Kafka设计解析(二十二)Flink + Kafka 0.11端到端精确一次处理语义的实现
本文是翻译作品,作者是Piotr Nowojski和Michael Winters。前者是该方案的实现者。
原文地址是An Overview of End-to-End Exactly-Once Processing in Apache Flink® (with Apache Kafka, too!)。
目录
一、Flink应用的EOS
二、Flink实现EOS应用
三、Flink中实现两阶段提交operator
四、总结
2017年12月Apache Flink社区发布了1.4版本。该版本正式引入了一个里程碑式的功能:两阶段提交Sink,即TwoPhaseCommitSinkFunction。该SinkFunction提取并封装了两阶段提交协议中的公共逻辑,自此Flink搭配特定source和sink(特别是0.11版本Kafka)搭建精确一次处理语义(下称EOS)应用成为了可能。作为一个抽象类,TwoPhaseCommitSinkFunction提供了一个抽象层供用户自行实现特定方法来支持EOS。
用户可以阅读Java文档来学习如何使用TwoPhaseCommitSinkFunction,或者参考Flink官网文档来了解FlinkKafkaProducer011是如何支持EOS的,因为后者正是基于TwoPhaseCommitSinkFunction实现的。
本文将深入讨论一下Flink 1.4这个新特性以及其背后的设计思想。在本文中我们将:
- 描述Flink应用中的checkpoint如何帮助确保EOS
- 展示Flink如何通过两阶段提交协议与source和sink交互以实现端到端的EOS交付保障
- 给出一个使用TwoPhaseCommitSinkFunction实现EOS的文件Sink实例
一、Flink应用的EOS
当谈及“EOS”时,我们真正想表达的是每条输入消息只会影响最终结果一次!【译者:影响应用状态一次,而非被处理一次】即使出现机器故障或软件崩溃,Flink也要保证不会有数据被重复处理或压根就没有被处理从而影响状态。长久以来Flink一直宣称支持EOS是指在一个Flink应用内部。在过去的几年间,Flink开发出了checkpointing机制,而它则是提供这种应用内EOS的基石。参考官网这篇文章来了解checkpointing机制。
在继续之前我们简要总结一下checkpointing算法,这对于我们了解本文内容至关重要。简单来说,一个Flink checkpoint是一个一致性快照,它包含:
- 应用的当前状态
- 输入流位置
Flink会定期地产生checkpoint并且把这些checkpoint写入到一个持久化存储上,比如S3或HDFS。这个写入过程是异步的,这就意味着Flink即使在checkpointing过程中也是不断处理输入数据的。
如果出现机器或软件故障,Flink应用重启后会从最新成功完成的checkpoint中恢复——重置应用状态并回滚状态到checkpoint中输入流的正确位置,之后再开始执行数据处理,就好像该故障或崩溃从未发生过一般。
在Flink 1.4版本之前,EOS只限于Flink应用内。Flink处理完数据后需要将结果发送到外部系统,这个过程中Flink并不保证EOS。但是Flink应用通常都需要接入很多下游子系统,而开发人员很希望能在多个系统上维持EOS,即维持端到端的EOS。
为了提供端到端的EOS,EOS必须也要应用于Flink写入数据的外部系统——故这些外部系统必须提供一种手段允许提交或回滚这些写入操作,同时还要保证与Flink checkpoint能够协调使用。
在分布式系统中协调提交和回滚的一个常见方法就是使用两阶段提交协议。下一章节中我们将讨论下Flink的TwoPhaseCommitSinkFunction是如何利用两阶段提交协议来实现EOS的。
二、Flink实现EOS应用
我们将给出一个实例来帮助了解两阶段提交协议以及Flink如何使用它来实现EOS。该实例从Kafka中读取数据,经处理之后再写回到Kafka。Kafka是非常受欢迎的消息引擎,而Kafka 0.11.0.0版本正式发布了对于事务的支持——这是与Kafka交互的Flink应用要实现端到端EOS的必要条件。
当然,Flink支持这种EOS并不只是限于与Kafka的绑定,你可以使用任何source/sink,只要它们提供了必要的协调机制。举个例子,Pravega是Dell/EMC的一个开源流式存储系统,Flink搭配它也可以实现端到端的EOS。
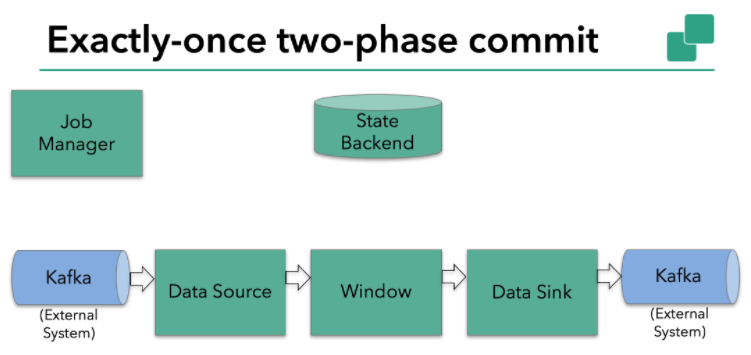
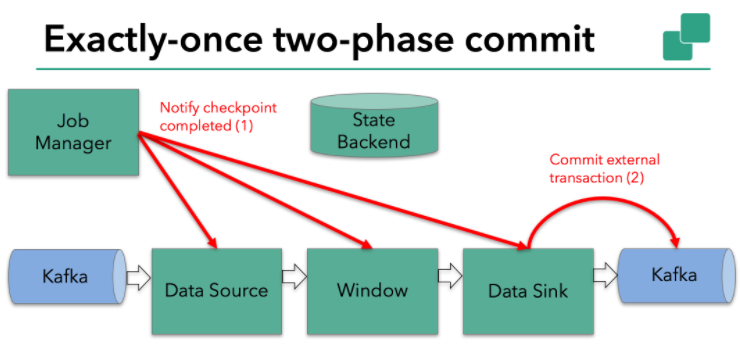
本例中的Flink应用包含以下组件,如上图所示:
- 一个source,从Kafka中读取数据(即KafkaConsumer)
- 一个时间窗口化的聚会操作
- 一个sink,将结果写回到Kafka(即KafkaProducer)
若要sink支持EOS,它必须以事务的方式写数据到Kafka,这样当提交事务时两次checkpoint间的所有写入操作当作为一个事务被提交。这确保了出现故障或崩溃时这些写入操作能够被回滚。
当然了,在一个分布式且含有多个并发执行sink的应用中,仅仅执行单次提交或回滚是不够的,因为所有组件都必须对这些提交或回滚达成共识,这样才能保证得到一个一致性的结果。Flink使用两阶段提交协议以及预提交(pre-commit)阶段来解决这个问题。
方案如下:Flink checkpointing开始时便进入到pre-commit阶段。具体来说,一旦checkpoint开始,Flink的JobManager向输入流中写入一个checkpoint barrier将流中所有消息分割成属于本次checkpoint的消息以及属于下次checkpoint的。barrier也会在操作算子间流转。对于每个operator来说,该barrier会触发operator状态后端为该operator状态打快照。
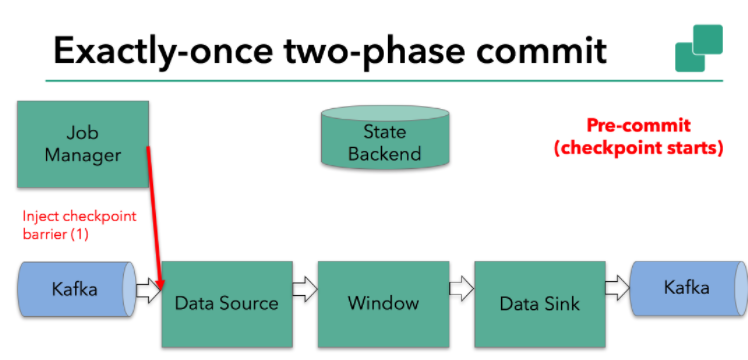
众所周知,flink kafka source保存Kafka消费位移,一旦完成位移保存,它会将checkpoint barrier传给下一个operator。
这个方法对于opeartor只有内部状态的场景是可行的。所谓的内部状态就是完全由Flink状态保存并管理的——本例中的第二个opeartor:时间窗口上保存的求和数据就是这样的例子。当只有内部状态时,pre-commit阶段无需执行额外的操作,仅仅是写入一些已定义的状态变量即可。当chckpoint成功时Flink负责提交这些写入,否则就终止取消掉它们。
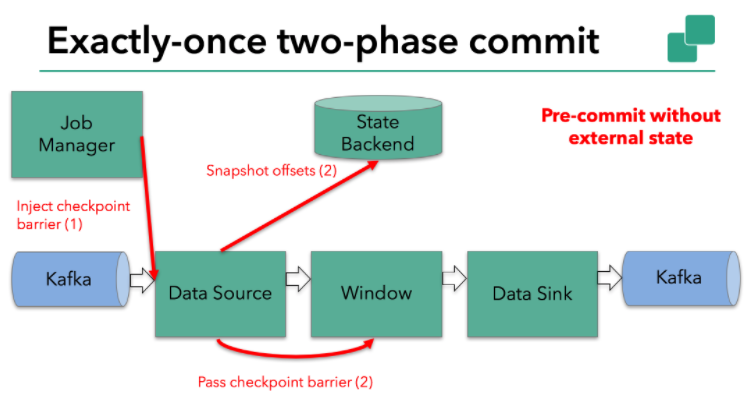
当时,一旦operator包含外部状态,事情就不一样了。我们不能像处理内部状态一样处理这些外部状态。因为外部状态通常都涉及到与外部系统的交互。如果是这样的话,外部系统必须要支持可与两阶段提交协议捆绑使用的事务才能确保实现整体的EOS。
显然本例中的data sink是有外部状态的,因为它需要写入数据到Kafka。此时的pre-commit阶段下data sink在保存状态到状态存储的同时还必须预提交它的外部事务,如下图所示:
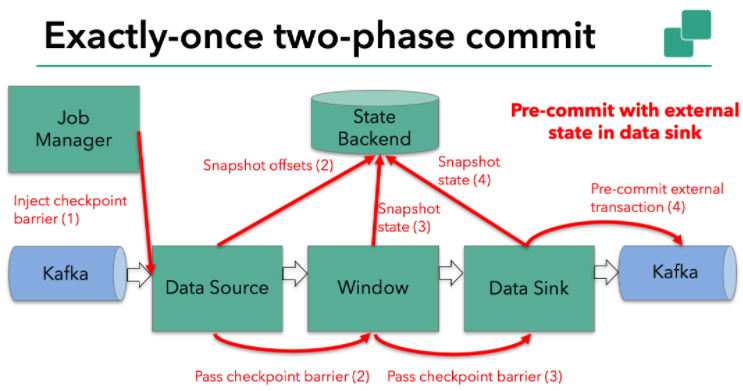
当checkpoint barrier在所有operator都传递了一遍且对应的快照也都成功完成之后,这个pre-commit阶段才算完成。该过程中所有创建的快照都被视为是checkpoint的一部分。我们说checkpoint就是整个应用的全局状态,当然也包含pre-commit阶段提交的外部状态。当出现崩溃时,我们可以回滚状态到最新已成功完成快照时的时间点。
下一步就是通知所有的operator,告诉它们checkpoint已成功完成。这便是两阶段提交协议的第二个阶段:commit阶段。该阶段中JobManager会为应用中每个operator发起checkpoint已完成的回调逻辑。
本例中的data source和窗口操作无外部状态【译者:该文章中的实例主要基于Kafka producer对于事务和EOS的支持。事实上,Kafka consumer对于EOS的支持是有限的,故作者这里并没有拿consumer的EOS来举例说明,故这里的data source没有外部状态】,因此在该阶段,这两个opeartor无需执行任何逻辑,但是data sink是有外部状态的,因此此时我们必须提交外部事务,如下图所示:
汇总以上所有信息,总结一下:
- 一旦所有operator完成各自的pre-commit,它们会发起一个commit操作
- 倘若有一个pre-commit失败,所有其他的pre-commit必须被终止,并且Flink会回滚到最近成功完成decheckpoint
- 一旦pre-commit完成,必须要确保commit也要成功——operator和外部系统都需要对此进行保证。倘若commit失败(比如网络故障等),Flink应用就会崩溃,然后根据用户重启策略执行重启逻辑,之后再次重试commit。这个过程至关重要,因为倘若commit无法顺利执行,就可能出现数据丢失的情况
因此,所有opeartor必须对checkpoint最终结果达成共识:即所有operator都必须认定数据提交要么成功执行,要么被终止然后回滚。
三、Flink中实现两阶段提交operator
这种operator的管理有些复杂,这也是为什么Flink提取了公共逻辑并封装进TwoPhaseCommitSinkFunction抽象类的原因。
下面讨论一下如何扩展TwoPhaseCommitSinkFunction类来实现一个简单的基于文件的sink。若要实现支持EOS的文件sink,我们需要实现以下4个方法:
- beginTransaction:开启一个事务,在临时目录下创建一个临时文件,之后,写入数据到该文件中
- preCommit:在pre-commit阶段,flush缓存数据块到磁盘,然后关闭该文件,确保再不写入新数据到该文件。同时开启一个新事务执行属于下一个checkpoint的写入操作
- commit:在commit阶段,我们以原子性的方式将上一阶段的文件写入真正的文件目录下。注意:这会增加输出数据可见性的延时。通俗说就是用户想要看到最终数据需要等会,不是实时的。
- abort:一旦终止事务,我们离自己删除临时文件
当出现崩溃时,Flink会恢复最新已完成快照中应用状态。需要注意的是在某些极偶然的场景下,pre-commit阶段已成功完成而commit尚未开始(也就是operator尚未来得及被告知要开启commit),此时倘若发生崩溃Flink会将opeartor状态恢复到已完成pre-commit但尚未commit的状态。
在一个checkpoint状态中,对于已完成pre-commit的事务状态,我们必须保存足够多的信息,这样才能确保在重启后要么重新发起commit亦或是终止掉事务。本例中这部分信息就是临时文件所在的路径以及目标目录。
TwoPhaseCommitSinkFunction考虑了这种场景,因此当应用从checkpoint恢复之后TwoPhaseCommitSinkFunction总是会发起一个抢占式的commit。这种commit必须是幂等性的,虽然大部分情况下这都不是问题。本例中对应的这种场景就是:临时文件不在临时目录下,而是已经被移动到目标目录下。
四、总结
本文的一些关键要点:
- Flinkcheckpointing机制是实现两阶段提交协议以及提供EOS的基石
- 与其他系统持久化传输中的数据不同,Flink不需要将计算的每个阶段写入到磁盘中——而这是很多批处理应用的方式
- Flink新的TwoPhaseCommitSinkFunction封装两阶段提交协议的公共逻辑使之搭配支持事务的外部系统来共同构建EOS应用成为可能
- 自1.4版本起,Flink + Pravega和Kafka 0.11 producer开始支持EOS
- Flink Kafka 0.11 producer基于TwoPhaseCommitSinkFunction实现,比起至少一次语义的producer而言开销并未显著增加
【译者:我越来越觉得所有的流式处理框架在设计上甚至是编码上都很相似了。。。Kafka对于事务的支持也是类似的方式,而且也有诸如beginTransaction, preCommit等字眼。另外很多Flink和Kafka源码中的方法名称都是类似的。。。。】
Kafka设计解析(二十二)Flink + Kafka 0.11端到端精确一次处理语义的实现的更多相关文章
- Kafka设计解析(十二)Kafka 如何读取offset topic内容 (__consumer_offsets)
转载自 huxihx,原文链接 Kafka 如何读取offset topic内容 (__consumer_offsets) 众所周知,由于Zookeeper并不适合大批量的频繁写入操作,新版Kafka ...
- Kafka设计解析(十八)Kafka与Flink集成
转载自 huxihx,原文链接 Kafka与Flink集成 Apache Flink是新一代的分布式流式数据处理框架,它统一的处理引擎既可以处理批数据(batch data)也可以处理流式数据(str ...
- Kafka设计解析(十六)Kafka 0.11消息设计
转载自 huxihx,原文链接 [原创]Kafka 0.11消息设计 目录 一.Kafka消息层次设计 1. v1格式 2. v2格式 二.v1消息格式 三.v2消息格式 四.测试对比 Kafka 0 ...
- Kafka设计解析(十五)Kafka controller重设计
转载自 huxihx,原文链接 Kafka controller重设计 目录 一.Controller是做什么的 二.Controller当前设计 三.Controller组成 四.Controlle ...
- Kafka设计解析(十九)Kafka consumer group位移重设
转载自 huxihx,原文链接 Kafka consumer group位移重设 本文阐述如何使用Kafka自带的kafka-consumer-groups.sh脚本随意设置消费者组(consumer ...
- Kafka设计解析(十四)Kafka producer介绍
转载自 huxihx,原文链接 Kafka producer介绍 Kafka 0.9版本正式使用Java版本的producer替换了原Scala版本的producer.本文着重讨论新版本produce ...
- [Big Data - Kafka] Kafka设计解析(五):Kafka Benchmark
性能测试及集群监控工具 Kafka提供了非常多有用的工具,如Kafka设计解析(三)- Kafka High Availability (下)中提到的运维类工具——Partition Reassign ...
- Kafka设计解析(十)Kafka如何创建topic
转载自 huxihx,原文链接 Kafka如何创建topic? 目录 一.命令行部分 二.后台逻辑部分 Kafka创建topic命令很简单,一条命令足矣: bin/kafka-topics. --re ...
- [Big Data - Kafka] Kafka设计解析(四):Kafka Consumer解析
High Level Consumer 很多时候,客户程序只是希望从Kafka读取数据,不太关心消息offset的处理.同时也希望提供一些语义,例如同一条消息只被某一个Consumer消费(单播)或被 ...
- [Big Data - Kafka] Kafka设计解析(三):Kafka High Availability (下)
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.Spa ...
随机推荐
- Hbuilder Webview调试+逍遥安卓模拟器
软件版本: HBuilder : 9.0.2.201803061935 逍遥安卓:5.2.2 webview相当于一个浏览器的tab,通过在webview中修改,模拟器端会实时刷新效果.从而达到调试手 ...
- HDU6152
Friend-Graph Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Tot ...
- 洛谷P4198 楼房重建(线段树)
题意 题目链接 Sol 别问我为什么发两遍 就是为了骗访问量 这个题的线段树做法,,妙的很 首先一个显然的结论:位置\(i\)能被看到当且仅当\(\frac{H_k}{k} < \frac{H_ ...
- 在Ubuntu 14.04 LTS系统中设置Apache虚拟主机(一IP多访问)
参考资料:http://os.51cto.com/art/201406/441909.htm
- 高性能JavaScript(数据存取)
数据存取分为4各部分 存取位置 作用域及改变作用域 原型以及原型链 缓存对象成员值 存取位置 JavaScript 有4中基本的数据存取位置 字面量:字面量代表自身,不存于特定的位置.比如这个的匿名函 ...
- HTTP协议学习随笔
一 HTTP概述 HTTP简单说其实就是一套语言交流规则!Http使用的是可靠的数据传输协议,因此即使数据来自地球的另一端,也能够确保数据在传输过程中不会被损坏或产生混乱. B/S结构 用户在浏览器, ...
- 借助form表单向web服务器发送消息
form表单是常用的,在网页浏览器中 用户点击的请求经htto协议发送回web容器,请求处理 建立用户的页面 <!DOCTYPE html> <html> <head&g ...
- 只有mdf文件的恢复方法
EXEC sp_attach_single_file_db @dbname = 'AdventureWorksDW2012_Data',@physname = 'D:\Program Files (x ...
- iOS 开发多线程 —— GCD(1)
本文是根据文顶顶老师的博客学习总结而来,如有不妥之处,还望指出.http://www.cnblogs.com/wendingding/p/3807716.html 概览: /* 纯c语言,提供了非常多 ...
- Sql server 使用drop database 语句,无法删除正在使用的数据库的解决办法
使用DROP DATABASE 删除数据库 显示“无法删除数据库 ,因为该数据库当前正在使用. 解决办法:在删除某一个数据库(下例中的“DB1”数据库)前,强制kill掉该数据库上的所有数据库连接. ...