kibana的Dev Tool中如何对es进行增删改查
kinaba Dev Tool中对es(elasticSearch)进行增删改查
一、查询操作
查询语句基本语法
以下语句类似于mysql的: select * from xxx.yyy.topic where 条件1,条件2,...条件N
GET xxx.yyy.topic/logs/_search
{
"query": {
"bool": {
这里面是限制条件,不写则查所有数据
可以包含单个或多个限制条件
}
}
}
select * from xxx.yyy.topic where 条件1
GET xxx.yyy.topic/logs/_search
{
"query": {
这里只能是单个条件
}
}
详细说明:
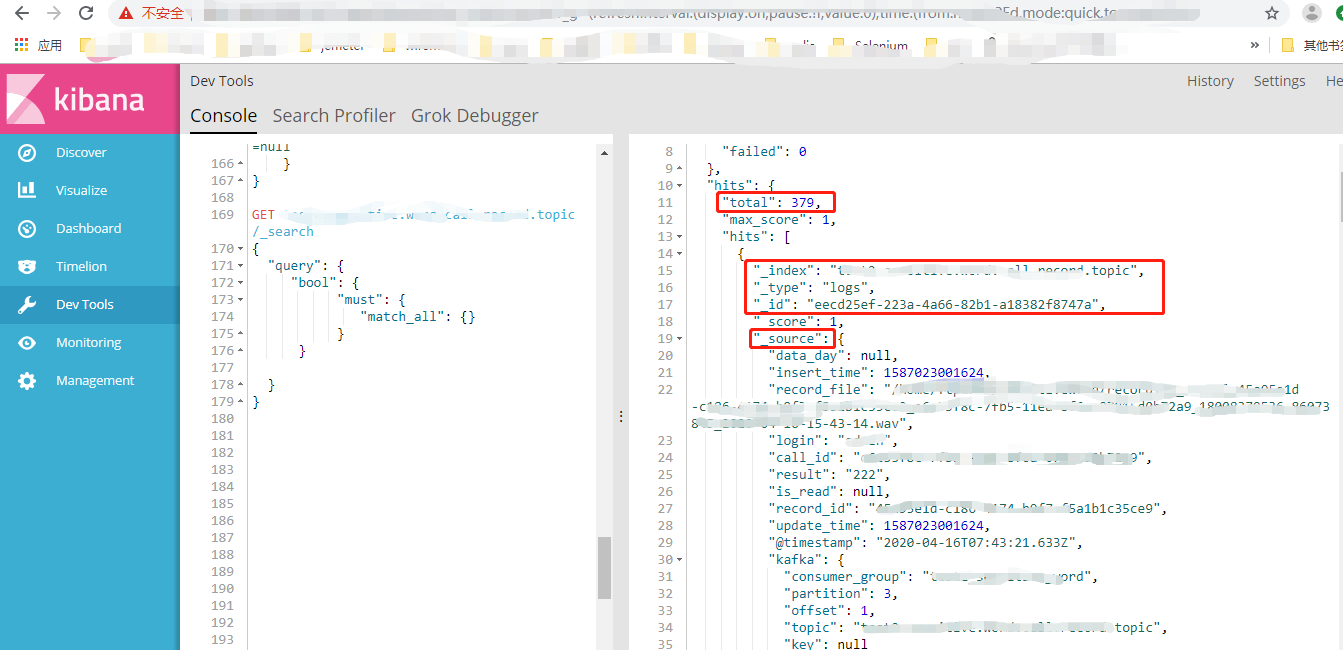
GET xxx.yyy.topic/logs/_search中
xxx.yyy.topic 对应字段_index 即索引字段 相当于mysql中的数据库名称
logs 对应字段_type 相当于mysql中的表名
_id 相当于mysql中的主键
_search 这表示执行查询操作
_source 相当于mysql表中的列的集合
bool体中是一个或多个基本查询的组合,可在bool里面使用以下参数:
must 文档中必须包含must后的条件
must_not 文档中必须不包含must_not后的条件
should 满足should后的任何一个条件
filter filter后跟过滤条件
1、select * from xxx.yyy.topic
GET xxx.yyy.topic/logs/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
}
} }
}
或者
GET xxx.yyy.topic/logs/_search
{
"query": {
"bool": {}
}
}
或者
GET xxx.yyy.topic/logs/_search
{
"query": {
"match_all": {}
}
}
如果在index下只有一种_type,则在GET中可以不带_type
GET xxx.yyy.topic/_search
{
"query": {
"bool": {}
}
}
2、 select * from xxx.yyy.topic where login = 'BigFaceCat' and pwd='123'
GET xxx.yyy.topic/logs/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"login.keyword": "BigFaceCat"
}
},
{
"match": {
"pwd.keyword": "123"
}
}
]
}
}
}
3、查询语句 select * from xxx.yyy.topic where update_time > 1591200000000 and update_time<1591200000000
select * from xxx.yyy.topic where update_time between 1591200000000 and 1591200000000
GET xxx.yyy.topic/logs/_search
{
"query":{
"bool":{
"must":[
{
"range":{
"update_time":{
"gte":1591200000000,
"lte":1591362000000
}
}
}
]
}
}
}
GET xxx.yyy.topic/logs/_search
{
"query":{
"bool":{
"filter":[
{
"range":{
"update_time":{
"gte":1591200000000,
"lte":1591362000000
}
}
}
]
}
}
}
gte :表示 >=
lte : 表示<=
gt : 表示>
lt : 表示<
4、查询语句 select * from xxx.yyy.topic where update_time > 1591200000000 and update_time<1591200000000 and login='BigFaceCat'
{
"query":{
"bool":{
"must":[
{
"range":{
"update_time":{
"gte":1591200000000,
"lte":1591362000000
}
}
},
{
"match":{
"login.keyword":"BigFaceCat"
}
}
]
}
}
}
GET xxx.yyy.topic/logs/_search
{
"query": {
"bool": {
"must":{ "match":{"login.keyword":"BigFaceCat"}},
"filter": {
"range": {
"update_time": {
"gte": 1591200000000,
"lte": 1591362000000
}
}
} }
}
}
5、查询语句 select * from xxx.yyy.topic where login='BigFaceCat' or login='LittlteFaceCat'
GET xxx.yyy.topic/logs/_search
{
"query": {
"bool": {
"should": [
{ "match": { "login.keyword": "BigFaceCat" }},
{ "match": { "login.keyword": "LittlteFaceCat"}}
]
}
}
}
6、select * from xxx.yyy.topic where login is null
GET xxx.yyy.topic/logs/_search
{
"query": {
"bool": {
"must_not": {
"exists": {
"field": "login"
}
}
}
}
}
7、select * from xxx.yyy.topic where login is not mull
GET xxx.yyy.topic/logs/_search
{
"query": {
"bool": {
"must": {
"exists": {
"field": "login"
}
}
}
}
}
GET xxx.yyy.topic/logs/_search
{
"query": {
"bool": {
"filter": {
"exists": {
"field": "login"
}
}
}
}
}
8、select * from xxx.yyy.topic where login in ('BigFaceCat','LittlteFaceCat')
GET xxx.yyy.topic/logs/_search
{
"query": {
"bool": {
"must": [
{
"match": { "login.keyword": "BigFaceCat" }
},
{
"match": { "login.keyword": "LittlteFaceCat" } }
]
}
}
}
GET xxx.yyy.topic/logs/_search
{
"query": {
"bool":{
"filter":{
"terms":{ "login":["BigFaceCat","LittleFaceCat"]}
}
}
}
}
GET xxx.yyy.topic/logs/_search
{
"query": {
"bool":{
"should": [
{ "term":{ "login":"BigFaceCat"} },
{ "term":{ "login":"LittleFaceCat"} }
]
}
}
}
terms : 后面可跟多个值
term : 后面只能有一个值
9、select call_id , record_id from xxx.yyy.topic where _id = 'eecd25747'
GET xxx.yyy.topic/logs/_search
{
"_source": ["call_id","record_id"],
"query": {
"match": { "_id": "eecd25747a"}
} }
select call_id , record_id from xxx.yyy.topic where login='BigFaceCat' and pwd='123'
GET xxx.yyy.topic/logs/_search
{
"_source": ["call_id","record_id"],
"query": {
"bool": {
"must": [
{
"match": {
"login.keyword": "BigFaceCat"
}
},
{
"match": {
"pwd.keyword": "123"
}
}
]
}
}
}
10、聚合查询 select sum( talk_duration) as sum_of_talkDuration from xxx.yyy.topic
GET xxx.yyy.topic/logs/_search
{
"aggs": {
"sum_of_talkDuration":{
"sum":{
"field": "talk_duration"
}
} }
}
select sum( talk_duration) as sum_of_talkDuration from xxx.yyy.topic where end_time is not null
GET xxx.yyy.topic/logs/_search
{
"query": {
"bool": {
"must": [
{"exists":{"field":"end_time"}}
]
}
}, "aggs": {
"sum_of_talkDuration":{
"sum":{
"field": "talk_duration"
}
} }
}
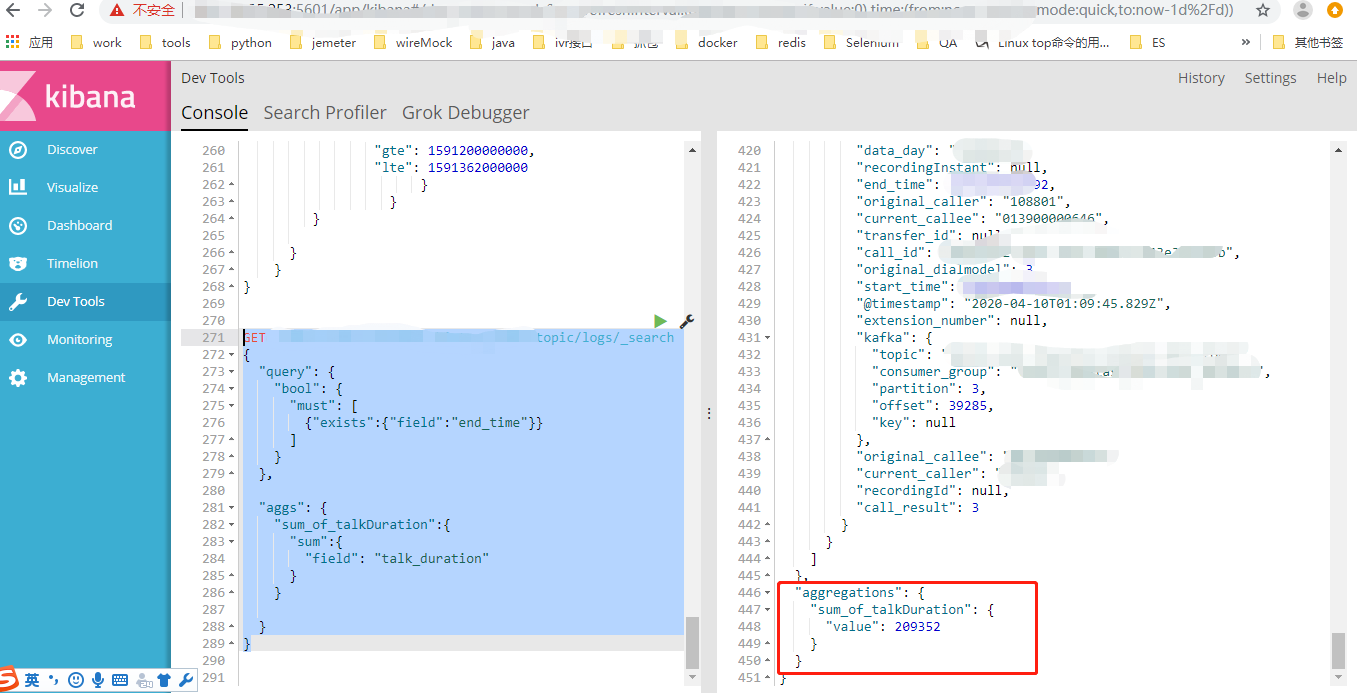
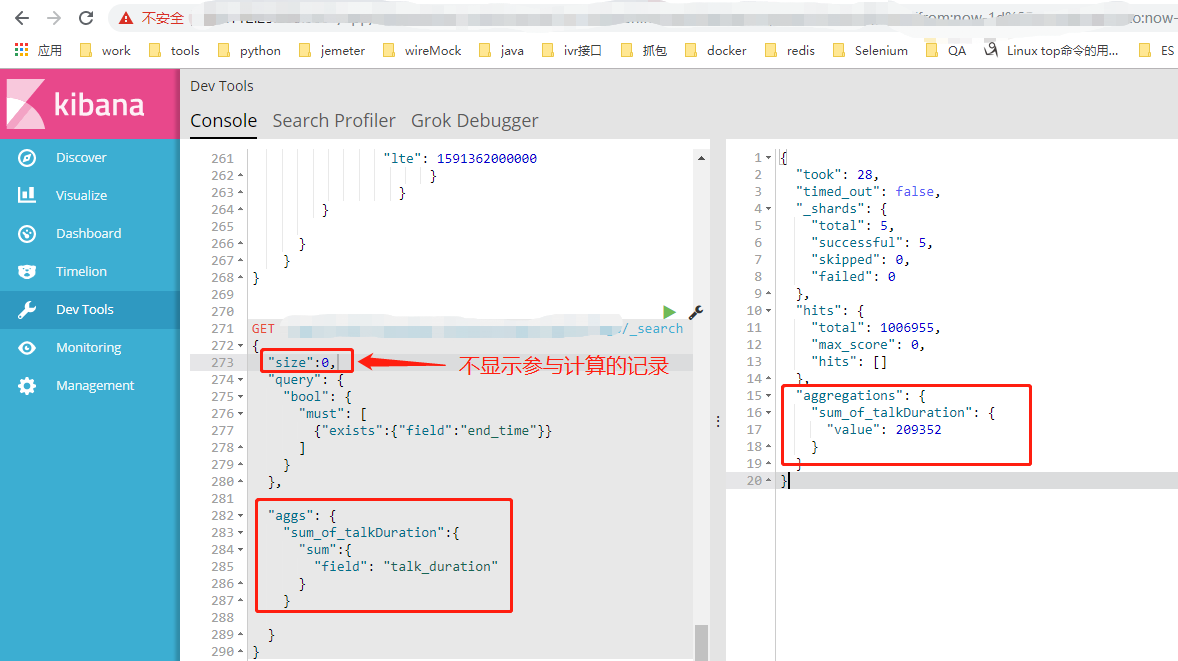
11、select SUM( DISTINCT talk_duration) as sum_of_diffTalkDuration from xxx.yyy.topic
GET xxx.yyy.topic/logs/_search
{
"size":0,
"aggs": {
"sum_of_diffTalkDuration":{
"cardinality":{
"field": "talk_duration"
}
} }
}
12、求平均值 SELECT AVG( record_duration ) as avg_of_talkDurtion FROM xxx.yyy.topic
GET xxx.yyy.topic/logs/_search
{
"size":0,
"aggs": {
"avg_of_talkDuration":{
"avg":{
"field": "talk_duration"
}
}
}
13、求最大值 SELECT MAX( record_duration ) as max_of_talkDurtion FROM xxx.yyy.topic
GET xxx.yyy.topic/logs/_search
{
"size":0,
"aggs": {
"max_of_talkDuration":{
"max":{
"field": "talk_duration"
}
}
}
14、对查询结果排序 select * from xxx.yyy.topic order by talk_duration desc
GET xxx.yyy.topic/logs/_search
{
"query": {
"bool": { }
}, "sort": [{ "talk_duration": "desc" }] }
GET xxx.yyy.topic/logs/_search
{
"query": {
"bool": {}
},
"sort": [
{ "talk_duration": {"order": "desc"} }
] }
desc : 降序排序
asc : 升序排序
15、分页查询
GET xxx.yyy.topic/logs/_search
{
"query": {
"bool": { }
},
"sort": [{ "talk_duration": {"order": "desc"} }],
"from": 2,
"size": 3 }
from : 起始页
size : 按size条记录分页
如上查询:按每页3条记录分页,返回第2页
16、通过主键_id查询 select * from xxx.yyy.topic where _id = 'AXKRp4hXdhuuEZQaKj7n'
GET xxx.yyy.topic/logs/AXKRp4hXdhuuEZQaKj7n
17、通过主键_id查询某些字段 select phone_number,system_code, extension from xxx.yyy.topic where _id='AXKRp4hXdhuuEZQaKj7'
GET xxx.yyy.topic/logs/AXKRp4hXdhuuEZQaKj7n?_source=phone_number,system_code,extension
二、修改操作
1、通过查询条件来限定修改范围的方式
update xxx.yyy.topic set result='[{\"aWord\":\"1哈哈哈哈\",\"count\":1,\"locations\":[\"00:05-00:08\",\"01:01-01:02\"]}]'
where update_time >= 1591200000000 and update_time <= 1591362000000
json串中带有特殊字符",需要用\进行转义
POST xxx.yyy.topic/logs/_update_by_query
{
"query": {
"bool": {
"must": [
{
"range": {
"update_time": {
"gte": 1591200000000,
"lte": 1591362000000
}
}
}
]
}
},
"script": {
"source": "ctx._source['result']='[{\"aWord\":\"1哈哈哈哈\",\"count\":1,\"locations\":[\"00:05-00:08\",\"01:01-01:02\"]}]'"
}
}
2、用主键作作为条件修改的方式
update xxx.yyy.topic set result='[{\"aWord\":\"1哈哈哈哈\",\"count\":1,\"locations\":[\"00:05-00:08\",\"01:01-01:02\"]}'
where _id='xx-b2fc-43ca-afe7-77e3ff406ff9'
注意:json中带有特殊字符,需要两个"""包起来
POST xxx.yyy.topic/logs/xx-b2fc-43ca-afe7-77e3ff406ff9/_update
{
"doc":{
"result": """[{"aWord":"1哈哈哈哈","count":1,"locations":["00:05-00:08","01:01-01:02"]}]"""
}
}
POST xxx.yyy.topic/logs/xx-b2fc-43ca-afe7-77e3ff406ff9/_update
{ "doc":{
"result": "哈哈哈" }
}
kibana的Dev Tool中如何对es进行增删改查的更多相关文章
- Django中对单表的增删改查
之前的简单预习,重点在后面 方式一: # create方法的返回值book_obj就是插入book表中的python葵花宝典这本书籍纪录对象 book_obj=Book.objects.creat ...
- Django学习笔记--数据库中的单表操作----增删改查
1.Django数据库中的增删改查 1.添加表和字段 # 创建的表的名字为app的名称拼接类名 class User(models.Model): # id字段 自增 是主键 id = models. ...
- Django中ORM对数据库的增删改查操作
前言 什么是ORM? ORM(对象关系映射)指用面向对象的方法处理数据库中的创建表以及数据的增删改查等操作. 简而言之,就是将数据库的一张表当作一个类,数据库中的每一条记录当作一个对象.在 ...
- Django中ORM对数据库的增删改查
Django中ORM对数据库数据的增删改查 模板语言 {% for line in press %} {% line.name %} {% endfor %} {% if 条件 %}{% else % ...
- ES 16 - 对Elasticsearch中的索引数据进行增删改查 (CRUD)
目录 1 创建document 1.1 创建时手动指定id 1.2 创建时自动生成id 2 查看document 2.1 根据id查询文档 2.2 通过_source字段控制查询结果 3 修改docu ...
- java中如何操作数据库(增删改查)
EntityManager 是用来对实体Bean 进行操作的辅助类.他可以用来产生/删除持久化的实体Bean,通过主键查找实体bean,也可以通过EJB3 QL 语言查找满足条件的实体Bean.实体B ...
- python中列表的常用操作增删改查
1. 列表的概念,列表是一种存储大量数据的存储模型. 2. 列表的特点,列表具有索引的概念,可以通过索引操作列表中的数据.列表中的数据可以进行添加.删除.修改.查询等操作. 3. 列表的基本语法 创建 ...
- es数据增删改查
设置最大查询条数 curl -XPUT 'http://10.121.8.5:9200/zdl_mx_shzt_ztdf/_settings' -d'{"index":{" ...
- 关于js对象中的,属性的增删改查问题
删除主要是delet方法: 1 function Person(){}; 2 var person = new Person(); 3 person.name = 'yy'; 4 person.gen ...
随机推荐
- tcp/ip 学习(一)
TCP/IP协议是什么? TCP:Transmission Control Protocol 传输控制协议 IP:Internet Protocol 因特网协议 简单来说,TCP/IP协议就是一个 ...
- Django模板之模板变量
深度查询句点符(.)在模板语言中有特殊的含义. 当模版系统遇到点("."),它将以这样的顺序查询: 字典查询(Dictionary lookup) 属性或方法查询(Attribut ...
- kubernetes flannel pod CrashLoopBackoff解决
背景 某环境客户部署了一个kubernetes集群,发现flannel的pod一直重启,始终处于CrashLoopBackOff状态. 排查 对于始终CrashLoopBackOff的pod,一般是应 ...
- python学习(12)使用正则表达式
1.正则表达式知识 符号 解释 示例 说明 . 匹配任意字符 b.t 可以匹配bat / but / b#t / b1t等 \w 匹配字母/数字/下划线 b\wt 可以匹配bat / b1t / b_ ...
- 王艳 201771010127《面向对象程序设计(java)》第二周学习总结
王艳 201771010127<面向对象程序设计(java)>第二周学习总结 第一部分:理论知识学习部分 3.1:基本概念. 1)标识符:标识符由字母.数字.美元符号以及下划线组成.且第 ...
- iOS [AFHTTPSessionManager GET:parameters:progress:success:failure:]: unrecognized selector sent to
AFN更新到4.0.1后,崩溃[AFHTTPSessionManager GET:parameters:progress:success:failure:]: unrecognized selecto ...
- 解决linux下启动tomcat找不到jdk
在tomcat目录下 vim catalina.sh 头部加入 JAVA_HOME='/root/use/local/java/jdk/';export JAVA_HOME;
- PHP的图像函数
imagecreate() 和 imagecreatetruecolor() 函数用于创建一幅空白图像. imagedestroy() 函数用于销毁图像资源. imagecreate() 如果我们要对 ...
- eatwhatApp开发实战(八)
在App中增,删功能都有了,这次我们来做改的功能.在项目中点击items项时对对应的条目中的商店名称进行修改. 点击items跳出一个对话框,里面包含了输入框.修改按钮和取消按钮: AlertDial ...
- Robot Framework(15)- 扩展关键字
如果你还想从头学起Robot Framework,可以看看这个系列的文章哦! https://www.cnblogs.com/poloyy/category/1770899.html 前言 什么是扩展 ...