Java 线程池(二)
简介
在上篇 Java 线程池(一) 我们介绍了线程池中一些的重要参数和具体含义,这篇我们看一看在 Java 中是如何去实现线程池的,要想用好线程池,只知其然是远远不够的,我们需要深入实现源码去了解线程池的具体实现细节,这样才能更好的使用到我们的工作中,当出现问题时能快速找到问题根源所在。
线程池如何处理提交的任务
我们向线程池提交任务有两种方式,分别是通过 submit 方法提交和通过 execute 方法提交,这两种方式的区别为 execute 只能提交 Runnable 类型的任务并且没有返回值,而 submit 既能提交 Runnable 类型的任务也能提交 Callable(JDK 1.5+)类型的任务并且会有一个类型 Future 的返回值,我们知道 Runnable 是没有返回值的,所以只有当提交 Callable 类型的任务时才会有返回值,而提交 Runnable 的返回值是 null。 execute 执行任务时,如果此时遇到异常会直接抛出,而 submit 不会直接抛出,只有在使用 Future 的 get 方法获取任务的返回结果时,才会抛出异常。
通过查看 ThreadPoolExecutor 的源码我们发现,其 submit 方法是继承自其抽象父类 AbstractExecutorService 而来的,有三个重载的方法,分别可以提交 Runnable 类型和 Callable 类型的任务。无论是哪个 submit 方法最终还是调用了 execute 方法来实现的。方法源码如下:
1 |
public Future<?> submit(Runnable task) {
|
首先对提交的任务进行判非空指针后,三个方法都是调用 newTaskFor 方法把任务统一封装成 RunnableFuture 对象,然后把封装好的对象作为 execute 方法的入参去执行,而此时 execute 方法还未实现,这个方法是在 AbstractExecutorService 的继承类 ThreadPoolExecutor 中实现。下面看看 newTaskFor 方法是如何封装我们提交的任务的,两个重载方法的源码如下:
1 |
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
|
那么这个 FutureTask 是个什么东东呢,进入其源码发现它实现了 RunnableFuture 接口,而 RunnableFuture 接口的作用正如其名,它是 Runnable 和 Future 的结合体,表示一个能异步返回结果的线程。我们知道 Runnable 是不能返回结果的,所以上面第一个 newTaskFor(Runnable runnable, T value) 方法的第二个参数 value 的作用就是指定返回结果。其实最后也是通过 RunnableAdapter 把 Runnable 和 value 封装成 Callable 的。下面我们看看 execute 方法是怎么处理的,方法源码如下:
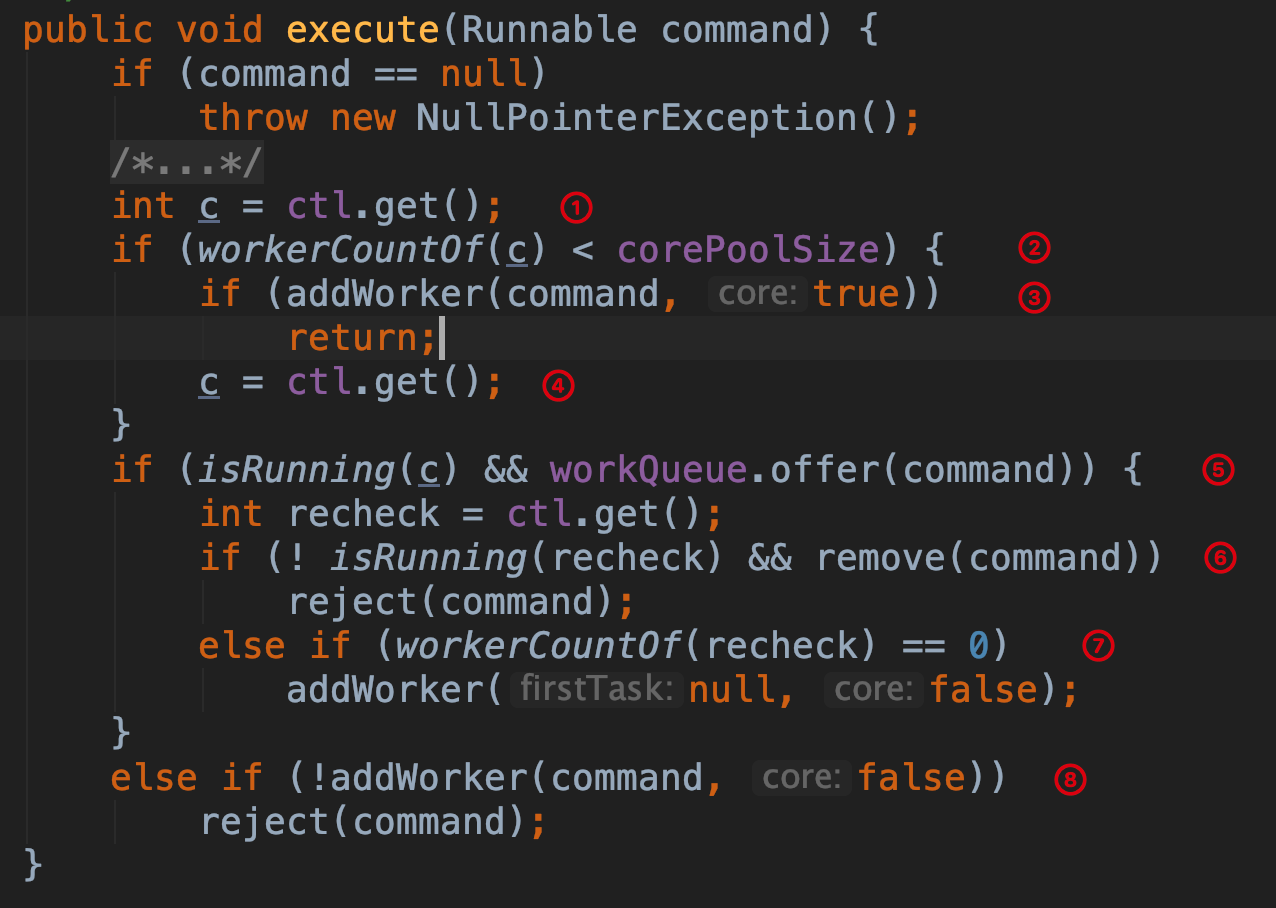
第 ① 步 获取当前的 ctl 值,在上篇 Java 线程池(一) 中说过,变量 ctl 存储了线程池的工作状态 runState 和线程池中正在运行的线程数 workerCount。
第 ② 步 通过 workerCountOf 方法取出线程池中当前正在运行的线程数( ctl 低 29 位的值),如果线程池当前工作线程数小于核心线程数 corePoolSize,则进行第 ③ 步。
第 ③ 步 通过 addWorker 方法新建一个线程加到线程池中,addWorker 方法的第二个参数如果为 true 则限制添加线程的数量是根据 corePoolSize 来判断,反之则根据 maximumPoolSize 来判断,并把任务添加到该线程中。
第 ④ 步 如果添加失败,则重新获取 ctl 的值。
第 ⑤ 步 如果当前线程池的状态是运行状态(state < SHUTDOWN)并且把任务成功添加到队列中。
第 ⑥ 步 重新获取 ctl 的值,再次判断线程池的运行状态,如果不是运行状态,要从队列中移除任务,因为到这一步了,意味着之前已经把任务成功添加到队列中了,所以需要从队列移除。移除成功后调用拒绝策略对任务进行处理,整个 execute 方法结束(PS:为什么不在入队列之前就先判断线程池的状态呢?因为判断一个线程池工作处于运行状态到执行入队列操作这段时间,线程池可能已经被其它线程关闭了,所以提前判断其实毫无意义)。
第 ⑦ 步 通过 workerCountOf 方法取出线程池中当前正在运行的线程数( ctl 低 29 位的值),如果是 0 则执行 addWorker(null, false) 方法,第一个参数传 null 表示只是在线程池中创建一个线程出来,但是没有立即启动,因为我们创建线程池时可能要求核心线程数量为 0。第二个参数为 false 表示限制添加线程时根据 maximumPoolSize 来判断,如果当前线程池中正在运行线程数量大于 0 ,则直接返回,因为在上面第 ⑤ 步已经把任务成功添加到队列 workQueue 中,它会在将来的某个时刻执行到。
第 ⑧ 步 如果执行到这个地方,只有两种情况,一种是线程池的状态已经不是运行状态了,另一种是线程池是运行状态,但是此时线程池的工作线程数大于等于核心线程数(workerCount >= corePoolSize)并且队列 workQueue 已满。这时会再次调用 addWorker 方法,第二个参数传的 false,意味着限制添加线程的数量是根据 maximumPoolSize 来判断的,如果失败则调用拒绝策略对任务进行处理,整个 execute 方法结束。
上面的 execute 方法中多次调用 addWorker,该方法的主要作用就是创建一个线程来执行任务。addWorker 的方法签名如下:
1 |
addWorker(Runnable firstTask, boolean core) |
第一个参数 firstTask 如果不为 null,则创建的线程首先执行 firstTask 任务,然后才会从队列中获取任务,否则会直接从队列中获取任务。第二个参数如果为 true,则表示限制添加线程时根据 corePoolSize 来判断,否则根据maximumPoolSize 来判断。我们看看 addWorker 方法的源码,方法源码如下:
1 |
private boolean addWorker(Runnable firstTask, boolean core) {
|
方法首先获取线程池 ctl 属性的值,该属性包含了线程池的运行状态和工作线程数,通过 runStateOf 获取线程池的运行状态,然后执行下面这个比较复杂的条件判断
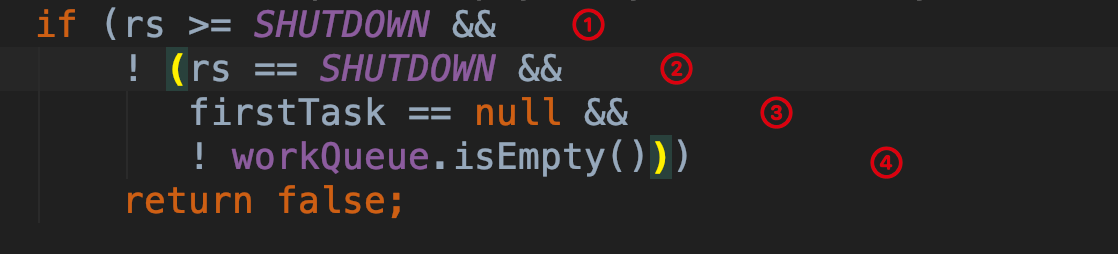
第 ① 个条件表示此时线程池已经不再接受新任务了,接下来的 ②、③、④ 三个判断条件只要有一个不满足,那么方法就会返回 false,方法结束。第 ② 个条件表示线程池为关闭状态,处于关闭状态的线程池不会处理新提交的任务,但会处理完已处理的任务,第 ③ 个条件为 firstTask 为 null,第 ④ 个条件为队列不为空。我们看看如果线程池此时为关闭状态的情况,这种情况线程池不会接受新提交的任务,所以此时如果传入的 firstTask 不为 null,则会直接返回 false;然后如果 firstTask 为 null,并且队列 workQueue 为空,此时也会返回 false,因为此时队列里已经没有任务了,那么也不需要再添加线程了,然后接下来会进入一个循环。
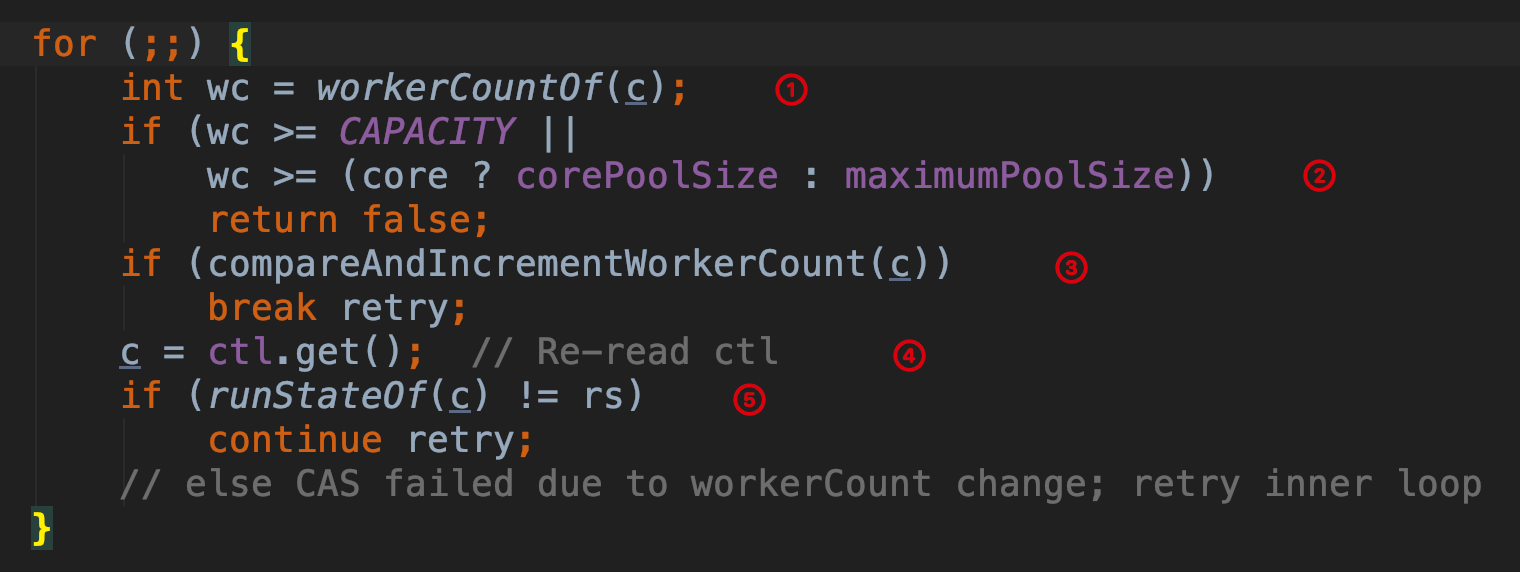
第 ① 步 调用 workerCountOf 方法获取当前线程池的工作线程数
第 ② 步 如果当前线程池的工作数大于 CAPACITY 也就是 ctl 的低 29 位的最大值,则返回 false,如果不大于 CAPACITY,然后根据 core (该方法的第二个参数)来判断是和 corePoolSize 比较还是和 maximumPoolSize 比较,如果比这个值大则返回 false。
第 ③ 步 使用 ctl 的 compareAndSet 原子方法尝试把工作线程数 workerCount + 1,如果增加成功,退出第一层循环。
第 ④ 步 如果增加线程池工作线程数失败,则重新获取 ctl 的值。
第 ⑤ 步 调用 runStateOf 获取线程池的状态,如果不等于方法前面获取的 rs,说明线程池的状态已经改变了,回到第一层循环继续执行。
接下来会启动线程执行任务,源码如下:
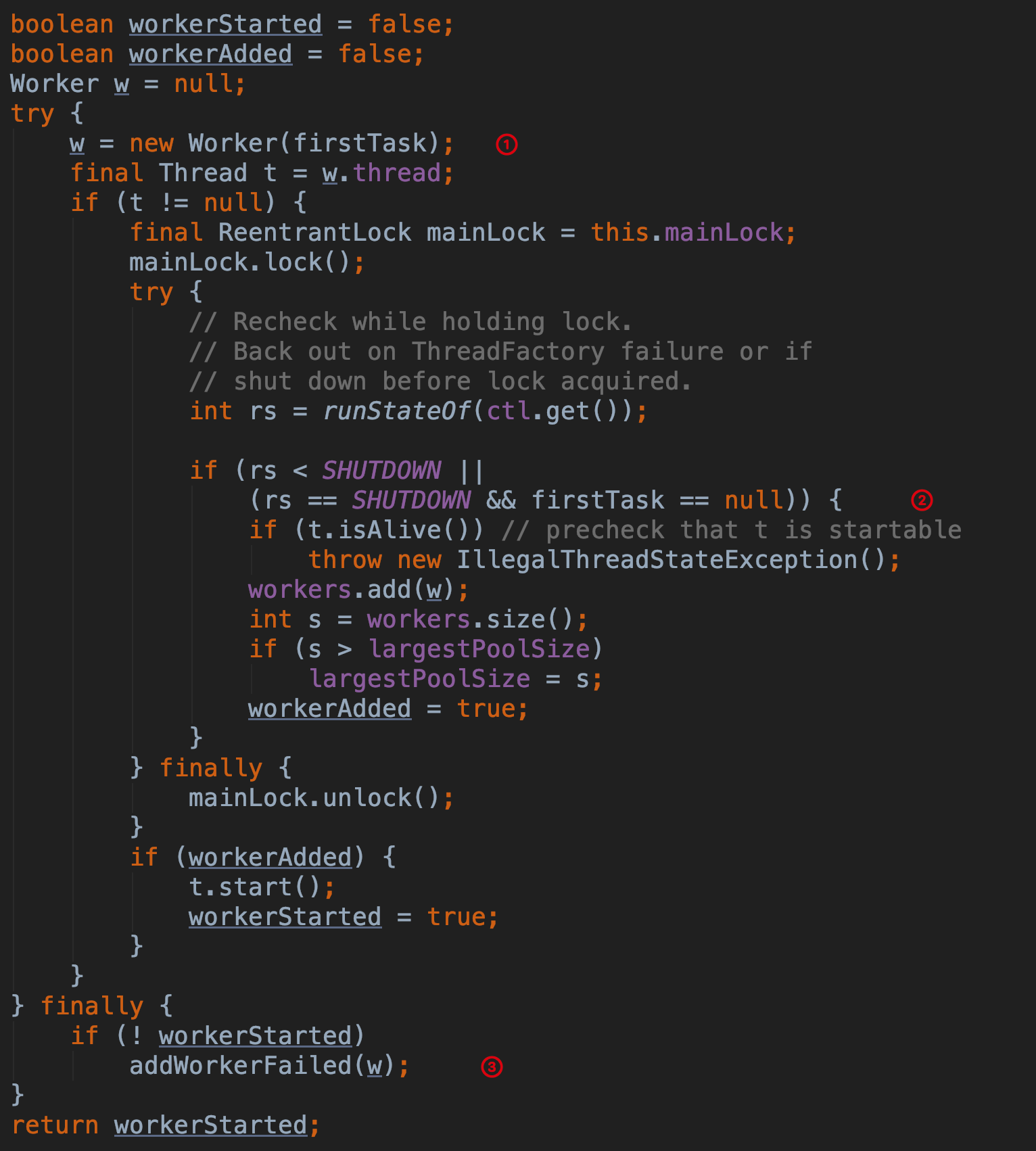
第 ① 步 根据 firstTask 创建 Worker 对象,每一个 Worker 对象都会创建一个线程,然后会使用重入锁 ReentrantLock 进行加锁操作。
第 ② 步 调用 runStateOf 获取线程池的状态,然后进行一个条件判断,第一个 rs < SHUTDOWN 表示线程池是运行状态。如果线程池是运行状态或者线程池是关闭状态并且 firstTask 为 null,那么就往线程池中加入线程(因为当线程池是 SHUTDOWN 状态时不会再向线程池添加新的任务,但会执行队列 workQueue 中的任务)。这里的 workers 是一个 HashSet,所以其 add 方法不是线程安全的,所以需要加锁操作。然后修改线程池中出现过的最大线程数量 largestPoolSize 记录和把是否添加成功标记 workerAdded 为 true。如果 workerAdded 为 true 那么会启动线程并把线程是否启动标记 workerStarted 改为 true。
第 ③ 步 根据线程是否启动 workerStarted 标记来判断是否需要进行失败的操作。包含从 workers 移除当前的 worker、线程池的工作线程数减 1、尝试终端线程池。
线程池中线程是如何执行的
线程池的线程执行是调用 Worker 的 thread 属性的 start 方法,而 thread 的 run 方法实际上调用了 Worker 类的 runWorker 方法,所以我们直接来看看 runWorker 方法的源码:
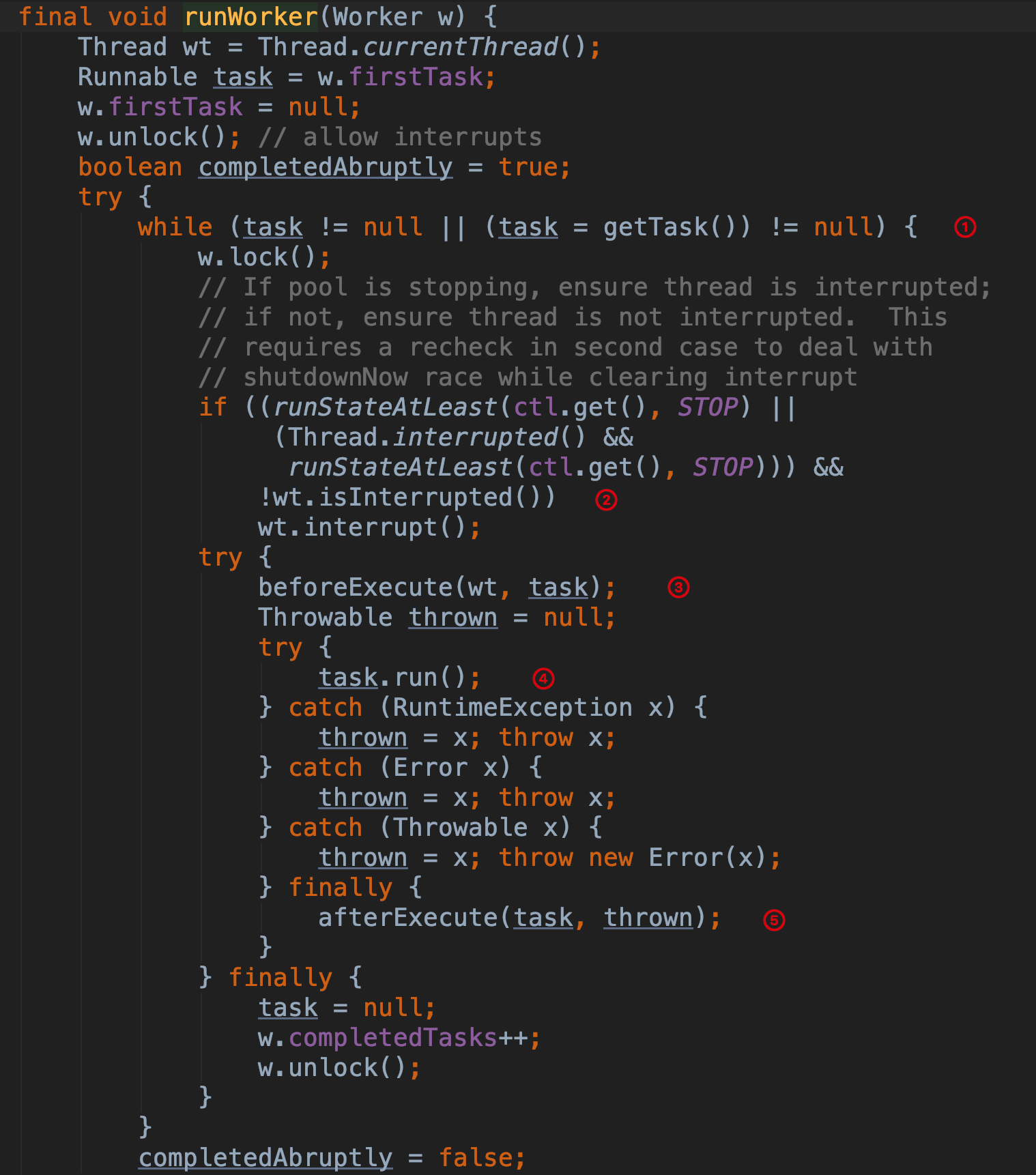
第 ① 步 获取第一个任务,while 循环不断地通过 getTask 方法从队列中获取任务。
第 ② 步 这个判断条件目的是要保证如果线程池正在停止,要保证当前线程是中断状态,如果是的话,要保证当前线程不是终端状态。
第 ③ 步 方法 beforeExecute 方法在类 ThreadPoolExecutor 中没有做任何操作,是留给子类去自定义在线程执行之前添加操作的方法。
第 ④ 步 执行 task.run() 执行任务(PS:这里为什么是调用 run 方法而不是调用 start 方法呢?我们知道当调用了 start 方法后操作系统才会给我们创建一个独立的线程来运行,而调用 run 方法只是一个普通的方法调用,而线程池正好就是需要它是一个普通的方法才能进行任务的调度。我们可以想象一下,假如这里是调用的 Runnable 的 start 方法,那么会是什么结果呢。如果我们往一个核心线程数、最大线程数为 3 的线程池里丢了 500 个任务,那么它会额外的创建 500 个线程,同时每个任务都是异步执行的,结果一下子就执行完毕了,根本无法对任务进行调度。从而没法做到由这 3 个 Worker 线程来调度这 1000 个任务,而只有当做一个普通的 run 方法调用时才能满足线程池的这个要求)。
第 ⑤ 步 方法 afterExecute 方法在类 ThreadPoolExecutor 中没有做任何操作,是留给子类去自定义在线程执行之后添加操作的方法。completedAbruptly 变量是用来表示在执行任务过程中是否出现了异常,processWorkerExit 方法中会对该变量的值进行判断。
接下来我们看看 getTask 方法是如何从队列中获取任务的,方法源码如下:
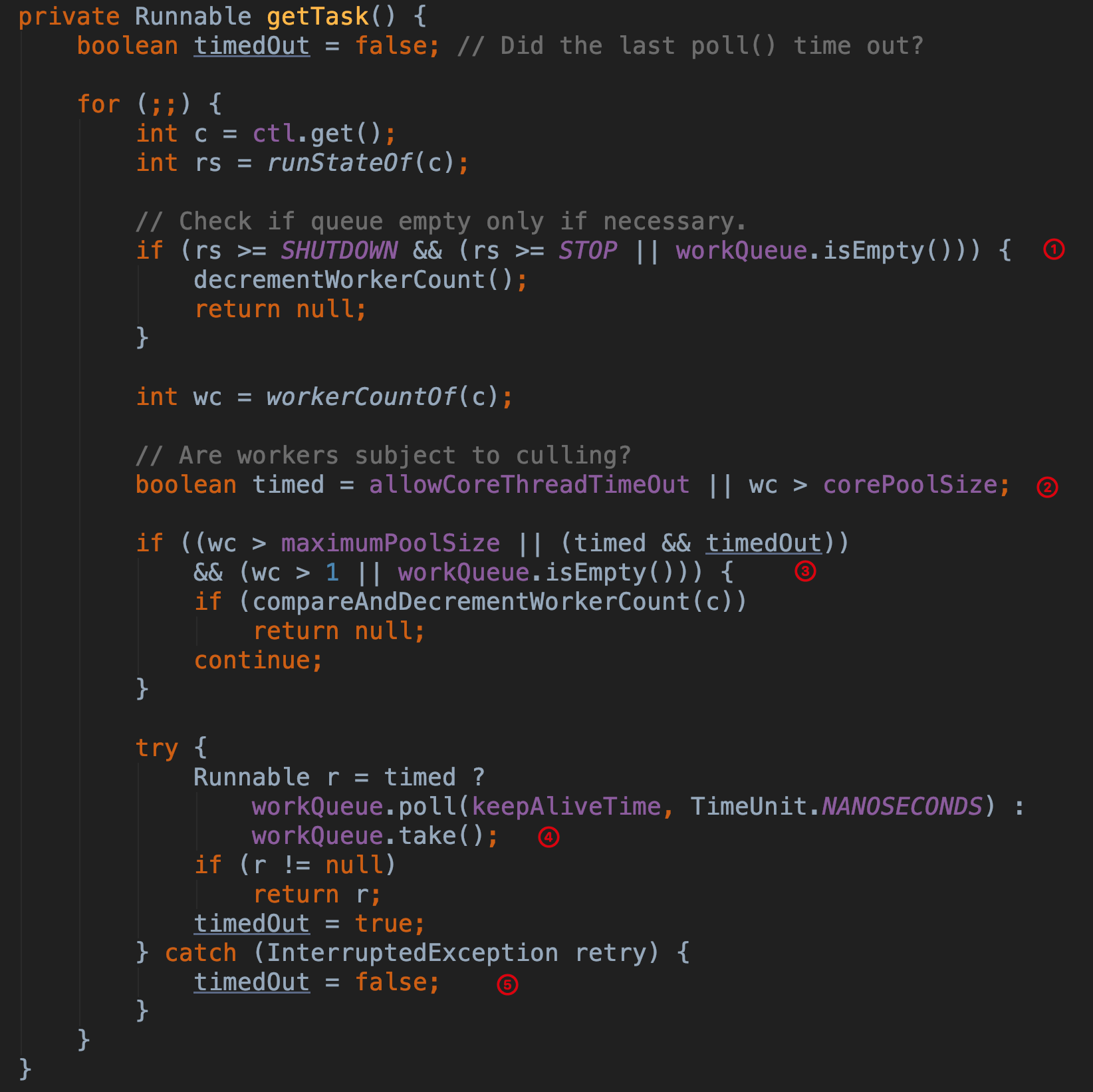
第 ① 步 如果线程池不是运行状态,则判断线程池是否正在停止或者当前队列为空,如果条件满足将线程池的工作线程数减一并返回 null。因为如果当前线程池状态的值是 SHUTDOWN 或以上时,就不允许再向队列中添加任务了。
第 ② 步 这里的 timed 变量用来标记是否需要线程进行超时控制,allowCoreThreadTimeOut 默认是 false,也就是核心线程不允许进行超时。wc > corePoolSize 表示当前线程池中的工作线程数量大于核心线程数量,对于超过核心线程数量的这些线程,需要进行超时控制。
第 ③ 步 第一个判断 wc > maximumPoolSize 如果成立是因为可能在此方法执行阶段同时执行了线程池的 setMaximumPoolSize 方法;第二个判断 timed && timedOut 如果成立表示当前操作需要进行超时控制,并且上次从队列中获取任务发生了超时(timeOut 变量的值表示上次从阻塞队列中取任务时是否超时);第三个判断 wc > 1 || workQueue.isEmpty() 如果线程池中工作线程数量大于 1,或者队列是空的,那么尝试将 workerCount 减一,如果减一失败,则返回重试。如果 wc == 1 时,也就说明当前线程是线程池中唯一的一个线程了。
第 ④ 步 根据 timed 来判断,如果为 true,则通过阻塞队列的 poll 方法进行超时控制,如果在 keepAliveTime 时间内没有获取到任务,则返回 null,否则通过 take 方法,如果这时队列为空,则 take 方法会阻塞直到队列不为空。如果 r == null,说明已经超时,timedOut 设置为 true。
第 ⑤ 步 如果获取任务时当前线程发生了中断,则设置 timedOut 为 false 并重新循环重试。
关闭线程池
线程池的关闭一般都是使用 shutdown 方法和 shutdownNow 方法,两者的区别是前面的 shutdown 方法不会执行新的任务,但是会执行完当前正在执行的任务,而后面的 shutdownNow 方法会立即停止当前线程池,不管当前是否有线程在执行。一般都是使用 shutdown 方法来停止线程池,其方法源码如下:
1 |
public void shutdown() {
|
advanceRunState(SHUTDOWN) 方法的作用是通过 CAS 原子操作将线程池的状态更改为关闭状态。interruptIdleWorkers 方法是对空闲的线程进行中断,其实是调用重载带参数的函数 interruptIdleWorkers(false)。然后 onShutdown 方法和上文提到的 beforeExecute、afterExecute 方法一样,在类 ThreadPoolExecutor 是空实现,也是个钩子函数。我们看看 interruptIdleWorkers 的实现源码:
1 |
private void interruptIdleWorkers(boolean onlyOne) {
|
先进行加锁操作,然后遍历 workers 容器,也就是遍历线程池中的线程,对每个线程进行 tryLock 操作,如果成功说明线程空闲,则设置其中断标志位。而线程是否响应中断则交给我们定义任务的人来决定。
总结
本文比较详细的分析了线程池任务的提交、线程的执行、线程池的关闭的工作流程。通过学习线程池相关的源码后,看到了在其内部用运用了很多多线程的解决方法,有如下几个方式:
- 通过定义重入锁
ReentrantLock变量mainLock来解决并发多线程的安全问题 - 利用等待机制来实现线程之间的通讯问题
除了内置的功能外,ThreadPoolExecutor也向外提供了两个接口供我们自己扩展满足我们需求的线程池,这两个接口分别是:beforeExecute任务执行前执行的方法,afterExecute任务执行结束后执行的方法。
Java 线程池(二)的更多相关文章
- Java线程池二:线程池原理
最近精读Netty源码,读到NioEventLoop部分的时候,发现对Java线程&线程池有些概念还有困惑, 所以深入总结一下 Java线程池一:线程基础 为什么需要使用线程池 Java线程映 ...
- Java线程池使用和分析(二) - execute()原理
相关文章目录: Java线程池使用和分析(一) Java线程池使用和分析(二) - execute()原理 execute()是 java.util.concurrent.Executor接口中唯一的 ...
- java线程池技术(二): 核心ThreadPoolExecutor介绍
版权声明:本文出自汪磊的博客,转载请务必注明出处. Java线程池技术属于比较"古老"而又比较基础的技术了,本篇博客主要作用是个人技术梳理,没什么新玩意. 一.Java线程池技术的 ...
- Java线程池ThreadPoolExecutor使用和分析(二) - execute()原理
相关文章目录: Java线程池ThreadPoolExecutor使用和分析(一) Java线程池ThreadPoolExecutor使用和分析(二) - execute()原理 Java线程池Thr ...
- Java线程池详解(二)
一.前言 在总结了线程池的一些原理及实现细节之后,产出了一篇文章:Java线程池详解(一),后面的(一)是在本文出现之后加上的,而本文就成了(二).因为在写完第一篇关于java线程池的文章之后,越发觉 ...
- Java多线程和并发(十二),Java线程池
目录 1.利用Executors创建线程的五种不同方式 2.为什么要使用线程池 3.Executor的框架 4.J.U.C的三个Executor接口 5.ThreadPoolExecutor 6.线程 ...
- 并发编程(十二)—— Java 线程池 实现原理与源码深度解析 之 submit 方法 (二)
在上一篇<并发编程(十一)—— Java 线程池 实现原理与源码深度解析(一)>中提到了线程池ThreadPoolExecutor的原理以及它的execute方法.这篇文章是接着上一篇文章 ...
- Java线程池使用说明
Java线程池使用说明 转自:http://blog.csdn.net/sd0902/article/details/8395677 一简介 线程的使用在java中占有极其重要的地位,在jdk1.4极 ...
- 四种Java线程池用法解析
本文为大家分析四种Java线程池用法,供大家参考,具体内容如下 http://www.jb51.net/article/81843.htm 1.new Thread的弊端 执行一个异步任务你还只是如下 ...
随机推荐
- Java学生管理系统(IO版)
图解: cade: student.java /* * 这是我的学生类 */ public class Student { //学号 private String id; //姓名 private S ...
- GitHub的学习和使用
大二寒假阶段: 今天初学了GitHub,并下载了git base,在如下大佬给的链接下并完成了新用户的注册以及项目的上传学习. 网站的新用户注册界面: https://g ...
- 题解【[FJOI2018]所罗门王的宝藏】
本题解同步于luogu emmm切了近年省选题来写题解啦qwq 该题较其他省选题较水吧(否则我再怎么做的出来 思路是图论做法,做法上楼上大佬已经讲的很清楚了,我来谈谈代码实现上的一些细节 \[\tex ...
- Flink(四) —— 数据流编程模型
分层抽象 The lowest level abstraction simply offers stateful streaming. It is embedded into the DataStre ...
- Docker部署zookeeper集群和kafka集群,实现互联
本文介绍在单机上通过docker部署zookeeper集群和kafka集群的可操作方案. 0.准备工作 创建zk目录,在该目录下创建生成zookeeper集群和kafka集群的yml文件,以及用于在该 ...
- Python笔记_第四篇_高阶编程_高阶函数_3.sorted
1. sorted函数: 常用的排序分:冒泡排序.选择排序.快速排序.插入排序.计数器排序 实例1:普通排序 # 普通排序 list1 = [,,,,] list2 = sorted(list1) # ...
- Python笔记_第四篇_高阶编程_高阶函数_1.map和reduce
1. map()函数: 原型:map(fn,lsd) 参数1是函数 参数2是序列 功能:将传入的函数一次作用在序列中的每一个元素.并把结果作为一个新的Iterator返回.其实map函数就是一个for ...
- 201512-2 消除类游戏 Java
思路: 用二维数组,对于每一个棋子,向右看三个,向下看三个,如果相等则置为负数,最后遍历输出. import java.util.Scanner; public class Main { public ...
- aws ec2 安装Elastic search 7.2.0 kibana 并配置 hanlp 分词插件
文章大纲 Elastic search & kibana & 分词器 安装 版本控制 下载地址 Elastic search安装 kibana 安装 分词器配置 Elastic sea ...
- Android通过包名打开第三方应用
import android.content.ComponentName; import android.content.Context; import android.content.Intent; ...