深夜,我用python爬取了整个斗图网站,不服来斗
QQ、微信斗图总是斗不过,索性直接来爬斗图网,我有整个网站的图,不服来斗。
废话不多说,选取的网站为斗图啦,我们先简单来看一下网站的结构
网页信息

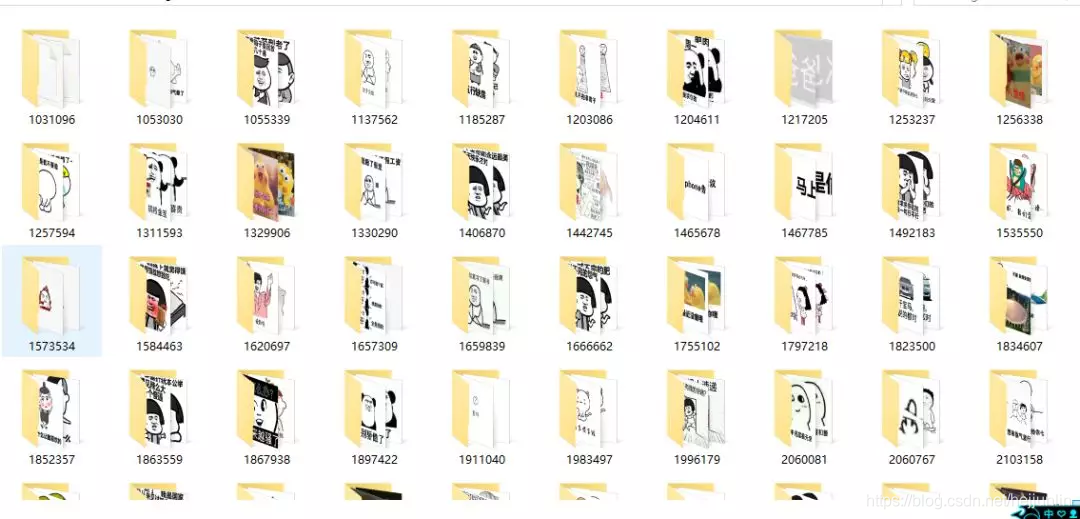
从上面这张图我们可以看出,一页有多套图,这个时候我们就要想怎么把每一套图分开存放(后边具体解释)
通过分析,所有信息在页面中都可以拿到,我们就不考虑异步加载,那么要考虑的就是分页问题了,通过点击不同的页面,很容易看清楚分页规则

很容易明白分页URL的构造,图片链接都在源码中,就不做具体说明了明白了这个之后就可以去写代码抓图片了
存图片的思路
因为要把每一套图存入一个文件夹中(os模块),文件夹的命名我就以每一套图的URL的最后的几位数字命名,然后文件从文件路径分隔出最后一个字段命名,具体看下边的截图。

这些搞明白之后,接下来就是代码了(可以参考我的解析思路,只获取了30页作为测试)全部源码
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import os
class doutuSpider(object):
headers = {
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"}
def get_url(self,url):
data = requests.get(url, headers=self.headers)
soup = BeautifulSoup(data.content,'lxml')
totals = soup.findAll("a", {"class": "list-group-item"})
for one in totals:
sub_url = one.get('href')
global path
path = 'J:\\train\\image'+'\\'+sub_url.split('/')[-1]
os.mkdir(path)
try:
self.get_img_url(sub_url)
except:
pass
def get_img_url(self,url):
data = requests.get(url,headers = self.headers)
soup = BeautifulSoup(data.content, 'lxml')
totals = soup.find_all('div',{'class':'artile_des'})
for one in totals:
img = one.find('img')
try:
sub_url = img.get('src')
except:
pass
finally:
urls = 'http:' + sub_url
try:
self.get_img(urls)
except:
pass
def get_img(self,url):
filename = url.split('/')[-1]
global path
img_path = path+'\\'+filename
img = requests.get(url,headers=self.headers)
try:
with open(img_path,'wb') as f:
f.write(img.content)
except:
pass
def create(self):
for count in range(1, 31):
url = 'https://www.doutula.com/article/list/?page={}'.format(count)
print '开始下载第{}页'.format(count)
self.get_url(url)
if __name__ == '__main__':
doutu = doutuSpider()
doutu.create()
结果

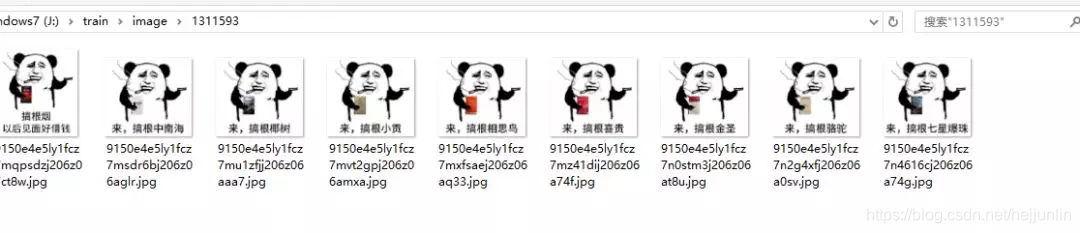
总结
总的来说,这个网站结构相对来说不是很复杂,大家可以参考一下,爬一些有趣的
原创作者:loading_miracle,原文链接:
https://www.jianshu.com/p/88098728aafd

欢迎关注我的微信公众号「码农突围」,分享Python、Java、大数据、机器学习、人工智能等技术,关注码农技术提升•职场突围•思维跃迁,20万+码农成长充电第一站,陪有梦想的你一起成长。
深夜,我用python爬取了整个斗图网站,不服来斗的更多相关文章
- Python 爬取各大代理IP网站(元类封装)
import requests from pyquery import PyQuery as pq base_headers = { 'User-Agent': 'Mozilla/5.0 (Windo ...
- Python 爬取所有51VOA网站的Learn a words文本及mp3音频
Python 爬取所有51VOA网站的Learn a words文本及mp3音频 #!/usr/bin/env python # -*- coding: utf-8 -*- #Python 爬取所有5 ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- python爬取某个网页的图片-如百度贴吧
python爬取某个网页的图片-如百度贴吧 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用告诉我 #coding:utf-8 import urllib imp ...
- Python:爬取乌云厂商列表,使用BeautifulSoup解析
在SSS论坛看到有人写的Python爬取乌云厂商,想练一下手,就照着重新写了一遍 原帖:http://bbs.sssie.com/thread-965-1-1.html #coding:utf- im ...
- 使用python爬取MedSci上的期刊信息
使用python爬取medsci上的期刊信息,通过设定条件,然后获取相应的期刊的的影响因子排名,期刊名称,英文全称和影响因子.主要过程如下: 首先,通过分析网站http://www.medsci.cn ...
- python爬取免费优质IP归属地查询接口
python爬取免费优质IP归属地查询接口 具体不表,我今天要做的工作就是: 需要将数据库中大量ip查询出起归属地 刚开始感觉好简单啊,毕竟只需要从百度找个免费接口然后来个python脚本跑一晚上就o ...
- Python爬取豆瓣指定书籍的短评
Python爬取豆瓣指定书籍的短评 #!/usr/bin/python # coding=utf-8 import re import sys import time import random im ...
- python爬取网页的通用代码框架
python爬取网页的通用代码框架: def getHTMLText(url):#参数code缺省值为‘utf-8’(编码方式) try: r=requests.get(url,timeout=30) ...
随机推荐
- js new 与 return
前置: 默认情况下, 函数的返回值是 undefined (即没有定义返回值). new 操作符 js 中的 new 操作符,可以是我们像 java 一样,获得一个新的对象,例如: function ...
- response 画验证码
代码 import java.awt.Color; import java.awt.Font; import java.awt.Graphics2D; import java.awt.image.Bu ...
- 初等数论-Base-1(筛法求素数,欧拉函数,欧几里得算法)
前言 初等数论在OI中应用的基础部分,同机房的AuSquare和zhou2003君早就写完了,一直划水偷懒的Hk-pls表示很方,这才开始了这篇博客. \(P.S.\)可能会分部分发表. Base-1 ...
- 吴裕雄--天生自然 python数据分析:基于Keras使用CNN神经网络处理手写数据集
import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib.image as mp ...
- TCP并发、GIL全局锁、多线程讨论
TCP实现并发 #client客户端 import socket client = socket.socket() client.connect(('127.0.0.1',8080)) while T ...
- Python---1基础介绍
因公司有自动化测试需求,开始自学python,跟着廖雪峰老师的教程,一边学习,一遍记笔记,将学习过程中,遇到的大大小小奇奇怪怪的问题,记录与此. 一.安装 Python是跨平台的,它可以运行在Wind ...
- OAuth 2.0学习笔记
文章目录 OAuth的作用就是让"客户端"安全可控地获取"用户"的授权,与"服务商提供商"进行互动. OAuth在"客户端&quo ...
- Dykin's blog
回归分析是一种很重要的预测建模技术.主要是研究自变量与因变量之间的因果关系.本文将会从数学角度与代码角度分析不同类型的回归.当你想预测连续型的非独立变量,或者对一系列独立变量或输入项有所反应时,就会使 ...
- SolrJ 的运用
SolrJ 是操作 Solr 的 Java 客户端,它提供了增加.修改.删除.查询 Solr 索引的 Java 接口.SolrJ 针对 Solr 提供了 REST 的 Http 接口进行了封装, So ...
- SAT考试里最难的数学题? · 三只猫的温暖
问题 今天无意中在Quora上看到有人贴出来一道号称是SAT里最难的一道数学题,一下子勾起了我的兴趣.于是拿起笔来写写画画,花了差不多十五分钟搞定.觉得有点意思,决定把解题过程记下来.原帖的图太小,我 ...