hadoop分布式集群的搭建

电脑如果是8G内存或者以下建议搭建3节点集群,如果是搭建5节点集群就要增加内存条了。当然实际开发中不会用虚拟机做,一些小公司刚刚起步的时候会采用云服务,因为开始数据量不大。
但随着数据量的增大才会考虑搭建自己的集群,中大型公司肯定会搭建自己的专属集群,毕竟云服务用起来方便,但是还是有很多的局限性。
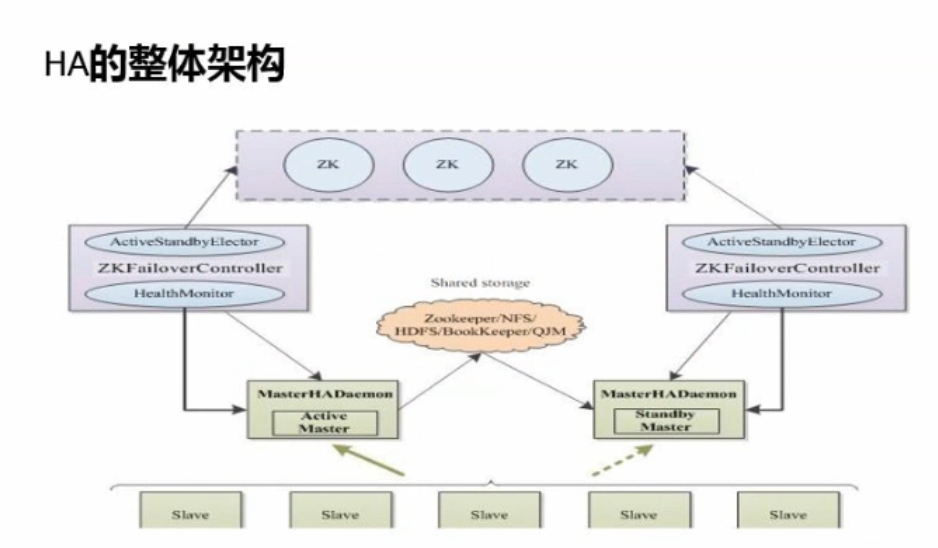
简单的集群架构图

1.journalnode来现主备节点之间的数据共享。
2.zookeeper实现主备节点的切换,通过选举机制来实现的。

1. 内存的选择一部是大内存容量的,64G 128G以上的,磁盘选择TB级别的,企业里会根据数据量的增大定期添加服务器,一般需要提前规划好,大概一年添加一次这样。
2.集群的部署方面,主节点和从节点是分开部署的,但一定要注意了,计算节点跟数据节点一定要部署在同一个节点上,datanode和nodemanager。
3.如果集群规模比较小20--30台机器这样子,namenode和resourcemanager可以部署在同一个节点上。
4.影响集群规模的因素还有在做高可用HA的时候,namenode和resourcemanager的高可用,还有就是客户的client要跟连接到集群上,我们建议客户端跟集群单独部署。
5.从性能考虑集群是规模,比如说处理1T的数据需要多少时间,比方说导入1T的数据要求是1个小时,对功能性要要求的。
6.可靠性需要,比如说系统一个月只能运行当机一次,可用性考虑,如果当机了要花多少时间能恢复,比如说要2个小时。所以在选择机器的时候可以廉价但不能太廉价,不能以后都把时间花在维护上面。还有就是每个节点的故障率,单个节点当机恢复时间也不能太久。
7.容错性需求,比如说节点当机或者硬件损坏了,但我们尽可能不能让数据丢失,或者说能恢复部分数据,对恢复时间有要求,namenode当机了恢复时间也需要快点。
8.还有就是机架--机架感知。


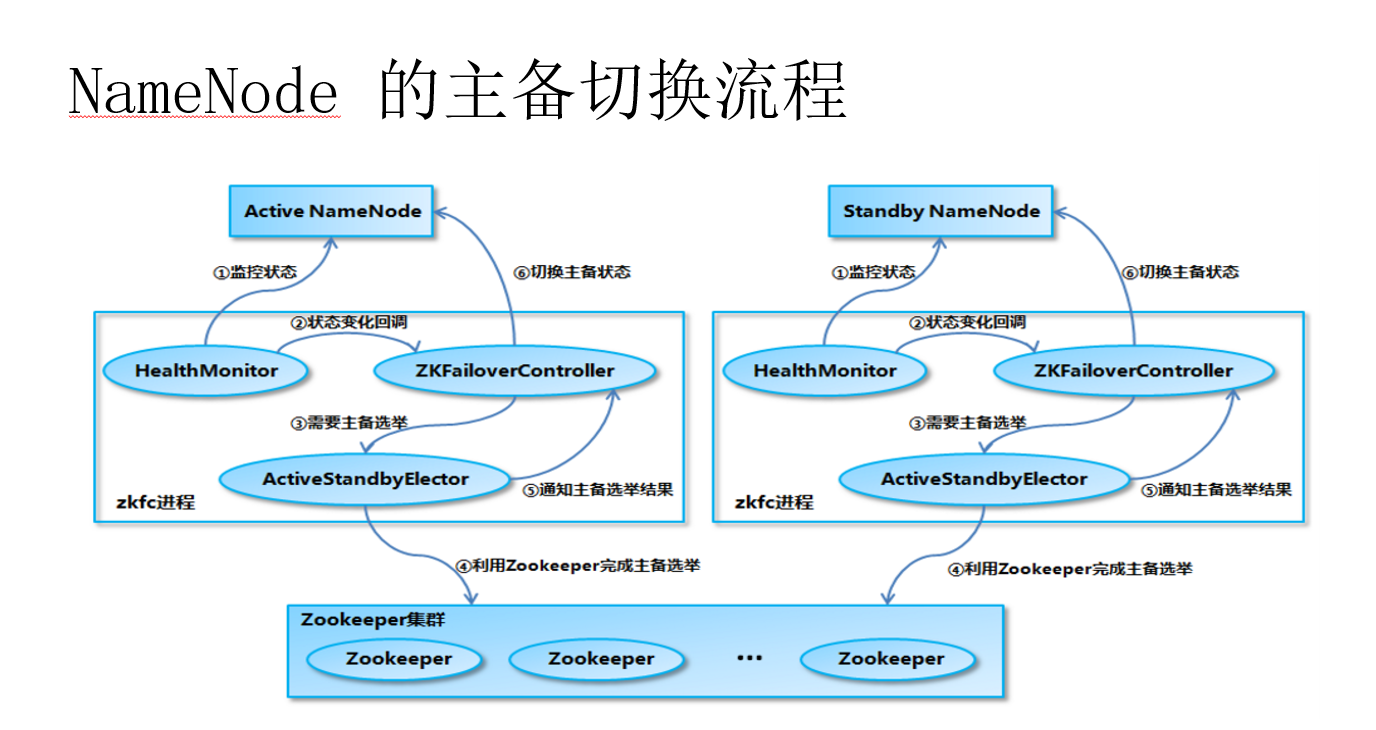
HADOOP HA



启动集群的时候要注意了先启动zookeeper,再启动hadoop,关闭的时候先关闭hadoop,再关闭zookeeper。

这个共享存储存的是编辑日志editlog.
Datanode这执行Active状态的Namenode命令



如何克隆节点:
先在想克隆的节点那里选中克隆选项,必须确保是关闭状态的
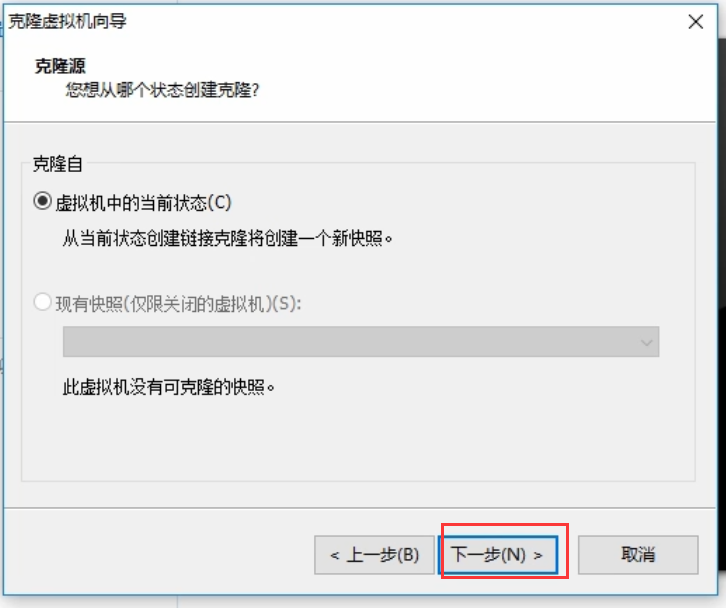


现在打开克隆好的节点

会发现主机名跟之前的是一样的,所以这里需要我们自己去修改了。
由于各个克隆出来的节点还不能上网

ping他的网关是不通的,可能是网卡没启动,需要我们去修改网卡了!



经过查看网卡已经启动了!ONBOOT=yes
是因为我们克隆了又两个网卡,网卡的地址不一样
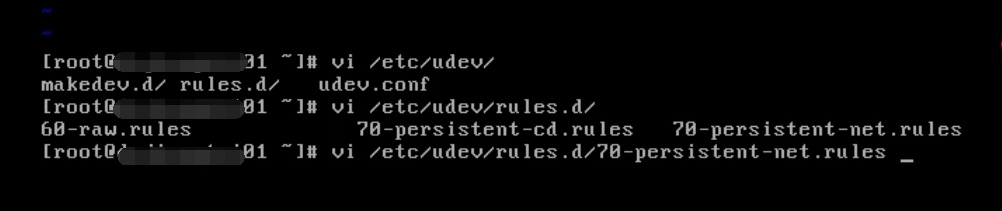
我们可以看到有两个网卡,正常情况下只有eth0网卡,克隆完了之后多了一个eth1网卡
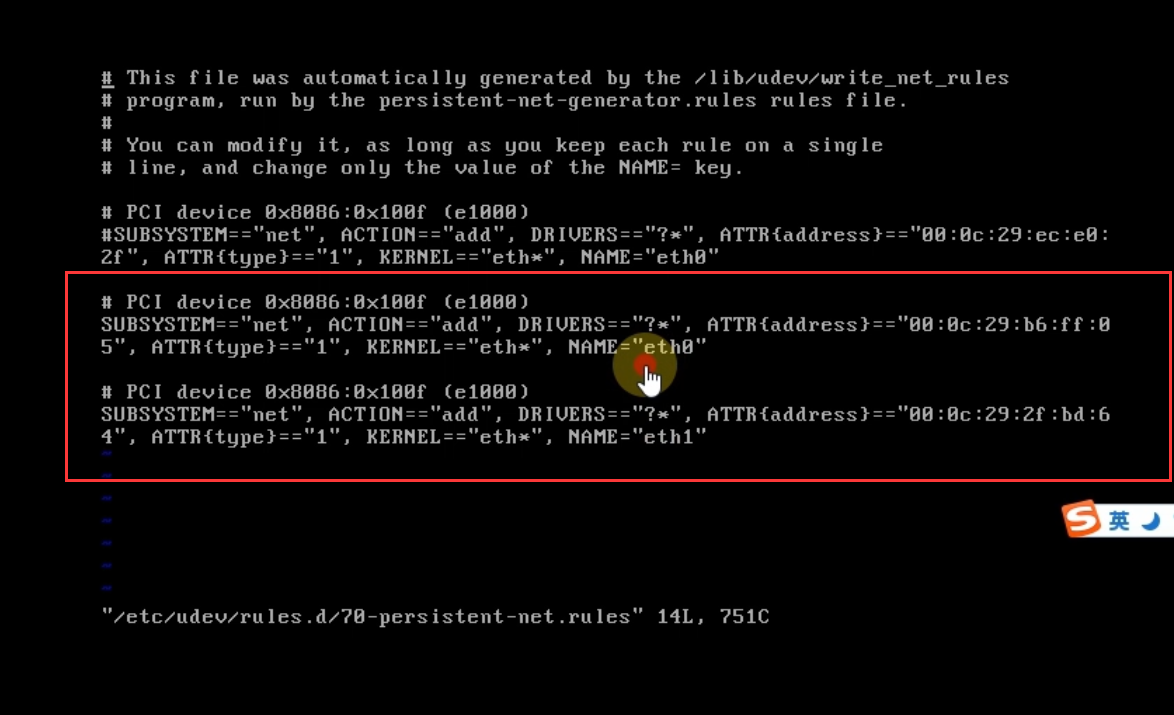
接下来我们需要做的就是把eth0注释掉,把eth1改成eth0,同时把eth1的这个地址记下来

把他修改一下

把刚刚记下来的地址修改到这里来
路径在这里


保存之后重启一下网卡,结果发现重启失败!!
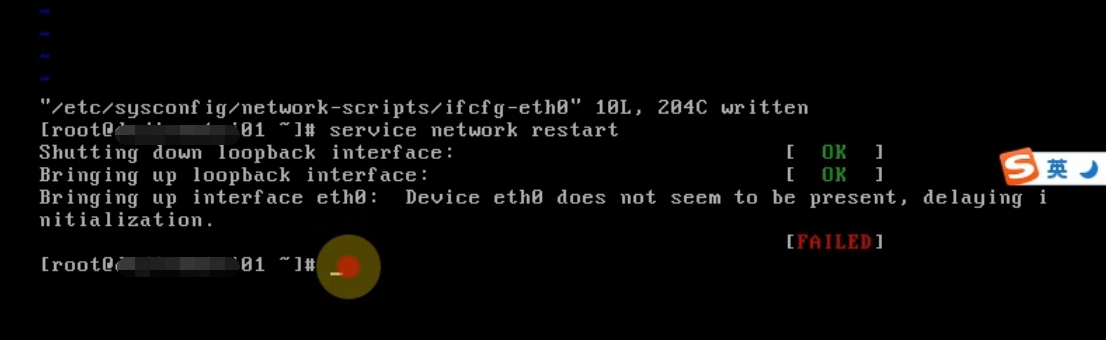
那我们就是reboot重启一下系统

重启之后可以看到网卡启动成功了
网卡能ping通了

查看一下他的ip地址

可以看到是一个静态ip地址,也就是说跟克隆前的那个节点是一样的,毕竟是克隆过来嘛,所以可以根据自己的需要去进行修改。
ping一下他的ip地址也是可以ping通的

可以看到网络是通的
好了,现在实现了克隆完节点之后的网络通信的几个步骤,关于这点我之前一直不敢去克隆。建议大家克隆完以后把主机名、ip地址都修改一下,不要跟之前的重复了,不然一起启动的时候容易出问题的。
(四)集群安装前的环境检查
时钟同步
所有节点的系统时间要与当前时间保持一致。
查看当前系统时间
date
Tue Nov 3 06:06:04 CST 2015
如果系统时间与当前时间不一致,进行以下操作。
[root@hadoop11 ~]# cd /usr/share/zoneinfo/
[root@hadoop11 zoneinfo]# ls //找到Asia
[root@hadoop11 zoneinfo]# cd Asia/ //进入Asia目录
[root@hadoop11 Asia]# ls //找到Shanghai
[root@hadoop11 Asia]# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime //当前时区替换为上海
我们可以同步当前系统时间和日期与NTP(网络时间协议)一致。
[root@hadoop11 Asia]# yum install ntp //如果ntp命令不存在,在线安装ntp
[root@hadoop11 Asia]# ntpdate pool.ntp.org //执行此命令同步日期时间
[root@hadoop11 Asia]# date //查看当前系统时间
hosts文件检查
所有节点的hosts文件都要配置静态ip与hostname之间的对应关系。
[root@hadoop11 Asia]# vi /etc/hosts
192.168.1.171 hadoop11
192.168.1.172 hadoop12
192.168.1.173 hadoop13
192.168.1.174 hadoop14
192.168.1.175 hadoop15
禁用防火墙
所有节点的防火墙都要关闭。
查看防火墙状态
[root@hadoop11 Asia]# service iptables status
iptables: Firewall is not running.
如果不是上面的关闭状态,则需要关闭防火墙。
[root@hadoop11 Asia]# chkconfig iptables off //永久关闭防火墙
[root@hadoop11 Asia]# service iptables stop //临时关闭防火墙
(五)配置SSH免密码通信
这里我们以hadoop11来配置ssh。
[root@hadoop11 ~]# su hadoop //切换到hadoop用户下
[hadoop@hadoop11 root]$ cd //切换到hadoop用户目录
[hadoop@hadoop11 ~]$ mkdir .ssh
[hadoop@hadoop11 ~]$ ssh-keygen -t rsa //执行命令一路回车,生成秘钥
[hadoop@hadoop11 ~]$cd .ssh
[hadoop@hadoop11 .ssh]$ ls
id_rsa id_rsa.pub
[hadoop@hadoop11 .ssh]$ cat id_rsa.pub >> authorized_keys //将公钥保存到authorized_keys认证文件中
[hadoop@hadoop11 .ssh]$ ls
authorized_keys id_rsa id_rsa.pub
[hadoop@hadoop11 .ssh]$ cd ..
[hadoop@hadoop11 ~]$ chmod 700 .ssh
[hadoop@hadoop11 ~]$ chmod 600 .ssh/*
[hadoop@hadoop11 ~]$ ssh hadoop11 //第一次执行需要输入yes
[hadoop@hadoop11 ~]$ ssh hadoop11 //第二次以后就可以直接访问
集群所有节点都要行上面的操作。
将所有节点中的共钥id_ras.pub拷贝到hadoop11中的authorized_keys文件中。
cat ~/.ssh/id_rsa.pub | ssh hadoop@hadoop11 'cat >> ~/.ssh/authorized_keys' 所有节点都需要执行这条命令
然后将hadoop11中的authorized_keys文件分发到所有节点上面。
scp -r authorized_keys hadoop@hadoop12:~/.ssh/ scp -r authorized_keys hadoop@hadoop13:~/.ssh/ scp -r authorized_keys hadoop@hadoop14:~/.ssh/ scp -r authorized_keys hadoop@hadoop15:~/.ssh/
大家通过ssh 相互访问,如果都能无密码访问,代表ssh配置成功。
(六)脚本工具的使用
在hadoop11节点上创建/home/hadoop/tools目录。
[hadoop@hadoop11 ~]$ mkdir /home/hadoop/tools
cd /home/hadoop/tools
将本地脚本文件上传至/home/hadoop/tools目录下。这些脚本大家如果能看懂也可以自己写, 如果看不懂直接使用就可以,后面慢慢补补Linux相关的知识。
[hadoop@hadoop11 tools]$ rz deploy.conf
[hadoop@hadoop11 tools]$ rz deploy.sh
[hadoop@hadoop11 tools]$ rz runRemoteCmd.sh
[hadoop@hadoop11 tools]$ ls
deploy.conf deploy.sh runRemoteCmd.sh
查看一下deploy.conf配置文件内容。
[hadoop@hadoop11 tools]$ cat deploy.conf
hadoop11,all,namenode,zookeeper,resourcemanager,
hadoop12,all,slave,namenode,zookeeper,resourcemanager,
hadoop13,all,slave,datanode,zookeeper,
hadoop14,all,slave,datanode,zookeeper,
hadoop15,all,slave,datanode,zookeeper,
查看一下deploy.sh远程复制文件脚本内容。
[hadoop@hadoop11 tools]$ cat deploy.sh
#!/bin/bash
#set -x if [ $# -lt 3 ]
then
echo "Usage: ./deply.sh srcFile(or Dir) descFile(or Dir) MachineTag"
echo "Usage: ./deply.sh srcFile(or Dir) descFile(or Dir) MachineTag confFile"
exit
fi src=$1
dest=$2
tag=$3
if [ 'a'$4'a' == 'aa' ]
then
confFile=/home/hadoop/tools/deploy.conf
else
confFile=$4
fi if [ -f $confFile ]
then
if [ -f $src ]
then
for server in `cat $confFile|grep -v '^#'|grep ','$tag','|awk -F',' '{print $1}'`
do
scp $src $server":"${dest}
done
elif [ -d $src ]
then
for server in `cat $confFile|grep -v '^#'|grep ','$tag','|awk -F',' '{print $1}'`
do
scp -r $src $server":"${dest}
done
else
echo "Error: No source file exist"
fi else
echo "Error: Please assign config file or run deploy.sh command with deploy.conf in same directory"
fi
查看一下runRemoteCmd.sh远程执行命令脚本内容。
[hadoop@hadoop11 tools]$ cat runRemoteCmd.sh
#!/bin/bash
#set -x if [ $# -lt 2 ]
then
echo "Usage: ./runRemoteCmd.sh Command MachineTag"
echo "Usage: ./runRemoteCmd.sh Command MachineTag confFile"
exit
fi cmd=$1
tag=$2
if [ 'a'$3'a' == 'aa' ]
then confFile=/home/hadoop/tools/deploy.conf
else
confFile=$3
fi if [ -f $confFile ]
then
for server in `cat $confFile|grep -v '^#'|grep ','$tag','|awk -F',' '{print $1}'`
do
echo "*******************$server***************************"
ssh $server "source /etc/profile; $cmd"
done
else
echo "Error: Please assign config file or run deploy.sh command with deploy.conf in same directory"
fi
以上三个文件,方便我们搭建hadoop分布式集群。具体如何使用看后面如何操作。
如果我们想直接使用脚本,还需要给脚本添加执行权限。
[hadoop@hadoop11 tools]$ chmod u+x deploy.sh
[hadoop@hadoop11 tools]$ chmod u+x runRemoteCmd.sh
同时我们需要将/home/hadoop/tools目录配置到PATH路径中。
[hadoop@hadoop11 tools]$ su root
Password:
[root@hadoop11 tools]# vi /etc/profile
PATH=/home/hadoop/tools:$PATH
export PATH
我们在hadoop11节点上,通过runRemoteCmd.sh脚本,一键创建所有节点的软件安装目录/home/hadoop/app。
[hadoop@hadoop11 tools]$ runRemoteCmd.sh "mkdir /home/hadoop/app" all
我们可以在所有节点查看到/home/hadoop/app目录已经创建成功。
(七)jdk安装
将本地下载好的jdk1.7,上传至hadoop11节点下的/home/hadoop/app目录。
[root@hadoop11 tools]# su hadoop
[hadoop@hadoop11 tools]$ cd /home/hadoop/app/
[hadoop@hadoop11 app]$ rz //选择本地的下载好的jdk-7u79-linux-x64.tar.gz
[hadoop@hadoop11 app]$ ls
jdk-7u79-linux-x64.tar.gz
[hadoop@hadoop11 app]$ tar zxvf jdk-7u79-linux-x64.tar.gz //解压
[hadoop@hadoop11 app]$ ls
jdk1.7.0_79 jdk-7u79-linux-x64.tar.gz
[hadoop@hadoop11 app]$ rm jdk-7u79-linux-x64.tar.gz //删除安装包
添加jdk环境变量。
[hadoop@hadoop11 app]$ su root
Password:
[root@hadoop11 app]# vi /etc/profile
JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
[root@hadoop11 app]# source /etc/profile //使配置文件生效
查看jdk是否安装成功。
[root@hadoop11 app]# java -version
java version "1.7.0_79"
Java(TM) SE Runtime Environment (build 1.7.0_79-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.79-b02, mixed mode)
出现以上结果就说明hadoop11节点上的jdk安装成功。
然后将hadoop11下的jdk安装包复制到其他节点上。
[hadoop@hadoop11 app]$ deploy.sh jdk1.7.0_79 /home/hadoop/app/ slave
hadoop12,hadoop13,hadoop14,hadoop15节点重复hadoop11节点上的jdk配置即可。
(八)Zookeeper安装
将本地下载好的zookeeper-3.4.6.tar.gz安装包,上传至hadoop11节点下的/home/hadoop/app目录下。
[hadoop@hadoop11 app]$ rz //选择本地下载好的zookeeper-3.4.6.tar.gz
[hadoop@hadoop11 app]$ ls
jdk1.7.0_79 zookeeper-3.4.6.tar.gz
[hadoop@hadoop11 app]$ tar zxvf zookeeper-3.4.6.tar.gz //解压
[hadoop@hadoop11 app]$ ls
jdk1.7.0_79 zookeeper-3.4.6.tar.gz zookeeper-3.4.6
[hadoop@hadoop11 app]$ rm zookeeper-3.4.6.tar.gz //删除zookeeper-3.4.6.tar.gz安装包
[hadoop@hadoop11 app]$ mv zookeeper-3.4.6 zookeeper //重命名
修改Zookeeper中的配置文件。
[hadoop@hadoop11 app]$ cd /home/hadoop/app/zookeeper/conf/
[hadoop@hadoop11 conf]$ ls
configuration.xsl log4j.properties zoo_sample.cfg
[hadoop@hadoop11 conf]$ cp zoo_sample.cfg zoo.cfg //复制一个zoo.cfg文件
[hadoop@hadoop11 conf]$ vi zoo.cfg
dataDir=/home/hadoop/data/zookeeper/zkdata //数据文件目录
dataLogDir=/home/hadoop/data/zookeeper/zkdatalog //日志目录
# the port at which the clients will connect
clientPort=2181 //默认端口号
#server.服务编号=主机名称:Zookeeper不同节点之间同步和通信的端口:选举端口(选举leader)
server.1=hadoop11:2888:3888
server.2=hadoop12:2888:3888
server.3=hadoop13:2888:3888
server.4=hadoop14:2888:3888
server.5=hadoop15:2888:3888
通过远程命令deploy.sh将Zookeeper安装目录拷贝到其他节点上面。
[hadoop@hadoop11 app]$ deploy.sh zookeeer /home/hadoop/app slave
通过远程命令runRemoteCmd.sh在所有的节点上面创建目录:
[hadoop@hadoop11 app]$ runRemoteCmd.sh "mkdir -p /home/hadoop/data/zookeeper/zkdata" all //创建数据目录
[hadoop@hadoop11 app]$ runRemoteCmd.sh "mkdir -p /home/hadoop/data/zookeeper/zkdatalog" all //创建日志目录
然后分别在hadoop11、hadoop12、hadoop13、hadoop14、hadoop15上面,进入zkdata目录下,创建文件myid,里面的内容分别填充为:1、2、3、4、5, 这里我们以hadoop11为例。
[hadoop@hadoop11 app]$ cd /home/hadoop/data/zookeeper/zkdata
[hadoop@hadoop11 zkdata]$ vi myid
1 //输入数字1
配置Zookeeper环境变量。
[hadoop@hadoop11 zkdata]$ su root
Password:
[root@hadoop11 zkdata]# vi /etc/profile
JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
ZOOKEEPER_HOME=/home/hadoop/app/zookeeper
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH ZOOKEEPER_HOME
[root@hadoop11 zkdata]# source /etc/profile //使配置文件生效
在hadoop11节点上面启动Zookeeper。
[hadoop@hadoop11 zkdata]$ cd /home/hadoop/app/zookeeper/
[hadoop@hadoop11 zookeeper]$ bin/zkServer.sh start
[hadoop@hadoop11 zookeeper]$ jps
3633 QuorumPeerMain
[hadoop@hadoop11 zookeeper]$ bin/zkServer.sh stop //关闭Zookeeper
使用runRemoteCmd.sh 脚本,启动所有节点上面的Zookeeper。
runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh start" zookeeper
查看所有节点上面的QuorumPeerMain进程是否启动。
runRemoteCmd.sh "jps" zookeeper
查看所有Zookeeper节点状态。
runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh status" zookeeper
如果一个节点为leader,另四个节点为follower,则说明Zookeeper安装成功。
(九)hadoop集群环境搭建
将下载好的apache hadoop-2.6.0.tar.gz安装包,上传至hadoop11节点下的/home/hadoop/app目录下。
[hadoop@hadoop11 app]$ rz //将本地的hadoop-2.6.0.tar.gz安装包上传至当前目录
[hadoop@hadoop11 app]$ ls
hadoop-2.6.0.tar.gz jdk1.7.0_79 zookeeper
[hadoop@hadoop11 app]$ tar zxvf hadoop-2.6.0.tar.gz //解压
[hadoop@hadoop11 app]$ ls
hadoop-2.6.0 hadoop-2.6.0.tar.gz jdk1.7.0_79 zookeeper
[hadoop@hadoop11 app]$ rm hadoop-2.6.0.tar.gz //删除安装包
[hadoop@hadoop11 app]$ mv hadoop-2.6.0 hadoop //重命名
切换到/home/hadoop/app/hadoop/etc/hadoop/目录下,修改配置文件。
[hadoop@hadoop11 app]$ cd /home/hadoop/app/hadoop/etc/hadoop/
配置HDFS
配置hadoop-env.sh
[hadoop@hadoop11 hadoop]$ vi hadoop-env.sh
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
配置core-site.xml
[hadoop@hadoop11 hadoop]$ vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1</value>
</property>
< 这里的值指的是默认的HDFS路径 ,取名为cluster1>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/tmp</value>
</property>
< hadoop的临时目录,如果需要配置多个目录,需要逗号隔开,data目录需要我们自己创建>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop11:2181,hadoop12:2181,hadoop13:2181,hadoop14:2181,hadoop15:2181</value>
</property>
< 配置Zookeeper 管理HDFS>
</configuration>
配置hdfs-site.xml
[hadoop@hadoop11 hadoop]$ vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
< 数据块副本数为3>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
< 权限默认配置为false>
<property>
<name>dfs.nameservices</name>
<value>cluster1</value>
</property>
< 命名空间,它的值与fs.defaultFS的值要对应,namenode高可用之后有两个namenode,cluster1是对外提供的统一入口>
<property>
<name>dfs.ha.namenodes.cluster1</name>
<value>hadoop11,hadoop12</value>
</property>
< 指定 nameService 是 cluster1 时的nameNode有哪些,这里的值也是逻辑名称,名字随便起,相互不重复即可>
<property>
<name>dfs.namenode.rpc-address.cluster1.hadoop11</name>
<value>hadoop11:9000</value>
</property>
< hadoop11 rpc地址>
<property>
<name>dfs.namenode.http-address.cluster1.hadoop11</name>
<value>hadoop11:50070</value>
</property>
< hadoop11 http地址>
<property>
<name>dfs.namenode.rpc-address.cluster1.hadoop12</name>
<value>hadoop12:9000</value>
</property>
< hadoop12 rpc地址>
<property>
<name>dfs.namenode.http-address.cluster1.hadoop12</name>
<value>hadoop12:50070</value>
</property>
< hadoop12 http地址>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
< 启动故障自动恢复>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop11:8485;hadoop12:8485;hadoop13:8485;hadoop14:8485;hadoop15:8485/cluster1</value>
</property>
< 指定journal>
<property>
<name>dfs.client.failover.proxy.provider.cluster1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
< 指定 cluster1 出故障时,哪个实现类负责执行故障切换>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/data/journaldata/jn</value>
</property>
< 指定JournalNode集群在对nameNode的目录进行共享时,自己存储数据的磁盘路径 >
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>10000</value>
</property>
< 脑裂默认配置>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
</configuration>
配置 slave
[hadoop@hadoop11 hadoop]$ vi slaves
hadoop13
hadoop14
hadoop15
向所有节点分发hadoop安装包。
[hadoop@hadoop11 app]$ deploy.sh hadoop /home/hadoop/app/ slave
hdfs配置完毕后启动顺序
1、启动所有节点上面的Zookeeper进程
[hadoop@hadoop11 hadoop]$ runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh start" zookeeper
2、启动所有节点上面的journalnode进程
[hadoop@hadoop11 hadoop]$ runRemoteCmd.sh "/home/hadoop/app/hadoop/sbin/hadoop-daemon.sh start journalnode" all
3、首先在主节点上(比如,hadoop11)执行格式化
[hadoop@hadoop11 hadoop]$ bin/hdfs namenode -format / /namenode 格式化
[hadoop@hadoop11 hadoop]$ bin/hdfs zkfc -formatZK //格式化高可用
[hadoop@hadoop11 hadoop]$bin/hdfs namenode //启动namenode
4、与此同时,需要在备节点(比如,hadoop12)上执行数据同步
[hadoop@hadoop12 hadoop]$ bin/hdfs namenode -bootstrapStandby //同步主节点和备节点之间的元数据
5、hadoop12同步完数据后,紧接着在hadoop11节点上,按下ctrl+c来结束namenode进程。 然后关闭所有节点上面的journalnode进程
[hadoop@hadoop11 hadoop]$ runRemoteCmd.sh "/home/hadoop/app/hadoop/sbin/hadoop-daemon.sh stop journalnode" all //然后停掉各节点的journalnode
6、如果上面操作没有问题,我们可以一键启动hdfs所有相关进程
[hadoop@hadoop11 hadoop]$ sbin/start-dfs.sh
启动成功之后,关闭其中一个namenode ,然后在启动namenode 观察切换的状况。
7、验证是否启动成功
通过web界面查看namenode启动情况。
http://hadoop11:50070
YARN安装配置
配置mapred-site.xml
[hadoop@hadoop11 hadoop]$ vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<指定运行mapreduce的环境是Yarn,与hadoop1不同的地方>
</configuration>
配置yarn-site.xml
[hadoop@hadoop11 hadoop]$ vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
< 超时的周期>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
< 打开高可用>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<启动故障自动恢复>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
</property>
<failover使用内部的选举算法>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-rm-cluster</value>
</property>
<给yarn cluster 取个名字yarn-rm-cluster>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<给ResourceManager 取个名字 rm1,rm2>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop11</value>
</property>
<配置ResourceManagerrm1hostname>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop12</value>
</property>
<配置ResourceManagerrm2hostname>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<启用resourcemanager 自动恢复>
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<value>hadoop11:2181,hadoop12:2181,hadoop13:2181,hadoop14:2181,hadoop15:2181</value>
</property>
<配置Zookeeper地址>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop11:2181,hadoop12:2181,hadoop13:2181,hadoop14:2181,hadoop15:2181</value>
</property>
<配置Zookeeper地址>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>hadoop11:8032</value>
</property>
< rm1端口号>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>hadoop11:8034</value>
</property>
< rm1调度器的端口号>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop11:8088</value>
</property>
< rm1webapp端口号>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>hadoop12:8032</value>
</property>
< rm2端口号>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>hadoop12:8034</value>
</property>
< rm2调度器的端口号>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop12:8088</value>
</property>
< rm2webapp端口号>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<执行MapReduce需要配置的shuffle过程>
</configuration>
启动YARN
1、在hadoop11节点上执行。
[hadoop@hadoop11 hadoop]$ sbin/start-yarn.sh
2、在hadoop12节点上面执行。
[hadoop@hadoop11 hadoop]$ sbin/yarn-daemon.sh start resourcemanager
同时打开一下web界面。
http://hadoop11:8088
http://hadoop12:8088
关闭其中一个resourcemanager,然后再启动,看看这个过程的web界面变化。
3、检查一下ResourceManager状态
[hadoop@hadoop11 hadoop]$ bin/yarn rmadmin -getServiceState rm1
[hadoop@hadoop11 hadoop]$ bin/yarn rmadmin -getServiceState rm2
4、Wordcount示例测试
[hadoop@hadoop11 hadoop]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /test/hadoop.txt /test/out/
hadoop分布式集群的搭建的更多相关文章
- hadoop分布式集群环境搭建
参考 http://www.cnblogs.com/zhijianliutang/p/5736103.html 1 wget http://mirrors.shu.edu.cn/apache/hado ...
- 超快速使用docker在本地搭建hadoop分布式集群
超快速使用docker在本地搭建hadoop分布式集群 超快速使用docker在本地搭建hadoop分布式集群 学习hadoop集群环境搭建是hadoop入门的必经之路.搭建分布式集群通常有两个办法: ...
- 基于Hadoop分布式集群YARN模式下的TensorFlowOnSpark平台搭建
1. 介绍 在过去几年中,神经网络已经有了很壮观的进展,现在他们几乎已经是图像识别和自动翻译领域中最强者[1].为了从海量数据中获得洞察力,需要部署分布式深度学习.现有的DL框架通常需要为深度学习设置 ...
- Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很多问题.以下是自己根据搭建Hadoop分布式集群的经验希望给新手一些帮助.当然,建议先把HDFS ...
- Hadoop分布式集群搭建
layout: "post" title: "Hadoop分布式集群搭建" date: "2017-08-17 10:23" catalog ...
- 暑假第二弹:基于docker的hadoop分布式集群系统的搭建和测试
早在四月份的时候,就已经开了这篇文章.当时是参加数据挖掘的比赛,在计科院大佬的建议下用TensorFlow搞深度学习,而且要在自己的hadoop分布式集群系统下搞. 当时可把我们牛逼坏了,在没有基础的 ...
- 使用Docker在本地搭建Hadoop分布式集群
学习Hadoop集群环境搭建是Hadoop入门必经之路.搭建分布式集群通常有两个办法: 要么找多台机器来部署(常常找不到机器) 或者在本地开多个虚拟机(开销很大,对宿主机器性能要求高,光是安装多个虚拟 ...
- 分布式计算(一)Ubuntu搭建Hadoop分布式集群
最近准备接触分布式计算,学习分布式计算的技术栈和架构知识.目前的分布式计算方式大致分为两种:离线计算和实时计算.在大数据全家桶中,离线计算的优秀工具当属Hadoop和Spark,而实时计算的杰出代表非 ...
- hadoop学习第二天-了解HDFS的基本概念&&分布式集群的搭建&&HDFS基本命令的使用
一.HDFS的相关基本概念 1.数据块 1.在HDFS中,文件诶切分成固定大小的数据块,默认大小为64MB(hadoop2.x以后是128M),也可以自己配置. 2.为何数据块如此大,因为数据传输时间 ...
随机推荐
- 为什么 PCB 生产时推荐出 Gerber 给工厂?
为什么 PCB 生产时推荐出 Gerber 给工厂? 事情是这样的,有一天电工王工,画了一块 PCB,发给 PCB 板厂. 过了几天 PCB 回来了,一看不对呀,这里的丝印怎么少了,那里怎么多了几条线 ...
- trac
F:\Python27>python F:\portabletrac\ez_setup.pyDownloading https://pypi.io/packages/source/s/setup ...
- webpack 打包产生的文件名中,hash、chunkhash、contenthash 的区别
table th:first-of-type { width: 90px; } hash 类型 区别 hash 每一次打包都会生成一个唯一的 hash chunkhash 根据每个 chunk 的内容 ...
- 定时任务的N种解决方案
1, java 有个延时任务接口 DelayQueue 实现这个接口可以做到延时队列 缺点:耗费资源,不持久( java程序重启后丢失 ), 2. 基于spring 定时任务. 缺点:定时执行,不能 ...
- split与re.split/捕获分组和非捕获分组/startswith和endswith和fnmatch/finditer 笔记
split()对字符串进行划分: >>> a = 'a b c d' >>> a.split(' ') ['a', 'b', 'c', 'd'] 复杂一些可以使用r ...
- redis 如何查看所有的key
可以使用KEYS 命令 KEYS pattern 例如, 列出所有的key redis> keys * 列出匹配的key redis>keys apple* 1) apple1 2) ap ...
- MySQL程序只mysqlbinlog详解
mysqlbinlog命令详解 mysqlbinlog用于处理二进制的日志文件,如果想要查看这些日志文件的文本内容,就需要使用mysqlbinlog工具 用法: mysqlbinlog [option ...
- 关于SQL Server 无法生成 FRunCM 线程(不完全)
在五一的前一天,准备启动数据库完成我剩下的项目代码时,数据库配置管理器出现了一个让人蛋疼的问题sqlserv配置管理器出现请求失败或服务器未及时响应关于这个问题的处理方法,经过我两个小时的百度,网上对 ...
- linux 服务器之间配置免密登录
客户机:172.16.1.2 远程机:172.16.1.3 1.远程机 a.允许root用户通过22端口登录 vi /etc/ssh/sshd_config PORT 22 PermitRootLog ...
- Java ArrayList排序方法详解
由于其功能性和灵活性,ArrayList是 Java 集合框架中使用最为普遍的集合类之一.ArrayList 是一种 List 实现,它的内部用一个动态数组来存储元素,因此 ArrayList 能够在 ...