初识Nosql
ref:http://www.runoob.com/mongodb/nosql.html
https://blog.csdn.net/testcs_dn/article/details/51225843
什么是NoSQL?
百度百科中:NoSQL,泛指非关系型的数据库。中文名:非关系型数据库,外文名:NoSQL=Not Only SQL。
看 Wikipedia中:A NoSQL (originally referring to "non SQL" or "non relational") database provides a mechanism for storage and retrieval of data which is modeled in means other than the tabular relations used in relational databases.
NoSQL(最初指的"非 SQL"或"非关系")数据库提供了一种机制用于存储和检索模型中的数据,不同于关系数据库中使用的表格关系的方式。
再看Wiki中参考的NoSQL终极指南(nosql-database.org)中说的:NoSQL DEFINITION:Next Generation Databases mostly addressing some of the points: being non-relational, distributed, open-source and horizontally scalable.
NoSQL的定义:下一代数据库主要是解决一些要点:非关系型,分布式的,开放源码和支持横向扩展。
The original intention has been modern web-scale databases. The movement began early 2009 and is growing rapidly. Often more characteristics apply such as: schema-free, easy replication support, simple API, eventually consistent / BASE (not ACID), a huge amount of data and more. So the misleading term "nosql" (the community now translates it mostly with "not only sql") should be seen as an alias to something like the definition above.
初衷是现代网络规模的数据库。该运动始于2009年初,并正在迅速增长。通常都支持的特性(共同特征),如:无架构开放架构(不需要预定义模式),易于复制,简单的API,最终一致/ 基础(不支持ACID特性),支持海量数据存储。所以,误导性术语“的NoSQL”(现在社会把它翻译大多为“不仅是SQL”),应被视为类似于上面的定义的别名。
前世今生
NoSQL最近几年才火起来,并且快速增长,那么它从什么时候开始有的呢?
Such databases have existed since the late 1960s, but did not obtain the "NoSQL" moniker until a surge of popularity in the early twenty-first century。
早啦,从60年代后期这样的数据库已经存在,但并没有取得“NoSQL”的绰号。
只是以前的应用场景更适合使用关系型的数据库,所以NoSQL类型的数据库不被大多数人需要,不被大多数人所知。
NoSQL一词最早出现于1998年,它是Carlo Strozzi开发的一个轻量、开源、不提供SQL功能的关系型数据库(他认为,由于NoSQL悖离传统关系数据库模型,因此,它应该有一个全新的名字,比如“NoREL”或与之类似的名字)。
2009年,Last.fm的Johan Oskarsson发起了一次关于分布式开源数据库的讨论,来自Rackspace的Eric Evans再次提出了NoSQL的概念,这时的NoSQL主要指非关系型、分布式、不提供ACID的数据库设计模式。
2009年在亚特兰大举行的“no:sql(east)”讨论会是一个里程碑,其口号是"select fun, profit from real_world where relational=false;"。因此,对NoSQL最普遍的解释是“非关系型的”,强调键值存储和文档数据库的优点,而不是单纯地反对关系型数据库。
诞生的原因
随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
今天我们可以通过第三方平台(如:Google,Facebook等)可以很容易的访问和抓取数据。用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍的增加。我们如果要对这些用户数据进行挖掘,那SQL数据库已经不适合这些应用了, NoSQL数据库的发展也却能很好的处理这些大的数据。
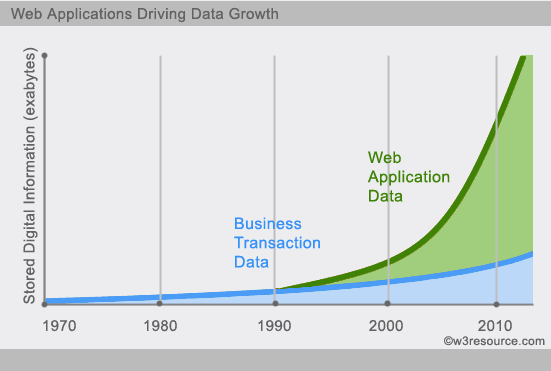
实例
社会化关系网:
Separate records: UserID, first_name,last_name, age, gender,...
Task: Find all friends of friends of friends of ... friends of a given user.
Wikipedia 页面 :
Combination of structured and unstructured data
Task: Retrieve all pages regarding athletics of Summer Olympic before 1950.
分布式系统
分布式系统(distributed system)由多台计算机和通信的软件组件通过计算机网络连接(本地网络或广域网)组成。
分布式系统是建立在网络之上的软件系统。正是因为软件的特性,所以分布式系统具有高度的内聚性和透明性。
因此,网络和分布式系统之间的区别更多的在于高层软件(特别是操作系统),而不是硬件。
分布式系统可以应用在不同的平台上如:Pc、工作站、局域网和广域网上等。
分布式计算的优点
可靠性(容错) :
分布式计算系统中的一个重要的优点是可靠性。一台服务器的系统崩溃并不影响到其余的服务器。
可扩展性:
在分布式计算系统可以根据需要增加更多的机器。
资源共享:
共享数据是必不可少的应用,如银行,预订系统。
灵活性:
由于该系统是非常灵活的,它很容易安装,实施和调试新的服务。
更快的速度:
分布式计算系统可以有多台计算机的计算能力,使得它比其他系统有更快的处理速度。
开放系统:
由于它是开放的系统,本地或者远程都可以访问到该服务。
更高的性能:
相较于集中式计算机网络集群可以提供更高的性能(及更好的性价比)。
分布式计算的缺点
故障排除:
故障排除和诊断问题。
软件:
更少的软件支持是分布式计算系统的主要缺点。
网络:
网络基础设施的问题,包括:传输问题,高负载,信息丢失等。
安全性:
开放系统的特性让分布式计算系统存在着数据的安全性和共享的风险等问题。
RDBMS vs NoSQL
RDBMS
- 高度组织化结构化数据
- 结构化查询语言(SQL)
- 数据和关系都存储在单独的表中。
- 数据操纵语言,数据定义语言
- 严格的一致性
- 基础事务
NoSQL
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式
-键 - 值对存储,列存储,文档存储,图形数据库
- 最终一致性,而非ACID属性
- 非结构化和不可预知的数据
- CAP定理
- 高性能,高可用性和可伸缩性
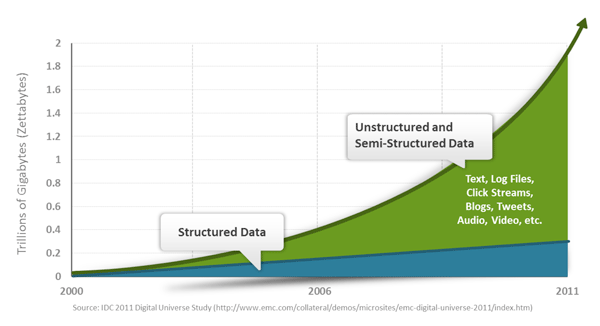
CAP定理(CAP theorem)
在计算机科学中, CAP定理(CAP theorem), 又被称作布鲁尔定理(Brewer's theorem), 它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency) (所有节点在同一时间具有相同的数据)
- 可用性(Availability) (保证每个请求不管成功或者失败都有响应)
- 分隔容忍(Partition tolerance) (系统中任意信息的丢失或失败不会影响系统的继续运作)
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三大类:
- CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
- CP - 满足一致性,分区容忍性的系统,通常性能不是特别高。
- AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
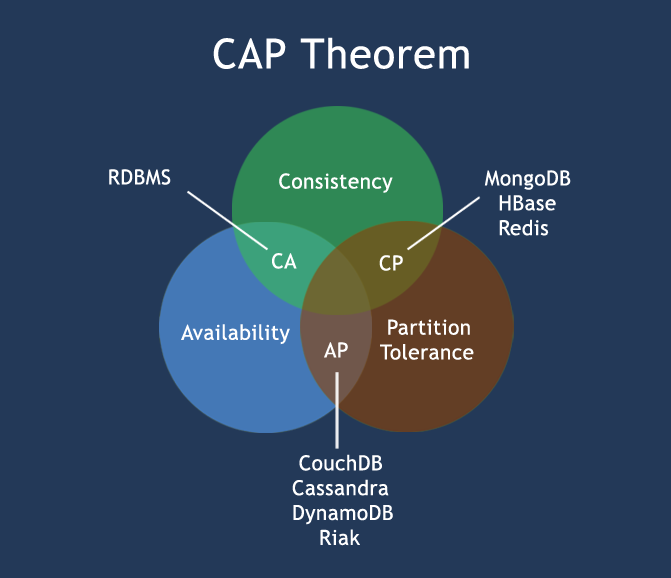
NoSQL数据库的四大分类
键值(Key-Value)存储数据库
这一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。Key/value模型对于IT系统来说的优势在于简单、易部署。但是如果DBA只对部分值进行查询或更新的时候,Key/value就显得效率低下了。例如:Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB.
列存储数据库
这部分数据库通常是用来应对分布式存储的海量数据。键仍然存在,但是它们的特点是指向了多个列。这些列是由列家族来安排的。如:Cassandra, HBase, Riak.
文档型数据库
文档型数据库的灵感是来自于Lotus Notes办公软件的,而且它同第一种键值存储相类似。该类型的数据模型是版本化的文档,半结构化的文档以特定的格式存储,比如JSON。文档型数据库可 以看作是键值数据库的升级版,允许之间嵌套键值。而且文档型数据库比键值数据库的查询效率更高。如:CouchDB, MongoDb. 国内也有文档型数据库SequoiaDB,已经开源。
图形(Graph)数据库
图形结构的数据库同其他行列以及刚性结构的SQL数据库不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上。NoSQL数据库没有标准的查询语言(SQL),因此进行数据库查询需要制定数据模型。许多NoSQL数据库都有REST式的数据接口或者查询API。如:Neo4J, InfoGrid, Infinite Graph.
因此,我们总结NoSQL数据库在以下的这几种情况下比较适用:1、数据模型比较简单;2、需要灵活性更强的IT系统;3、对数据库性能要求较高;4、不需要高度的数据一致性;5、对于给定key,比较容易映射复杂值的环境。
四大分类对比分析
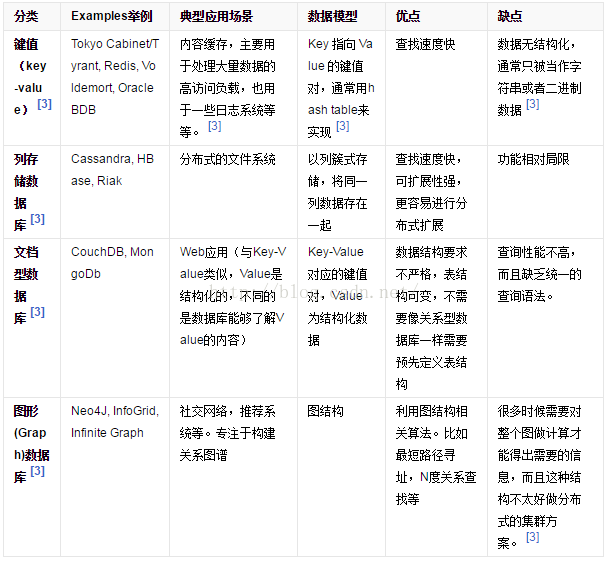
NoSQL的优点/缺点
优点:
- - 高可扩展性
- - 分布式计算
- - 低成本
- - 架构的灵活性,半结构化数据
- - 没有复杂的关系
缺点:
- - 没有标准化
- - 有限的查询功能(到目前为止)
- - 最终一致是不直观的程序
BASE
BASE:Basically Available, Soft-state, Eventually Consistent。 由 Eric Brewer 定义。
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
BASE是NoSQL数据库通常对可用性及一致性的弱要求原则:
- Basically Availble --基本可用
- Soft-state --软状态/柔性事务。 "Soft state" 可以理解为"无连接"的, 而 "Hard state" 是"面向连接"的
- Eventual Consistency -- 最终一致性, 也是是 ACID 的最终目的。
ACID vs BASE
| ACID | BASE |
| 原子性(Atomicity) | 基本可用(Basically Available) |
| 一致性(Consistency) | 软状态/柔性事务(Soft state) |
| 隔离性(Isolation) | 最终一致性 (Eventual consistency) |
| 持久性 (Durable) |
Nosql和关系型数据库的区别
1.存储方式
关系型数据库是表格式的,因此存储在表的行和列中。他们之间很容易关联协作存储,提取数据很方便。而Nosql数据库则与其相反,他是大块的组合在一起。通常存储在数据集中,就像文档、键值对或者图结构。
2.存储结构
关系型数据库对应的是结构化数据,数据表都预先定义了结构(列的定义),结构描述了数据的形式和内容。这一点对数据建模至关重要,虽然预定义结构带来了可靠性和稳定性,但是修改这些数据比较困难。而Nosql数据库基于动态结构,使用与非结构化数据。因为Nosql数据库是动态结构,可以很容易适应数据类型和结构的变化。
3.存储规范
关系型数据库的数据存储为了更高的规范性,把数据分割为最小的关系表以避免重复,获得精简的空间利用。虽然管理起来很清晰,但是单个操作设计到多张表的时候,数据管理就显得有点麻烦。而Nosql数据存储在平面数据集中,数据经常可能会重复。单个数据库很少被分隔开,而是存储成了一个整体,这样整块数据更加便于读写
4.存储扩展
这可能是两者之间最大的区别,关系型数据库是纵向扩展,也就是说想要提高处理能力,要使用速度更快的计算机。因为数据存储在关系表中,操作的性能瓶颈可能涉及到多个表,需要通过提升计算机性能来克服。虽然有很大的扩展空间,但是最终会达到纵向扩展的上限。而Nosql数据库是横向扩展的,它的存储天然就是分布式的,可以通过给资源池添加更多的普通数据库服务器来分担负载。
5.查询方式
关系型数据库通过结构化查询语言来操作数据库(就是我们通常说的SQL)。SQL支持数据库CURD操作的功能非常强大,是业界的标准用法。而Nosql查询以块为单元操作数据,使用的是非结构化查询语言(UnQl),它是没有标准的。关系型数据库表中主键的概念对应Nosql中存储文档的ID。关系型数据库使用预定义优化方式(比如索引)来加快查询操作,而Nosql更简单更精确的数据访问模式。
6.事务
关系型数据库遵循ACID规则(原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)),而Nosql数据库遵循BASE原则(基本可用(Basically Availble)、软/柔性事务(Soft-state )、最终一致性(Eventual Consistency))。由于关系型数据库的数据强一致性,所以对事务的支持很好。关系型数据库支持对事务原子性细粒度控制,并且易于回滚事务。而Nosql数据库是在CAP(一致性、可用性、分区容忍度)中任选两项,因为基于节点的分布式系统中,很难全部满足,所以对事务的支持不是很好,虽然也可以使用事务,但是并不是Nosql的闪光点。
7.性能
关系型数据库为了维护数据的一致性付出了巨大的代价,读写性能比较差。在面对高并发读写性能非常差,面对海量数据的时候效率非常低。而Nosql存储的格式都是key-value类型的,并且存储在内存中,非常容易存储,而且对于数据的 一致性是 弱要求。Nosql无需sql的解析,提高了读写性能。
8.授权方式
关系型数据库通常有SQL Server,Mysql,Oracle。主流的Nosql数据库有redis,memcache,MongoDb。大多数的关系型数据库都是付费的并且价格昂贵,成本较大,而Nosql数据库通常都是开源的。
谁在使用
现在已经有很多公司使用了 NoSQL:
- Mozilla
- Adobe
- Foursquare
- Digg
- McGraw-Hill Education
- Vermont Public Radio
初识Nosql的更多相关文章
- 初识 NoSQL Databases RethinkDB
初识 NoSQL Databases RethinkDB rethinkDB所有数据都是基于 json的Document; 官网:http://rethinkdb.com/ github: https ...
- 初识NoSQL 快速认识NoSQL数据库 分析Analytics For Hackers: How To Think About Event Data
做了一年的大一年度项目了,对于关系型数据库结构还是有些了解了,有的时候还是觉得这种二维表不是很顺手.在看过一篇文章之后,对NoSQL有了初步的了解,(https://keen.io/blog/5395 ...
- Key-Value键值存储原理初识(NOSQL)
NO-Sql数据库:Not Only不仅仅是SQL 定义:非关系型数据库:NoSQL用于超大规模数据的存储.(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据).这些类型的数据存储不需要固 ...
- mongDB
MongoDB[第一篇]MongodDB初识 NoSQL介绍 一.NoSQL简介 NoSQL,全称是”Not Only Sql”,指的是非关系型的数据库. 非关系型数据库主要有这些特点:非关系型的 ...
- 初识关系型数据库(SQL)与非关系型数据库(NOSQL)
一.关系型数据库(SQL): Mysql,oracle 特点:数据和数据之间,表和字段之间,表和表之间是存在关系的 例如:部门表 001部分, 员工表 001 用户表,用户名.密码 分类表 和 商 ...
- MongoDB【第一篇】MongodDB初识
NoSQL介绍 一.NoSQL简介 NoSQL,全称是”Not Only Sql”,指的是非关系型的数据库. 非关系型数据库主要有这些特点:非关系型的.分布式的.开源的.水平可扩展的. 原始的目的是为 ...
- 初识MongoDB
1. 初识 接触MongoDB,是由于最近在工作中用到了MongoDB做数据存储.之前也听说过这个NoSQL数据库,但是一直没有尝试去使用它做开发.这次趁着这个机会,想好好学习下这个NoSQL数据库. ...
- NoSQL和Redis简介及Redis在Windows下的安装和使用教程
转载于:http://www.itxuexiwang.com/a/shujukujishu/redis/2016/0216/103.html?1455869099 NoSQL简介 介绍redis前,我 ...
- 初识Identity
初识Identity 摘要 通过本文你将了解ASP.NET身份验证机制,表单认证的基本流程,ASP.NET Membership的一些弊端以及ASP.NET Identity的主要优势. 目录 身份验 ...
随机推荐
- 跟着刚哥学习Spring框架--事务配置(七)
事务 事务用来保证数据的完整性和一致性. 事务应该具有4个属性:原子性.一致性.隔离性.持久性.这四个属性通常称为ACID特性.1.原子性(atomicity).一个事务是一个不可分割的工作单位,事务 ...
- Java - 获取帮助信息
在线开发文档 Java SE 8 Java SE 8 Developer Guides Java SE 8 API Specification Java API Specifications 离线开发 ...
- 《Python编程从入门到实践》--- 学习过程笔记(3)列表
一.用[](方括号)表示列表,用,(逗号)分隔其中的元素. >>> name=['limei', 'hanmeimei', 'xiaoming'] >>> prin ...
- C语言写了一个socket client端,适合windows和linux,用GCC编译运行通过
////////////////////////////////////////////////////////////////////////////////* gcc -Wall -o c1 c1 ...
- 插入排序的Java代码实现
插入排序也是一类非常常见的排序方法,它主要包含直接插入排序,Shell排序和折半插入排序等几种常见的排序方法. 1.直接插入排序 直接插入排序的思路非常简单:依次将待排序的数据元素按其关键字值的大小插 ...
- oc中类的实例化及方法调用
上一篇我们讲了oop和类的创建,上一篇的重点我们回顾一下 类 对象 实例 方法 接口 这一篇我们来实现类的实例化,调用类中的公共参数和方法:类的实现在.m文件中,以下是实现代码: // // HuiT ...
- redisTemplate实现轻量级消息队列, 异步处理excel并实现腾讯云cos文件上传下载
背景 公司项目有个需求, 前端上传excel文件, 后端读取数据.处理数据.返回错误数据, 最简单的方式同步处理, 客户端上传文件后一直阻塞等待响应, 但用户体验无疑很差, 处理数据可能十分耗时, 没 ...
- docker OCI runtime
Open Container Initiative(OCI)目前有2个标准:runtime-spec以及image-spec.前者规定了如何运行解压过的filesystem bundle.OCI规定了 ...
- TCP保活的必要性
TCP的长连接理论上只要连接建立后,就会一直保持着.但有时有一些防火墙之类的软件会自动检查主机的网络连接状况,比如说如果发现某个连接在几分钟之内都没有数据通讯,则会关闭这个连接.有时客户端与服务器需要 ...
- Andrew Ng机器学习课程笔记(一)之线性回归
Andrew Ng机器学习课程笔记(一)之线性回归 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7364598.html 前言 ...