大数据入门第二十天——scala入门(一)入门与配置
一、概述
1.什么是scala
Scala是一种多范式的编程语言,其设计的初衷是要集成面向对象编程和函数式编程的各种特性。Scala运行于Java平台(Java虚拟机),并兼容现有的Java程序。
scala 特性:
面向对象特性、
函数式编程
静态类型
扩展性
并发性
详细的阐述,参考菜鸟教程:http://www.runoob.com/scala/scala-intro.html
易百教程:https://www.yiibai.com/scala/scala_overview.html
通过官网的一句话总结:当面向对象遇上函数式编程。
到今天(2018年),scala 已经15岁了!
2.scala 如何工作
- 编译成Java字节码
- 可在任何标准JVM上运行
- 甚至是一些不规范的JVM上,如Dalvik
- Scala编译器是Java编译器的作者写的
3.为什么选择scala
作者:吴雪峰
链接:https://www.zhihu.com/question/27630156/answer/37598031
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 我想大部分应用开发程序员,最关键是看有什么类库合适的方便特定领域的应用开发。
就像ruby有rails做web开发,你可以去论证ruby优缺点,但实际上应用开发效率提升很大程度上依靠类库。
现在Spark是大数据领域的杀手级应用框架,BAT,我们现在几个领域巨头的客户(有保密协议不方便透露)都全面使用Spark了,
这个时候再谈Scala适不适合大数据开发其实意义不大。因为大家比的不只是编程语言,而是构建在这个编程语言之上的类库、
社区和生态圈(包括文档和数据、衍生类库、商业技术支持、成熟产品等等)。那么反过来问,为什么Spark会选择Scala可能更有意义一点。
Spark主创Matei在不同场合回答两次这个问题,思考的点稍微不一样,但重点是一样的,很适合回答题主的问题。总结来说最主要有三点: . API能做得优雅; 这是框架设计师第一个要考虑的问题,框架的用户是应用开发程序员,API是否优雅直接影响用户体验。 . 能融合到Hadoop生态圈,要用JVM语言; Hadoop现在是大数据事实标准,Spark并不是要取代Hadoop,而是要完善Hadoop生态。
JVM语言大部分可能会想到Java,但Java做出来的API太丑,或者想实现一个优雅的API太费劲。 . 速度要快; Scala是静态编译的,所以和JRuby,Groovy比起来速度会快很多,非常接近Java。关于Scala性能的问题,
主要分两种情况, . Scala的基准性能很接近Java,但确实没有Java好。但很多任务的单次执行的,性能损失在毫秒级不是什么问题; . 在大数据计算次数很多的情况下,我们全部写成命令式,而且还要考虑GC,JIT等基于JVM特性的优化。Scala很难是个很含糊的问题,
关键是要看你想达到什么目的。我们培训客户做Spark开发,基本上一两个星期就可以独立工作了。当然师傅领进门,修行靠个人
,一两个星期能独立工作不代表能马上成为Scala或Spark专家。
这里回答主要针对大数据产品应用开发,不是大数据分析。大数据分析是个更泛的话题,包括大数据分析实验和大数据分析产品等。
实验关心建模和快速试不同方式,产品关心稳定、可拓展性。大数据分析实验首选R(SAS),python和Matlab, 通常只拿真实数据的一小部分,
在一个性能很好的单机上试各种想法。Scala目前在大数据分析实验上没有太多优势,不过现在有人在做R语言的Scala实现,
可以无缝和Spark等大数据平台做衔接。当然现在也已经有SparkR了,可能用R和Spark做交互。
二、安装
1.前置条件
安装JDK
2.下载scala
前往官网下载msi 的安装包,这里选择和spark兼容的2.10版本中的2.10.6的版
注意此版本不允许安装目录有空格(默认的Program Files 不可用!)
3.配置环境变量
SCALA_HOME: 变量值一栏输入:F:\scala
Path追加:%SCALA_HOME%\bin;%SCALA_HOME%\jre\bin;
(WIN 10分两项追加)
4.验证
scala -version
三、安装IDEA的scala插件
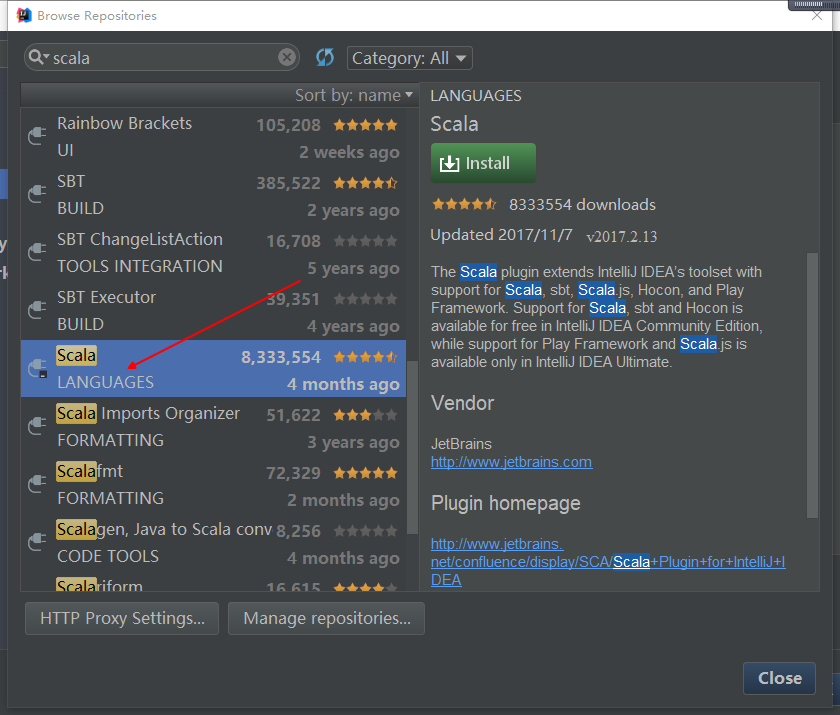
重启完成插件的安装、
三、基础知识
1.交互式编程
在cmd窗口输入scala即可
$ scala
Welcome to Scala version 2.11.7 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_31).
Type in expressions to have them evaluated.
Type :help for more information. scala> 1 + 1
res0: Int = 2 scala> println("Hello World!")
Hello World! scala>
2.注释
与Java保持一致
3.包
定义包与导包与Java一致
4.访问修饰符
Scala 访问修饰符基本和Java的一样,分别有:private,protected,public。
如果没有指定访问修饰符符,默认情况下,Scala对象的访问级别都是 public。
Scala 中的 private 限定符,比 Java 更严格,在嵌套类情况下,外层类甚至不能访问被嵌套类的私有成员。
在 scala 中,对保护(Protected)成员的访问比 java 更严格一些。因为它只允许保护成员在定义了该成员的的类的子类中被访问(Java本包和子类)。
5.结束符
结束符分号;在scala是可选的(通常IDEA会提示是多余的)
大数据入门第二十天——scala入门(一)入门与配置的更多相关文章
- 大数据入门第二十天——scala入门(二)scala基础01
一.基础语法 1.变量类型 // 上表中列出的数据类型都是对象,也就是说scala没有java中的原生类型.在scala是可以对数字等基础类型调用方法的. 2.变量声明——能用val的尽量使用val! ...
- 大数据入门第二十天——scala入门(二)scala基础02
一. 类.对象.继承.特质 1.类 Scala的类与Java.C++的类比起来更简洁 定义: package com.jiangbei //在Scala中,类并不用声明为public. //Scala ...
- 大数据入门第二十一天——scala入门(二)并发编程Akka
一.概述 1.什么是akka Akka基于Actor模型,提供了一个用于构建可扩展的(Scalable).弹性的(Resilient).快速响应的(Responsive)应用程序的平台. 更多入门的基 ...
- 大数据入门第二十一天——scala入门(一)并发编程Actor
注:我们现在学的Scala Actor是scala 2.10.x版本及以前版本的Actor. Scala在2.11.x版本中将Akka加入其中,作为其默认的Actor,老版本的Actor已经废弃 一. ...
- 大数据入门第十九天——推荐系统与mahout(一)入门与概述
一.推荐系统概述 为了解决信息过载和用户无明确需求的问题,找到用户感兴趣的物品,才有了个性化推荐系统.其实,解决信息过载的问题,代表性的解决方案是分类目录和搜索引擎,如hao123,电商首页的分类目录 ...
- 大数据入门第十七天——storm上游数据源 之kafka详解(一)入门与集群安装
一.概述 1.kafka是什么 根据标题可以有个概念:kafka是storm的上游数据源之一,也是一对经典的组合,就像郭德纲和于谦 根据官网:http://kafka.apache.org/intro ...
- 大数据入门第十七天——storm上游数据源 之kafka详解(三)其他问题
一.kafka文件存储机制 1.topic存储 在Kafka文件存储中,同一个topic下有多个不同partition,每个partition为一个目录,partiton命名规则为topic名称+有序 ...
- 大数据入门第三天——基础补充与ActiveMQ
一.多线程基础回顾 先导知识在基础随笔篇:http://www.cnblogs.com/jiangbei/p/6664555.html 以下此部分以补充为主 1.概念 进程:进行中的程序,内存中有独立 ...
- 大数据入门第五天——离线计算之hadoop(上)概述与集群安装
一.概述 根据之前的凡技术必登其官网的原则,我们当然先得找到它的官网:http://hadoop.apache.org/ 1.什么是hadoop 先看官网介绍: The Apache™ Hadoop® ...
随机推荐
- webstorm技巧
webstorm安装后的一些设置技巧: 如何更改主题(字体&配色):File -> settings -> Editor -> colors&fonts -> ...
- SD从零开始19-20
SD从零开始19 免费货物(Free Goods) 包含和不包含赠品数量Exclusive and Inclusive Bonus Quantities 在一些产业领域,例如零售,化工行业,消费品行业 ...
- PHP学习目标
课程阶段学习目标 阶段一: 目标:能够使用DIV+CSS布局出任意的网页页面 说明:根据PSD图设计,使用DIV+CSS布局符合WEB标准.多浏览器兼容的网页,能建立网站制作所需要的模板 阶段二: 目 ...
- Python+Selenium笔记(十四)鼠标与键盘事件
(一) 前言 Webdriver高级应用的API,允许我们模拟简单到复杂的键盘和鼠标事件,如拖拽操作.快捷键组合.长按以及鼠标右键操作,都是通过使用webdriver的Python API 中的Ac ...
- beego快速入门
beego的官方网址:https://beego.me 参考文档:https://beego.me/quickstart 1:安装 您需要安装 Go 1.1+ 以确保所有功能的正常使用. 需要已经设置 ...
- Linux下动态链接库加载路径
引子 近日,服务器迁移后,偷懒未重新编译nginx的,直接./nginx启动,结果遇到如下问题: "error while loading shared libraries" 这是 ...
- C# 实例化的执行顺序(转)
首先进行细分1.类的成员分为:字段,属性,方法,构造函数2.成员修饰符:静态成员,实例成员不考虑继承的关系执行顺序为:1.静态字段2.静态构造方法3.实例字段4.实例构造方法其中 属性和方法只有在调用 ...
- RBAC用户角色权限设计方案【转载】
RBAC(Role-Based Access Control,基于角色的访问控制),就是用户通过角色与权限进行关联.简单地说,一个用户拥有若干角色,每一个角色拥有若干权限.这样,就构造成“用户-角色- ...
- TSQL使用ADHOC访问Excle文件
如题,今天正好碰到这个问题,现将相关知识点记录如下: --开启高级配置功能 reconfigure --开启导入功能 reconfigure --允许在进程中使用ACE.OLEDB.12 --允许使用 ...
- sql server数据导入导出方法统计
常用的数据量不是很大的情况的几种方法:转载地址 http://www.cnblogs.com/changbluesky/archive/2010/06/23/1761779.html 大数据量的推荐导 ...