[Spark Core] Spark Shell 实现 Word Count
0. 说明
在 Spark Shell 实现 Word Count
RDD (Resilient Distributed dataset), 弹性分布式数据集。
示意图
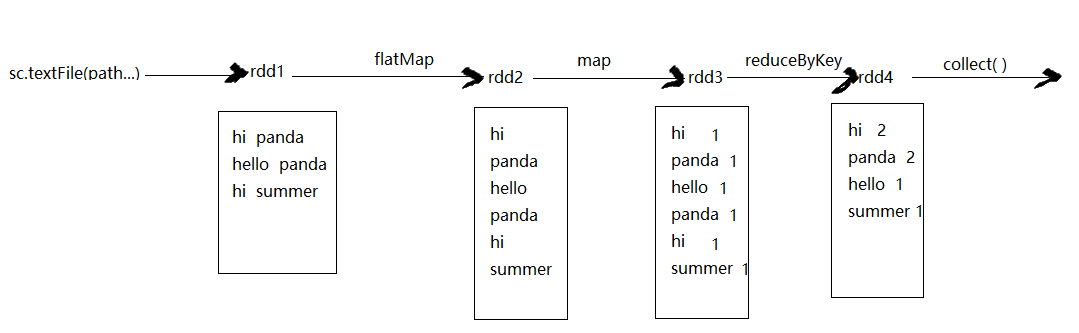
1. 实现
1.1 分步实现
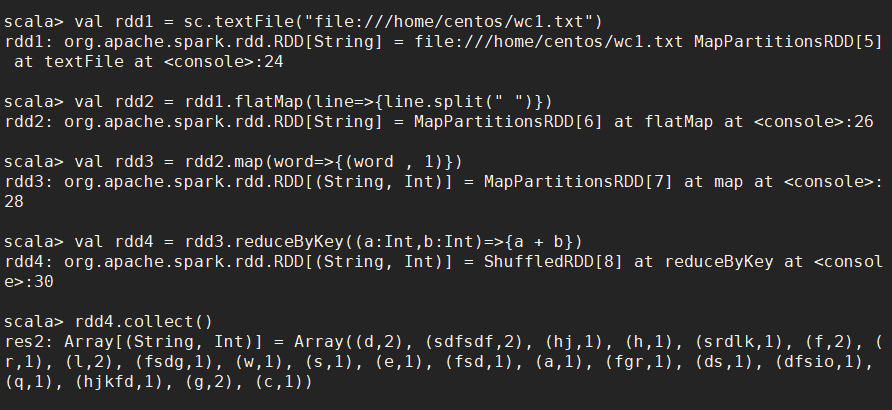
# step 加载文档
val rdd1 = sc.textFile("file:///home/centos/wc1.txt") # step 压扁
val rdd2 = rdd1.flatMap(line=>{line.split(" ")}) # step 标1成对
val rdd3 = rdd2.map(word=>{(word , )}) # step 聚合
val rdd4 = rdd3.reduceByKey((a:Int,b:Int)=>{a + b}) # step
rdd4.collect()
1.2 一步完成 (reduceByKey)
sc.textFile("file:///home/centos/wc1.txt").flatMap(_.split(" ")).map((_,)).reduceByKey(_+_).collect()

1.3 一步完成 (groupByKey)
sc.textFile("file:///home/centos/wc1.txt").flatMap(_.split(" ")).map((_,)).groupByKey().mapValues(_.size).collect()

[Spark Core] Spark Shell 实现 Word Count的更多相关文章
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
- Spark:java api实现word count统计
方案一:使用reduceByKey 数据word.txt 张三 李四 王五 李四 王五 李四 王五 李四 王五 王五 李四 李四 李四 李四 李四 代码: import org.apache.spar ...
- [Spark Core] Spark 实现气温统计
0. 说明 聚合气温数据,聚合出 MAX . MIN . AVG 1. Spark Shell 实现 1.1 MAX 分步实现 # 加载文档 val rdd1 = sc.textFile(" ...
- [Spark Core] Spark Client Job 提交三级调度框架
0. 说明 官方文档 Job Scheduling Spark 调度核心组件: DagScheduler TaskScheduler BackendScheduler 1. DagSchedule ...
- [Spark Core] Spark 核心组件
0. 说明 [Spark 核心组件示意图] 1. RDD resilient distributed dataset , 弹性数据集 轻量级的数据集合,逻辑上的集合.等价于 list 没有携带数据. ...
- [Spark Core] Spark 使用第三方 Jar 包的方式
0. 说明 Spark 下运行job,使用第三方 Jar 包的 3 种方式. 1. 方式一 将第三方 Jar 包分发到所有的 spark/jars 目录下 2. 方式二 将第三方 Jar 打散,和我们 ...
- 【待补充】[Spark Core] Spark 实现标签生成
0. 说明 在 IDEA 中编写 Spark 代码实现将 JSON 数据转换成标签,分别用 Scala & Java 两种代码实现. 1. 准备 1.1 pom.xml <depend ...
- [Spark Core] Spark 在 IDEA 下编程
0. 说明 Spark 在 IDEA 下使用 Scala & Spark 在 IDEA 下使用 Java 编写 WordCount 程序 1. 准备 在项目中新建模块,为模块添加 Maven ...
- shell 实现word count
awk '{arr[$2]+=$1}END{for (i in arr) print i,arr[i]}' sort_all.txt | sort -k2nr -g
随机推荐
- python get请求
#!/usr/bin/python #-*- coding:UTF-8 -*-#coding=utf-8 import requests import time import hashlib impo ...
- JVM内存结构(转)
所有的Java开发人员可能会遇到这样的困惑?我该为堆内存设置多大空间呢?OutOfMemoryError的异常到底涉及到运行时数据的哪块区域?该怎么解决呢?其实如果你经常解决服务器性能问题,那么这些问 ...
- (转)Spring事务管理(详解+实例)
文章转自:http://blog.csdn.net/trigl/article/details/50968079 写这篇博客之前我首先读了<Spring in action>,之后在网上看 ...
- JS作用域,作用域,作用链详解
前言 通过本文,你大概明白作用域,作用域链是什么,毕竟这也算JS中的基本概念. 一.作用域(scope) 什么是作用域,你可以理解为你所声明变量的可用范围,我在某个范围内申明了一个变量,且这个变量 ...
- ASP.NET MVC验证码演示(Ver2)
前一版本<ASP.NET MVC验证码演示>http://www.cnblogs.com/insus/p/3622116.html,Insus.NET还是使用了Generic handle ...
- jQuery UI的datepicker()与变更格式
继续MVC应用程序的练习,刚刚练习了jQuery的UI中的datepicker()的方法,它是为了让用户能在文本框中快捷输入日期. 代码简洁与简单. 打开以前练习的一个视图Views\Home\Ind ...
- SQL SERVER 查看SQL语句IO,时间,索引消耗
1.查看SQL语句IO消耗 set statistics io on select * from dbo.jx_order where order_time>'2011-04-12 12 ...
- [日常] Go语言圣经--包和文件-导入包习题
1.每个包都有一个全局唯一的导入路径 2.按照惯例,一个包的名字和包的导入路径的最后一个字段相同 练习 2.2: 写一个通用的单位转换程序,用类似cf程序的方式从命令行读取参数,如果缺省的话则是从标准 ...
- Java基础——JSP(二)
一.JSP隐式对象概述 为了简化jsp表达式和脚本片断代码的编写,JSP一共提供了9个预先定义的变量,这些变量也称为隐式对象或内置对象. 在 jsp生成的Servlet源码中,有如下声明: publi ...
- Spring IOC 容器源码分析
声明!非原创,本文出处 Spring 最重要的概念是 IOC 和 AOP,本篇文章其实就是要带领大家来分析下 Spring 的 IOC 容器.既然大家平时都要用到 Spring,怎么可以不好好了解 S ...