Kafka与Logstash的数据采集对接
Logstash工作原理
由于Kafka采用解耦的设计思想,并非原始的发布订阅,生产者负责产生消息,直接推送给消费者。而是在中间加入持久化层——broker,生产者把数据存放在broker中,消费者从broker中取数据。这样就带来了几个好处::
1 生产者的负载与消费者的负载解耦
2 消费者按照自己的能力fetch数据
3 消费者可以自定义消费的数量
由于broker采用了主题topic–>分区的思想,使得某个分区内部的顺序可以保证有序性,但是分区间的数据不保证有序性。这样,消费者可以以分区为单位,自定义读取的位置——offset。
Kafka采用zookeeper作为管理,记录了producer到broker的信息,以及consumer与broker中partition的对应关系。因此,生产者可以直接把数据传递给broker,broker通过zookeeper进行leader–>followers的选举管理;消费者通过zookeeper保存读取的位置offset以及读取的topic的partition分区信息。
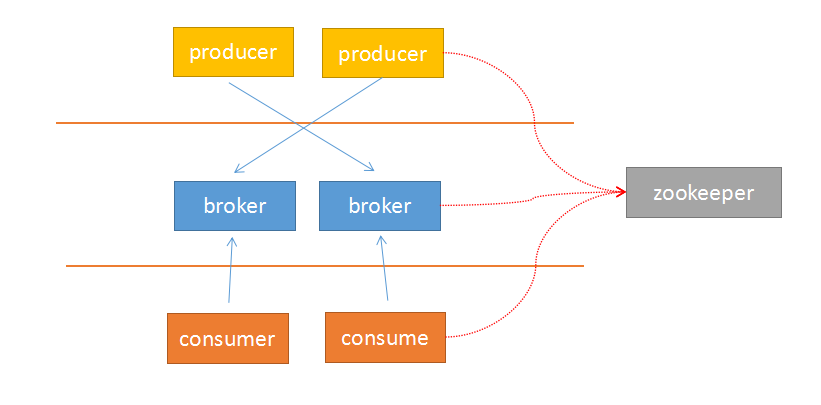
由于上面的架构设计,使得生产者与broker相连;消费者与zookeeper相连。有了这样的对应关系,就容易部署logstash–>kafka–>logstash的方案了。
接下来,按照下面的步骤就可以实现logstash与kafka的对接了。

启动zookeeper
$zookeeper/bin/zkServer.sh start
启动kafka
$kafka/bin/kafka-server-start.sh $kafka/config/server.properties &
创建主题
$kafka/bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --create --topic hello --replication-factor 1 --partitions 1
查看主题
$kafka/bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --describe
测试环境
执行生存者脚本
$kafka/bin/kafka-console-producer.sh --broker-list 10.0.67.101:9092 --topic hello
执行消费者脚本
$kafka/bin/kafka-console-consumer.sh --zookeeper 127.0.0.1:2181 --from-beginning --topic hello
测试输入
input{stdin{}}output{kafka{topic_id => "hello"bootstrap_servers => "192.168.0.4:9092" # kafka的地址batch_size => 5}stdout{codec => rubydebug}}
读取测试
input{kafka {codec => "plain"group_id => "logstash1"auto_offset_reset => "smallest"reset_beginning => truetopic_id => "hello"#white_list => ["hello"]#black_list => nilzk_connect => "192.168.0.5:2181" # zookeeper的地址}}output{stdout{codec => rubydebug}}
Kafka与Logstash的数据采集对接的更多相关文章
- Kafka与Logstash的数据采集对接 —— 看图说话,从运行机制到部署
基于Logstash跑通Kafka还是需要注意很多东西,最重要的就是理解Kafka的原理. Logstash工作原理 由于Kafka采用解耦的设计思想,并非原始的发布订阅,生产者负责产生消息,直接推送 ...
- Kafka与Logstash的数据采集
Kafka与Logstash的数据采集 基于Logstash跑通Kafka还是需要注意很多东西,最重要的就是理解Kafka的原理. Logstash工作原理 由于Kafka采用解耦的设计思想,并非原始 ...
- kafka(logstash) + elasticsearch 构建日志分析处理系统
第一版:logstash + es 第二版:kafka 替换 logstash的方案
- Kafka、Logstash、Nginx日志收集入门
Nginx作为网站的第一入口,其日志记录了除用户相关的信息之外,还记录了整个网站系统的性能,对其进行性能排查是优化网站性能的一大关键. Logstash是一个接收,处理,转发日志的工具.支持系统日志, ...
- 海量日志分析方案--logstash+kibnana+kafka
下图为唯品会在qcon上面公开的日志处理平台架构图.听后觉得有些意思,好像也可以很容易的copy一个,就动手尝试了一下. 目前只对flume===>kafka===>elacsticSea ...
- ELK架构下利用Kafka Group实现Logstash的高可用
系统运维的过程中,每一个细节都值得我们关注 下图为我们的基本日志处理架构 所有日志由Rsyslog或者Filebeat收集,然后传输给Kafka,Logstash作为Consumer消费Kafka里边 ...
- 【ELK】【docker】【elasticsearch】2.使用elasticSearch+kibana+logstash+ik分词器+pinyin分词器+繁简体转化分词器 6.5.4 启动 ELK+logstash概念描述
官网地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html#docker-cli-run-prod ...
- ELK + kafka 日志方案
概述 本文介绍使用ELK(elasticsearch.logstash.kibana) + kafka来搭建一个日志系统.主要演示使用spring aop进行日志收集,然后通过kafka将日志发送给l ...
- ELK + kafka 分布式日志解决方案
概述 本文介绍使用ELK(elasticsearch.logstash.kibana) + kafka来搭建一个日志系统.主要演示使用spring aop进行日志收集,然后通过kafka将日志发送给l ...
随机推荐
- Python2.7-copy_reg
copy_reg 模块,提供了在 pickle 或是 copy 特定对象时,可以运行一个指定的函数,作为对象的构造器 模块方法: copy_reg.constructor(object):声明一个可调 ...
- easyui validatebox textbox 使用例子
<%@ Page Language="C#" AutoEventWireup="true" CodeBehind="WebFormTextbox ...
- *p++,*++p,*(p++),*(++p)
直接上代码: #include <stdio.h> #include <stdlib.h> int main () { ,,,}; ; int *p, *tmp; p = &a ...
- python 23 种 设计模式
频率 所属类型 模式名称 模式 简单定义 5 创建型 Singleton 单件 保证一个类只有一个实例,并提供一个访问它的全局访问点. 4 创建型 Abstract Factory 抽象工厂 提供一个 ...
- GIT命令基本使用
记录摘选自廖雪峰的官方网站归纳总结 1.centos下安装git [root@cdw-lj ~]# yum install git 2.配置用户名以及邮箱 [root@cdw-lj opt]# git ...
- libgdx学习记录15——音乐Music播放
背景音乐是游戏中必备的元素,好的背景音乐能为游戏加分不少,使人更容易融入到游戏的氛围中去. Music类中主要有以下函数: play()播放 stop()停止 pause()暂停 setVolume( ...
- falsk之文件上传
在使用flask定义路由完成文件上传时,定义upload视图函数 from flask import Flask, render_template from werkzeug.utils import ...
- Android Studio Xposed模块编写(二)
阅读本文前,假设读者已经看过Android Studio Xposed模块编写(一) 相关环境已经搭建完成.本文演示案例与上文环境一致,不在赘述. 1.概述 Xposed是非常牛叉的一款hook框架 ...
- 并发编程(Concurrent programming)
并发编程(Concurrent programming) 1.并发编程概述 2.委托(delegate) 3.事件(event) 4.线程(thread) 5.线程池(threadPool) 6.任务 ...
- Redis简介、安装、配置、启用学习笔记
前一篇文章有介绍关系型数据库和非关系型数据库的差异,现在就来学习一下用的较广的非关系型数据库:Redis数据库 Redis 简介 Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-v ...