使用jsoup爬取所有成语
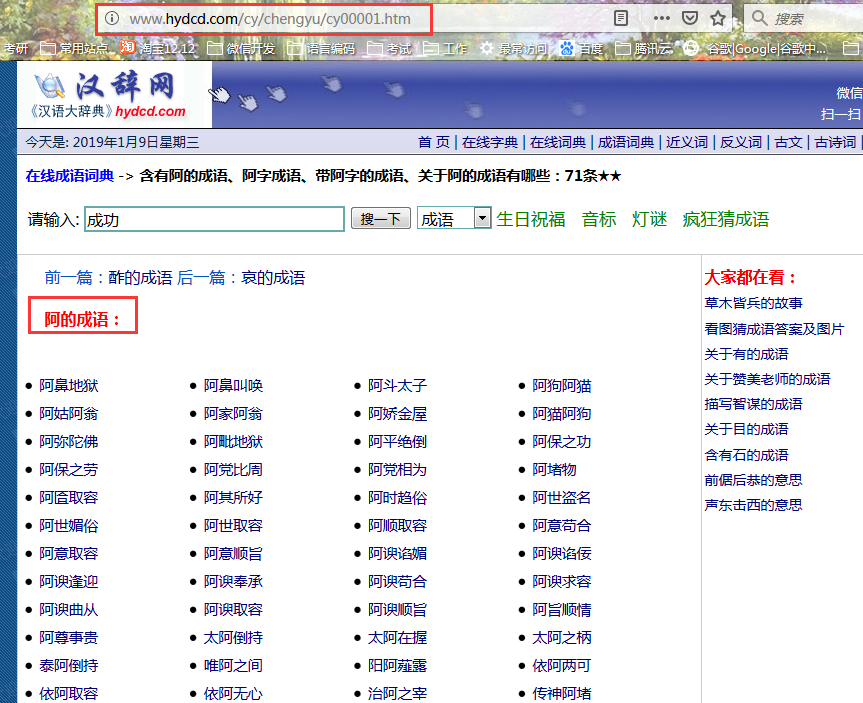
前几天看到有人在博问上求所有成语,想到刚好看了jsoup,就动手实践了一下,提问者给出了网站,一看很简单,就两种页面,一种是包含某个字的成语链接页面,一个是具体的包含某个字的成语的页面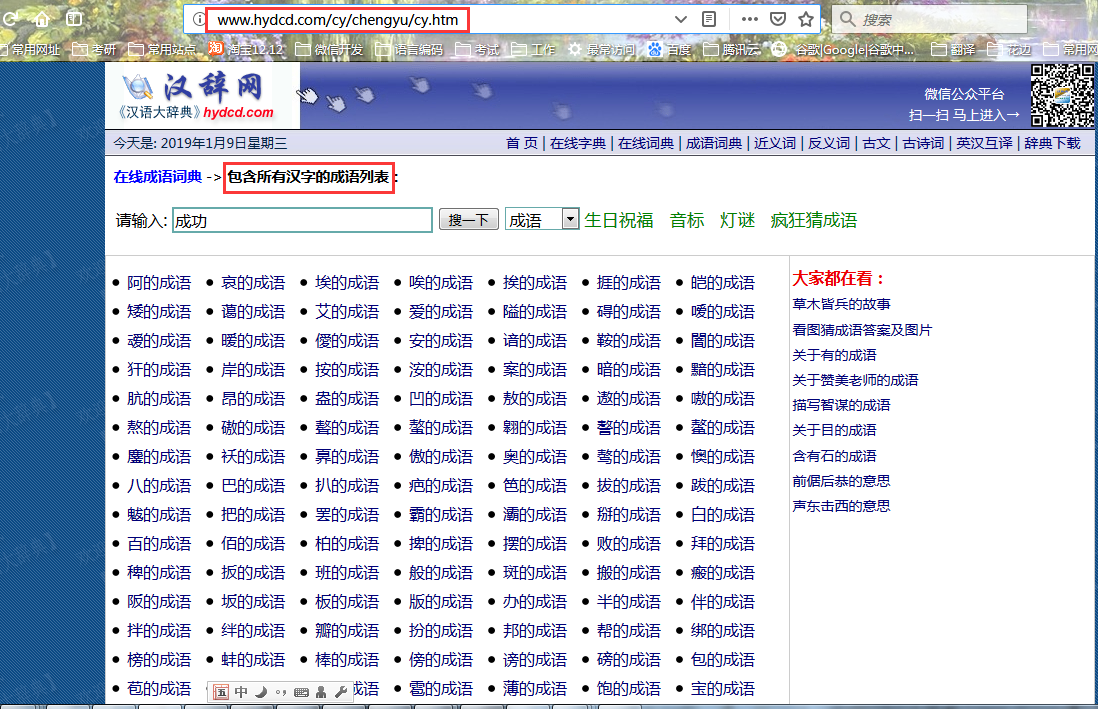
下面是我的代码,用到了jsoup的jar包
package cnblogs.spider; import java.io.BufferedWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.net.URL;
import java.util.ArrayList;
import java.util.List; import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements; public class IdiomScratch
{ public static void main(String[] args)
{
final String url = "http://www.hydcd.com/cy/chengyu/cy.htm";
final String urlSub = "http://www.hydcd.com/cy/chengyu/";
BufferedWriter writer = null;
try
{
Document doc = Jsoup.parse(new URL(url).openStream(), "gb18030", "http://www.hydcd.com");
Element cyTable = doc.getElementById("table1");
Elements aElements = cyTable.getElementsByTag("a");
List<String> aHrefs = new ArrayList<String>(); if(null != aElements && aElements.size() > 0)
{
for(int i = 0, size = aElements.size(); i < size; i++)
{
aHrefs.add(urlSub + aElements.get(i).attr("href"));
} File cytxt = new File("c://cengyu.txt");
if(!cytxt.exists())
{
cytxt.createNewFile();
} writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(cytxt)));
String cy = null; for(int i = 0, size = aHrefs.size(); i < size; i++)
{
doc = Jsoup.parse(new URL(aHrefs.get(i)).openStream(), "gb18030", "http://www.hydcd.com");
cyTable = doc.getElementById("table1");
aElements = cyTable.getElementsByTag("a"); if(null != aElements && aElements.size() > 0)
{
int b = 0;
for(int j = 0, size2 = aElements.size(); j < size2; j++)
{
cy = aElements.get(j).text(); writer.write(cy + " ");
b++;
if(b == 8)
{
b = 0;
writer.write("\r\n");
}
} writer.write("\r\n");
if(b != 0)
{
writer.write("\r\n");
}
writer.flush();
}
}
}
}
catch(IOException e)
{
e.printStackTrace();
}
finally
{
if(null != writer)
{
try
{
writer.close();
}
catch(IOException e)
{
e.printStackTrace();
}
}
}
} }
说一下碰到的坑,一开始没有注意编码问题,得到的txt结果中总有一些乱码,后来看网页源码显示编码是gb2312,就换成了gb2312,但还是不对,一想gb2312是简体字的,肯定不能包含所有的成语中的汉字啊,所有就查了一下汉字的编码,发现有gb18030,就用这个试了一下,果然没有乱码了
结果如下:
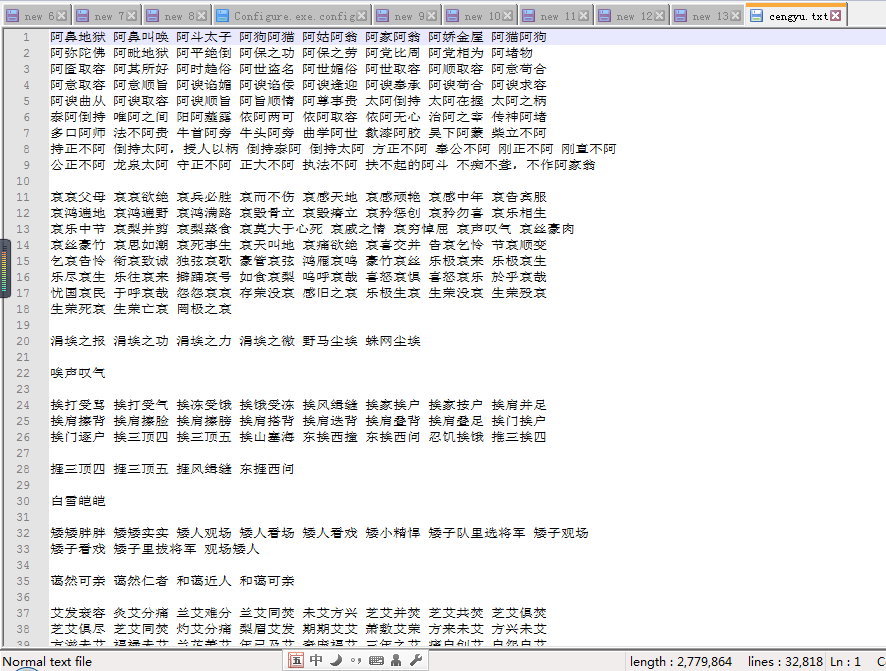
下面是所有成语的txt文件和代码:
使用jsoup爬取所有成语的更多相关文章
- Jsoup爬取带登录验证码的网站
今天学完爬虫之后想的爬一下我们学校的教务系统,可是发现登录的时候有验证码.因此研究了Jsoup爬取带验证码的网站: 大体的思路是:(需要注意的是__VIEWSTATE一直变化,所以我们每个页面都需要重 ...
- jsoup爬取某网站安全数据
jsoup爬取某网站安全数据 package com.vfsd.net; import java.io.IOException; import java.sql.SQLException; impor ...
- 使用Jsoup 爬取网易首页所有的图片
package com.enation.newtest; import java.io.File; import java.io.FileNotFoundException; import java. ...
- java爬虫入门--用jsoup爬取汽车之家的新闻
概述 使用jsoup来进行网页数据爬取.jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址.HTML文本内容.它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuer ...
- 使用Jsoup爬取网站图片
package com.test.pic.crawler; import java.io.File; import java.io.FileOutputStream; import java.io.I ...
- 如何使用Jsoup爬取网页内容
前言: 这是一篇迟到很久的文章了,人真的是越来越懒,前一阵用jsoup实现了一个功能,个人觉得和selenium的webdriver原理类似,所以今天正好有时间,就又来更新分享了. 实现场景: 爬取博 ...
- 利用Jsoup爬取新冠疫情数据并存至数据库
需要用到的jar包(用来爬取的jsoup,htmlunit-2.37.0-bin以及连接数据库中的mysql.jar) 链接:https://pan.baidu.com/s/1VlylWmlhjd8K ...
- 利用jsoup爬取百度网盘资源分享连接(多线程)
突然有一天就想说能不能用某种方法把百度网盘上分享的资源连接抓取下来,于是就动手了.知乎上有人说过最好的方法就是http://pan.baidu.com/wap抓取,一看果然链接后面的uk值是一串数字, ...
- jsoup爬取网站图片
package com.ij34.JsoupTest; import java.io.File; import java.io.FileOutputStream; import java.io.Inp ...
随机推荐
- C语言强化——学生管理系统
系统模块设计 a.预处理模块 系统在启动时会根据配置文件里的内容去相应文件里去加载账户信息和学生信息. b.登陆模块 输入用户名和密码,输密码的时候用"*" 代表用户当前输入的内容 ...
- python之路——2
王二学习python的笔记以及记录,如有雷同,那也没事,欢迎交流,wx:wyb199594 复习 1.编译型:一次性将全部的代码编译成二进制文件 c c++ 优点:运行效率高 缺点:开发速度慢,不能跨 ...
- MVC 访问静态页面 View 下面放JS
http://blog.csdn.net/qq_17255515/article/details/53293120
- sed初学者实用说明
转自:http://www.codeweblog.com/sed%E5%88%9D%E5%AD%A6%E8%80%85%E5%AE%9E%E7%94%A8%E8%AF%B4%E6%98%8E/ ...
- 第9章 应用层(2)_动态主机配置协议(DHCP)
2. 动态主机配置协议(DHCP) 2.1 静态地址和动态地址的应用场景 (1)静态地址应用场景 ①IP地址不经常更改的设备(如服务器地址) ②使用有规律的IP地址以便于管理(如学校机房为方便教师管理 ...
- C Mysql API连接Mysql
最近都在查看MYsql C API文档,也遇到了很多问题,下面来简单的做一个总结. mysql多线程问题 mysql多线程处理不好,经常会发生coredump,见使用Mysql出core一文. 单线程 ...
- Spark Streaming实时数据分析
[kfk@bigdata-pro01 softwares]$ sudo rpm -ivh nc-.el6.x86_64.rpm Preparing... ####################### ...
- 微信小程序内容组件图标 icon
小程序内置了一下图标可以用 需要自定义图标的看这里 ==>微信小程序中使用iconfont/font-awesome等自定义字体图标 小程序内置图标使用示例 <icon type=&quo ...
- 5种分布式共享session的方法
集群/分布式环境下5种session处理策略 转载 2016年03月16日 08:59:53 标签: session / nginx / 分布式 / 集群 11098 转载自:http://blog. ...
- python生成器异步使用
import dis,time # 反汇编 import threading def request(): print('start request') v = yield print(v) def ...