Glusterfs读写性能测试与分析
一、测试目的:
1、测试分布卷(Distributed)、分布式复制卷(Distributed-Replicate)、条带卷(Strip)和分布式条带复制卷(Distributed-Strip-Replicate)的读写性能。
2、测试网络对文件系统读写性能的影响。
一、测试准备:
1、三台千兆网测试机:dn151,dn152,dn154。每台测试机上有七块1T硬盘,dn151等是测试机的hostname。hostname配置方式,以及glusterfs的安装见https://www.cnblogs.com/ForestCherry/p/10876049.html。
2、创建目录:mkdir -p /data01 /data02 /data03 /data04 /data05 /data06 /data07 /Distributed-test /Distributed-Replicate-test /Strip-test /Distributed-Strip-Replicate-test(前面的是磁盘挂载目录,后面是卷节点挂载目录)
3、挂载磁盘:mount /dev/sdb /data01;mount /dev/sdc /data02;mount /dev/sdb /data03;mount /dev/sde /data04;mount /dev/sdf /data05;mount /dev/sdg /data06;mount /dev/sdh /data07;
4、测试命令:time dd if=/dev/zero bs=1M count=4096 of=4G.file(也可以借助fio工具测试)
三、开始测试:
1、创建gluster集群:gluster peer probe dn152;gluster peer probe dn154(这里是在dn151上创建的,也可以在其他两台上创建)
2、创建卷:(任意一台上执行)
1)gluster volume create Distributed-Strip-Replicate-test strip 2 replica 2 dn151:/data01 dn152:/data01 dn151:/data02 dn152:/data02 dn151:/data03 dn152:/data03 dn151:/data04 dn152:/data04 force 创建分布式条带复制卷
2)gluster volume create Distributed-test dn151:/data05 dn152:/data05 force 创建分布卷
3)gluster volume create Strip-test strip 2 dn151:/data06 dn152:/data06 force 创建条带卷
4)gluster volume create Distributed-Replicate-test replica 2 151:/data07 dn152:/data07 force 创建分布式复制卷
3、启动卷:gluster volume start Distributed-Strip-Replicate-test;gluster volume start Distributed-test; gluster volume start Strip-test;gluster volume start Distributed-Replicate-test(任意一台上执行)
4、挂载卷:mount -t glusterfs dn151:/Distributed-Replicate-test Distributed-Replicate-test;mount -t glusterfs dn151:/Distributed-Strip-Replicate-test Distributed-Strip-Replicate-test; mount -t glusterfs dn151:/Distributed-test Distributed-test;mount -t glusterfs dn151:/Strip-test Strip-test(每台上都要执行)
5、查看卷信息:gluster volume info
图一:
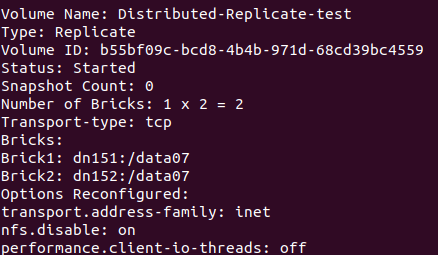
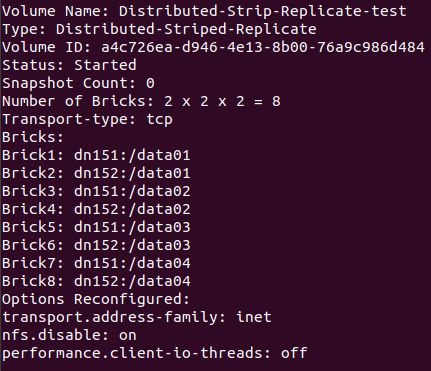
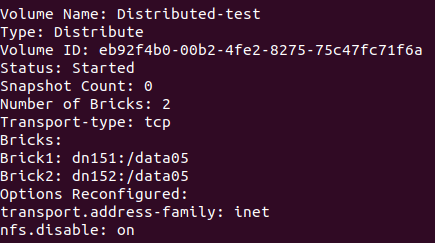
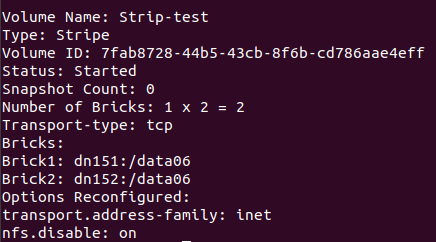
6、测试及现象:
dn151上:
图二:
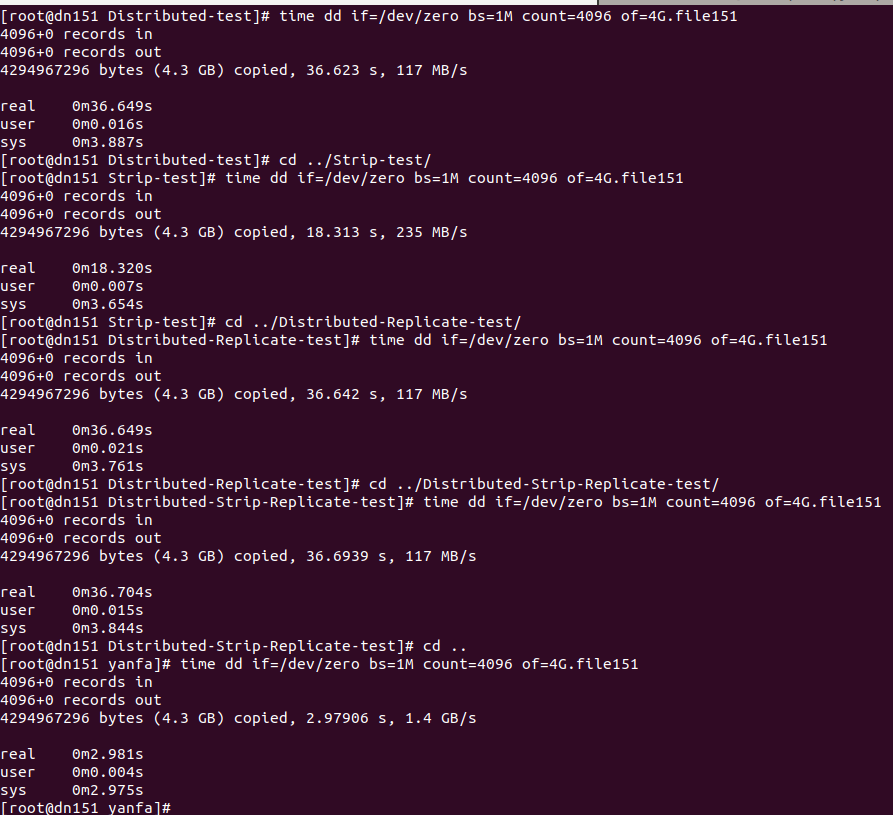
dn152上:
图三:
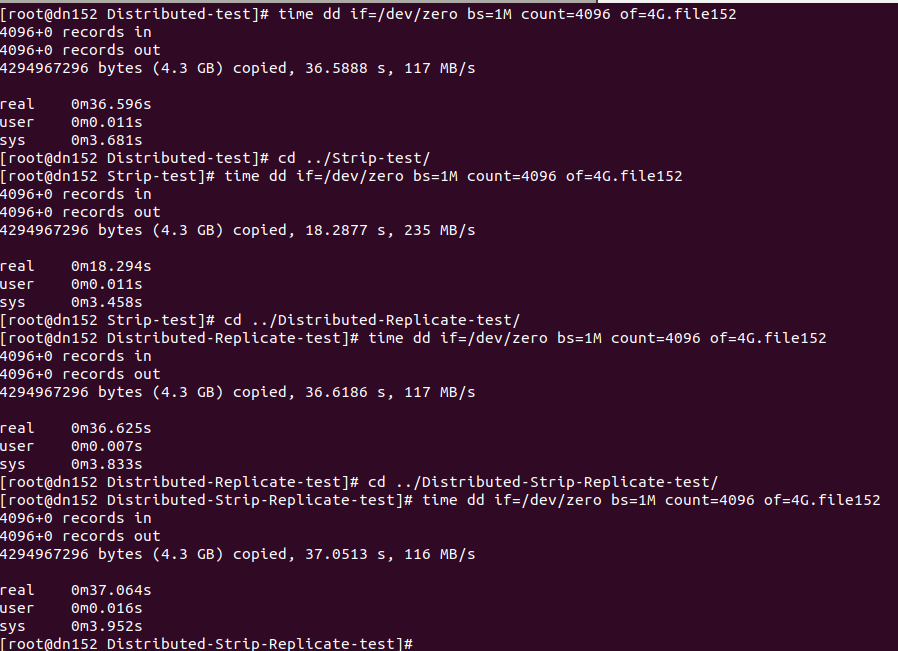
dn154上:
图四:
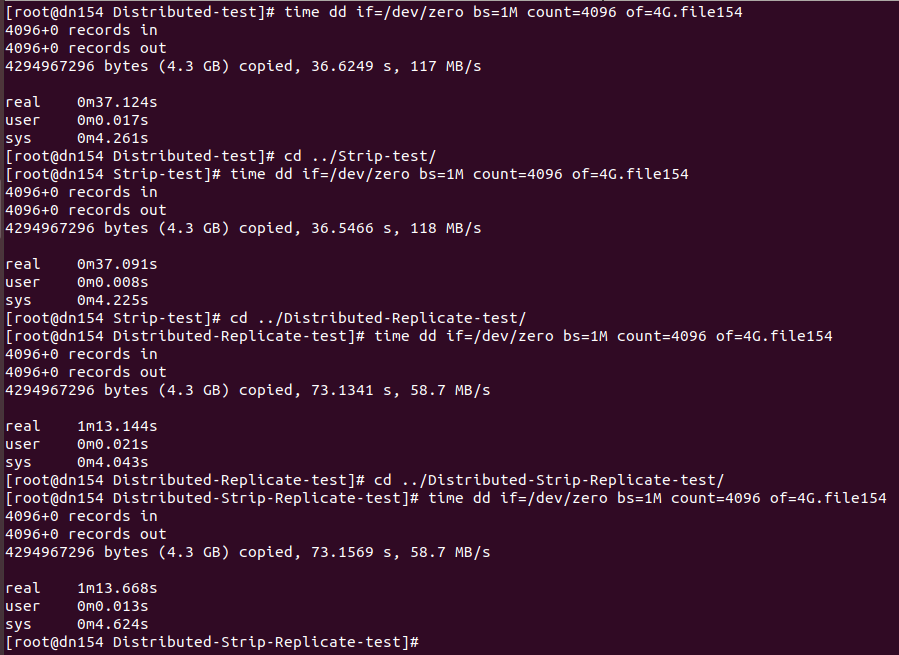
dn151上:
图五:
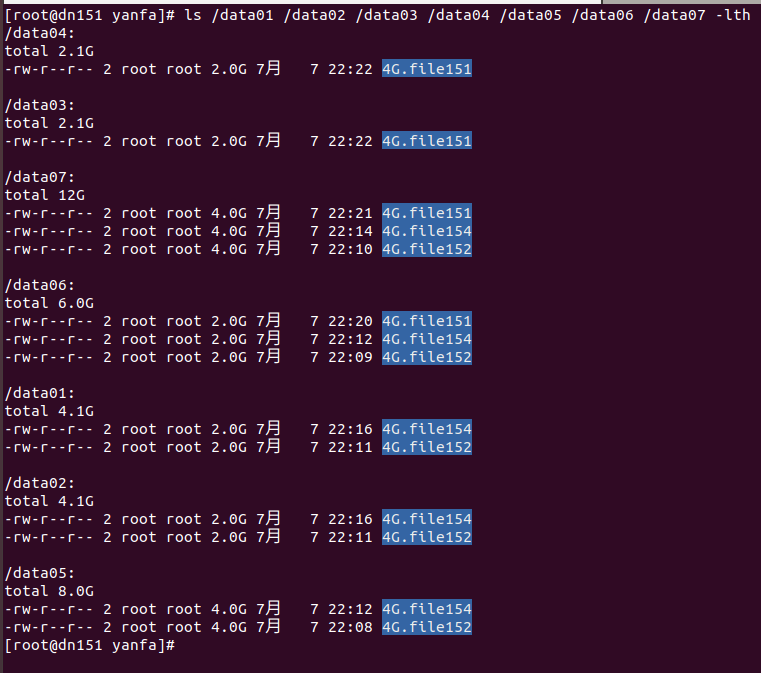
dn152上:
图六:
说明:上诉dd命令是在一台上执行完后再去另一台上执行(相当于只测试了读或写),如果几台同时执行dd(相当于并发读写测试),那么性能会有所下降。
四、测试结果分析:(来自小白的简单分析,可能不准确,求大神指教)
1、glusterfs下读写请求的处理流程分析:请参照https://www.cnblogs.com/chaozhu/p/6402000.html
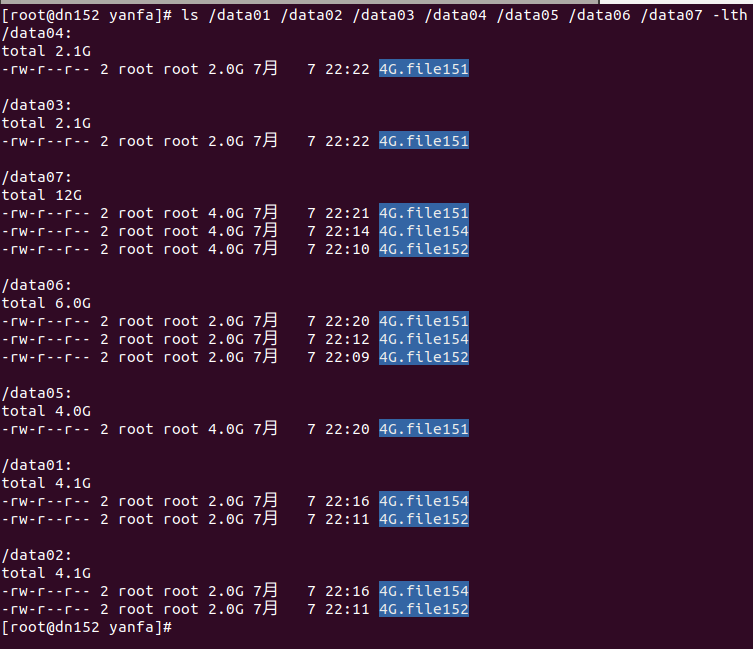
2、从图二或图三或图四可以看出:本地 > 条带卷 > 分布卷 ≈ 复制卷 ≈ 分布式条带复制卷
分析:
1)条带卷大于分布卷:结合图五图六可以看出,在dn151上执行dd命令,分布卷目录下根据哈希算法,随机将文件4G.flie151存储在dn152:/data05上;而条带卷是将4G.flie151分别存在dn151和dn152上的/data06上。所以就跨网来说,分布卷时4G全部使用socket存储,而条带卷只有2G文件通过socket存储,所以此时表现条带卷速度大于分布卷(如果分布卷存储通过哈希算法,在dn151上也将文件存储在dn151上,那么肯定是分布卷速度远大于条带卷速度,读者可自行测试)。
2)值得一提,创建条带卷时,当Number of Bricks: 为n*2(n >= 2)时,如果创建语句为:gluster volume create Strip-test strip 2 dn151:/data06 dn151:/data07 dn152:/data06 dn152:/data07 force(未跨网络分段),
如果创建语句为:gluster volume create Strip-test strip 2 dn151:/data06 dn152:/data06 dn151/data07 dn152:/data07 force(跨网络分段,不好的习惯,性能下降),两者的速度是不一样的,前者速度明显大于后者。
3)分布式复制卷 ≈ 分布式条带复制卷:测试文件不够大或者网络条件制约(千兆网的传输速率门槛大概在128MB/s),没体现出条带卷的优势。
2、图二和图三和图四对比可得:图四 < 图三 = 图二
分析:拿复制卷来说。
1)无论是在dn151上执行还是在dn152上执行,文件都是先在本地创建了4G.flie151或4G.flie152,然后再通过socke备份到另一台上,而当本地执行完请求后就会返回;而在dn154上执行,是要通过socket将文件存储到dn151和dn152上,所以返回响应会更久。
2)从结果117MB/s的测试结果可以看出,网络是制约影响文件系统读写性能的主要因素。
3、求指教:
1、以上分析是在当前条件下测试,结果和分析可能不太准确,如有不当,还请指教。
2、网上说fuse层对性能的影响很小,那么为什么在本地执行dd命令和通过flusterfs的挂载目录执行dd命令速度会慢那么多(咱们可以在dn151上执行 gluster volume create test-volume dn151:/test1 /dn151:/test2 force试一下)
3、求大神对上面的测试结果进行专业的分析。
Glusterfs读写性能测试与分析的更多相关文章
- 161220、使用Spring AOP实现MySQL数据库读写分离案例分析
一.前言 分布式环境下数据库的读写分离策略是解决数据库读写性能瓶颈的一个关键解决方案,更是最大限度了提高了应用中读取 (Read)数据的速度和并发量. 在进行数据库读写分离的时候,我们首先要进行数据库 ...
- LoadRunner性能测试结果分析
LoadRunner性能测试结果分析http://www.docin.com/p-793607435.html
- Greenplum 简单性能测试与分析
如今,多样的交易模式以及大众消费观念的改变使得数据库应用领域不断扩大,现代的大型分布式应用系统的数据膨胀也对数据库的海量数据处理能力和并行处理能力提出了更高的要求,如何在数据呈现海量扩张的同时提高处理 ...
- Apache ab性能测试结果分析
Apache ab性能测试结果分析 测试场景:模拟10个用户,对某页发起总共100次请求. 测试命令: ab -n 100 -c 10 地址 测试报告: Server Software: 被测服务器软 ...
- 170301、使用Spring AOP实现MySQL数据库读写分离案例分析
使用Spring AOP实现MySQL数据库读写分离案例分析 原创 2016-12-29 徐刘根 Java后端技术 一.前言 分布式环境下数据库的读写分离策略是解决数据库读写性能瓶颈的一个关键解决方案 ...
- LoadRunner性能测试结果分析(转载)
性能测试的需求指标:本次测试的要求是验证在30分钟内完成2000次用户登录系统,然后进行考勤业务,最后退出,在业务操作过程中页面的响应时间不超过3秒,并且服务器的CPU使用率.内存使用率分别不超过75 ...
- 使用Spring AOP实现MySQL数据库读写分离案例分析
一.前言 分布式环境下数据库的读写分离策略是解决数据库读写性能瓶颈的一个关键解决方案,更是最大限度了提高了应用中读取 (Read)数据的速度和并发量. 在进行数据库读写分离的时候,我们首先要进行数据库 ...
- Web项目性能测试结果分析
1.测试结果分析 LoadRunner性能测试结果分析是个复杂的过程,通常可以从结果摘要.并发数.平均事务响应时间.每秒点击数.业务成功率.系统资源.网页细分图.Web服务器资源.数据库服务器资源等几 ...
- Linux系统性能测试工具(九)——文件系统的读写性能测试工具之iozone
本文介绍关于Linux系统(适用于centos/ubuntu等)的文件系统的读写性能测试工具-iozone: 参考链接: https://www.cnblogs.com/Dev0ps/p/788938 ...
随机推荐
- Java实现 LeetCode 667 优美的排列 II(暴力)
667. 优美的排列 II 给定两个整数 n 和 k,你需要实现一个数组,这个数组包含从 1 到 n 的 n 个不同整数,同时满足以下条件: ① 如果这个数组是 [a1, a2, a3, - , an ...
- Java实现k个数乘(cheng)(自然数的k乘积问题)
k个数乘(cheng) 题目描述 桐桐想把一个自然数N分解成K个大于l的自然数相乘的形式,要求这K个数按从小到大排列,而且除了第K个数之外,前面(K-l)个数是N分解出来的最小自然数.例如:N=24, ...
- Java实现 蓝桥杯VIP 算法提高 快速幂
算法提高 快速幂 时间限制:1.0s 内存限制:256.0MB 问题描述 给定A, B, P,求(A^B) mod P. 输入格式 输入共一行. 第一行有三个数,N, M, P. 输出格式 输出共一行 ...
- Java实现 蓝桥杯VIP 算法提高 数的划分
算法提高 数的划分 时间限制:1.0s 内存限制:256.0MB 问题描述 一个正整数可以划分为多个正整数的和,比如n=3时: 3:1+2:1+1+1: 共有三种划分方法. 给出一个正整数,问有多少种 ...
- Java实现 LeetCode 95 不同的二叉搜索树 II(二)
95. 不同的二叉搜索树 II 给定一个整数 n,生成所有由 1 - n 为节点所组成的二叉搜索树. 示例: 输入: 3 输出: [ [1,null,3,2], [3,2,null,1], [3,1, ...
- Python:求时间差(天时分秒格式)
传入一个时间戳,以天时分秒格式打印出时间差 输入一个10位的时间戳,求出时间差 def time_diff(timestamp): onlineTime = datetime.datetime.fro ...
- ant构建Jmeter脚本的build文件配置(build.xml)
使用此构建文件可自动发送邮件 代码如下: <?xml version="1.0" encoding="UTF8"?> <project na ...
- 关于adb的下载和基本使用
我们无论是开发还是测试,对Android SDK一定都不陌生,如果我们要使用adb(Android debug bridge)命令,那么这个就必不可少了. 1.给大家提供一个下载地址:https:// ...
- [Web][学习随笔]Session&cookie
Session 从登录建立连接到退出就是一次会话.Session数据就会在会话期间用户存在服务器端的数据.这样,当用户在Web页之间跳转时,存储在Session对象中的变量将不会丢失,而是在整个用户会 ...
- 使用PyQtGraph绘制图形(2)
采用addplot()方法将多个图形添加到一个窗口. 首先利用numpy模块创建两个随机数组,用来作为图形绘制的数据: import pyqtgraph as pg import numpy as n ...