Python之-------基础数据类型
数据类型:
计算可以处理各种不同文件,图形,音频,视频,网页等各种各样的数据,不同的数据,需要定义不同的数据类型。在Python中,能够直接处理的数据类型有以下几种:
一:nubmer(数字)
1.1数据类型的创建:
a=90
b=a
b=9000
print(a)
print(b)
1.2number 数据类型的转换:
var1=3.14
var2=5
var3=int(var1)
var4=float(var2)
5 print(var3,var4)
Python内置函数:
x=10
abs(x) #x的绝对值, 例如-10,结果就是10
ceil(x) #返回数字的上入整数,如math.ceil(4.1) 返回 5
cmp(x, y) #如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1
exp(x) # 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045
fabs(x) # 返回数字的绝对值,如math.fabs(-10) 返回10.0
floor(x) # 返回数字的下舍整数,如math.floor(4.9)返回 4
log(x) # 如math.log(math.e)返回1.0,math.log(100,10)返回2.0
log10(x) # 返回以10为基数的x的对数,如math.log10(100)返回.0
max(x1, x2,...) #返回给定参数的最大值,参数可以为序列。
min(x1, x2,...) #返回给定参数的最小值,参数可以为序列。
modf(x) #返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。
pow(x, y) # x**y 运算后的值。
round(x [n]) #返回浮点数x的四舍五入值,如给出n值,则代表舍入到小数点后的位数。
sqrt(x) # 返回数字x的平方根,数字可以为数,返回类型为实数,如math.sqrt(4)返回 2+0j
二:字符串类型:string
字符串的格式:是以英文状态下的:"abcd",或者'123 '以单引号,或者以双引号格式书写的;
2.1创建字符串:
print("helloworld")
print('nihao')
2.2对应的操作:
# 1 * 重复输出字符串
print('hello123'*2) # 2 [] ,[:] 通过索引获取字符串中字符,这里和列表的切片操作是相同的,具体内容见列表
print('helloworld123456'[2:])
# 3 in 成员运算符 - 如果字符串中包含给定的字符返回 True
print('el' in 'helloworld123')
# 4 % 格式字符串
print('%s is a good teacher'%'wing') # 5 + 字符串拼接
a=''
b='abc'
c=''
d1=a+b+c
print(d1)
# +效率低,该用join
d2=''.join([a,b,c])
print(d2)
2.3string的内置函数:
# string.capitalize() 把字符串的第一个字符大写
# string.center(width) 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串
# string.count(str, beg=0, end=len(string)) 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数
# string.decode(encoding='UTF-8', errors='strict') 以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除 非 errors 指 定
# string.encode(encoding='UTF-8', errors='strict') 以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignor
# string.endswith(obj, beg=0, end=len(string)) 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 Fals
# string.expandtabs(tabsize=8) 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。
# string.find(str, beg=0, end=len(string)) 检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1
# string.index(str, beg=0, end=len(string)) 跟find()方法一样,只不过如果str不在 string中会报一个异常.
# string.isalnum() 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False
# string.isalpha() 如果 string 至少有一个字符并且所有字符都是字母则返回 True,否则返回 False
三:字节类型:
四:布尔值:
4.1:True和False,在Python中,布尔值,要区分大小写:
print(True)
print(4>2)
print(True+1)
print(bool([3,4]))
4.2或与非的操作:
bool(1 and 0)
bool(1 and 1)
bool(1 or 0)
bool(not 0)
4.3布尔值的常用场景:
#
# age=18
# if age>18:
# print('成功')
# else:
# print('haha')
五:list列表
list是Python中数据最长用的数据类型,列表是可变的:
5.1查:[]
names_class2=['小米','华为','联想','三星'] print(names_class2[2])
print(names_class2[0:3])
print(names_class2[0:7])
print(names_class2[-1])
print(names_class2[2:3])
print(names_class2[0:3:1])
print(names_class2[3:0:-1])
5.2增
append可以在列表的最后追加内容,insert是在列表里面插入内容;
names_class2.append('月月')
names_class2.insert(2,'mimi')
print(names_class2)
5.3改(重新赋值)
names_class2[3]=('haha')
names_class2[0:2] =('hhh','www')
print(names_class2)
5.4删除:del remove pop
names_class2.remove('haha')
del names_class2[0]
names_class2.pop()
del names_class2
5.5 count
count()用于统计某个字母在列表里面出现的次数;
x=['to','me','to','me','to','haha','hello']
x.count('to')
y=[1,2,[1,2],[1,2],[4,5]]
y.count([1,2])
y.count(1)
5.6extend,可以在另一个序列的后边追加一个序列;
x=[1,2,3]
y=[4,5,6]
x.extend(y)
print(x)
extend 的是改变了原来的列表,而原来的 +这是返回一个全新的列表
x=[1,2]
y=[3,4]
print(x+y)
print(x)
5.8 index ,找出序列的第一个匹配的索引的位置;
print(names_class2.index('www'))
5.9reverse(),方法是将列表中的元素反向存放;
names_class2.reverse(
print(names_class2)
6.0 sort 是在原来的基础上,让原来的列表排序
x=[4,5,1,2]
x.sort()
print(x)
6.1深浅拷贝
对于一个列表,我们可以对其进行,复制,而不是通过重新赋值的方式;重新赋值的内存空间是两个独立的内存空间;
names1=['张三','李四','王五','赵六']
names1.copy=['张三','李四','王五','赵六']
通过如上的方式,可以实现两个值得一样,但是并不是使用于所有的场合,如果说所有的数据都通过这种方式赋值的方式复制,因为其数据量比较大不适合,所有这里面我们可以使用copy()
n=['张三','李四','王五','赵六',[1,7,8]]
ncopy=n.copy() n[0]='zhangsan'
print(n)
print(ncopy)
#这里查看如下代码,发现两者并不是一直独立的;
n[4][0]=0
print(n)
print(ncopy)
这里简单的介绍一下什么是深浅拷贝:
1、首先给大家介绍一下,哪些基本的数据类型是可变的,哪些是不可变的:
可变数据类型:字典,列表,这些是可变的
不可变的数据类型:元组,数字,字符串
通过id()函数我们可以获取一个对象的内存地址;如果两个对象的内存地址是一样的,那么这两个对象肯定是一个对象。和is是等价的。Python源代码为证:
static PyObject *
cmp_outcome(int op, register PyObject *v, register PyObject *w)
{
int res = 0;
switch (op) {
case PyCmp_IS:
res = (v == w);
break;
case PyCmp_IS_NOT:
res = (v != w);
break;
2、当我们对列表进行修改的时候,注意不变的是列表的内存地址,不是里面的元素;
u=[1,2,3,4]
print(id(u)) #执行结果3247840
u[0]='a'
print(id(u)) #执行结果3247840
2.1像:数字,元组,字符串这些不可变的数据类型,要想改变,必须重新赋值,指针指向新的内存地址;
r='wing'
print(id(r))#内存地址4551520
# r[0]='a' #报错
r='mimi'
print(id(r)) #内存地址:6750304
2.3有关拷贝知识:这里我们只需要掌握浅拷贝的知识,就可以了;
a=[[1,2],3,4]
b=a[:]#b=a.copy() print(a,b)
print(id(a),id(b))
print('a[0]:',id(a[0]),'b[0]:',id(b[0]))
print('a[0][0]:',id(a[0][0]),'b[0][0]:',id(b[0][0]))
print('a[0][1]:',id(a[0][1]),'b[0][1]:',id(b[0][1]))
print('a[1]:',id(a[1]),'b[1]:',id(b[1]))
print('a[2]:',id(a[2]),'b[2]:',id(b[2])) print("-------------------------------------------") b[0][0]=0
print(a,b)
print(id(a),id(b))
print('*************************************')
print('a[0]:',id(a[0]),'b[0]:',id(b[0]))
print('a[0][0]:',id(a[0][0]),'b[0][0]:',id(b[0][0]))
print('a[0][1]:',id(a[0][1]),'b[0][1]:',id(b[0][1]))
print('a[1]:',id(a[1]),'b[1]:',id(b[1]))
print('a[2]:',id(a[2]),'b[2]:',id(b[2])) 如图参考:
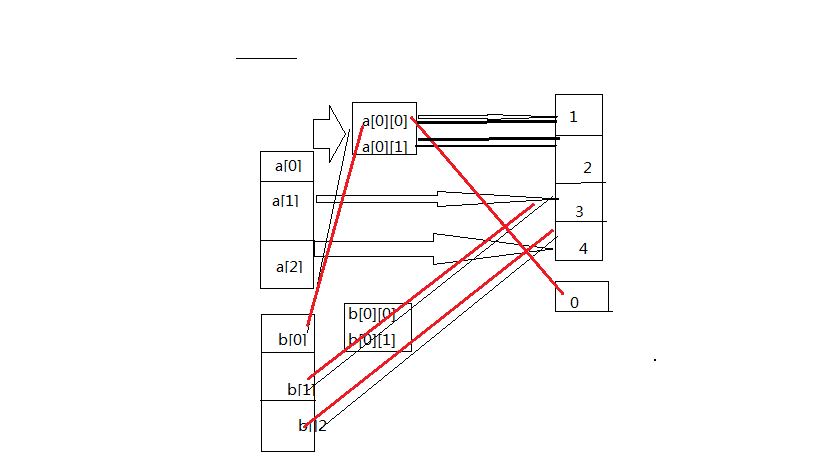
六:元组,tuple:
元组是不可变的,即数据不能修改,只能被查询,元组在小括号里面(),元组用逗号隔开,元组可以被查询,所以可以像列表一样使用切片查询;
a=()
b=(2,)
元组可以是空的,元组是一个元素的时候要使用逗号;
元组的作用:
1 对于一些数据我们不想被修改,可以使用元组;
2 另外,元组的意义还在于,元组可以在映射(和集合的成员)中当作键使用——而列表则不行;元组作为很多内建函数和方法的返回值存在。
七:字典:
1、字典是python中唯一的映射类型,采用键值对(key-value)的形式存储数据。
2、python对key进行哈希函数运算,根据计算的结果决定value的存储地址,所以字典是无序存储的,且key必须是可哈希的。
3、可哈希表示key必须是不可变类型,如:数字、字符串、元组。
4、字典(dictionary)是除列表意外python之中最灵活的内置数据结构类型。
5、列表是有序的对象结合,字典是无序的对象集合。
6、两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
7.1创建字典:
dic={'name':'wing','age':34,'sex':'nv'}
dic2=dict((('name','wing'),))
print(dic)
print(dic2)
执行结果:
{'name': 'wing', 'age': 34, 'sex': 'nv'}
{'name': 'wing'}
7.2字典常用的操作方法:
dic={}
dic['name']='wing'
dic['age']=12
print(dic)
执行结果:
{'name': 'wing', 'age': 12}
7.2查:
dic={}
dic['name']='wing'
dic['age']=12
print(dic)
print(dic['name'])
print(dic.items())
print(dic.keys())
print(dic.values())
print('name' in dic)
print(list(dic.values()))
执行结果:
{'name': 'wing', 'age': 12}
wing
dict_items([('name', 'wing'), ('age', 12)])
dict_keys(['name', 'age'])
dict_values(['wing', 12])
True
['wing', 12]
7.3删除:
dic={}
dic['name']='
dic['age']=12
print(dic)
dic['name']='
del dic['name
print(dic)
a=dic.popitem
print(a,dic)
执行结果:
{'name': 'wing', 'age': 12}
{'age': 12}
('age', 12) {}
7.4 改:
dic={'name
dic['name'
dic2={'sex
dic.update
print(dic)
7.5 字典的嵌套:
dic={ 'zhangsan':{'age':23,'sex':'male'},
'李二敏':{'age':33,'sex':'male'},
'wing':{'age':27,'sex':'women'} }
八:集合:(set)
8.1:集合是无序的,不重复的,它的作用:
1、去重,把列表变成集合,就会自动的去重了;
2、交叉,并集,交集,差集等关系;
在Python中,集合是不能重复的;
li=[1,2,3,4]
s=set(li)
print(s) li2=[1,2,3,4,1,1]
s2=set(li2)
print(s2)
执行结果:
{1, 2, 3, 4}
{1, 2, 3, 4}
集合的对象无序排列的可哈希的值:集合成员可以做字典的键;
集合分类:可变集合,不可变集合;
可变集合(set):可添加和删除元素,非可哈希的,不能用作字典的键,也不能做其他集合的元素
不可变集合(frozenset):与上面恰恰相反
li=[1,2,3]
s =set(li)
dic={s:''} #TypeError: unhashable type: 'set'
8.2集合的相关操作:
集合通过:set()和frozenset()创建;
s1=set('aaaal')
s2=frozenset('abcd')
print(type(s1)) #<class 'set'>
print(type(s2)) #<class 'frozenset'>
集合本身是无序的,所有不能通过切片来访问集合,只能通过in,not in来访问和判断集合元素;
s1=set('abcd')
print('a' in s1)
print('e' not in s1)
执行结果:
True
True
b
d
a
c
8.3更新集合:
通过如下的方法更新集合:
add()
remove()
update()
8.3.1如上的方法只有在可变集合中才能更新使用;
s1=set('abcd')
s2=frozenset('efch')
s2.add(0) #'frozenset' object has no attribute 'add'
s1=set('abcd')
s2=frozenset('efch')
s1.add('wing') #{'wing', 'c', 'b', 'a', 'd'}
print(s1) #{'c', 'b', 'wing', 'a', 'd'}
s1.update('hello')
print(s1) #{'wing', 'l', 'c', 'o', 'b', 'e', 'a', 'h', 'd'}
s1.remove('a')
print(s1) #{'wing', 'l', 'c', 'o', 'b', 'e', 'h', 'd'}
del 是删除集合本身;
8.4集合的操作类型:
in,not in,
等价==
不等价:!=
子集,超集
s=set('wanghelloworld')
s1=set('wang')
print('w' in s) #True
print(s1 <s) #True
8.4联合:|
联合(union)操作与集合的or操作其实等价的,联合符号有个等价的方法,union();
s=set('wanghelloworld')
s1=set('wang')
s2=s|s1
print(s2) # {'a', 'o', 'g', 'w', 'd', 'l', 'n', 'r', 'h', 'e'}
print(s.union(s1)) #{'a', 'o', 'g', 'w', 'd', 'l', 'n', 'r', 'h', 'e'}
8.5交集:
和and等级,在集合里面的等价方法是:intersection()
s1=set('abc')
s2=set('ahc')
s3=s1&s2
print(s3) #{'c', 'a'}
print(s1.intersection(s2)) #{'c', 'a'}
8.6 差集 -
s1=set('abc')
s2=set('ahc')
s3=s1-s2
print(s3) #{'b'}
print(s1.difference(s2)) #{'b'}
8.7 对称差集:
其等价方法是:symmetric_difference(),就是集合里面的异或,属于s1,和s2,但是不同时属于s1,s2,就是说,s1和s2的所有的元素,去除公共部分;
s1=set('abc')
s2=set('ahc')
s3=s1^s2
print(s3) # {'b', 'h'}
print(s1.symmetric_difference(s2)) #{'b', 'h'}
如下最简单的驱虫方式:
"""最简单的去重方式"""
lis=[1,2,3,4,56,1,2,2]
print(list(set(lis))) #[1, 2, 3, 4, 56]
九:文件操作
文件操作的流程:
1.打开文件,获取文件的句柄,并且赋值给变量;
2.通过句柄对文件进行操作;
3.关闭文件;
锄禾日当午
汗滴和下土
谁知盘种餐
丽丽皆辛苦
美丽的生活
开心的生活
我想好好活 现有如上述的文件;名字为:‘小文件’
f=open('小文件',encoding='utf8')#打开文件
data=f.read()#获取文件的内容
f.close()
备注:如果首次打开使用如下代码会报错;
f=open('小文件')#打开文件
data=f.read()#获取文件的内容
f.close()
执行结果:
Traceback (most recent call last):
File "D:/pytest/Demo/Basictest.py", line 274, in <module>
data=f.read()#获取文件的内容
UnicodeDecodeError: 'gbk' codec can't decode byte 0xa6 in position 4: illegal multibyte sequence
所以:文件是utf8保存的,打开文件时open函数是通过操作系统打开的文件,而win操作系统
默认的是gbk编码,所以直接打开会乱码,需要f=open('小文件',encoding='utf8'),如果小文件如果是gbk保存的,则直接打开即可。所以说:第一段代码加入:encoding='utf8',才不会报错;
9.2文件打开的模式:
'r' open for reading (default)
'w' open for writing, truncating the file first
'x' create a new file and open it for writing
'a' open for writing, appending to the end of the file if it exists
'b' binary mode
't' text mode (default)
'+' open a disk file for updating (reading and writing)
'U' universal newline mode (deprecated)
f=open('小文件',encoding='utf8')#打开文件
data1=f.read()#获取文件内容
print(data1)
接下来我们扩展文件格式:
f = open('小文件','w') #打开文件
f = open('小文件2','a') #打开文件
f.write('云云UN11111\n')
f.write('白了少年头2\n')
f.write('空悲切!3')
f.close()
#r+,w+模式
f = open('小文件2','r+') #以读写模式打开文件
print(f.read(5))#可读
f.write('hello')
print('-------------------')
print(f.read())
f = open('小文件2','w+') #以写读模式打开文件
print(f.read(5))#什么都没有,因为先格式化了文本
f.write('hello alex')
print(f.read())#还是read不到
f.seek(0)
print(f.read())
#w+与a+的区别在于是否在开始覆盖整个文件
# ok,重点来了,我要给文本第三行后面加一行内容:'hello !!!!!!!!!'
# 有同学说,前面不是做过修改了吗? 大哥,刚才是修改内容后print,现在是对文件进行修改!!!
# f = open('小文件2','r+') #以写读模式打开文件
# f.readline()
# print(f.tell())
# f.write('hello !!!!!!!!!!!')
# f.close()
# 和想的不一样,不管事!那涉及到文件修改怎么办呢? # f_read = open('小文件','r') #以读模式打开文件
# f_write = open('小文件_back','w') #以写读模式打开文件
注意1: 无论是py2还是py3,在r+模式下都可以等量字节替换,但没有任何意义的!
注意2:有同学在这里会用readlines得到内容列表,再通过索引对相应内容进行修改,最后将列表重新写会该文件。
这种思路有一个很大的问题,数据若很大,你的内存会受不了的,而我们的方式则可以通过迭代器来优化这个过程
9.4 为了避免打开文件后忘记关闭,可以使用with语句:
with open('小文件','r') as f:
pass
这种方法的方便之处在于:当with执行完毕了,解释器会自动关闭,并释放文件的资源;
在Python3中支持对多个文件打开,在Python2.6之前的版本都是不可以的;
with open('文件1') as obj1, open('文件2') as obj2:
pass
Python之-------基础数据类型的更多相关文章
- python的基础数据类型笔记
注意:此文章基于python3.0以上做的笔记. python的基础数据类型大体有一下几种 一.int int类型有以下几种方法 .bit_length 返回数据在内存中所占的比特位 如下: prin ...
- python的基础数据类型
Python基础数据类型 定义: int => 数字类型 str => 字符串数据类型 bool =>布尔值,True False list 列表,用来存放大量数据 [ ...
- 《Python》 基础数据类型补充和深浅copy
一.基础数据类型的补充 元组: 如果元组中只有一个数据,且没有逗号,则该‘元组’数据类型与里面的数据类型一致 列表: 列表之间可加不可减,可跟数字相乘 l1=['wang','rui'] l2=['c ...
- 【python】 [基础] 数据类型,字符串和编码
python笔记,写在前面:python区分大小写1.科学计数法,把10用e代替,1.23x10·9就是 1.23e9 或者 0.00012就是1 ...
- 07、python的基础-->数据类型、集合、深浅copy
一.数据类型 1.列表 lis = [11, 22, 33, 44, 55] for i in range(len(lis)): print(i) # i = 0 i = 1 i = 2 del li ...
- Python中的基础数据类型
Python中基础数据类型 1.数字 整型a=12或者a=int(2),本质上各种数据类型都可看成是类,声明一个变量时候则是在实例化一个类. 整型具备的功能: class int(object): & ...
- 四.python基础数据类型
一.什么是数据类型? 什么是数据类型? 我们人类可以很容易的分清数字与字符的区别,但是计算机并不能呀,计算机虽然很强大,但从某种角度上看又很傻,除非你明确的告诉它,1是数字,“汉”是文字,否则它是分不 ...
- 第2章 Python编程基础知识 第2.1节 简单的Python数据类型、变量赋值及输入输出
第三节 简单的Python数据类型.变量赋值及输入输出 Python是一门解释性语言,它的执行依赖于Python提供的执行环境,前面一章介绍了Python环境安装.WINDOWS系列Python编辑和 ...
- python学习之数据类型(List)
3.5 列表 3.5.1 列表的介绍 列表是python的基础数据类型之⼀,其他编程语言也有类似的数据类型. 比如JS中的数组, java中的数组等等.它是以[ ]括起来, 每个元素⽤' , '隔 ...
随机推荐
- Java可视操作界面例子
package rom; import java.lang.*; import java.awt.*; import java.awt.event.ActionEvent; import java.a ...
- uva-188-枚举
题意:直接模拟 注意,w[i]不能是0 #include <string> #include<iostream> #include<map> #include< ...
- Python入门-随机漫步
Python入门-随机漫步,贴代码吧,都在代码里面 代码1 class文件 random_walk.py from random import choice class RandomWalk(): # ...
- linux 之 source命令:
source命令: source命令也称为“点命令”,也就是一个点符号(.).source命令通常用于重新执行刚修改的初始化文件,使之立即生效,而不必注销并重新登录. 用法: source filen ...
- Jmeter性能测试基础
压力测试 压力测试分两种场景:一种是单场景,压一个接口的:第二种是混合场景,多个有关联的接口.压测时间,一般场景都运行10-15分钟.如果是疲劳测试,可以压一天或一周,根据实际情况来定. 压测任务 ...
- PHP 扩展在 Linux(centos7)系统下的编译与安装 以 mysqli 为例
(操作系统 Centos7,环境版本 php7) 01,进入到 PHP 解压后的源码包的的 ext 文件夹 02,查看是否存在 mysqli 扩展 => ls, 如果不存在需要去响应网站下载 ( ...
- 抓取mooc中国随笔
// $url = "http://www.baidu.com/"; $url= "https://www.icourse163.org/web/j/courseBean ...
- 机器学习入门-数值特征-数据四分位特征 1.quantile(用于求给定分数位的数值) 2.plt.axvline(用于画出竖线) 3.pd.pcut(对特征进行分位数切分,生成新的特征)
函数说明: 1. .quantile(cut_list) 对DataFrame类型直接使用,用于求出给定列表中分数的数值,这里用来求出4分位出的数值 2. plt.axvline() # 用于画 ...
- day33-常见内置模块二(hashlib、shutil、configparse)
一.hashlib算法介绍 Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等. 1.什么是摘要算法呢? 摘要算法又称哈希算法.散列算法.它通过一个函数,把任意长度的数据转换为一 ...
- linux系统安装java环境
参考资料:实测可用 https://www.cnblogs.com/xuliangxing/p/7066913.html