python爬虫(七) mozillacookiejar
MozillaCookiejar
保存百度得Cookiejar信息:
from urllib import request
from urllib import parse
from http.cookiejar import MozillaCookieJar # 保存在本地
cookiejar=MozillaCookieJar('cookie.txt')
handler=request.HTTPCookieProcessor(cookiejar)
opener=request.build_opener(handler) # 打开百度,此时已将信息保存在了cookiejar中
resp=opener.open('http://www.baidu.com/') # 下载在本地
cookiejar.save()

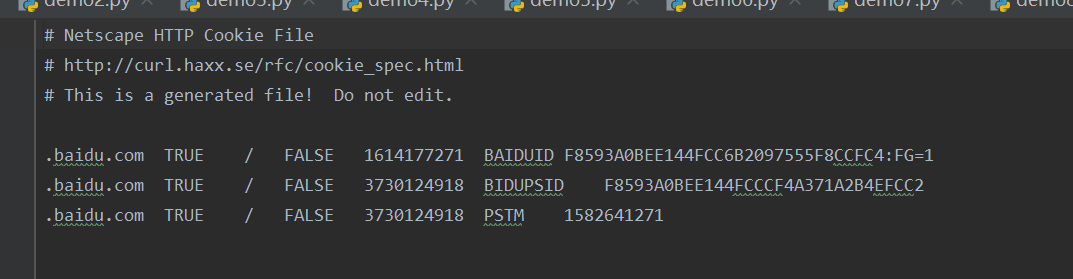
如果通过网址:hyypbin.org中得一个连接来自定义cookie信息,然后再代码中引用这个新的网址,那么下载在本地得cookie.txt为空,因为在cookie信息会在我们结束浏览时过期,如果想浏览刚刚使用得cookie信息,我们可以在代码得save函数中写
cookiejar.save(ignore_discard=True)
如果想把我们过期得cookie得信息打印出来,使用load函数
cookiejar.load(ignore_discard=True)
然后再加上
for cookie in cookiejar:
print(cookie)
python爬虫(七) mozillacookiejar的更多相关文章
- Python 爬虫七 Scrapy
Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设 ...
- python爬虫(七)_urllib2:urlerror和httperror
urllib2的异常错误处理 在我们用urlopen或opener.open方法发出一个请求时,如果urlopen或opener.open不能处理这个response,就产生错误. 这里主要说的是UR ...
- Python爬虫实战七之计算大学本学期绩点
大家好,本次为大家带来的项目是计算大学本学期绩点.首先说明的是,博主来自山东大学,有属于个人的学生成绩管理系统,需要学号密码才可以登录,不过可能广大读者没有这个学号密码,不能实际进行操作,所以最主要的 ...
- Python爬虫入门七之正则表达式
在前面我们已经搞定了怎样获取页面的内容,不过还差一步,这么多杂乱的代码夹杂文字我们怎样把它提取出来整理呢?下面就开始介绍一个十分强大的工具,正则表达式! 1.了解正则表达式 正则表达式是对字符串操作的 ...
- 孤荷凌寒自学python第七十九天开始写Python的第一个爬虫9并使用pydocx模块将结果写入word文档
孤荷凌寒自学python第七十九天开始写Python的第一个爬虫9 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 到今天终于完成了对docx模块针对 ...
- 孤荷凌寒自学python第七十八天开始写Python的第一个爬虫8
孤荷凌寒自学python第七十八天开始写Python的第一个爬虫8 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 到今天止基本完成了对docx模块针 ...
- 孤荷凌寒自学python第七十七天开始写Python的第一个爬虫7
孤荷凌寒自学python第七十七天开始写Python的第一个爬虫7 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 今天的学习仍然是在纯粹对docx模 ...
- 孤荷凌寒自学python第七十六天开始写Python的第一个爬虫6
孤荷凌寒自学python第七十六天开始写Python的第一个爬虫6 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 不过由于对python-docx模 ...
- 孤荷凌寒自学python第七十五天开始写Python的第一个爬虫5
孤荷凌寒自学python第七十五天开始写Python的第一个爬虫5 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 直接上代码.详细过程见文末屏幕录像 ...
- 孤荷凌寒自学python第七十四天开始写Python的第一个爬虫4
孤荷凌寒自学python第七十四天开始写Python的第一个爬虫4 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 直接上代码.详细过程见文末屏幕录像 ...
随机推荐
- layuiAdmin pro v1.x 【单页版】开发者文档
layuiAdmin std v1.x [iframe版]开发者文档 题外 该文档适用于 layuiAdmin 专业版(单页面),阅读之前请务必确认是否与你使用的版本对应. 熟练掌握 layuiAdm ...
- DFS(深度优先搜索)
基本概念 深度优先搜索算法(Depth First Search,简称DFS):一种用于遍历或搜索树或图的算法. 沿着树的深度遍历树的节点,尽可能深的搜索树的分支.当节点v的所在边都己被探寻过或者在搜 ...
- unittest 测试套件使用汇总篇
# coding=utf-8import unittestfrom inspect import isfunction def usage(): """also unit ...
- libcurl库的简介(二)
下面是使用libcurl库实现文件上传的一个实例: void CDataProcess::sendFileToServer(void) { string netIp = strNetUrl + &qu ...
- vue实现数据遍历、多个倒计时列表
移动端效果图: 1.HTML显示代码: <template> <div class="activeList"> <div class="li ...
- watch监听变化
<template> <div> 父级 <childCom1 @click.native="fn()"></childCom1> { ...
- <位运算> 任意二进制数 异或两个相同的二进制数 还是原本的值
二进制,即0与1. 因为两个相同的二进制 异或必为0.(类似于不进位加法) 二进制里与0异或为其原本的0与1.. 可得任意二进制数 异或两个相同的二进制数 还是原本的值. 可用于交换和加密.
- IDEA Tomcat配置 VM Option
-server -XX:PermSize=512M -XX:MaxPermSize=1024m -Dfile.encoding=UTF-8
- php中判断shell_exec执行结果
$shell = "wget -O despath sourcepath && echo 'success' "; $shellExec = shell_exec( ...
- python正则表达式中括号的作用,形如 "(\w+)\s+\w+"
先看一个例子: import re string="abcdefg acbdgef abcdgfe cadbgfe" #带括号与不带括号的区别 regex=re.compile(& ...