损失函数coding
损失函数(Loss Function)和成本函数(Cost Function)之间有什么区别?
在此强调这一点,尽管成本函数和损失函数是同义词并且可以互换使用,但它们是不同的。
损失函数用于单个训练样本。它有时也称为误差函数(error function)。另一方面,成本函数是整个训练数据集的平均损失(average function)。优化策略旨在最小化成本函数。
1.平方误差损失
每个训练样本的平方误差损失(也称为L2 Loss)是实际值和预测值之差的平方:(y-f(x))^2
相应的成本函数是这些平方误差的平均值(MSE)
import numpy as np
def update_weights_MSE(m,X, Y, learning_rate):
m_deriv = 0
b_deriv = 0
N = len(X)
for i in range(N): #所有样本更新的权重
# 计算偏导数为
# -2x(y - (mx + b))
k = Y[i]-np.matmul(m,X[i])
m_deriv += -2*X[i] *k
# -2(y - (mx + b))
b_deriv += -2*(Y[i] - (m*X[i]))
# 我们减去它,因为导数指向最陡的上升方向
#print(m_deriv)
m = m-(m_deriv/N) * learning_rate#所有样本更新权重的均值作为整体的更新
b -= (b_deriv / float(N)) * learning_rate
return m
X = np.array([[1,2],[3,1],[0,3]])
Y = np.array([2,4,7])
m=np.array([2,3])
t = update_weights_MSE(m,X, Y, 0.1)
print(t)
把一个比较大的数平方会使它变得更大。但有一点需要注意,这个属性使MSE成本函数对异常值的健壮性降低。因此,如果我们的数据容易出现许多的异常值,则不应使用这个它。
2.绝对误差损失
L(x)=|y-f(x)| 成本是这些绝对误差的平均值(MAE).
def update_weights_MAE(m, b, X, Y, learning_rate):
m_deriv = 0
b_deriv = 0
N = len(X)
for i in range(N):
#计算偏导数
# -x(y - (mx + b)) 可以分开写
m_deriv += - X[i] * (Y[i] - (m*X[i] + b)) / abs(Y[i] - (m*X[i] + b))
# -(y - (mx + b)) / |mx + b|
b_deriv += -(Y[i] - (m*X[i] + b)) / abs(Y[i] - (m*X[i] + b))
#我们减去它,因为导数指向最陡的上升方向
m -= (m_deriv / float(N)) * learning_rate
b -= (b_deriv / float(N)) * learning_rate
return m, b
3.Huber损失
Huber损失结合了MSE和MAE的最佳特性。对于较小的误差,它是二次的,否则是线性的(对于其梯度也是如此)。Huber损失需要确定δ参数

def update_weights_Huber(m, b, X, Y, delta, learning_rate):
m_deriv = 0
b_deriv = 0
N = len(X)
for i in range(N):
# 小值的二次导数,大值的线性导数
if abs(Y[i] - m*X[i] - b) <= delta:
m_deriv += -X[i] * (Y[i] - (m*X[i] + b))
b_deriv += - (Y[i] - (m*X[i] + b))
else:
m_deriv += delta * X[i] * ((m*X[i] + b) - Y[i]) / abs((m*X[i] + b) - Y[i])
b_deriv += delta * ((m*X[i] + b) - Y[i]) / abs((m*X[i] + b) - Y[i])
#我们减去它,因为导数指向最陡的上升方向
m -= (m_deriv / float(N)) * learning_rate
b -= (b_deriv / float(N)) * learning_rate
return m, b
Huber损失对于异常值比MSE更强。它用于稳健回归(robust regression),M估计法(M-estimator)和可加模型(additive model)。Huber损失的变体也可以用于分类。
二分类损失函数
意义如其名。二分类是指将物品分配到两个类中的一个。该分类基于应用于输入特征向量的规则。二分类的例子例如,根据邮件的主题将电子邮件分类为垃圾邮件或非垃圾邮件。
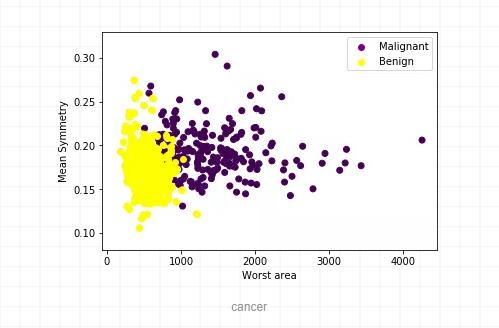
我将在乳腺癌数据集^2上说明这些二分类损失函数。
我们希望根据平均半径,面积,周长等特征将肿瘤分类为"恶性(Malignant)"或"良性(Benign)"。为简化起见,我们将仅使用两个输入特征(X_1和X_2),即"最差区域(worst area)"和"平均对称性(mean symmetry)"用于分类。Y是二值的,为0(恶性)或1(良性)。
1.二元交叉熵损失
让我们从理解术语"熵"开始。通常,我们使用熵来表示无序或不确定性。测量具有概率分布p(X)的随机变量X:
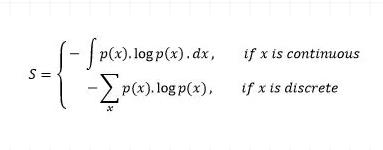
负号用于使最后的结果为正数。
概率分布的熵值越大,表明分布的不确定性越大。同样,一个较小的值代表一个更确定的分布。
这使得二元交叉熵适合作为损失函数(你希望最小化其值)。我们对输出概率p的分类模型使用二元交叉熵损失
元素属于第1类(或正类)的概率=p
元素属于第0类(或负类)的概率=1-p
然后,输出标签y(可以取值0和1)的交叉熵损失和和预测概率p定义为:
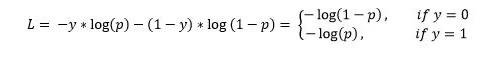
这也称为Log-Loss(对数损失)。为了计算概率p,我们可以使用sigmoid函数。这里,z是我们输入功能的函数
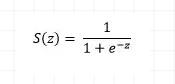
sigmoid函数的范围是[0,1],这使得它适合于计算概率。
def update_weights_BCE(m1, m2, b, X1, X2, Y, learning_rate):
m1_deriv = 0
m2_deriv = 0
b_deriv = 0
N = len(X1)
for i in range(N):
s = 1 / (1 / (1 + math.exp(-m1*X1[i] - m2*X2[i] - b)))
# 计算偏导数
m1_deriv += -X1[i] * (s - Y[i])
m2_deriv += -X2[i] * (s - Y[i])
b_deriv += -(s - Y[i])
# 我们减去它,因为导数指向最陡的上升方向
m1 -= (m1_deriv / float(N)) * learning_rate
m2 -= (m2_deriv / float(N)) * learning_rate
b -= (b_deriv / float(N)) * learning_rate
return m1, m2, b
2.Hinge损失
Hinge损失主要用于带有类标签-1和1的支持向量机(SVM)。因此,请确保将数据集中"恶性"类的标签从0更改为-1。
Hinge损失不仅会惩罚错误的预测,还会惩罚不自信的正确预测
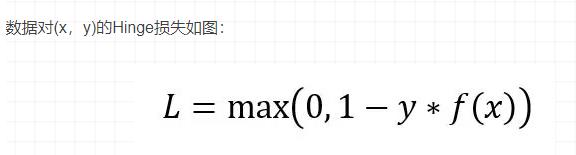
def update_weights_Hinge(m1, m2, b, X1, X2, Y, learning_rate):
m1_deriv = 0
m2_deriv = 0
b_deriv = 0
N = len(X1)
for i in range(N):
# 计算偏导数
if Y[i]*(m1*X1[i] + m2*X2[i] + b) <= 1:
m1_deriv += -X1[i] * Y[i]
m2_deriv += -X2[i] * Y[i]
b_deriv += -Y[i]
# 否则偏导数为0
# 我们减去它,因为导数指向最陡的上升方向
m1 -= (m1_deriv / float(N)) * learning_rate
m2 -= (m2_deriv / float(N)) * learning_rate
b -= (b_deriv / float(N)) * learning_rate
return m1, m2, b
Hinge损失简化了SVM的数学运算,同时最大化了损失(与对数损失(Log-Loss)相比)。当我们想要做实时决策而不是高度关注准确性时,就可以使用它。
多分类损失函数详见softmax
损失函数coding的更多相关文章
- 如何使用 pytorch 实现 yolov3
前言 看了 Yolov3 的论文之后,发现这论文写的真的是很简短,神经网络的具体结构和损失函数的公式都没有给出.所以这里参考了许多前人的博客和代码,下面进入正题. 网络结构 Yolov3 将主干网络换 ...
- 神经网络架构pytorch-MSELoss损失函数
MSELoss损失函数中文名字就是:均方损失函数,公式如下所示: 这里 loss, x, y 的维度是一样的,可以是向量或者矩阵,i 是下标. 很多的 loss 函数都有 size_average 和 ...
- TensorFlow笔记-06-神经网络优化-损失函数,自定义损失函数,交叉熵
TensorFlow笔记-06-神经网络优化-损失函数,自定义损失函数,交叉熵 神经元模型:用数学公式比表示为:f(Σi xi*wi + b), f为激活函数 神经网络 是以神经元为基本单位构成的 激 ...
- 对数损失函数(Logarithmic Loss Function)的原理和 Python 实现
原理 对数损失, 即对数似然损失(Log-likelihood Loss), 也称逻辑斯谛回归损失(Logistic Loss)或交叉熵损失(cross-entropy Loss), 是在概率估计上定 ...
- 从损失函数优化角度:讨论“线性回归(linear regression)”与”线性分类(linear classification)“的联系与区别
1. 主要观点 线性模型是线性回归和线性分类的基础 线性回归和线性分类模型的差异主要在于损失函数形式上,我们可以将其看做是线性模型在多维空间中“不同方向”和“不同位置”的两种表现形式 损失函数是一种优 ...
- Deep Learning-Based Video Coding: A Review and A Case Study
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 1.Abstract: 本文主要介绍的是2015年以来关于深度图像/视频编码的代表性工作,主要可以分为两类:深度编码方案以及基于传统编码方 ...
- 如何优化coding
如何优化coding 前言 最近一直在做修改bug工作,修改bug花费时间最多的不是如何解决问题而是怎样快速读懂代码.如果代码写的好的,不用debug就可以一眼看出来哪里出了问题.实际上,我都要deb ...
- 使用 Code Snippet 简化 Coding
在开发的项目的时候,你是否经常遇到需要重复编写一些类似的代码,比如是否经常会使用 for.foreach ? 在编写这两个循环语句的时候,你是一个字符一个字符敲还是使用 Visual Studio 提 ...
- 数据预处理中归一化(Normalization)与损失函数中正则化(Regularization)解惑
背景:数据挖掘/机器学习中的术语较多,而且我的知识有限.之前一直疑惑正则这个概念.所以写了篇博文梳理下 摘要: 1.正则化(Regularization) 1.1 正则化的目的 1.2 正则化的L1范 ...
随机推荐
- mitmproxy(TLS错误)
一.原来的基础上添加代码 """ This inline script allows conditional TLS Interception based on a us ...
- Django——整体结构/MVT设计模式
MVT设计模式 Models 封装数据库,对数据进行增删改查; Views 进行业务逻辑的处理 Templates 进行前端展示 前端展示看到的是模板 --> 发起 ...
- python-模块安装
首先到这个网址https://www.lfd.uci.edu/~gohlke/pythonlibs/ 找到自己想要用的模块,然后下载下来, 回到桌面找到文件所在位置进入cmd中, pip instal ...
- python常用代码、问题汇总
1.生成dataframe数据 5.读取带 ','分隔符的txt文件 4.DataFrame格式数据处理中报错 2.安装库时出现如下错误: 3.得到股票交易日数据 1.生成dataframe数据 im ...
- 创建简单web项目
Intellij Idea直接安装(可根据需要选择自己设置的安装目录),jdk使用1.6/1.7/1.8都可以,主要是配置好系统环境变量,tomcat7上tomcat的官网下载压缩包解压即可. 一.创 ...
- Vulkan 开发学习资料汇总
开发资料汇总 1.API Reference 2.Vulkan Spec 有详细说明的pdf 文章 1.知乎Vulkan-高性能渲染 2.Life of a triangle - NVIDIA's l ...
- [RoarCTF 2019]Simple Upload
0x00 知识点 1:Think PHP上传默认路径 默认上传路径是/home/index/upload 2:Think PHP upload()多文件上传 think PHP里的upload()函数 ...
- error LNK2005: "void * __cdecl operator new(unsigned int)" (??2@YAPAXI@Z) already defined in LIBCMT
项目--属性 ---连接器---命令行 输入: /FORCE:MULTIPLE 编译环境:VS2012SP3
- offsetof宏与container_of宏
offsetof宏与container_of宏1.由结构体指针进而访问各元素的原理(1)通过结构体整体变量来访问其中各个元素,本质上是通过指针方式来访问的,形式上是通过.的方式来访问的(这个时候其实是 ...
- mysql5.6免安装使用
一.去MYSQL官网下载MYSQL免安装版,由于我的系统是64位的,所以就下载了64位的Mysql版本 http://cdn.mysql.com//Downloads/MySQL-5.6/mysql- ...