不支持含有'-'字符的日期格式,如:"2018-11-23" 解决方法: 日期格式 'yyyy-mm-dd' 改成 'yyyy/mm/dd' 代码: ...
- tomcat重载web项目,debug
Reloading Context with name [/testCookie] is completed 加载上下文名称[ / ]完成testcookie //start九月 05, 2017 9 ...
- 搞懂G1垃圾收集器
一.G1 GC术语Overview 1.1 并发 并发的意思是Java应用执行和垃圾收集活动可以同时进行 1.2 并行 并行的意思是垃圾收集运算是多线程执行的,比如CMS垃圾收集器的年轻代就是并行的, ...
- javascript中,对象本身就是一种Map结构。
var map = {}; map['key1'] = 1; map['key2@'] = 2; console.log(map['key1']);//结果是1. console.log(map[ ...
- redis集群JedisCluster连接关闭问题
JedisCluster连接关闭问题 set方法为例 //伪代码 JedisCluster jedisCluster = new JedisCluster(); jedisCluster.set(&q ...
- C++ 类 与 static
背景 从学习C++到使用现在,发现很多新的东西,正好整理一下. static 为静态,指是当类编译加载的时候,内存就会开辟存储空间的. static 数据成员 在类中,static 可修饰 类中的成员 ...
- 【pwnable.tw】 death_note
题目逻辑比较简单,大概增加和删除和打印三个功能: show函数中,打印各日记内容,由于这题没有给出libc文件,应该不需要泄露地址,估计用处不大: delete函数中,正常的free,然后指针修改为n ...
- vue使用videojs控制后台m3u8数据请求
关于Video.js的使用方法就不再说了,有兴趣的请迁跃:https://videojs.com/ VideoJS中并没有stop之类控制后台数据请求的参数,只有暂停 video.pause()方法 ...
- 数十万PhpStudy用户被植入后门,快来检测你是否已沦为“肉鸡”!
北京时间9月20日,杭州公安发布<杭州警方通报打击涉网违法犯罪暨‘净网2019’专项行动战果>一文,文章曝光了国内知名PHP调试环境程序集成包“PhpStudy软件”遭到黑客篡改并植入“后 ...