spark 数据读取与保存
spark支持的常见文件格式如下:
文本,json,CSV,SequenceFiles,Protocol buffers,对象文件
1.文本
只需要使用文件路径作为参数调用SparkContext 中的textFile() 函数,就可以读取一个文
本文件;
scala> val lines=sc.textFile("/tmp/20171024/20171024.txt")
lines: org.apache.spark.rdd.RDD[String] = /tmp/20171024/20171024.txt MapPartitionsRDD[1] at textFile at <console>:24
scala> lines.collect
res0: Array[String] = Array(10 20 30 50 80 100 60 90 60 60 31 80 70 51 50)
求每个文件的平均值:
scala> val linesall=sc.wholeTextFiles("/tmp/20171024/2017*.txt")
linesall: org.apache.spark.rdd.RDD[(String, String)] = /tmp/20171024/2017*.txt MapPartitionsRDD[7] at wholeTextFiles at <console>:24
scala> linesall.collect
res4: Array[(String, String)] = Array((hdfs://localhost:9000/tmp/20171024/20171024.txt,"10 20 30 50 80 100 60 90 60 60 31 80 70 51 50 "), (hdfs://localhost:9000/tmp/20171024/20171026.txt,"100 500 600 800 10 30 66 96 89 80 100 "))
scala> val result=linesall.mapValues{y=>val nums=y.split(" ").map(x=>x.toDouble);nums.sum/nums.size}.collect
result: Array[(String, Double)] = Array((hdfs://localhost:9000/tmp/20171024/20171024.txt,56.13333333333333), (hdfs://localhost:9000/tmp/20171024/20171026.txt,224.63636363636363))
保存计算结果:
scala> linesall.mapValues{y=>val nums=y.split(" ").map(x=>x.toDouble);nums.sum/nums.size}.saveAsTextFile("/tmp/20171024/result0.txt")
查看保存的结果:
[root@host bin]# hdfs dfs -lsr /tmp/20171024/result0*
lsr: DEPRECATED: Please use 'ls -R' instead.
-rw-r--r-- 1 root supergroup 0 2017-10-26 17:00 /tmp/20171024/result0.txt/_SUCCESS
-rw-r--r-- 1 root supergroup 68 2017-10-26 17:00 /tmp/20171024/result0.txt/part-00000
-rw-r--r-- 1 root supergroup 69 2017-10-26 17:00 /tmp/20171024/result0.txt/part-00001
2.json
读取json,将数据作为文本文件读取,然后对JSON 数据进行解析。
scala> import org.apache.spark.sql.hive.HiveContext;
import org.apache.spark.sql.hive.HiveContext
scala> val hiveCtx = new HiveContext(sc)
warning: there was one deprecation warning; re-run with -deprecation for details hiveCtx: org.apache.spark.sql.hive.HiveContext = org.apache.spark.sql.hive.HiveContext@1dbb9a4a
scala> val json=hiveCtx.jsonFile("/tmp/20171024/namejson.txt")
warning: there was one deprecation warning; re-run with -deprecation for details json: org.apache.spark.sql.DataFrame = [age: bigint, id: bigint ... 1 more field]
scala> json.printSchema()
root
|-- age: long (nullable = true)
|-- id: long (nullable = true)
|-- name: string (nullable = true)
scala> json.registerTempTable("t_name")
warning: there was one deprecation warning; re-run with -deprecation for details
scala>
scala> val all=hiveCtx.sql("select * from t_name")
all: org.apache.spark.sql.DataFrame = [age: bigint, id: bigint ... 1 more field]
scala> all.show
+---+---+-----+
|age| id| name|
+---+---+-----+
| 18| 1| leo|
| 19| 2| jack|
| 17| 3|marry|
+---+---+-----+
3.读取csv
scala> import java.io.StringReader import java.io.StringReader
scala> import au.com.bytecode.opencsv.CSVReader import au.com.bytecode.opencsv.CSVReader
scala> import scala.collection.JavaConversions._
scala> val input=sc.wholeTextFiles("/tmp/20171024/game*.csv") input: org.apache.spark.rdd.RDD[(String, String)] = /tmp/20171024/game*.csv MapPartitionsRDD[1] at wholeTextFiles at <console>:26
scala> input.collect
res0: Array[(String, String)] = Array((hdfs://localhost:9000/tmp/20171024/gamelist.csv,""9041","167","百人牛牛" "9041","174","将相和" "9041","152","百家乐" "9041","194","血战到底" "9041","4009","推到胡" "9041","4010","红中王" "9041","4098","二人麻将" "9041","4077","福建麻将" "9041","4039","血流成河" "9041","178","178" "))
scala> case class gamelist(id:String,subid:String,name:String)
defined class gamelist
scala> val result = input.flatMap { case (_, txt) => val reader = new CSVReader(new StringReader(txt));reader.readAll().map(x => gamelist(x(0), x(1), x(2))) }
result: org.apache.spark.rdd.RDD[gamelist] = MapPartitionsRDD[2] at flatMap at <console>:33
scala> result.collect
res1: Array[gamelist] = Array(gamelist(9041,167,百人牛牛), gamelist(9041,174,将相和), gamelist(9041,152,百家乐), gamelist(9041,194,血战到底), gamelist(9041,4009,推到胡), gamelist(9041,4010,红中王), gamelist(9041,4098,二人麻将), gamelist(9041,4077,福建麻将), gamelist(9041,4039,血流成河), gamelist(9041,178,178))
sparksql读取csv如下:
scala> import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.SQLContext
scala> val sqltext=new SQLContext(sc)
warning: there was one deprecation warning; re-run with -deprecation for details
注释:.option("header","false") //如果在csv第一行没有列头就是"false"
.option("inferSchema",true.toString)//这是自动推断属性列的数据类型。
scala> val data=sqltext.read.format("com.databricks.spark.csv").option("header","false").option("inferSchema",true.toString).load("/tmp/20171024/game*.csv")
data: org.apache.spark.sql.DataFrame = [_c0: int, _c1: int ... 1 more field]
scala> data.collect
res25: Array[org.apache.spark.sql.Row] = Array([9041,167,百人牛牛], [9041,174,将相和], [9041,152,百家乐], [9041,194,血战到底], [9041,4009,推到胡], [9041,4010,红中王], [9041,4098,二人麻将], [9041,4077,福建麻将], [9041,4039,血流成河], [9041,178,178])nt ... 1 more field]
scala> import org.apache.spark.sql.types.{StructType,StructField,StringType};
import org.apache.spark.sql.types.{StructType, StructField, StringType}
scala> val struct1=StructType(StructType(Array(StructField("id",StringType,true),StructField("subid",StringType,true),StructField("name",StringType,true))))
struct1: org.apache.spark.sql.types.StructType = StructType(StructField(id,StringType,true), StructField(subid,StringType,true), StructField(name,StringType,true))
scala> val data=sqltext.read.schema(struct1).format("com.databricks.spark.csv").option("header","false").option("inferSchema",true.toString).load("/tmp/20171024/game*.csv")
data: org.apache.spark.sql.DataFrame = [id: string, subid: string ... 1 more field]
scala> data.collect
res27: Array[org.apache.spark.sql.Row] = Array([9041,167,百人牛牛], [9041,174,将相和], [9041,152,百家乐], [9041,194,血战到底], [9041,4009,推到胡], [9041,4010,红中王], [9041,4098,二人麻将], [9041,4077,福建麻将], [9041,4039,血流成河], [9041,178,178])
scala> data.select("id","name").collect
res33: Array[org.apache.spark.sql.Row] = Array([9041,百人牛牛], [9041,将相和], [9041,百家乐], [9041,血战到底], [9041,推到胡], [9041,红中王], [9041,二人麻将], [9041,福建麻将], [9041,血流成河], [9041,178])
scala> data.registerTempTable("game")
warning: there was one deprecation warning; re-run with -deprecation for details
scala> sqltext.sql("select * from game").show
+----+-----+----+
| id|subid|name|
+----+-----+----+
|9041| 167|百人牛牛|
|9041| 174| 将相和|
|9041| 152| 百家乐|
|9041| 194|血战到底|
|9041| 4009| 推到胡|
|9041| 4010| 红中王|
|9041| 4098|二人麻将|
|9041| 4077|福建麻将|
|9041| 4039|血流成河|
|9041| 178| 178|
+----+-----+----+scala> sqltext.sql("select * from game where subid>200").show
+----+-----+----+
| id|subid|name|
+----+-----+----+
|9041| 4009| 推到胡|
|9041| 4010| 红中王|
|9041| 4098|二人麻将|
|9041| 4077|福建麻将|
|9041| 4039|血流成河|
+----+-----+----+
4.读取SequenceFile
SequenceFile 是由没有相对关系结构的键值对文件组成的常用Hadoop 格式。SequenceFile
文件有同步标记,Spark 可以用它来定位到文件中的某个点,然后再与记录的边界对
齐。这可以让Spark 使用多个节点高效地并行读取SequenceFile 文件。SequenceFile 也是
Hadoop MapReduce 作业中常用的输入输出格式,所以如果你在使用一个已有的Hadoop 系
统,数据很有可能是以SequenceFile 的格式供你使用的。SequenceFile 是由实现Hadoop 的Writable
接口的元素组成。
scala> val rdd = sc.parallelize(List(("wwww", 3), ("tttt", 6), ("gggg", 2))) rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[45] at parallelize at <console>:34
scala> rdd.saveAsSequenceFile("/tmp/20171024/sqf.txt")
[root@host bin]# hdfs dfs -lsr /tmp/20171024/sqf*
lsr: DEPRECATED: Please use 'ls -R' instead.
-rw-r--r-- 1 root supergroup 0 2017-10-30 15:37 /tmp/20171024/sqf.txt/_SUCCESS
-rw-r--r-- 1 root supergroup 85 2017-10-30 15:37 /tmp/20171024/sqf.txt/part-00000
-rw-r--r-- 1 root supergroup 103 2017-10-30 15:37 /tmp/20171024/sqf.txt/part-00001
-rw-r--r-- 1 root supergroup 101 2017-10-30 15:37 /tmp/20171024/sqf.txt/part-00002
-rw-r--r-- 1 root supergroup 103 2017-10-30 15:37 /tmp/20171024/sqf.txt/part-00003
scala> import org.apache.hadoop.io.{IntWritable, Text}
import org.apache.hadoop.io.{IntWritable, Text}
scala> val output = sc.sequenceFile("/tmp/20171024/sqf.txt", classOf[Text], classOf[IntWritable]).map{case (x, y) => (x.toString, y.toString)} output: org.apache.spark.rdd.RDD[(String, String)] = MapPartitionsRDD[1] at map at <console>:25
scala> output.collect res0: Array[(String, String)] = Array((wwww,3), (tttt,6), (gggg,2))
读取SequenceFile
scala> import org.apache.hadoop.io.{IntWritable, Text}
import org.apache.hadoop.io.{IntWritable, Text}
scala> val data = sc.sequenceFile("/spark/parinum/p*", classOf[Text], classOf[IntWritable]).map{case (x,y)=>(x.toString,y.get)}
data: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[216] at map at <console>:37
scala> data.collect
res229: Array[(String, Int)] = Array((zhangsan,100), (wangwu,250), (xiaoma,120), (laozhan,300), (tiandi,60))
保存SequenceFile
scala> numpairdd.collect
res224: Array[(String, Int)] = Array((zhangsan,100), (wangwu,250), (xiaoma,120), (laozhan,300), (tiandi,60))
scala> numpairdd.saveAsSequenceFile("/spark/parinum")
查看hdfs
[root@host conf]# hdfs dfs -ls -R /spark
SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/root/hadoop/hadoop-2.7.4/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/root/hive/apache-hive-2.1.1/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
drwxr-xr-x - root supergroup 0 2018-06-25 16:08 /spark/parinum
-rw-r--r-- 1 root supergroup 0 2018-06-25 16:08 /spark/parinum/_SUCCESS
-rw-r--r-- 1 root supergroup 125 2018-06-25 16:08 /spark/parinum/part-00000
-rw-r--r-- 1 root supergroup 143 2018-06-25 16:08 /spark/parinum/part-00001
----------------------------
读取人员信息,并按得分逆序排序,如果得分相同则按年龄顺序排列
scala> val lines=sc.textFile("/tmp/person.txt")
lines: org.apache.spark.rdd.RDD[String] = /tmp/person.txt MapPartitionsRDD[5] at textFile at <console>:24
scala> lines.collect
res10: Array[String] = Array(2,zhangsan,50,866, 4,laoliu,522,30, 5,zhangsan,20,565, 6,limi,522,65, 1,xiliu,50,6998, 7,llihmj,23,565)
scala> lines.map(_.split(",")).map(arr=>person(arr(0).toLong,arr(1),arr(2).toInt,arr(3).toInt))
res11: org.apache.spark.rdd.RDD[person] = MapPartitionsRDD[7] at map at <console>:29
scala> case class person(id:Long,name:String,age:Int,fv:Int)
defined class person
scala> val userRdd=lines.map(_.split(",")).map(arr=>person(arr(0).toLong,arr(1),arr(2).toInt,arr(3).toInt))
userRdd: org.apache.spark.rdd.RDD[person] = MapPartitionsRDD[9] at map at <console>:28
scala> val pdf=userRdd.toDF()
pdf: org.apache.spark.sql.DataFrame = [id: bigint, name: string ... 2 more fields]
scala> pdf.registerTempTable("person")
warning: there was one deprecation warning; re-run with -deprecation for details
scala> import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.SQLContext
scala> val sqlcon=new SQLContext(sc)
warning: there was one deprecation warning; re-run with -deprecation for details
sqlcon: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@65502709
scala> sqlcon.sql("select * from person")
res14: org.apache.spark.sql.DataFrame = [id: bigint, name: string ... 2 more fields]
scala> sqlcon.sql("select * from person").show
+---+--------+---+----+
| id| name|age| fv|
+---+--------+---+----+
| 2|zhangsan| 50| 866|
| 4| laoliu|522| 30|
| 5|zhangsan| 20| 565|
| 6| limi|522| 65|
| 1| xiliu| 50|6998|
| 7| llihmj| 23| 565|
+---+--------+---+----+
scala> sqlcon.sql("select * from person order by fv desc,age ").show
+---+--------+---+----+
| id| name|age| fv|
+---+--------+---+----+
| 1| xiliu| 50|6998|
| 2|zhangsan| 50| 866|
| 5|zhangsan| 20| 565|
| 7| llihmj| 23| 565|
| 6| limi|522| 65|
| 4| laoliu|522| 30|
+---+--------+---+----+
scala> sqlcon.sql("select * from person order by fv desc,age limit 4 ").show
+---+--------+---+----+
| id| name|age| fv|
+---+--------+---+----+
| 1| xiliu| 50|6998|
| 2|zhangsan| 50| 866|
| 5|zhangsan| 20| 565|
| 7| llihmj| 23| 565|
+---+--------+---+----+
scala> val pdf1=sqlcon.sql("select name,age,fv from person order by fv desc,age limit 4 ")
pdf1: org.apache.spark.sql.DataFrame = [name: string, age: int ... 1 more field]
scala> pdf1.show
+--------+---+----+
| name|age| fv|
+--------+---+----+
| xiliu| 50|6998|
|zhangsan| 50| 866|
|zhangsan| 20| 565|
| llihmj| 23| 565|
+--------+---+----+
scala> pdf1.groupBy("age").count.show
+---+-----+
|age|count|
+---+-----+
| 50| 2|
| 20| 1|
| 23| 1|
+---+-----+
scala> pdf1.write.csv("/tmp/pdf2")
查看hdfs:
[root@host tmpdata]# hdfs dfs -ls /tmp/pdf2
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/root/hadoop/hadoop-2.7.4/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/root/hive/apache-hive-2.1.1/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Found 2 items
-rw-r--r-- 1 root supergroup 0 2018-08-07 10:51 /tmp/pdf2/_SUCCESS
-rw-r--r-- 1 root supergroup 60 2018-08-07 10:51 /tmp/pdf2/part-00000-f4a16495-ea53-4332-b9a7-06e38036a7ac-c000.csv
[root@host tmpdata]# hdfs dfs -cat /tmp/pdf2/par*
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/root/hadoop/hadoop-2.7.4/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/root/hive/apache-hive-2.1.1/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
xiliu,50,6998
zhangsan,50,866
zhangsan,20,565
llihmj,23,565
scala> pdf.printSchema
root
|-- id: long (nullable = false)
|-- name: string (nullable = true)
|-- age: integer (nullable = false)
|-- fv: integer (nullable = false)
scala> pdf1.write.json("/tmp/pdf1json")
查看HDFS:
[root@host tmpdata]# hdfs dfs -ls /tmp/pdf1json
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/root/hadoop/hadoop-2.7.4/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/root/hive/apache-hive-2.1.1/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Found 2 items
-rw-r--r-- 1 root supergroup 0 2018-08-07 10:57 /tmp/pdf1json/_SUCCESS
-rw-r--r-- 1 root supergroup 148 2018-08-07 10:57 /tmp/pdf1json/part-00000-f7246fb2-ad7b-49a6-bcb0-919c9102d9f2-c000.json
[root@host tmpdata]# hdfs dfs -cat /tmp/pdf1json/par*
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/root/hadoop/hadoop-2.7.4/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/root/hive/apache-hive-2.1.1/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
{"name":"xiliu","age":50,"fv":6998}
{"name":"zhangsan","age":50,"fv":866}
{"name":"zhangsan","age":20,"fv":565}
{"name":"llihmj","age":23,"fv":565}
--------------------------
scala> pdf1.write.text("/tmp/pdf1text")
org.apache.spark.sql.AnalysisException: Text data source supports only a single column, and you have 3 columns.;
at org.apache.spark.sql.execution.datasources.text.TextFileFormat.verifySchema(TextFileFormat.scala:46)
at org.apache.spark.sql.execution.datasources.text.TextFileFormat.prepareWrite(TextFileFormat.scala:66)
scala> pdf1.registerTempTable("tb_pdf")
warning: there was one deprecation warning; re-run with -deprecation for details
scala> val sqlcon=new SQLContext(sc)
warning: there was one deprecation warning; re-run with -deprecation for details sqlcon: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@66000786
scala> sqlcon.sql("select * from tb_pdf")
res31: org.apache.spark.sql.DataFrame = [name: string, age: int ... 1 more field]
scala> sqlcon.sql("select * from tb_pdf").show
+--------+---+----+
| name|age| fv|
+--------+---+----+
| xiliu| 50|6998|
|zhangsan| 50| 866|
|zhangsan| 20| 565|
| llihmj| 23| 565|
+--------+---+----+
scala> sqlcon.sql("desc tb_pdf").show
+--------+---------+-------+
|col_name|data_type|comment|
+--------+---------+-------+
| name| string| null|
| age| int| null|
| fv| int| null|
+--------+---------+-------+
-------------------------------------------------------------------------------------------------------------------
scala> pdf.cube("age").mean("fv")
res43: org.apache.spark.sql.DataFrame = [age: int, avg(fv): double]
scala> pdf.cube("age").mean("fv").show
+----+------------------+
| age| avg(fv)|
+----+------------------+
| 23| 565.0|
|null|1514.8333333333333|
| 50| 3932.0|
| 522| 47.5|
| 20| 565.0|
+----+------------------+
scala> pdf.describe("age").show
+-------+------------------+
|summary| age|
+-------+------------------+
| count| 6|
| mean|197.83333333333334|
| stddev|251.42348073850752|
| min| 20|
| max| 522|
+-------+------------------+
scala> pdf.filter("age>50").show
+---+------+---+---+
| id| name|age| fv|
+---+------+---+---+
| 4|laoliu|522| 30|
| 6| limi|522| 65|
+---+------+---+---+
scala> pdf.select(col("age")+1,col("name")).show
+---------+--------+
|(age + 1)| name|
+---------+--------+
| 51|zhangsan|
| 523| laoliu|
| 21|zhangsan|
| 523| limi|
| 51| xiliu|
| 24| llihmj|
+---------+--------+
scala> pdf.select("age"+1,"name").show
org.apache.spark.sql.AnalysisException: cannot resolve '`age1`' given input columns: [id, name, age, fv];;
'Project ['age1, name#6]
...........................
scala> pdf.select(col("age")+1,"name").show
<console>:37: error: overloaded method value select with alternatives:
[U1, U2](c1: org.apache.spark.sql.TypedColumn[org.apache.spark.sql.Row,U1], c2: org.apache.spark.sql.TypedColumn[org.apache.spark.sql.Row,U2])org.apache.spark.sql.Dataset[(U1, U2)] <and>
(col: String,cols: String*)org.apache.spark.sql.DataFrame <and>
(cols: org.apache.spark.sql.Column*)org.apache.spark.sql.DataFrame
cannot be applied to (org.apache.spark.sql.Column, String)
pdf.select(col("age")+1,"name").show
^
scala> pdf.select("name","age").where("fv>500").show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 50|
|zhangsan| 20|
| xiliu| 50|
| llihmj| 23|
+--------+---+
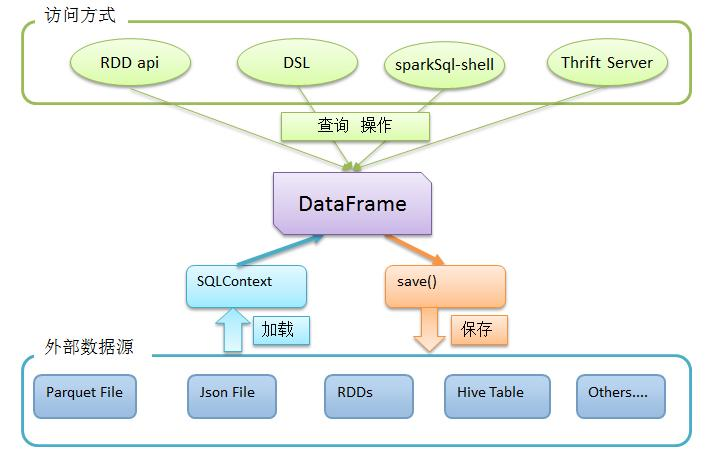
DataFrame可以通过多种来源创建:结构化数据文件,hive的表,外部数据库,或者RDDs
Spark SQL如何使用
首先,利用sqlContext从外部数据源加载数据为DataFrame
然后,利用DataFrame上丰富的api进行查询、转换
最后,将结果进行展现或存储为各种外部数据形式
Spark on Hive和Hive on Spark
Spark on Hive: Hive只作为储存角色,Spark负责sql解析优化,执行。
Hive on Spark:Hive即作为存储又负责sql的解析优化,Spark负责执行。
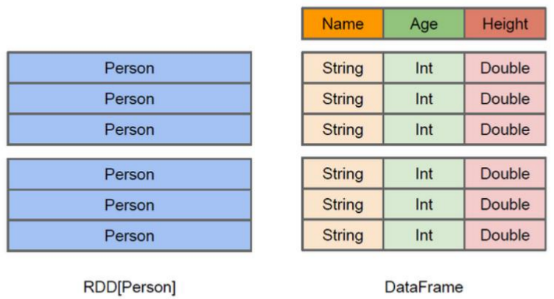
DataFrame也是一个分布式数据容器。与RDD类似,然而DataFrame更像传统数据库的二维表格,除了数据以外,还掌握数据的结构信息,即schema。同时,与Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)。从API易用性的角度上 看, DataFrame API提供的是一套高层的关系操作,比函数式的RDD API要更加友好,门槛更低。
DataFrame的底层封装的是RDD,只不过RDD的泛型是Row类型。
通过反射的方式将非json格式的RDD转换成DataFrame(不建议使用)
1.创建RDD
scala> val lines=sc.textFile("/tmp/person.txt") lines: org.apache.spark.rdd.RDD[String] = /tmp/person.txt MapPartitionsRDD[5] at textFile at <console>:24
scala> lines.collect res10: Array[String] = Array(2,zhangsan,50,866, 4,laoliu,522,30, 5,zhangsan,20,565, 6,limi,522,65, 1,xiliu,50,6998, 7,llihmj,23,565)
2.对每行使用列分割符进行分割
3.定义case class (相当于表的schema)
4.将rdd与case class关联
scala> case class person(id:Long,name:String,age:Int,fv:Int) defined class person
scala> val userRdd=lines.map(_.split(",")).map(arr=>person(arr(0).toLong,arr(1),arr(2).toInt,arr(3).toInt))
userRdd: org.apache.spark.rdd.RDD[person] = MapPartitionsRDD[9] at map at <console>:28
5.rdd转化为dataframe
scala> val pdf=userRdd.toDF()
pdf: org.apache.spark.sql.DataFrame = [id: bigint, name: string ... 2 more fields]
6.对dataframe进行处理
动态创建Schema将非json格式的RDD转换成DataFrame(建议使用)
scala> import org.apache.spark.sql.types._
import org.apache.spark.sql.types._
scala> import org.apache.spark.sql.{SQLContext,Row}
import org.apache.spark.sql.{SQLContext, Row}
scala> val lines=sc.textFile("/tmp/person.txt")
lines: org.apache.spark.rdd.RDD[String] = /tmp/person.txt MapPartitionsRDD[7] at textFile at <console>:31
scala> val rowrdd=lines.map(_.split("[,]"))
rowrdd: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[8] at map at <console>:33
scala> val schema=StructType(List(StructField("id",LongType,true),StructField("name",StringType,true),StructField("age",IntegerType,true),StructField("fv",IntegerType,true)))
schema: org.apache.spark.sql.types.StructType = StructType(StructField(id,LongType,true), StructField(name,StringType,true), StructField(age,IntegerType,true), StructField(fv,IntegerType,true))
scala> val rows=rowrdd.map(x=>Row(x(0).toLong,x(1).toString,x(2).toInt,x(3).toInt))
rows: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[30] at map at <console>:35
scala> val sqlcon=new SQLContext(sc)
warning: there was one deprecation warning; re-run with -deprecation for details
sqlcon: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@2bd13c
scala> val personDF=sqlcon.createDataFrame(rows,schema)
personDF: org.apache.spark.sql.DataFrame = [id: bigint, name: string ... 2 more fields]
scala> personDF.show
+---+--------+---+----+
| id| name|age| fv|
+---+--------+---+----+
| 2|zhangsan| 50| 866|
| 4| laoliu|522| 30|
| 5|zhangsan| 20| 565|
| 6| limi|522| 65|
| 1| xiliu| 50|6998|
| 7| llihmj| 23| 565|
+---+--------+---+----+
scala> personDF.registerTempTable("tb_person")
warning: there was one deprecation warning; re-run with -deprecation for details
scala> sqlcon.sql("select * from tb_person where age>500").show
+---+------+---+---+
| id| name|age| fv|
+---+------+---+---+
| 4|laoliu|522| 30|
| 6| limi|522| 65|
+---+------+---+---+
scala> df.write.parquet("/tmp/parquet")
[root@host tmpdata]# hdfs dfs -cat /tmp/parquet/par*
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/root/hadoop/hadoop-2.7.4/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/root/hive/apache-hive-2.1.1/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
.........................................
org.apache.spark.sql.parquet.row.metadata?{"type":"struct","fields":[{"name":"id","type":"string","nullable":true,"metadata":{}},{"name":"name","type":"string","nullable":true,"metadata":{}},{"name":"age","type":"string","nullable":true,"metadata":{}},{"name":"fv","type":"string","nullable":true,"metadata":{}}]}Iparquet-mr version 1.8.2 (build c6522788629e590a53eb79874b95f6c3ff11f16c)?PAR1
scala> val lines=spsession.read.parquet("/tmp/parquet/part*")
lines: org.apache.spark.sql.DataFrame = [id: string, name: string ... 2 more fields]
scala> lines.show
+---+--------+---+----+
| id| name|age| fv|
+---+--------+---+----+
| 2|zhangsan| 50| 866|
| 4| laoliu|522| 30|
| 5|zhangsan| 20| 565|
| 6| limi|522| 65|
| 1| xiliu| 50|6998|
| 7| llihmj| 23| 565|
+---+--------+---+----+
spark 数据读取与保存的更多相关文章
- Spark基础:(四)Spark 数据读取与保存
1.文件格式 Spark对很多种文件格式的读取和保存方式都很简单. (1)文本文件 读取: 将一个文本文件读取为一个RDD时,输入的每一行都将成为RDD的一个元素. val input=sc.text ...
- 【原】Learning Spark (Python版) 学习笔记(二)----键值对、数据读取与保存、共享特性
本来应该上周更新的,结果碰上五一,懒癌发作,就推迟了 = =.以后还是要按时完成任务.废话不多说,第四章-第六章主要讲了三个内容:键值对.数据读取与保存与Spark的两个共享特性(累加器和广播变量). ...
- Spark学习之数据读取与保存总结(一)
一.动机 我们已经学了很多在 Spark 中对已分发的数据执行的操作.到目前为止,所展示的示例都是从本地集合或者普通文件中进行数据读取和保存的.但有时候,数据量可能大到无法放在一台机器中,这时就需要探 ...
- Spark学习之数据读取与保存(4)
Spark学习之数据读取与保存(4) 1. 文件格式 Spark对很多种文件格式的读取和保存方式都很简单. 如文本文件的非结构化的文件,如JSON的半结构化文件,如SequenceFile结构化文件. ...
- Spark学习笔记4:数据读取与保存
Spark对很多种文件格式的读取和保存方式都很简单.Spark会根据文件扩展名选择对应的处理方式. Spark支持的一些常见文件格式如下: 文本文件 使用文件路径作为参数调用SparkContext中 ...
- Spark(十二)【SparkSql中数据读取和保存】
一. 读取和保存说明 SparkSQL提供了通用的保存数据和数据加载的方式,还提供了专用的方式 读取:通用和专用 保存 保存有四种模式: 默认: error : 输出目录存在就报错 append: 向 ...
- Spark学习之数据读取与保存总结(二)
8.Hadoop输入输出格式 除了 Spark 封装的格式之外,也可以与任何 Hadoop 支持的格式交互.Spark 支持新旧两套Hadoop 文件 API,提供了很大的灵活性. 要使用新版的 Ha ...
- 【Spark机器学习速成宝典】基础篇03数据读取与保存(Python版)
目录 保存为文本文件:saveAsTextFile 保存为json:saveAsTextFile 保存为SequenceFile:saveAsSequenceFile 读取hive 保存为文本文件:s ...
- matlab各格式数据读取与保存函数
数据处理及matlab的初学者,可能最一开始接触的就是数据的读取与保存: %matlab数据保存与读入 function datepro clear all; %产生随机数据 mat = rand(, ...
随机推荐
- WCF类型共享技巧【转载】
调用过WCF服务的同学可能都会遇到这样的问题,同一个实体类型,不同的服务Visual Studio生成了不同的版本,例如Service1.User和Service2.User,对于C#来说,这是两个不 ...
- java统计文件字母大小写的数量练习
import java.io.*; import java.lang.*; public class WordStatistic { private BufferedReader br; privat ...
- IDEA创建简单servlet程序
创建项目 创建完后的目录结构为: web项目配置 在WEB-INF目录下新建两个文件夹,分别命名未classes和lib(classes目录用于存放编译后的class文件,lib用于存放依赖的jar包 ...
- pytest.9.使用fixture参数化接口入参
From: http://www.testclass.net/pytest/test_api_using_params/ 背景 接上一节v2ex网站的查看论坛节点信息的api.具体如下: 节点信息 获 ...
- 关于MySql悲观锁与乐观锁
悲观锁与乐观锁是两种常见的资源并发锁设计思路,也是并发编程中一个非常基础的概念.本文将对这两种常见的锁机制在数据库数据上的实现进行比较系统的介绍. 悲观锁(Pessimistic Lock) 悲观锁的 ...
- 【Mybatis】mybatis使用示例
BusinessAnalysisMapper.java import com.chinamobile.epic.dao.model.PerformanceMetricAnalysis; import ...
- Android 引用库项目,Debug 库项目
转自:http://www.cnblogs.com/xitang/p/3615768.html#commentform 使用引用项目,无法追到源代码,无法Debug库项目The JAR of this ...
- 享元(FlyWeight)模式
享元模式(Flyweight Pattern)主要用于减少创建对象的数量,以减少内存占用和提高性能.这种类型的设计模式属于结构型模式,它提供了减少对象数量从而改善应用所需的对象结构的方式.享元模式尝试 ...
- 学习笔记之Lazy evaluation
Lazy evaluation - Wikipedia https://en.wikipedia.org/wiki/Lazy_evaluation In programming language th ...
- 自定义锁屏图片 win7
win + R打开运行对话框 输入Regedit 点确定 进入注册表,找到以下项次 HKEY_LOCAL_MACHINE/SOFTWARE/Microsoft/Windows/CurrentVersi ...