spark性能调优(二) 彻底解密spark的Hash Shuffle
装载:http://www.cnblogs.com/jcchoiling/p/6431969.html
引言
Spark HashShuffle 是它以前的版本,现在1.6x 版本默应是 Sort-Based Shuffle,那为什么要讲 HashShuffle 呢,因为有分布式就一定会有 Shuffle,而且 HashShuffle 是 Spark以前的版本,亦即是 Sort-Based Shuffle 的前身,因为有 HashShuffle 的不足,才会有后续的 Sorted-Based Shuffle,以及现在的 Tungsten-Sort Shuffle,所以我们有必要去了解它。
人们对Spark的印象往往是基于内存进行计算,但实际上来讲,Spark可以基于内存、也可以基于磁盘或者是第三方的储存空间进行计算,背后有两层含意,第一、Spark框架的架构设计和设计模式上是倾向于在内存中计算数据的,第二、这也表达了人们对数据处理的一种美好的愿望,就是希望计算数据的时候,数据就在内存中。
为什么再一次强调 Shuffle 是 Spark 的性能杀手啦,那不就是说,Spark中的 “Shuffle“ 和 “Spark完全是基于内存计算“ 的愿景是相违背的!!!希望这篇文章能为读者带出以下的启发:
- 了解为什么 Shuffle 是分布式系统的天敌
- 了解 Spark HashShuffle的原理和机制
- 了解优化后 Spark Consolidated HashShuffle的原理和机制
- 了解Shuffle 是如何成为 Spark 性能杀手
- 了解可以从那几方面思考 Spark Shuffle 的性能调优
- 了解 Spark HashShuffle 在读、写磁盘这个过程的源码鉴赏
一、shuffle是分布式系统的天敌
Spark 运行分成两部份,第一部份是 Driver Program,里面的核心是 SparkContext,它驱动著一个程序的开始,负责指挥,另外一部份是 Worker 节点上的 Task,它是实际运行任务的,当程序运行时,不间断地由 Driver 与所在的进程进行交互,交互什么,有几点,第一、是让你去干什么,第二、是具体告诉 Task 数据在那里,例如说有三个 Stage,第二个 Task 要拿数据,它就会向 Driver 要数据,所以在整个工作的过程中,Executor 中的 Task 会不断地与 Driver 进行沟通,这是一个网络传输的过程。
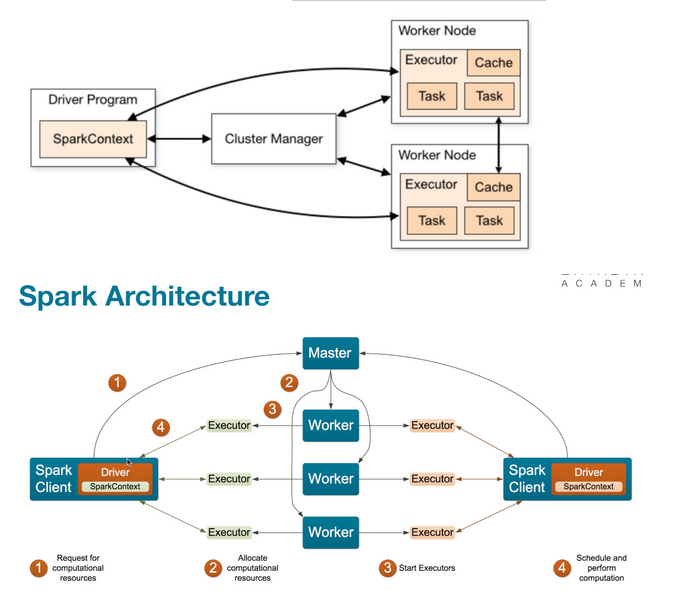
在这个过程中一方面是 Driver 跟 Executor 进行网络传输,另一方面是Task要从 Driver 抓取其他上游的 Task 的数据结果,所以有这个过程中就不断的产生网络结果。其中,下一个 Stage 向上一个 Stage 要数据这个过程,我们就称之为 Shuffle。
思考点:上一个 Stage 为什么要向下一个 Stage 发数据?假设现在有一个程序,里面有五个 Stage,我把它看成为一个很大的 Stage,在分布式系统中,数据分布在不同的节点上,每一个节点计算一部份数据,如果不对各个节点上独立的部份进行汇聚的话,我们是计算不到最终的结果。这就是因为我们需要利用分布式来发挥它本身并行计算的能力,而后续又需要计算各节点上最终的结果,所以需要把数据汇聚集中,这就会导致 Shuffle,这也是说为什么 Shuffle 是分布式不可避免的命运。
二、spark中的Hash Shuffle介绍
1、 原始的Hash Shuffle机制
基于 Mapper 和 Reducer 理解的基础上,当 Reducer 去抓取数据时,它的 Key 到底是怎么分配的,核心思考点是:作为上游数据是怎么去分配给下游数据的。在这张图中你可以看到有4个 Task 在2个 Executors 上面,它们是并行运行的,Hash 本身有一套 Hash算法,可以把数据的 Key 进行重新分类,每个 Task 对数据进行分类然后把它们不同类别的数据先写到本地磁盘,然后再经过网络传输 Shuffle,把数据传到下一个 Stage 进行汇聚。
下图有3个 Reducer,从 Task 开始那边各自把自己进行 Hash 计算,分类出3个不同的类别,每个 Task 都分成3种类别的数据,刚刚提过因为分布式的关系,我们想把不同的数据汇聚然后计算出最终的结果,所以下游的 Reducer 会在每个 Task 中把属于自己类别的数据收集过来,汇聚成一个同类别的大集合,抓过来的时候会首先放在内存中,但内存可能放不下,也有可能放在本地 (这也是一个调优点。可以参考上一章讲过的一些调优参数),每1个 Task 输出3份本地文件,这里有4个 Mapper Tasks,所以总共输出了4个 Tasks x 3个分类文件 = 12个本地小文件。
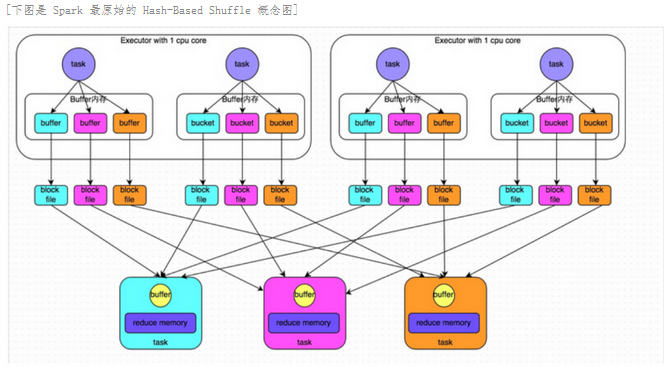
Hash Shuffle 也有它的弱点:
- Shuffle前在磁盘上会产生海量的小文件,此时会产生大量耗时低效的 IO 操作 (因為产生过多的小文件)
- 内存不够用,由于内存中需要保存海量文件操作句柄和临时信息,如果数据处理的规模比较庞大的话,内存不可承受,会出现 OOM 等问题。
2、 优化后的Hash Shuffle 机制
在刚才 HashShuffle 的基础上思考该如何进行优化,这是优化后的实现:
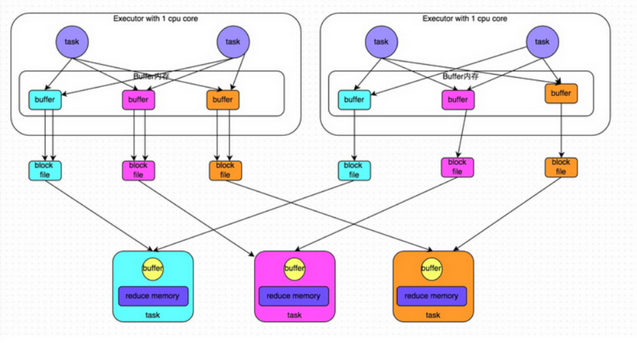
这里还是有4个Tasks,数据类别还是分成3种类型,因为Hash算法会根据你的 Key 进行分类,在同一个进程中,无论是有多少过Task,都会把同样的Key放在同一个Buffer里,然后把Buffer中的数据写入以Core数量为单位的本地文件中,(一个Core只有一种类型的Key的数据),每1个Task所在的进程中,分别写入共同进程中的3份本地文件,这里有4个Mapper Tasks,所以总共输出是 2个Cores x 3个分类文件 = 6个本地小文件。Consoldiated Hash-Shuffle的优化有一个很大的好处就是假设现在有200个Mapper Tasks在同一个进程中,也只会产生3个本地小文件; 如果用原始的 Hash-Based Shuffle 的话,200个Mapper Tasks 会各自产生3个本地小文件,在一个进程已经产生了600个本地小文件。3个对比600已经是一个很大的差异了。
这个优化后的 HashShuffle 叫 ConsolidatedShuffle,在实际生产环境下可以调以下参数:
spark.shuffle.consolidateFiles=true
Consolidated HashShuffle 也有它的弱点:
- 如果 Reducer 端的并行任务或者是数据分片过多的话则 Core * Reducer Task 依旧过大,也会产生很多小文件。
3、Shuffle是如何成为Spark性能杀手及调优点思考
Shuffle 不可以避免是因为在分布式系统中的基本点就是把一个很大的的任务/作业分成一百份或者是一千份,这一百份和一千份文件在不同的机器上独自完成各自不同的部份,我们是针对整个作业要结果,所以在后面会进行汇聚,这个汇聚的过程的前一阶段到后一阶段以至网络传输的过程就叫 Shuffle。在 Spark 中为了完成 Shuffle 的过程会把真正的一个作业划分为不同的 Stage,这个Stage 的划分是跟据依赖关系去决定的,Shuffle 是整个 Spark 中最消耗性能的一个地方。试试想想如果没有 Shuffle 的话,Spark可以完成一个纯内存式的操作。
reduceByKey,它会把每个 Key 对应的 Value 聚合成一个 value 然后生成新的 RDD
Shuffle 是如何破坏了纯内存操作呢,因为在不同节点上我们要进行数据传输,数据在通过网络发送之前,要先存储在内存中,内存达到一定的程度,它会写到本地磁盘,(在以前 Spark 的版本它没有Buffer 的限制,会不断地写入 Buffer 然后等内存满了就写入本地,现在的版本对 Buffer 多少设定了限制,以防止出现 OOM,减少了 IO)
Mapper 端会写入内存 Buffer,这个便关乎到 GC 的问题,然后 Mapper端的 Block 要写入本地,大量的磁盘与IO的操作和磁盘与网络IO的操作,这就构成了分布式的性能杀手。
如果要对最终计算结果进行排序的话,一般会都会进行 sortByKey,如果以最终结果来思考的话,你可以认为是产生了一个很大很大的 partition,你可以用 reduceByKey 的时候指定它的并行度,例如你把 reduceByKey 的并行度变成为1,新 RDD 的数据切片就变成1,排序一般都会在很多节点上,如果你把很多节点变成一个节点然后进行排序,有时候会取得更好的效果,因为数据就在一个节点上,技术层面来讲就只需要在一个进程里进行排序。
可以在调用 reduceByKey()接著调用 mapPartition( );
也可以用 repartitionAndSortWithPartitions( );
还有一个很危险的地方就是数据倾斜,在我们谈的 Shuffle 机制中,不断强调不同机器从Mapper端抓取数据并计算结果,但有没有意会到数据可能会分布不均衡,什么时候会导致数据倾斜,答案就是 Shuffle 时会导政数据分布不均衡,也就是数据倾斜的问题。数据倾斜的问题会引申很多其他问题,比如,网络带宽、各重硬件故障、内存过度消耗、文件掉失。因为 Shuffle 的过程中会产生大量的磁盘 IO、网络 IO、以及压缩、解压缩、序列化和反序列化等等。
4、Shuffle 性能调优思考
Shuffle可能面临的问题,运行 Task 的时候才会产生 Shuffle (Shuffle 已经融化在 Spark 的算子中)
- 几千台或者是上万台的机器进行汇聚计算,数据量会非常大,网络传输会很大
- 数据如何分类其实就是 partition,即如何 Partition、Hash 、Sort 、计算
- 负载均衡 (数据倾斜)
- 网络传输效率,需要压缩或解压缩之间做出权衡,序列化 和 反序列化也是要考虑的问题
具体的 Task 进行计算的时候尽一切最大可能使得数据具备 Process Locality 的特性,退而求其次是增加数据分片,减少每个 Task 处理的数据量,基于Shuffle 和数据倾斜所导致的一系列问题,可以延伸出很多不同的调优点,比如说:
- Mapper端的 Buffer 应该设置为多大呢?
- Reducer端的 Buffer 应该设置为多大呢?如果 Reducer 太少的话,这会限制了抓取多少数据
- 在数据传输的过程中是否有压缩以及该用什么方式去压缩,默应是用 snappy 的压缩方式。
- 网络传输失败重试的次数,每次重试之间间隔多少时间。
spark性能调优(二) 彻底解密spark的Hash Shuffle的更多相关文章
- [Spark性能调优] 第三章 : Spark 2.1.0 中 Sort-Based Shuffle 产生的内幕
本課主題 Sorted-Based Shuffle 的诞生和介绍 Shuffle 中六大令人费解的问题 Sorted-Based Shuffle 的排序和源码鉴赏 Shuffle 在运行时的内存管理 ...
- [Spark性能调优] 第四章 : Spark Shuffle 中 JVM 内存使用及配置内幕详情
本课主题 JVM 內存使用架构剖析 Spark 1.6.x 和 Spark 2.x 的 JVM 剖析 Spark 1.6.x 以前 on Yarn 计算内存使用案例 Spark Unified Mem ...
- [Spark性能调优] 源码补充 : Spark 2.1.X 中 Unified 和 Static MemoryManager
本课主题 Static MemoryManager 的源码鉴赏 Unified MemoryManager 的源码鉴赏 引言 从源码的角度了解 Spark 内存管理是怎么设计的,从而知道应该配置那个参 ...
- spark性能调优(四) spark shuffle中JVM内存使用及配置内幕详情
转载:http://www.cnblogs.com/jcchoiling/p/6494652.html 引言 Spark 从1.6.x 开始对 JVM 的内存使用作出了一种全新的改变,Spark 1. ...
- Spark性能调优之道——解决Spark数据倾斜(Data Skew)的N种姿势
原文:http://blog.csdn.net/tanglizhe1105/article/details/51050974 背景 很多使用Spark的朋友很想知道rdd里的元素是怎么存储的,它们占用 ...
- Spark性能调优
Spark性能优化指南——基础篇 https://tech.meituan.com/spark-tuning-basic.html Spark性能优化指南——高级篇 https://tech.meit ...
- [Spark性能调优] 第一章:性能调优的本质、Spark资源使用原理和调优要点分析
本課主題 大数据性能调优的本质 Spark 性能调优要点分析 Spark 资源使用原理流程 Spark 资源调优最佳实战 Spark 更高性能的算子 引言 我们谈大数据性能调优,到底在谈什么,它的本质 ...
- 性能调优的本质、Spark资源使用原理和调优要点分析
本课主题 大数据性能调优的本质 Spark 性能调优要点分析 Spark 资源使用原理流程 Spark 资源调优最佳实战 Spark 更高性能的算子 引言 我们谈大数据性能调优,到底在谈什么,它的本质 ...
- Spark性能调优之Shuffle调优
Spark性能调优之Shuffle调优 • Spark底层shuffle的传输方式是使用netty传输,netty在进行网络传输的过程会申请堆外内存(netty是零拷贝),所以使用了堆外内存. ...
- spark 性能调优(一) 性能调优的本质、spark资源使用原理、调优要点分析
转载:http://www.cnblogs.com/jcchoiling/p/6440709.html 一.大数据性能调优的本质 编程的时候发现一个惊人的规律,软件是不存在的!所有编程高手级别的人无论 ...
随机推荐
- Django Rest Framework源码剖析(六)-----序列化(serializers)
一.简介 django rest framework 中的序列化组件,可以说是其核心组件,也是我们平时使用最多的组件,它不仅仅有序列化功能,更提供了数据验证的功能(与django中的form类似). ...
- 20155204 王昊《网络对抗技术》EXP3
20155204 王昊<网络对抗技术>EXP3 一.基础问题回答 1.杀软是如何检测出恶意代码的? 答: 基于特征码:一段特征码就是一段或多段数据.(如果一个可执行文件(或其他运行的库.脚 ...
- 网络对抗技术 2017-2018-2 20155215 Exp9 Web安全基础
1.实践过程 前期准备:WebGoat WebGoat分为简单版和开发板,简单版是个Java的Jar包,只需要有Java环境即可,我们在命令行里执行java -jar webgoat-containe ...
- 20155302《网络对抗》Exp8 Web基础
20155302<网络对抗>Exp8 Web基础 实验内容 (1).Web前端HTML(0.5分) 能正常安装.启停Apache.理解HTML,理解表单,理解GET与POST方法,编写一个 ...
- 谈谈对Python装饰器的理解
装饰器,又名函数修饰符.笔者觉得函数修饰符,这个名字更能直观的反应他的作用. 函数修饰符语法特征 : @ + 修饰符 函数修饰符的装饰对象: 函数修饰符,就是说他修饰的是 ...
- 汇编 EAX,EBX,ECX,EDX,寄存器
知识点: 寄存器EAX 寄存器AX 寄存器AH 寄存器AL 一.EAX与AX,AH,AL关系图 一格表示一字节 #include <Windows.h> int _tmain(int ar ...
- [CF1083F]The Fair Nut and Amusing Xor[差分+同余分类+根号分治+分块]
题意 给定两个长度为 \(n\) 的序列 \(\{a_i\}\) 与 \(\{b_i\}\),你需要求出它们的相似度.,我们定义这两个序列的相似度为将其中一个序列转化为另一个序列所需的最小操作次数.一 ...
- JS基础内容小结(DOM&&BOM)(二)
元素.childNodes:只读 属性 子节点列表集合 元素.nodeType:只读 属性 当前元素下的节点类型 元素.attributes : 只读 属性 属性列表集合 元素.children: 只 ...
- supervisor管理进程 superlance对进程状态报警
supervisor介绍 首先,介绍一下supervisor.Supervisor(http://supervisord.org/)是用Python开发的一个client/server服务,是Linu ...
- 【阿里巴巴】CBU技术部招聘
如果你偏爱技术挑战,希望成就不一样的自己,欢迎投递简历至 yangyang.xiayy@alibaba-inc.com [业务简介] B2B内贸www.1688.com:1688.com是最大的内贸B ...