传统声学模型之HMM和GMM
声学模型是指给定声学符号(音素)的情况下对音频特征建立的模型。
数学表达
用 \(X\) 表示音频特征向量 (观察向量),用 \(S\) 表示音素 (隐藏/内部状态),声学模型表示为 \(P(X|S)\)。
但我们的机器是个牙牙学语的孩子,并不知道哪个音素具体的发出的声音是怎么样的。我们只能通过大量的数据去教他,比如说在拼音「é」的时候对应「鹅」的发音,而这个过程就是 GMM 所做的,根据数据建立起「é」这个拼音对应的音频特征分布,即 \(P(x|s=é)\)。孩子学会每个拼音的发音后,就可以根据拼音拼读一个单词 / 一个句子,但你发现他在读某段句子的时候,听起来好像怪怪的,你检查发现是他把某个拼音读错了,导致这句话听起来和常理不符。而这个怪怪的程度就是你听到这个音频特征序列的时感觉这个音频序列以及其背后的拼音出现的可能性的倒数,这部分则是通过 HMM 来建模的。
总结一下,GMM 用于对音素所对应的音频特征分布进行建模,HMM 则用于音素转移和音素对应输出音频特征之间关系的建模。
HMM
即为隐马尔可夫模型(Hidden Markov model,HMM)
HMM 脱胎于马尔可夫链,马尔可夫链表示的是一个系统中,从一个状态转移到另一个状态的所有可能性。但因为在实际应用过程中,并不是所有状态都是可观察的,不过我们可以通过可观察到的状态与隐藏状态之间的可能性。因此就有了隐马尔可夫模型。
HMM 要遵循的假设:
一阶马尔可夫假设:下一个状态只依赖于当前的状态。因此多阶马尔可夫链可简化为
\[P(s_{t+1} | s_1,s_2,\ldots,s_t) = P(s_{t+1} | s_t)
\]输出无关假设:每个输出只取决于当前 (内部/隐藏) 状态,和前一个或多个输出无关。
声学模型为什么要用HMM?
因为声学模型建立的是在给定音素序列下输出特定音频特征序列的似然 \(P(X|S)\),但在实际情况中,我们只知道音频特征序列,并不知道其对应的音素序列,所以我们需要通过 HMM 建立音频特征与背后的每个音素的对应关系,以及这个音素序列是怎么由各个音素组成的。
上两个假设可以引申出 HMM 中主要的两种概率构成:
- 从一个内部状态 \(i\) 转移到另一个内部状态 \(j\) 的概率称为转移(Transition) 概率,表示为 \(a_{ij}\)。
- 在给定一个内部状态 \(j\) 的情况下观察到某个观察值 \(x_t\) 的概率称为输出(Emission)概率,表示为 \(b_j(x_t)\)。
HMM 的三个经典问题
- 评估问题 Estimation
- 解码问题 Decoding
- 训练问题 Learning
️:后文提到的状态即指的是内部 / 隐藏状态。
评估问题
评估问题就是说,我已知模型参数 \(\theta\) (输出概率以及转移概率),最后得到的观察序列为某个特定序列 \(X\) 的概率是多少。
在刚才的例子中,就是孩子已经知道每个拼音后面可能接什么拼音,每个拼音怎么读,当他读出了某段声音,这段声音的概率是多少。
因为在观察序列固定的情况下,有多种可能的状态序列 \(S\),而评估问题就是要计算出在所有可能的状态下得到观察序列的概率,表示为
P(X) = \sum_S P(X | S) P(S) \\
\end{aligned}
\]
在当前的公式里,我们暂时先忽略固定的参数 \(\theta\)。根据一阶马尔可夫假设,时刻 \(t\) 的状态都只取决于时刻 t-1 的状态,因此单个状态序列出现的概率表示为
P(S) &= P(s_1) \prod^T_{t=2} P(s_t|s_{t-1}) \\
&= \pi_k \prod^T_{t=2} a_{ij}
\end{aligned}
\]
其中, \(\pi_k\) 表示时刻1下状态为 \(k\) 的概率。
根据输出无关假设,在时刻 \(t\) 观察序列的值只取决于时刻 \(t\) 的状态,因此观察序列关于状态序列的似然表示为
\]
因此整个观察序列出现的概率为
P(X) &= \sum_S P(X | S) P(S) \\
&= \sum_S \pi_k b_k(x_1) \prod^T_{t=2} a_{ij} b_j(x_t)
\end{aligned}
\]
由于 \(i,j,k\) 都表示可能的状态,假设有 \(n\) 种状态,那么计算该概率的事件复杂度就为 \(O(n^T)\),可谓是指数级别了。
因此,前人开动了脑筋,提出了在该问题上将时间复杂度将为多项式时间的方法。
似然前向算法
该方法采用了分治 / 动态规划的思想,在时刻 \(t\) 下的结果可以利用时刻 \(t-1\) 的结果来计算。
在时刻 \(t\),观察序列的概率表示为前 \(t\) 个时刻的观察序列与时刻 \(t\) 所有可能的状态同时出现的概率和
\]
其中, \(N\) 表示所有可能的状态的集合。
而连加符号的后面部分被定义为前向概率 \(\alpha_t(j)\),而它可以被上一个时刻的前向概率迭代表示。
\alpha_t(j) &=P(x_1,x_2,\ldots,x_t,s_t=j) \\ &= \sum_{i\in N} P(x_1,x_2,\ldots,x_{t-1},s_{t-1}=i)P(s_t|s_{t-1}=i)P(x_t|s_{t}=j) \\
&= \sum_{i\in N}\alpha_{t-1}(i) a_{ij} b_j(x_t)
\end{aligned}
\]
通过该方法,当前时刻下某个状态的概率只需要遍历上一时刻所有状态的概率 (\(n\)),然后当前时刻的所有状态的概率和也只需要遍历当前的所有状态就可以计算得到 (\(n\)),考虑到观察序列持续了 \(T\) 个时刻,因此时间复杂度降为 \(O(n^2T)\)。
整个过程总结如下
- 初始化:根据初始的状态分布,计算得到时刻1下每个状态的前向概率 \(\alpha_1(k) = \pi_k b_k(x_1)\)
- 对于每个时刻,计算该时刻下每个状态的前向概率 \(\alpha_t(j) = \sum_{i\in N}\alpha_{t-1}(i) a_{ij} b_j(x_t)\)
- 最终得到结果 \(P(X) = \sum_{i\in N}\alpha_{T}(i)\)
解码问题
解码问题就是说在得到 HMM 模型之后,我们如何通过观察序列找到最有可能的状态序列。在语音识别中,在给定的音频片段下,找到对应的各个音素。
还是刚才的例子,我们需要猜测孩子读出的这段声音最有可能对应什么样的拼音序列,这就是解码问题。
Viterbi 算法
数学表示
给定在时间 \(t\) 下的内部状态为 \(j\),局部最优概率 \(v_t(j)\) 表示的是在时刻 \(t\) 观察序列与最优内部状态序列的联合概率。
\]
同样也可以根据时间递归表示为
\]
算法具体流程如下
- 初始化:根据初始的状态分布,计算得到时刻1下每个状态的最优概率 \(v_1(k) = \pi_k b_k(x_1)\)
- 对于每个时刻,计算该时刻下每个状态的局部最优概率 \(v_t(j) = \max_{i\in N}v_{t-1}(i) a_{ij} b_j(x_t)\),记录下最优局部最优序列 \((s_1^*,s_2^*,\ldots,s_{t-2}^*) \bigcup (s_{t-1}^*)\)
- 最终得到全局最优概率 \(P(X,S^*) = \max_{i\in N} v_T(i)\)
- 得到全局最优序列 \(S^* = \arg \max_{i\in N} v_T(i), S^* = (s_1^*,s_2^*,\ldots,s_T^*)\)
在表示上很类似于上面的前向算法,只是加和变成了取最大值。具体推导流程也就不再赘述了。两者的区别可以看下图(来源) ,红线表示解码路径,黑线表示评估路径。
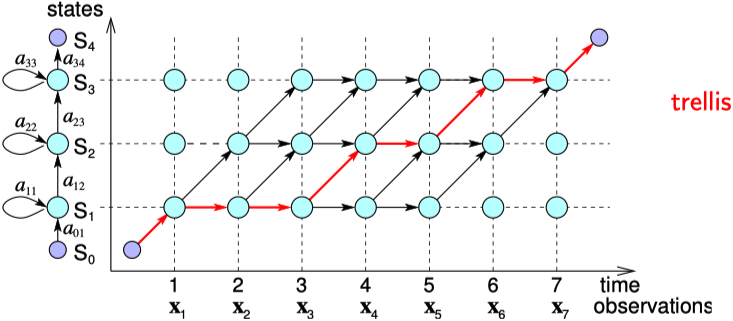
不过这张图是简化的状态,即状态序列 \(S\) 是确定的情况下的状态转移与观察序列之间的关系。
传统声学模型之HMM和GMM的更多相关文章
- kaldi基于GMM的单音素模型 训练部分
目录 1. gmm-init-mono 模型初始化 2. compile-train-graghs 训练图初始化 3. align-equal-compiled 特征文件均匀分割 4. gmm-acc ...
- 音频工具kaldi部署及模型制作调研学习
语音识别简介 语音识别(speech recognition)技术,也被称为自动语音识别(英语:Automatic Speech Recognition, ASR).计算机语音识别(英语:Comput ...
- NLP入门之语音模型原理
这一篇文章其实是参考了很多篇文章之后写出的一篇对于语言模型的一篇科普文,目的是希望大家可以对于语言模型有着更好地理解,从而在接下来的NLP学习中可以更顺利的学习. 1:传统的语音识别方法: 这里我们讲 ...
- Kaldi单音素模型 训练部分
在Kaldi中,单音素GMM的训练用的是Viterbi training,而不是Baum-Welch training.因此就不是用HMM Baum-Welch那几个公式去更新参数,也就不用计算前向概 ...
- 语音识别传统方法(GMM+HMM+NGRAM)概述
春节后到现在近两个月了,没有更新博客,主要是因为工作的关注点正从传统语音(语音通信)转向智能语音(语音识别).部门起了个新项目,要用到语音识别(准备基于Kaldi来做).我们之前做的传统音频已基本成熟 ...
- HMM 传统后向算法
HMM 传统后向算法,已实现,仅供参考. package jxutcm.edu.cn.hmm.model; import jxutcm.edu.cn.hmm.bean.HMMHelper; impor ...
- 网络流量预测 国内外研究现状【见评论】——传统的ARIMA、HMM模型,目前LSTM、GRU、CNN应用较多,貌似小波平滑预处理步骤非常关键
Time Series Anomaly Detection in Network Traffic: A Use Case for Deep Neural Networks from:https://j ...
- HMM隐马尔科夫算法(Hidden Markov Algorithm)初探
1. HMM背景 0x1:概率模型 - 用概率分布的方式抽象事物的规律 机器学习最重要的任务,是根据一些已观察到的证据(例如训练样本)来对感兴趣的未知变量(例如类别标记)进行估计和推测. 概率模型(p ...
- 上下文无关的GMM-HMM声学模型
一.语音识别基本介绍 (一)统计语音识别的基本等式 X------声学特征向量序列,观测值 W------单词序列 W*------给定观测值下,概率最大的单词序列 应用贝叶斯理论等价于 进而得出统计 ...
随机推荐
- Chisel3 - model - Hardware Model
https://mp.weixin.qq.com/s/x6j7LZg7i7i_KcNEA8YCQw Chisel作为领域专用语言(DSL),用于构建硬件模型.待硬件模型建立后,再基于模型进行仿真. ...
- WebServer远程部署
通过远程部署获取webshell并不属于代码层次的漏洞,而是属于配置性错误漏洞. 1.Tomcat tomcat是一个jsp/Servlet容器 端口号:8080 攻击方法: 默认口令.弱口令,爆破, ...
- java方法句柄-----3.方法句柄的实现接口
目录 1.使用方法句柄实现接口 1.使用方法句柄实现接口 2.3节介绍的动态代理机制可以在运行时为多个接口动态创建实现类,并拦截通过接口进行的方法调用.方法句柄也具备动态实现一个接口的能力.这是通 ...
- Sched_Boost小结
之前遇到一个耗电问题,最后发现是/proc/sys/kernel/sched_boost节点设置异常,一直处于boost状态.导致所有场景功耗上升. 现在总结一下sched_boost的相关知识. S ...
- Java实现 LeetCode 633 平方数之和(暴力大法)
633. 平方数之和 给定一个非负整数 c ,你要判断是否存在两个整数 a 和 b,使得 a2 + b2 = c. 示例1: 输入: 5 输出: True 解释: 1 * 1 + 2 * 2 = 5 ...
- Java实现 LeetCode 149 直线上最多的点数
149. 直线上最多的点数 给定一个二维平面,平面上有 n 个点,求最多有多少个点在同一条直线上. 示例 1: 输入: [[1,1],[2,2],[3,3]] 输出: 3 解释: ^ | | o | ...
- Java实现 蓝桥杯VIP 算法提高 复数求和
算法提高 复数求和 时间限制:1.0s 内存限制:512.0MB 从键盘读入n个复数(实部和虚部都为整数)用链表存储,遍历链表求出n个复数的和并输出. 样例输入: 3 3 4 5 2 1 3 样例输出 ...
- Java实现第九届蓝桥杯付账问题
付账问题 题目描述 [题目描述] 几个人一起出去吃饭是常有的事.但在结帐的时候,常常会出现一些争执. 现在有 n 个人出去吃饭,他们总共消费了 S 元.其中第 i 个人带了 ai 元.幸运的是,所有人 ...
- java实现第五届蓝桥杯出栈次序
出栈次序 X星球特别讲究秩序,所有道路都是单行线.一个甲壳虫车队,共16辆车,按照编号先后发车,夹在其它车流中,缓缓前行. 路边有个死胡同,只能容一辆车通过,是临时的检查站,如图[p1.png]所示. ...
- java实现第五届蓝桥杯格子放鸡蛋
格子放鸡蛋 X星球的母鸡很聪明.它们把蛋直接下在一个 N * N 的格子中,每个格子只能容纳一枚鸡蛋.它们有个习惯,要求:每行,每列,以及每个斜线上都不能有超过2个鸡蛋.如果要满足这些要求,母鸡最多能 ...