[C++]那些年被虐的STL
首先很感谢**P1135奇怪的电梯
**【2.14补充:此题已被AC!然后将被我花式虐[From语]哈哈哈哈哈哈哈哈哈哈好嗨哟感觉人生已经到达了巅峰感觉人生已经到达了高潮】这道题了!在做这道题的我大致就是下图qwq:
dfs—>sp—>bfs—>stl
于是小蒟蒻准备写一篇博客整理一下STL库啦!
祭出大佬@From 廿八——初六每日更新
目录:
vector
封装数组
#### 向量(vector) 连续存储的元素<vector>
set
封装二叉树【集合】
集合(set) 由节点组成的红黑树,每个节点都包含着一个元素,节点之间以某种作用于元素对的谓词排列,没有两个不同的元素能够拥有相同的次序
queue
队列(queue)【包括优先队列priority_queue】 先进先出的值的排列
stack
栈(stack) 后进先出的值的排列
map
封装二叉树
映射(map) 由{键,值}对组成的集合,以某种作用于键对上的谓词排列
algorithm?lower_bound?upper_bound?【待定】
VECTOR
参考:
解释:
进化的动态数组:不用考虑会不会浪费内存或者越界
特点:
==可分配拓展的数组。随机访问快,在中间插入和删除慢,末端插入和删除快
vector可以分为STL方式和类数组方式,由于本蒟蒻太水了然后先重点讲类数组方式呐【STL方式看懂了再补上呐】
然而这些和实际操作并没有什么关系!完全可以当数组用呐!
用法
头文件
#include<vector>
定义方式
vector<int>v1;//vector元素为int型
vector<node>v2;//自定义结构体
vector<int>v3(a,b)//声明一个初始大小为a且初始值都为b的向量
//【向量:一个存放数据的地方,类似于一维数组和链表】
vector<int>::iterator it;//定义一个迭代器
/*【迭代器:in a word 是一个复杂的指针,
通过“*”,“++”,“==”,“!=”,“=”遍历数组,
开氧气优化会很快很快(set,map只能用迭代器遍历)。如iter==a.end()】*/
常规操作
vector<int>v1;
v1.push_back() /*在数组的最后添加一个数据*/
v1.pop_back() /*去掉数组的最后一个数据 */
v1.front() /*返回第一个元素(栈顶元素)*/
v1.begin() /*得到数组头的指针,用迭代器接受*/
v1.end() /*得到数组的最后一个单元+1的指针,用迭代器接受*/
v1.clear() /* 移除容器中所有数据*/
v1.empty() /*判断容器是否为空*/
v1.erase(pos) /*删除pos位置的数据【慢】*/
v1.erase(beg,end) /* 删除[beg,end)区间的数据【慢】*/
/*考虑到erase过慢所以尽量不要用erase*/
v1.size() /*返回容器中实际数据的个数*/
v1.insert(pos,data)/*在pos处插入数据【data:要插入的数】*/
for(int i=0;i<int(v1.size());++i) /*循环遍历【不这么写会发出橙红色的警告√】*/
栗子
P1540 机器翻译
用vector模拟队列√
#include<bits/stdc++.h>
using namespace std;
int M,N,ans;
vector<int>dic;
vector<int>text;
int main(){
cin>>M>>N;
int cinn;
for(int i=1;i<=N;i++){
cin>>cinn;
text.push_back(cinn);}
for(int i=0;i<int(text.size());++i){
bool flag=false;
for(int j=0;j<int(dic.size());++j)
if(text[i]==dic[j]) flag=true;
if(!flag){
if(int(dic.size())-1<M-1){
dic.push_back(text[i]);
ans++;}
else{
dic.push_back(text[i]);
for(int j=0;j<int(dic.size())-1;++j)
dic[j]=dic[j+1];
dic.pop_back();
ans++;}}}
cout<<ans;
return 0;
}
【vector暂且告一段落,等到所有都整好之后再来做批注和修改呐】
SET
前面der补充:
今天From大佬向小蒟蒻介绍了一个特别神奇的东西——修改语言标准!
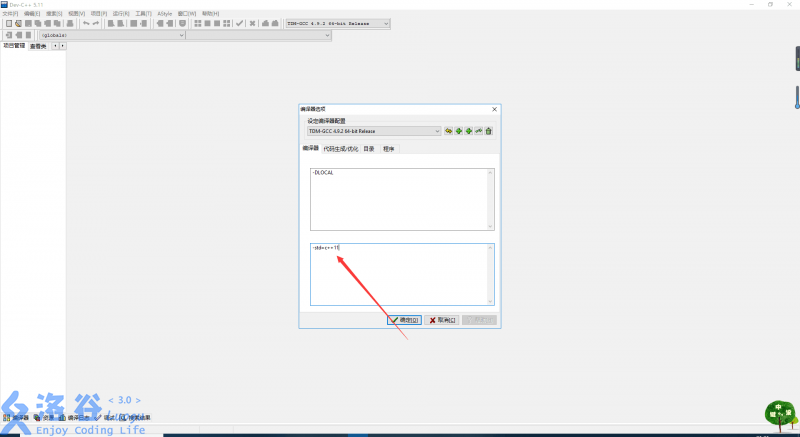
工具—>编译选项—>在连接器命令行加入以下命令—>语言标准
【图片中为“-std=c++11”】
是不是觉得在哪里见到过?没错就是这里!
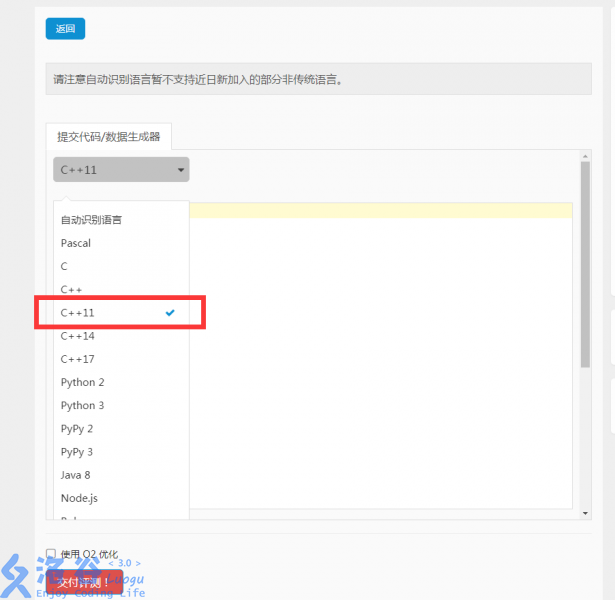
From:“这样改之后就会舒服很多啦!比如:
迭代器可以直接用auto 定义
遍历vector可以这样:
vector<int> s
for (auto it : s)
虽然说还不是很会用8但是以后可以慢慢用起来呢!明明就是你蠢qwq
好啦下面正式进入set!
参考
C++set容器
这篇真的超级超级详细emmm唯一不足的地方就是讲得有点深奥不好理解set—常见成员函数及基本用法
这篇也很好哒!
解释
set是用红黑树【很高级的东西,emmm有兴趣请百度】的一种高级数据结构,可以类比于数学中的集合。
“除了没有单独的键,set 容器和 map 容器很相似。定义 set 的模板有 4 种,其中两种默认使用 less 来对元素排序,另外两种使用哈希值来保存元素。有序 set 的模板定义在 set 头文件中。无序 set 的模板定义在 unordered_set 头文件中。因此有序 set 包含的元素必须支持比较运算,无序 set 中的元素必须支持哈希运算。”
真好又发现一个不会的了——哈希
特点
- 集合,最大的特点就是其中的元素不能重复,所以用set的时候可以判断元素是否重复再进入【此特点在下面的例题中可以充分显示】。
- set中的元素都是排好序的
用法
头文件
#include<set>
所以STL里的头文件都是有规律的8
定义方式
同vector
set<node>s
set<int>::iterator it;
set不能用下角标遍历,所以每次都要写迭代器
当set集合中的元素为结构体时,该结构体必须实现运算符‘<’的重载???【没懂】
常规操作
set<int> s;
s.begin(); //返回set容器的第一个元素
s.end(); //返回set容器的最后一个元素
s.clear(); //删除set容器中的所有的元素
s.empty(); //判断set容器是否为空
s.max_size(); //返回set容器可能包含的元素最大个数
s.size(); //返回当前set容器中的元素个数
s.rbegin(); //返回的值和end()相同
s.rend(); //返回的值和rbegin()相同
s.find(); //返回一个指向被查找到元素的迭代器
s.insert(); //在集合中插入元素
添加,删除,插入
由于c++11还是没能很适应,暂且看不懂里面的代码emmm
添加,删除,插入
栗子
P4305不重复数字
//快读吸氧必选其一
#include<bits/stdc++.h>
using namespace std;
int T,N;
long long num;
set<long long> s;
vector<long long> v;
int main(){
cin>>T;
while(T--){
v.clear();
s.clear();
scanf("%d",&N);
for(int j=1;j<=N;++j){
cin>>num;
if(s.find(num)==s.end()){
v.push_back(num);
s.insert(num);}
}
for(int j=0;j<int(v.size());++j)
cout<<v[j]<<" ";
cout<<endl;
}
return 0;
}
MAP
Ps:由于map和set很像所以先将map提上来讲呐 明明是From大佬发烧穿越了好8
参考
解释
顾名思义,给你张地图去查找。map的主要用处也就是查找。同时也是一个集合,即和set一样,每个元素只能在集合中出现一次。并且根据key在内部自动排序【应该是为了查找方便吧emmm】
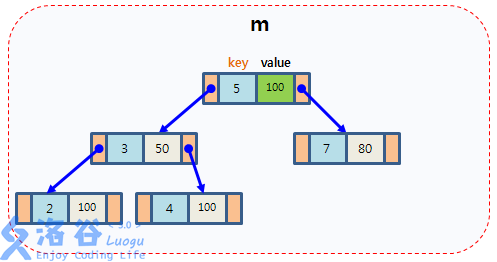
map是STL的一个关联容器,它提供一对一的hash。[所以hash有什么用emmm]
map中通常需要pair:
第一个可以称为关键字(key),每个关键字只能在map中出现一次;
第二个可能称为该关键字的值(value);
类比一下,就像你的学号与你的名字对应一样。
用法
定义方式
map<node,node> m;
map<node1,node2>::iterator iter;//node1为索引,node2为相关联的指针
头文件
#include<map>
常规操作
map<int, string> m;
m.begin() //返回指向map头部的迭代器
m.clear() //删除所有元素
m.count() //返回指定元素出现的次数
m.empty() //如果map为空则返回true
m.end() //返回指向map末尾的迭代器
m.equal_range() //返回特殊条目的迭代器对
m.erase() //删除一个元素
m.find() //查找一个元素
m.get_allocator() //返回map的配置器
m.insert() //插入元素
m.key_comp() //返回比较元素key的函数
m.lower_bound() //返回键值>=给定元素的第一个位置
m.max_size() //返回可以容纳的最大元素个数
m.rbegin() //返回一个指向map尾部的逆向迭代器
m.rend() //返回一个指向map头部的逆向迭代器
m.size() //返回map中元素的个数
m.swap() //交换两个map
m.upper_bound() //返回键值>给定元素的第一个位置
m.value_comp() //返回比较元素value的函数
for(iter = m.begin(); iter != mapStudent.end(); iter++)
//前项遍历map
```
其中的插入元素的方法有三种【emmm三种对我来说都还有问题】
```cpp
map<int, string> mapStudent;
// 第一种 用insert函數插入pair【那是不是又得定义一个pair啦?】
mapStudent.insert(pair<int, string>(000, "student_zero"));
// 第二种 用insert函数插入value_type数据【基本不用】
mapStudent.insert(map<int, string>::value_type(001, "student_one"));
// 第三种 用"array"方式插入【咳咳array是Java里的数组的名称,类似于vector】
mapStudent[123] = "student_first";
mapStudent[456] = "student_second";
//insert和数组的插入的区别在于,insert的时候如果以前有这个值,那么插入不了;而数组可以覆盖掉这个值
然后是map的查找功能啦
用count判断关键字是否出现。【因为集合的特性,所以只能返回0或1】
用迭代器接收 find() 寻找到的东西。通过map对象的方法获取的iterator数据类型是一个std::pair对象,包括两个数据 iterator->first和 iterator->second分别代表关键字和存储的数据。
lower_bound函数用法,这个函数用来返回要查找关键字的下界(是一个迭代器)
upper_bound函数用法,这个函数用来返回要查找关键字的上界(是一个迭代器)
例如:map中已经插入了1,2,3,4的话,如果lower_bound(2)的话,返回的2,而upper-bound(2)的话,返回的就是3
栗子
#include<iostream>
#include<map>
#include<string>
using namespace std;
int n;
string str;
int main(){
map<string,int> m;
while(cin>>n,n!=0){
string ans;
int maxn=-1;
m.clear();
while(n--){
cin>>str;
m[str]++;
if(m[str]>maxn){
maxn=m[str];
ans=str;
}
}
cout<<ans<<endl;
}
return 0;
}
备注
map不能用sort!
STACK
参考
解释
先进后出,注意与队列区分,不多加解释了
用法
由于和From大佬聊得太久再加上我想睡觉后者是主要原因,所以用法合在一起写辽
#include<stack>//头文件
stack<int> s;//定义
//stack没有迭代器,queue也是
s.push();//入栈
s.pop();//出栈
s.top();//访问栈顶
s.empty();//判断栈是否为空
s.size();//返回栈中的元素个数
【下面是stack的用法图解,内含deque】
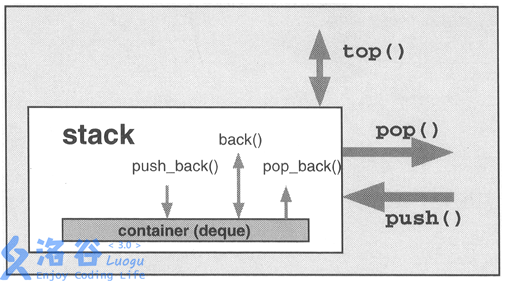
栗子
2.14补充
常用库函数
include
//因为bits库包含的东西过多,所以编译时间会比较长(yxc:肉眼可见的慢)
- sort [不稳定排序]
//扩充成pair【a[i]=>pair<int,int>】可以手动稳定
//两个vector可以进行sort排序比较。sort很厉害的呢!【sort不只是快速排序,是一堆排序一起的】
stable_sort [稳定排序]
min/max [只要支持小于号的东西都可以使用]
//if语句先判断,问号表达式先把?后面的算出来再判断?前面的东西。【可能编译器已经优化过了emmm】
//*1ll long long 类型常量1
swap [交换函数]
reverse [sort倒转]
erase [删除一段数组,经常和下面的unique函数一起用于离散化]
//a.erase(unique(a.begin(),a.end()),a.end()) 离散化去重复
unique [见上]
nth_element [快选,第k个大的数是什么,时间复杂度为O(n),内部实现方式和快排差不多,具体不知道emmm]
memset [初始化,0x3f大于10^9]
memcpy??????????
vector
vector<int> b{1,2,3,4};
//vector存图,如邻接表(???)
//两个vector可以按字典序排序
string
string a,b,c;
a.size();
a.length();//返回长度
a=b+c;
a+="xqy";
a+='s';
a+='d';
a="8*ying is my wife";
cout<<a.substr(0,6);//输出为8*ying
//printf不能直接输出string【string是个指针,乱码】,但是后面加一个东西c_*******???可以输出
strstr();//是否存在一个子串
set
set<int >s;
multiset<int>;
//其中的erase很神奇会把所有的***都删掉???????
//内部是个红黑树/平衡树,很长很长emmm
if(s.count(x))
auto i=s.lower_bound(x);//返回大于x的最小值
auto j=s.upper_bound(x);//返回大于等于x的最小数
map
//如果map里的位置没东西就会返回理想值,如int会返回0,string会返回""
for(auto item:M)//遍历
queue
q.push(x);
q.front();
q.pop();
q.empty();
//...没抄完就被删了
priority_queue
priority_queue<int> heap;
//时间复杂度和二叉堆一样,但常数较大
pair
pair<int,int> pair[N];
pair<int,pair<int,vector<map<pair<int,int>,set>>>>//咳咳可能对应不上,pair真是个好东西
//比较函数特别好用,先比较第一个再比较第二个,而struct需要再重载一个比较函数
unordered_set
哈希表
insert
count
size
empty
heap
[C++]那些年被虐的STL的更多相关文章
- 2016 ECJTU - STL
1.ECJTU-STL重挂 STL 2.总结:学长出的题,本来还想ak的,结果又被虐了... 3.标程和数据:http://pan.baidu.com/s/1qYzXY2K 01 水 02 水 ...
- 详细解说 STL 排序(Sort)
0 前言: STL,为什么你必须掌握 对于程序员来说,数据结构是必修的一门课.从查找到排序,从链表到二叉树,几乎所有的算法和原理都需要理解,理解不了也要死记硬背下来.幸运的是这些理论都已经比较成熟,算 ...
- STL标准模板库(简介)
标准模板库(STL,Standard Template Library)是C++标准库的重要组成部分,包含了诸多在计算机科学领域里所常见的基本数据结构和基本算法,为广大C++程序员提供了一个可扩展的应 ...
- STL的std::find和std::find_if
std::find是用来查找容器元素算法,但是它只能查找容器元素为基本数据类型,如果想要查找类类型,应该使用find_if. 小例子: #include "stdafx.h" #i ...
- STL: unordered_map 自定义键值使用
使用Windows下 RECT 类型做unordered_map 键值 1. Hash 函数 计算自定义类型的hash值. struct hash_RECT { size_t operator()(c ...
- C++ STL简述
前言 最近要找工作,免不得要有一番笔试,今年好像突然就都流行在线笔试了,真是搞的我一塌糊涂.有的公司呢,不支持Python,Java我也不会,C有些数据结构又有些复杂,所以是时候把STL再看一遍了-不 ...
- codevs 1285 二叉查找树STL基本用法
C++STL库的set就是一个二叉查找树,并且支持结构体. 在写结构体式的二叉查找树时,需要在结构体里面定义操作符 < ,因为需要比较. set经常会用到迭代器,这里说明一下迭代器:可以类似的把 ...
- STL bind1st bind2nd详解
STL bind1st bind2nd详解 先不要被吓到,其实这两个配接器很简单.首先,他们都在头文件<functional>中定义.其次,bind就是绑定的意思,而1st就代表fir ...
- STL sort 函数实现详解
作者:fengcc 原创作品 转载请注明出处 前几天阿里电话一面,被问到STL中sort函数的实现.以前没有仔细探究过,听人说是快速排序,于是回答说用快速排序实现的,但听电话另一端面试官的声音,感觉不 ...
随机推荐
- Spring返回jsp页面
1.SpringMVC返回的jsp,需要配置相应的viewResolvers,如: <property name="viewResolvers"> <list&g ...
- JavaScript对象的几种创建方式与优缺点
JavaScript中常见的几种创建对象的方式有:Object构造函数模式.对象字面量模式.工厂模式.自定义构造函数模式.构造函数加原型组合模式:他们各自有各自的优缺点和使用场景. 1. Object ...
- 2018年宜賓美酒文化節浮空投影舞美特效 / 2018 Yibing Wine Festival Visual Effect Projection
客户 Client:五粮液集团 硬件 Hardware:PC,巴可投影机30,000流明*2 Barco projector 30,000 lumen*2 软件 Software:Resolume, ...
- OpenSSL编程之摘要
说明: 数字摘要是将任意长度的消息变成固定长度的短消息,它类似于一个自变量是消息的函数,也就是Hash函数.数字摘要就是采用单向Hash函数将需要加密的明文“摘要”成一串固定长度(128位)的密文这一 ...
- linux记录每次登陆的历史命令
编辑/etc/profile,增加如下代码 #Record history operation USER_IP=`>/dev/null |awk '{print $NF}' |sed -e 's ...
- 一月七笔千万美元投资!国内VR行业在刮什么风?
虽然直到现在仍然没有一款真正能够彻底普及并改变大众操控方式的虚拟现实设备出现,但其已经被认定是未来人类社会中不可或缺的重要组成部分和工作.生活.娱乐.休闲载体.而虚拟现实设备.内容在今年年初CES展会 ...
- iPhone7会点燃苹果内战吗?
苹果第十代手机产品iPhone7或者叫iPhone6 SE注定是设计上的平庸之作,与之前的产品相比,这两款产品只是进行了小幅度地升级,对于一些需要靠苹果logo标榜身份的人来说,几乎是没有吸引力的 ...
- TCP可靠传输的工作原理
TCP可靠传输的工作原理 一.停止等待协议 1.1.简介 在发送完一个分组后,必须暂时保留已发送的分组的副本. 分组和确认分组都必须进行编号. 超时计时器的重传时间应当比数据在分组传输的平均往返时间更 ...
- 编写一个可复用的SpringBoot应用运维脚本
前提 作为Java开发者,很多场景下会使用SpringBoot开发Web应用,目前微服务主流SpringCloud全家桶也是基于SpringBoot搭建的.SpringBoot应用部署到服务器上,需要 ...
- Spring Boot 2.x基础教程:使用MyBatis访问MySQL
之前我们已经介绍了两种在Spring Boot中访问关系型数据库的方式: 使用spring-boot-starter-jdbc 使用spring-boot-starter-data-jpa 虽然Spr ...