Scala进阶之路-I/O流操作之文件处理
Scala进阶之路-I/O流操作之文件处理
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
说起Scala语言操作文件对象其实是很简单的,大部分代码和Java相同。
一.使用Scala拷贝文件实现
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Scala%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.file import java.io._ object FileDemo {
/**
* 定义读取文件的方法
*/
def readFile(filePath:String): Unit ={
val f = new File(filePath)
val fis = new FileInputStream(f)
val buf = new BufferedReader(new InputStreamReader(fis))
var line = "";
/**
* 我这里定义一个标志位,判断文件是否读取完毕,不建议使用break,不仅仅是因为它需要导报,而是因为它是以抛异常的
* 方式结束了整个程序!这一点我真的想吐槽Scala啦!比起Python,Java,Golang,Scala是没有continue和break关键字的!
*/
var flag:Boolean= true
while (flag){
line = buf.readLine()
//注意,Scala在读取文件时,如果读到最后会返回一个null值,因此,此时我们将标志位改为false,以便下一次结束while循环
if (line == null){
flag = false
}else{
println(line)
}
}
buf.close()
fis.close()
} /**
* 拷贝文本文件
*/
def copyFile(Input:String)(OutPut:String): Unit ={
val input = new File(Input)
val output = new File(OutPut)
val fis = new FileInputStream(input)
val fos = new FileOutputStream(output)
val buf = new BufferedReader(new InputStreamReader(fis))
val cache = new BufferedWriter(new OutputStreamWriter(fos))
var line = "";
var flag:Boolean= true
while (flag){
line = buf.readLine()
if (line == null){
flag = false
}else{
cache.write(line)
cache.write("\r\n")
cache.flush()
}
}
cache.close()
fos.close()
fis.close()
println("拷贝完毕")
} /**
* 拷贝任意类型文件,包括二进制文件
*/
def copyFile2(Input:String)(OutPut:String): Unit ={
val fis = new FileInputStream(Input)
val fos = new FileOutputStream(OutPut)
//定义缓冲区
val buf = new Array[Byte](1024)
var len = 0 /**
* 注意:len = fis.read(buf)是一个赋值操作,这个赋值操作是没有任何的返回值的哟!因此我们需要返回len的值。
*/
while ({len = fis.read(buf);len} != -1){
fos.write(buf,0,len)
}
fos.close()
fis.close()
println("拷贝完毕")
} def main(args: Array[String]): Unit = {
var input = "D:\\BigData\\JavaSE\\yinzhengjieData\\1.java"
var output = "D:\\BigData\\JavaSE\\yinzhengjieData\\2.java"
// readFile(input)
copyFile2(input)(output)
}
} /*
以上代码输出结果如下 :
拷贝完毕
*/
二.读取用户的输出
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Scala%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.file import scala.io.StdIn object ConsoleDemo {
def main(args: Array[String]): Unit = {
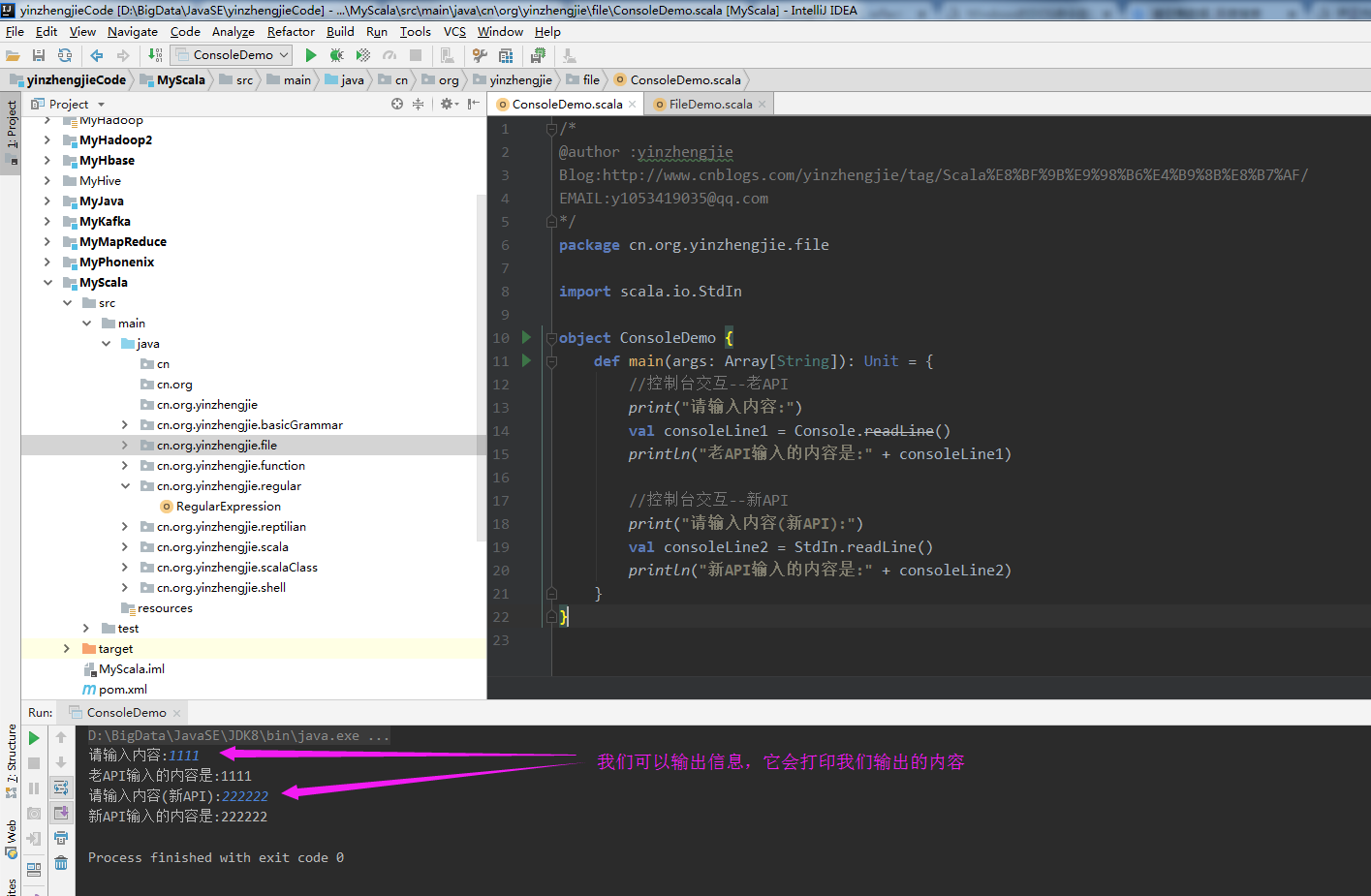
//控制台交互--老API
print("请输入内容:")
val consoleLine1 = Console.readLine()
println("老API输入的内容是:" + consoleLine1) //控制台交互--新API
print("请输入内容(新API):")
val consoleLine2 = StdIn.readLine()
println("新API输入的内容是:" + consoleLine2)
}
}
以上代码执行结果如下:
三.Scala文件处理常用方法
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Scala%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.file object SourceDemo {
def main(args: Array[String]): Unit = {
var input = "D:\\BigData\\JavaSE\\yinzhengjieData\\1.java"
val f = scala.io.Source.fromFile(input)
println(f) /**
* 迭代打印文件中的每行内容
*/
// val it = f.getLines()
// for(x <- it){
// println(x)
// } /**
* 读取整个文件串
*/
println(f.mkString) /**
* 迭代每个字符
*/
// for(c <- f){
// print(c)
// } /**
* 使用正则 s:空白符 S:非空白符
* 所谓的空白符就是指:空格,制表符,换行符等等
*/
// val arr = f.mkString.split("\\s+")
// for(a <- arr){
// println(a)
// } }
}
使用Scala爬取网页,在网上找了一些写的都长篇大论,属实懒得看,爬虫的话建议还是用Java或者Python去写,Java爬取网页的笔记可参考:https://www.cnblogs.com/yinzhengjie/p/9366013.html。
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Scala%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.file import java.io.FileOutputStream object ReptilianDemo { def copyFile(Input:String)(OutPut:String): Unit ={
val fos = new FileOutputStream(OutPut)
fos.write(Input.getBytes())
println("拷贝完毕")
} def main(args: Array[String]): Unit = {
/**
* Scala的fromURL方法我是不推荐使用的,因为爬去的内容不完全,需要设置相应的参数,建议用java代码或者Python去爬取
* 可参考:https://www.cnblogs.com/yinzhengjie/p/9366013.html
*/
val res = scala.io.Source.fromURL("https://www.cnblogs.com/yinzhengjie")
val html = res.mkString
println(html)
var output = "D:\\BigData\\JavaSE\\yinzhengjieData\\尹正杰.html"
copyFile(html)(output) }
}
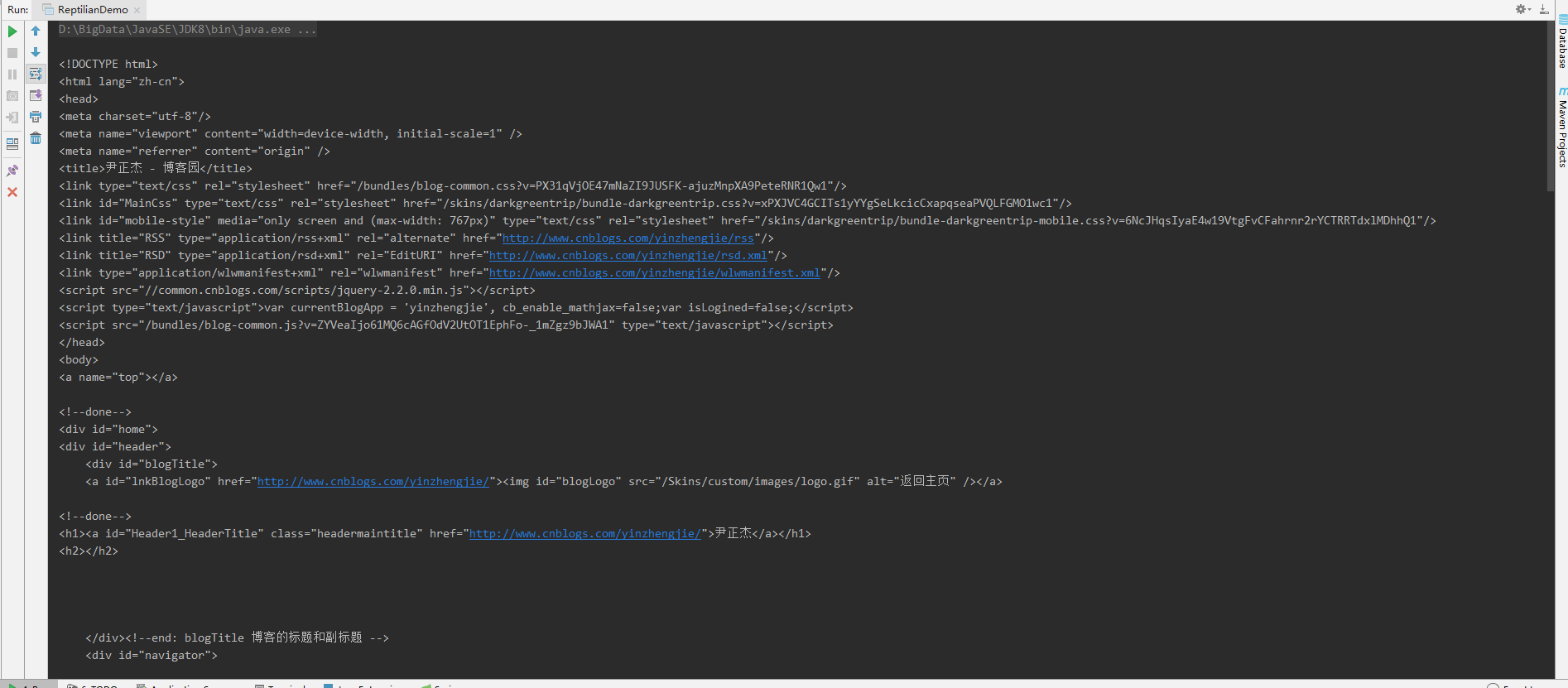
访问成功的话,在控制端会打印如下信息:
Scala进阶之路-I/O流操作之文件处理的更多相关文章
- Scala进阶之路-Spark本地模式搭建
Scala进阶之路-Spark本地模式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Spark简介 1>.Spark的产生背景 传统式的Hadoop缺点主要有以下两 ...
- Scala进阶之路-Spark独立模式(Standalone)集群部署
Scala进阶之路-Spark独立模式(Standalone)集群部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们知道Hadoop解决了大数据的存储和计算,存储使用HDFS ...
- Scala进阶之路-Spark底层通信小案例
Scala进阶之路-Spark底层通信小案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Spark Master和worker通信过程简介 1>.Worker会向ma ...
- Scala进阶之路-尾递归优化
Scala进阶之路-尾递归优化 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 递归调用有时候能被转换成循环,这样能节约栈空间.在函数式编程中,这是很重要的,我们通常会使用递归方法来 ...
- Scala进阶之路-面向对象编程之类的成员详解
Scala进阶之路-面向对象编程之类的成员详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Scala中的object对象及apply方法 1>.scala 单例对象 ...
- Scala进阶之路-高级数据类型之集合的使用
Scala进阶之路-高级数据类型之集合的使用 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Scala 的集合有三大类:序列 Seq.集 Set.映射 Map,所有的集合都扩展自 ...
- Scala进阶之路-高级数据类型之数组的使用
Scala进阶之路-高级数据类型之数组的使用 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.数组的初始化方式 1>.长度不可变数组Array 注意:顾名思义,长度不可变数 ...
- Scala进阶之路-Scala函数篇详解
Scala进阶之路-Scala函数篇详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.传值调用和传名调用 /* @author :yinzhengjie Blog:http: ...
- Scala进阶之路-Scala的基本语法
Scala进阶之路-Scala的基本语法 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.函数式编程初体验Spark-Shell之WordCount var arr=Array( ...
随机推荐
- ASP.NET多行文本框限制字符个数
asp.net中TextBox当设置TextMode = Multiline时,其MaxLength属性无效.可使用JS进行辅助限制输入的字符个数.中文算两个字符,西文算1个字符. TextBox属性 ...
- OPENSTACK重装系统失败导致虚拟机状态为error
重装系统失败导致虚拟机状态为error DASHBOARD查看虚拟机状态: 查看日志: 磁盘不足导致下载新镜像失败. Virsh list -all 无法发现虚拟机,底层盘消失(因为重装系统时nova ...
- 绕WAF&安全狗新姿势
俗话说只要思路宽,绕狗绕的欢.前段时间我有尝试着用以下的方法绕狗,效果还不错.不过这方法呢也许这段时间可以绕过,过段时间可能就失效了,大家还是要多去尝试找到更多的方法. 举例-->整型注入 绕过 ...
- django反向解析URL和URL命名空间
django反向解析URL和URL命名空间 首先明确几个概念: 1.在html页面上的内容特别是向用户展示的url地址,比如常见的超链接,图片链接等,最好能动态生成,而不要固定. 2.一个django ...
- Git多人协作工作流程
前言 之前一直把Git当做个人版本控制的工具使用,现在由于工作需要,需要多人协作维护文档,所以去简单了解了下Git多人协作的工作流程,发现还真的很多讲解的,而且大神也已经讲解得很清楚了,这里就做一个简 ...
- PAT甲题题解-1008. Elevator (20)-大么个大水题,这也太小瞧我们做题者的智商了
如题... #include <iostream> #include <cstdio> #include <algorithm> #include <cstr ...
- This is me
This is me 爱琴棋 爱书画 也爱格物 爱跋山 爱涉水 也爱深林 This is me. 刘伯承的诗词有曰“高耸入云”,于是“李入云”便成为了我一生的标记,也造就了一个时而安静,时而疯狂的我 ...
- 20135220谈愈敏Blog4_系统调用(上)
系统调用(上) 谈愈敏 原创作品转载请注明出处 <Linux内核分析>MOOC课程 http://mooc.study.163.com/course/USTC-1000029000 用户态 ...
- 20135337朱荟潼 Linux第七周学习总结——可执行程序的装载
朱荟潼 + 原创作品转载请注明出处 + <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 第七周 Linu ...
- PAT 甲级 1106 Lowest Price in Supply Chain
https://pintia.cn/problem-sets/994805342720868352/problems/994805362341822464 A supply chain is a ne ...