理解java容器底层原理--手动实现LinkedList
Node
java 中的 LIinkedList 的数据结构是链表,而链表中每一个元素是节点。
我们先定义一下节点:
package com.xzlf.collection;
public class Node {
Node previous; // 上一个节点
Node next; // 下一个节点
Object element; // 元素数据
public Node(Object element) {
super();
this.element = element;
}
public Node(Node previous, Node next, Object element) {
super();
this.previous = previous;
this.next = next;
this.element = element;
}
}
版本一:基础版本
先创建一个类,完成链表的创建、添加元素、然后重写toString() 方法:
package com.xzlf.collection;
/**
* 自定义一个链表
* @author xzlf
*
*/
public class MyLinkedList {
private Node first;
private Node last;
private int size;
public void add(Object obj) {
Node node = new Node(obj);
if(first == null) {
first = node;
last = node;
}else {
node.previous = last;
node.next = null;
last.next = node;
last = node;
}
size++;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder("[");
Node tmp = first;
while(tmp != null) {
sb.append(tmp.element + ",");
tmp = tmp.next;
}
sb.setCharAt(sb.length() - 1, ']');
return sb.toString();
}
public static void main(String[] args) {
MyLinkedList list = new MyLinkedList();
list.add("a");
list.add("b");
list.add("c");
list.add("a");
list.add("b");
list.add("c");
list.add("a");
list.add("b");
list.add("c");
System.out.println(list);
}
}
测试:
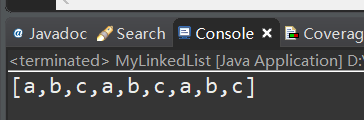
版本二:增加get() 方法
package com.xzlf.collection;
/**
* 自定义一个链表
* 增加get方法
* @author xzlf
*
*/
public class MyLinkedList2 {
private Node first;
private Node last;
private int size;
public void add(Object obj) {
Node node = new Node(obj);
if(first == null) {
first = node;
last = node;
}else {
node.previous = last;
node.next = null;
last.next = node;
last = node;
}
size++;
}
public Object get(int index) {
Node tmp = null;
// 判断索引是否合法
if(index < 0 || index > size - 1) {
throw new RuntimeException("索引不合法:" + index);
}
/*索引位置为前半部分,从头部开始找*/
if (index <= size >> 1) {
tmp = first;
for (int i = 0; i < index; i++) {
tmp = tmp.next;
}
}else {
/*索引位置为或半部分,从未部开始找*/
tmp = last;
for (int i = size -1; i > index; i--) {
tmp = tmp.previous;
}
}
return tmp.element;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder("[");
Node tmp = first;
while(tmp != null) {
sb.append(tmp.element + ",");
tmp = tmp.next;
}
sb.setCharAt(sb.length() - 1, ']');
return sb.toString();
}
public static void main(String[] args) {
MyLinkedList2 list = new MyLinkedList2();
list.add("a");
list.add("b");
list.add("c");
list.add("d");
list.add("e");
list.add("f");
System.out.println(list);
System.out.println(list.get(1));
System.out.println(list.get(4));
}
}
测试:
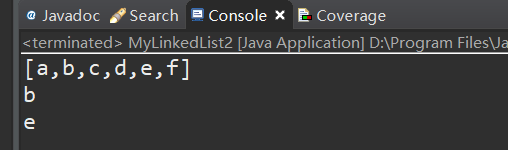
版本三:增加remove() 方法
package com.xzlf.collection;
/**
* 自定义一个链表
* 增加remove
* @author xzlf
*
*/
public class MyLinkedList3 {
private Node first;
private Node last;
private int size;
public void add(Object obj) {
Node node = new Node(obj);
if(first == null) {
first = node;
last = node;
}else {
node.previous = last;
node.next = null;
last.next = node;
last = node;
}
size++;
}
public Object get(int index) {
Node tmp = null;
// 判断索引是否合法
if(index < 0 || index > size - 1) {
throw new RuntimeException("索引不合法:" + index);
}
tmp = getNode(index);
return tmp == null ? null : tmp.element;
}
public void remove(int index) {
Node tmp = getNode(index);
Node up = tmp.previous;
Node down = tmp.next;
if (tmp != null) {
if (up != null) {
up.next = down;
}
if (down != null) {
down.previous = up;
}
// 被删元素是第一个时
if(index == 0) {
first = down;
}
// 被删元素是最后一个时
if(index == size - 1) {
last = up;
}
size--;
}
}
public Node getNode(int index) {
Node tmp = null;
/*索引位置为前半部分,从头部开始找*/
if (index <= size >> 1) {
tmp = first;
for (int i = 0; i < index; i++) {
tmp = tmp.next;
}
}else {
/*索引位置为或半部分,从未部开始找*/
tmp = last;
for (int i = size -1; i > index; i--) {
tmp = tmp.previous;
}
}
return tmp;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder("[");
Node tmp = first;
while(tmp != null) {
sb.append(tmp.element + ",");
tmp = tmp.next;
}
sb.setCharAt(sb.length() - 1, ']');
return sb.toString();
}
public static void main(String[] args) {
MyLinkedList3 list = new MyLinkedList3();
list.add("a");
list.add("b");
list.add("c");
list.add("d");
list.add("e");
list.add("f");
System.out.println(list);
list.remove(2);
System.out.println(list);
list.remove(0);// 删除第一个元素
System.out.println(list);
list.remove(3);// 删除最后一个元素
System.out.println(list);
}
}
测试:
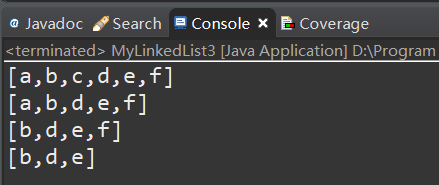
版本四:插入节点
package com.xzlf.collection;
/**
* 自定义一个链表
* 插入节点
* @author xzlf
*
*/
public class MyLinkedList4 {
private Node first;
private Node last;
private int size;
public void add(Object obj) {
Node node = new Node(obj);
if(first == null) {
first = node;
last = node;
}else {
node.previous = last;
node.next = null;
last.next = node;
last = node;
}
size++;
}
public void add(int index, Object obj) {
Node tmp = getNode(index);
Node newNode = new Node(obj);
if(tmp != null) {
Node up = tmp.previous;
up.next = newNode;
newNode.previous = up;
newNode.next = tmp;
tmp.previous = newNode;
}
}
public Object get(int index) {
Node tmp = null;
// 判断索引是否合法
if(index < 0 || index > size - 1) {
throw new RuntimeException("索引不合法:" + index);
}
tmp = getNode(index);
return tmp == null ? null : tmp.element;
}
public void remove(int index) {
Node tmp = getNode(index);
Node up = tmp.previous;
Node down = tmp.next;
if (tmp != null) {
if (up != null) {
up.next = down;
}
if (down != null) {
down.previous = up;
}
// 被删元素是第一个时
if(index == 0) {
first = down;
}
// 被删元素是最后一个时
if(index == size - 1) {
last = up;
}
size--;
}
}
public Node getNode(int index) {
Node tmp = null;
/*索引位置为前半部分,从头部开始找*/
if (index <= size >> 1) {
tmp = first;
for (int i = 0; i < index; i++) {
tmp = tmp.next;
}
}else {
/*索引位置为或半部分,从未部开始找*/
tmp = last;
for (int i = size -1; i > index; i--) {
tmp = tmp.previous;
}
}
return tmp;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder("[");
Node tmp = first;
while(tmp != null) {
sb.append(tmp.element + ",");
tmp = tmp.next;
}
sb.setCharAt(sb.length() - 1, ']');
return sb.toString();
}
public static void main(String[] args) {
MyLinkedList4 list = new MyLinkedList4();
list.add("a");
list.add("b");
list.add("c");
list.add("d");
list.add("e");
list.add("f");
System.out.println(list);
list.add(1, "hello");
System.out.println(list);
}
}
测试:
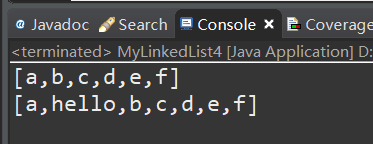
版本五:增加泛型,小的封装
package com.xzlf.collection;
/**
* 自定义一个链表
* 增加泛型,小的封装
* @author xzlf
*
*/
public class MyLinkedList5<E> {
private Node first;
private Node last;
private int size;
public void add(E element) {
Node node = new Node(element);
if(first == null) {
first = node;
last = node;
}else {
node.previous = last;
node.next = null;
last.next = node;
last = node;
}
size++;
}
public void add(int index, E element) {
checkRange(index);
Node tmp = getNode(index);
Node newNode = new Node(element);
if(tmp != null) {
Node up = tmp.previous;
up.next = newNode;
newNode.previous = up;
newNode.next = tmp;
tmp.previous = newNode;
size++;
}
}
private void checkRange(int index) {
if(index < 0 || index > size - 1) {
throw new RuntimeException("索引不合法:" + index);
}
}
public E get(int index) {
Node tmp = null;
// 判断索引是否合法
checkRange(index);
tmp = getNode(index);
return tmp == null ? null : (E) tmp.element;
}
public void remove(int index) {
checkRange(index);
Node tmp = getNode(index);
Node up = tmp.previous;
Node down = tmp.next;
if (tmp != null) {
if (up != null) {
up.next = down;
}
if (down != null) {
down.previous = up;
}
// 被删元素是第一个时
if(index == 0) {
first = down;
}
// 被删元素是最后一个时
if(index == size - 1) {
last = up;
}
size--;
}
}
private Node getNode(int index) {
checkRange(index);
Node tmp = null;
/*索引位置为前半部分,从头部开始找*/
if (index <= size >> 1) {
tmp = first;
for (int i = 0; i < index; i++) {
tmp = tmp.next;
}
}else {
/*索引位置为或半部分,从未部开始找*/
tmp = last;
for (int i = size -1; i > index; i--) {
tmp = tmp.previous;
}
}
return tmp;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder("[");
Node tmp = first;
while(tmp != null) {
sb.append(tmp.element + ",");
tmp = tmp.next;
}
sb.setCharAt(sb.length() - 1, ']');
return sb.toString();
}
public static void main(String[] args) {
MyLinkedList5<String> list = new MyLinkedList5<>();
list.add("a");
list.add("b");
list.add("c");
System.out.println(list);
list.add(1, "hello");
System.out.println(list);
System.out.println(list.get(1));
}
}
测试:
现在我们在编辑上使用add() 方法后已经提示要插入String类型的数据了:
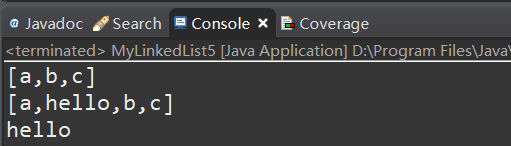
以上代码测试运行结果:
以上代码可能还有部分细节上的bug,不过作为理解LinkedList数据结构的练习应该够用了。
理解java容器底层原理--手动实现LinkedList的更多相关文章
- 理解java容器底层原理--手动实现HashMap
HashMap结构 HashMap的底层是数组+链表,百度百科找了张图: 先写个链表节点的类 package com.xzlf.collection2; public class Node { int ...
- 理解java容器底层原理--手动实现HashSet
HashSet的底层其实就是HashMap,换句话说HashSet就是简化版的HashMap. 直接上代码: package com.xzlf.collection2; import java.uti ...
- 理解java容器底层原理--手动实现ArrayList
为了照顾初学者,我分几分版本发出来 版本一:基础版本 实现对象创建.元素添加.重新toString() 方法 package com.xzlf.collection; /** * 自定义一个Array ...
- (前篇:NIO系列 推荐阅读) Java NIO 底层原理
出处: Java NIO 底层原理 目录 1.1. Java IO读写原理 1.1.1. 内核缓冲与进程缓冲区 1.1.2. java IO读写的底层流程 1.2. 四种主要的IO模型 1.3. 同步 ...
- Java面试底层原理
面试发现经常有些重复的面试问题,自己也应该学会记录下来,最好自己能做成笔记,在下一次面的时候说得有条不紊,深入具体,面试官想必也很开心.以下是我个人总结,请参考: HashSet底层原理:(问了大几率 ...
- 10分钟看懂, Java NIO 底层原理
目录 写在前面 1.1. Java IO读写原理 1.1.1. 内核缓冲与进程缓冲区 1.1.2. java IO读写的底层流程 1.2. 四种主要的IO模型 1.3. 同步阻塞IO(Blocking ...
- java容器HashMap原理
1.为什么需要HashMap 前面我们说了ArrayList和LinkedList,它们对容器内的对象都能实现增.删.改.查.遍历等操作, 并且对应不同的情况,我们可以选择不同的List,用以提高效率 ...
- 魔鬼在细节,理解Java并发底层之AQS实现
jdk的JUC包(java.util.concurrent)提供大量Java并发工具提供使用,基本由Doug Lea编写,很多地方值得学习和借鉴,是进阶升级必经之路 本文从JUC包中常用的对象锁.并发 ...
- Java 容器源码分析之 LinkedList
概览 同 ArrayList 一样,LinkedList 也是对 List 接口的一种具体实现.不同的是,ArrayList 是基于数组来实现的,而 LinkedList 是基于双向链表实现的.Lin ...
随机推荐
- WePY的开发环境的安装
2020-03-24 1.安装Node.js 官网:https://nodejs.org/ 两个版本 LTS为稳定的长期支持版本 Current为最新的版本 安装完毕后,cmd下输入 node -v ...
- iOS 项目优化
前言 iOS性能优化系列篇之"优化总体原则" 不要提前过度优化 要找到性能瓶颈 要在不同性能指标间权衡 要理解优化任务的底层运行机制 要有技术保障体系 一.启动速度优化 1.1 学 ...
- 3.用IntelliJ IDEA 创建Maven
一.File→New→ Project (需要下载安装配置Maven等,这些步骤省略) 二.Maven→org.apache.maven.archetypes:maven-archetype-quic ...
- Java数据类型与mysql对应表
- 我是如何从通信转到Java软件开发工程师的?
我的读者里面有绝大部分都是在校学生,有本科的,也有专科的,我在微信里收到很多读者的提问,大部分问题都跟如何学习编程有关,有换专业自学的.有迷茫不知道如何学习的.有报培训班没啥效果的等等,我能感受到他们 ...
- linux硬件资源问题排查:cpu负载、内存使用情况、磁盘空间、磁盘IO
在使用过程中之前正常的功能,突然无法使用,性能变慢,通常都是资源消耗问题,资源消耗可以从以下几个方面去排查.对于已经安装硬件资源监控软件(zabbix)的环境,直接使用硬件资源监控软件(zabbix) ...
- iapp,iapp http请求,iapp解析json数据
iapp发送http请求,并解析json数据 //http操作 t() { s a = "http://wap.baidu.com/" //目标url hs(a, null, nu ...
- 数据库学习 day2 检索数据
上一节我们介绍了什么是数据库,以及一些基本的数据库术语 这一课介绍使用SELECT语句从表中检索一个或多个数据列. 关键字(Keyword) 作为SQL组成部分的保留字.关键字不能用作表和列的名字(类 ...
- Vue 实战项目: 硅谷外卖(1)
第 1 章: 准备 1.1. 项目描述 1) 此项目为外卖 WebApp(SPA) 2) 包括商家, 商品, 购物车, 用户等多个子模块 3) 使用 Vue 全家桶+ES6+Webpack 等前端最新 ...
- C++11中的四种类型转换
static_cast 基础数据类型转换(基本类型) 同一继承体系中类型的转换(父子类型) 任意类型与空指针(void *)之间的转换(指针类型) dynamic_cast 执行派生类指针或引用与基类 ...