python-day5爬虫基础之正则表达式2
dot:
'.'匹配任意的字符
'*'匹配任意多个(0到多个) 如图所示,
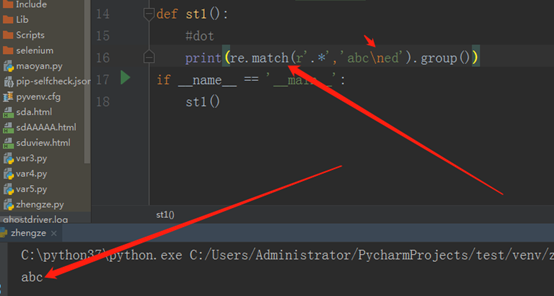
程序运行结果是abc,之所以没有匹配\n,是因为\n是换行符,它就代表这个字符串是两行的,而正则表达式是一行一行去匹配的。在re.match中遇到换行符就默认的认为字符串结束了,所以就不会去匹配下一行的内容,因此输出abc。
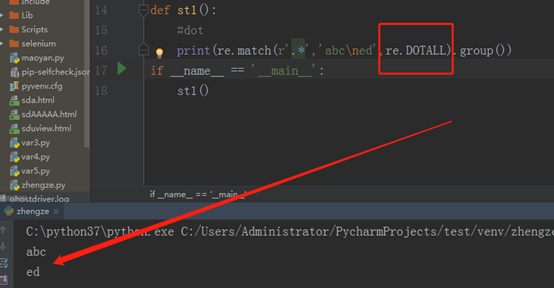
DOTALL:单单表示字符串,还可以表示换行符。这样的话,他就可以匹配整个字符串了。如上所示。
caret:中文意思就是拖字号,shift+6,
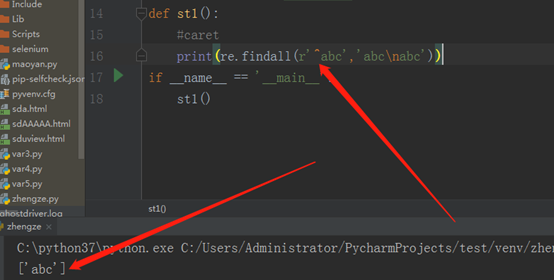
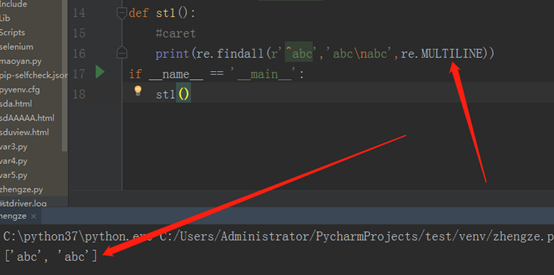
findall,就是找出所有的‘abc’,但是在匹配的时候,我们把它当成一个整体来匹配了,虽然它是两行,其中‘^’表示开始位置,此时如果我们加一个re.MULTILINE,此时这个‘^’就不单单表示字符串的开始了,而是表示行的开始,所以遇到换行符后又是一个新行。程序如下:
‘^’表示字符串的开始,‘$’表示字符串的结束,先看程序:
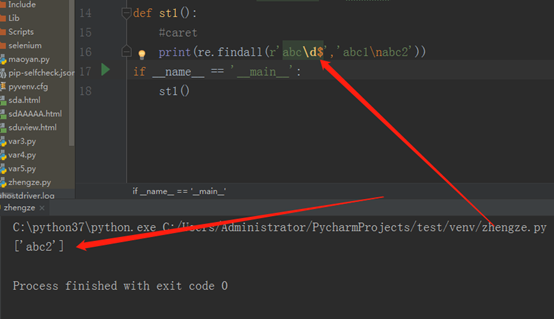
之所以匹配了abc2,没有匹配abc1,是因为在不加任何flag的情况下,‘$’表示的是一个字符串的结束,而不是行的结束,虽然里边有个换行符,但是没有任何的flag。如我我们加上re.MULTILINE,它就代表我们将这个字符串,当成多行来处理,那样的话,运行结果就不得而知了。如下:(\d表示的是数字)
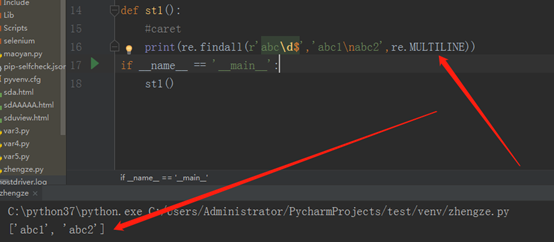
从上可以看出,没有re.MULTILINE就代表字符串的结束,有re.MULTILINE就代表行的结束。
*:前一个匹配单元的匹配次数,匹配0到多个
+:前一个匹配单元的匹配次数,匹配1到多个
?:前一个匹配单元的匹配次数,匹配0到1个
那么 r’ab*’表示的就是匹配1个a,b可以是0个,也可以是多个,看程序:
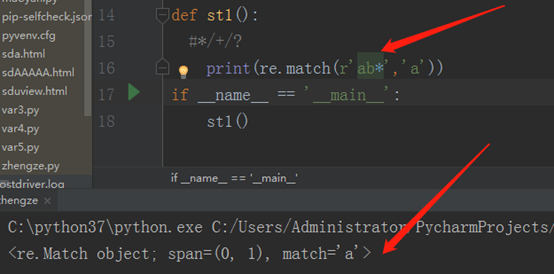
这里补充一下,如果我们在后边再加上group,就可以将匹配结果打印出来了,如下:
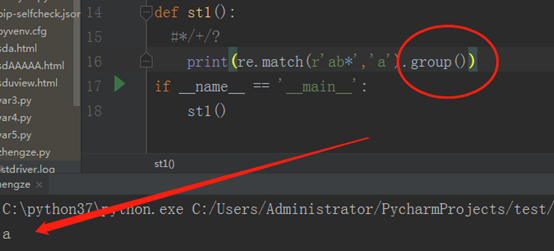
如果我们将*换成+,那就匹配不上了, 那样就代表1个a,b最少是一个,看程序:
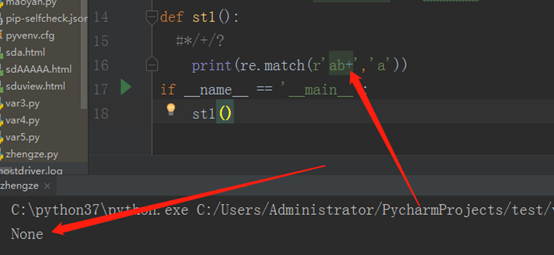
同理,把+换成?,也是可以匹配的。
接下来,在看一看贪婪和非贪婪(greedy/non-greedy)
先看程序:

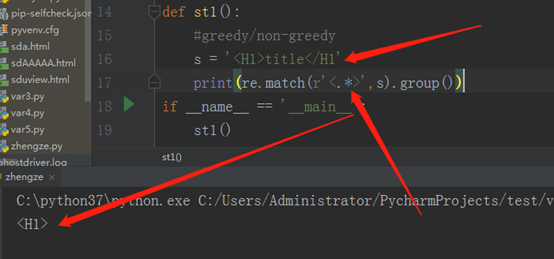
.表示任意字符,*表示0到多个,而这样系统默认是贪婪模式,所以,H 1 > t I t l e < / H 1 全部都当成了任意字符,因为最后边有个>。其实匹配结果是这样的<H1>title</H1>,不知这样写能不能看懂,朋友们。
还有就是如果最后边没有那个‘>’,那么他就认为最后一个’>’是<H1>中的红体部分,运行结果我们也就知道了,如下:
如果此时,我们加一个?,他就变成非贪婪模式,看程序:
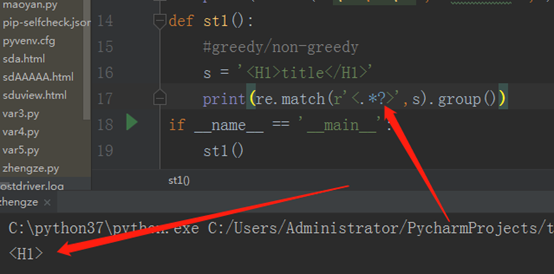
默认的是贪婪模式,要想非贪婪,就要加?
再给大家介绍一个,{m}表示匹配个数,看程序吧
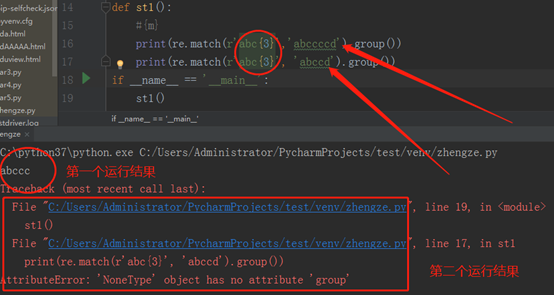
通过上边这个程序,大家应该都看明白了吧,{m}代表的就是匹配的个数,如果个数不够m个,就会报错,如果个数大于m个,就会输出m个结果,多余的也不会输出。再扩展一下,看程序:
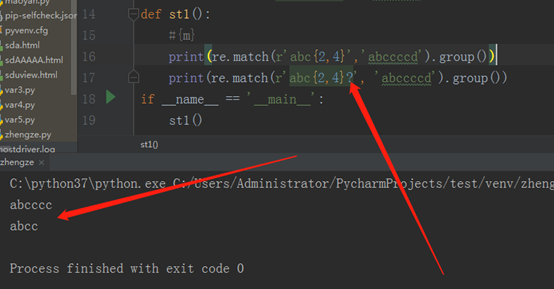
两个输出语句的区别就是一个有问号,一个没有问号,大家应该都明白,带问号的就是非贪婪模式,而{2,4}代表匹配2到4个,贪婪模式下,会匹配多的,也就是4个,非贪婪模式下,会匹配少的,也就是2个。
再看看转义字符’\’,看程序:
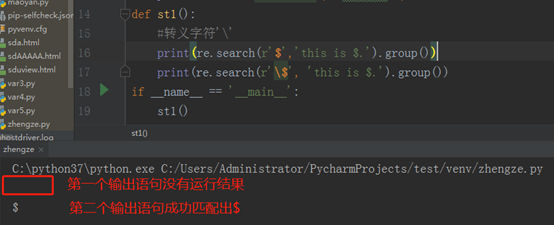
如果不加转义字符‘\’,$就会被系统认为是结束字符,加上之后,就会被当成一个符号来匹配。
最后,再写个[ ],它就代表集合的意思,就是可以匹配集合里边的任意一个,先看程序:
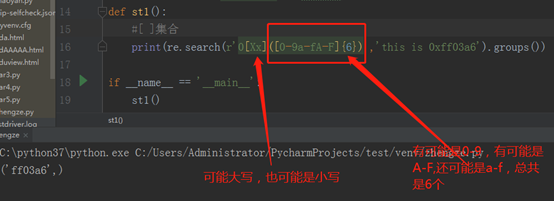
以上就是今天所学,总结的可能有些不是很细,部分内容可能理解有些不对,还请多多指出,大家共同学习,一起进步,谢谢。
python-day5爬虫基础之正则表达式2的更多相关文章
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
- 自学Python六 爬虫基础必不可少的正则
要想做爬虫,不可避免的要用到正则表达式,如果是简单的字符串处理,类似于split,substring等等就足够了,可是涉及到比较复杂的匹配,当然是正则的天下,不过正则好像好烦人的样子,那么如何做呢,熟 ...
- Python BeautifulSoup4 爬虫基础、多线程学习
针对 崔庆才老师 的 https://ssr1.scrape.center 的爬虫基础练习.Threading多线程库.Time库.json库.BeautifulSoup4 爬虫库.py基本语法
- python从爬虫基础到爬取网络小说实例
一.爬虫基础 1.1 requests类 1.1.1 request的7个方法 requests.request() 实例化一个对象,拥有以下方法 requests.get(url, *args) r ...
- Python扫描器-爬虫基础
0x1.基础框架原理 1.1.爬虫基础 爬虫程序主要原理就是模拟浏览器发送请求->下载网页代码->只提取有用的数据->存放于数据库或文件中 1.1.基础原理 1.发起HTTP请求 2 ...
- Python爬虫基础之正则表达式
一.Python正则表达式的基本使用 Python 3 使用re模块可以实现大部分的正则表达式情况. 1.re.compile(pattern, flags=0) re.compile构建匹配规则并返 ...
- Python归纳 | 爬虫基础知识
1. urllib模块库 Urllib是python内置的HTTP请求库,urllib标准库一共包含以下子包: urllib.error 由urllib.request引发的异常类 urllib.pa ...
- python开发模块基础:正则表达式
一,正则表达式 1.字符组:[0-9][a-z][A-Z] 在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示字符分为很多类,比如数字.字母.标点等等.假如你现在要求一个位置&q ...
- python网络爬虫之三re正则表达式模块
""" re正则表达式,正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的 一些特定字符,及这些特定字符的组合,组成一个"规则字符串",然后用 ...
- 自学Python四 爬虫基础知识储备
首先,推荐两个关于python爬虫不错的博客:Python爬虫入门教程专栏 和 Python爬虫学习系列教程 .写的都非常不错,我学习到了很多东西!在此,我就我看到的学到的进行总结一下! 爬虫就是 ...
随机推荐
- Bulma CSS - CSS类
Bulma CSS框架教程 Bulma CSS – 简介 Bulma CSS – 开始 Bulma CSS – CSS类 Bulma CSS – 模块化 Bulma CSS – 响应式 Bulma是一 ...
- vue 父子传值,子页面没有实时刷新的问题
在做高德地图的时候,发现列表点击编辑的时候,地图不能实时更新: <el-form-item label="门店坐标:" :label-width="formLabe ...
- UVA - 10791 Minimum Sum LCM(最小公倍数的最小和)
题意:输入整数n(1<=n<231),求至少两个正整数,使得它们的最小公倍数为n,且这些整数的和最小.输出最小的和. 分析: 1.将n分解为a1p1*a2p2……,每个aipi作为一个单独 ...
- redis性能测试方法
redis本身设计为单线程服务器,性能本身并不随着多核而提高,但是会随着cpu本身而改变,AMD的可能只有Intel一半的性能,Intel是最好的选择. 性能会随着连接数的增多而下降,30000大概只 ...
- PythonTwo
格式化输出: % 占位符 s(str 字符串) d(digit 数字) %% 只单纯显示% Str 索引切片 captlze 首字母大写 upper 全大写 lower 全小写 find 通过元 ...
- java登录以及连接数据库的温习
学完一部分android相关知识点后,为了下周的java测试,我还是反回来重新的学习了上学期的知识点java,在今天打开eclipse之后,对于自己之前自己所写过的东西还有连接数据库的内容,已经有所忘 ...
- CSS - 导入Google Web 字体
@import url('http://fonts.googleapis.com/css?family=Poppins:100,200,300,400,500,600,700,800,900'); b ...
- BZOJ:2242: [SDOI2011]计算器
题解:BSGS 问题:map空间 BSGS判无解 a%p!=0 0与最小非负整数 有区别 函数传参类型转换int->long long long long ->int; 费马小定理充分必要 ...
- 二十四、CI框架之URL辅助函数
一.控制器代码如下: 二.view的显示代码中,关于路径,我们可以用另外一种方法来写, 如: "/CodeIgniter-3.1.10/index.php/welcome/add" ...
- statement 、prepareStatement的用法和解释
转自:http://blog.csdn.net/QH_JAVA/article/details/48245945 一.prepareStatement 的用法和解释 1.PreparedState ...