GoogLeNetv3 论文研读笔记
Rethinking the Inception Architecture for Computer Vision
摘要
卷积网络是目前最新的计算机视觉解决方案的核心,对于大多数任务而言,虽然增加的模型大小和计算成本都趋向于转化为直接的质量收益(只要提供足够的标注数据去训练),但计算效率和低参数计数仍是各种应用场景的限制因素。目前,我们正在探索增大网络的方法,目标是通过适当的分解卷积和积极的正则化来尽可能地有效利用增加的计算
引言
深度卷积架构上的架构改进可以用来改善大多数越来越多地依赖于高质量、可学习视觉特征的其它计算机视觉任务的性能。尽管VGGNet具有架构简洁的强有力特性,但它的成本很高:评估网络需要大量的计算。另一方面,GoogLeNet的Inception架构也被设计为在内存和计算预算严格限制的情况下也能表现良好。Inception的计算成本也远低于VGGNet或其更高性能的后继者。这使得可以在大数据场景中,在大量数据需要以合理成本处理的情况下或在内存或计算能力固有地受限情况下,利用Inception网络变得可行。然而,Inception架构的复杂性使得更难以对网络进行更改。如果单纯地放大架构,大部分的计算收益可能会立即丢失。在本文中,我们从描述一些一般原则和优化思想开始,对于以有效的方式扩展卷积网络来说,这被证实是有用的
通用设计原则
避免表示瓶颈,尤其是在网络的前面
前馈网络可以由从输入层到分类器或回归器的非循环图表示。这为信息流定义了一个明确的方向。对于分离输入输出的任何切口,可以访问通过切口的信息量。应该避免极端压缩的瓶颈。一般来说,在达到用于着手任务的最终表示之前,表示大小应该从输入到输出缓慢减小。理论上,信息内容不能仅通过表示的维度来评估,因为它丢弃了诸如相关结构的重要因素;维度仅提供信息内容的粗略估计
高维度特征在网络局部处理更加容易
在卷积网络中增加每个图块的激活允许更多解耦的特征,所产生的网络将训练更快
空间聚合可以在较低维度嵌入上完成,而不会在表示能力上造成过多损失
例如,在执行更多展开(例如3×3)卷积之前,可以在空间聚合之前减小输入表示的维度,没有预期的严重不利影响。我们假设,如果在空间聚合上下文中使用输出,则相邻单元之间的强相关性会导致维度缩减期间的信息损失少得多。鉴于这些信号应该易于压缩,因此尺寸减小甚至会促进更快的学习
平衡网络的宽度和深度
通过平衡每个阶段的滤波器数量和网络的深度可以达到网络的最佳性能。增加网络的宽度和深度可以有助于更高质量的网络。然而,如果两者并行增加,则可以达到恒定计算量的最佳改进。因此,计算预算应该在网络的深度和宽度之间以平衡方式进行分配
基于大滤波器尺寸分解卷积
GoogLeNet网络的大部分初始收益来源于大量地使用降维。这可以被视为以计算有效的方式分解卷积的特例。例如1x1卷积层后跟着3x3卷积层。在网络角度看,激活层的输出是高相关的;因此在聚合前进行降维,可以得到类似的局部表示性能
因为Inception结构是全卷积,每一个激活值对应的每一个权重,都对应一个乘法运算。因此减小计算量意味着减少参数。所以通过解耦和参数,可以加快训练。利用节省下来的计算和内存来增加我们网络的滤波器组的大小,同时保持我们在单个计算机上训练每个模型副本的能力
分解为更小的卷积
大的卷积计算量更大,具有较大空间滤波器(例如5×5或7×7)的卷积在计算方面往往不成比例的昂贵,而且可以使用较小的卷积核叠加来获得与较大卷积核相同的视野,并且同时还能获得更好的非线性特性,如下,叠加3*3卷积核获得与5*5卷积核相同的视野,但是使用的参数却更少
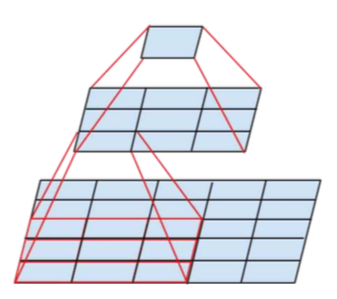
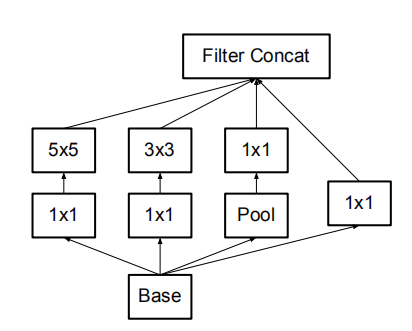
原来的Inception结构
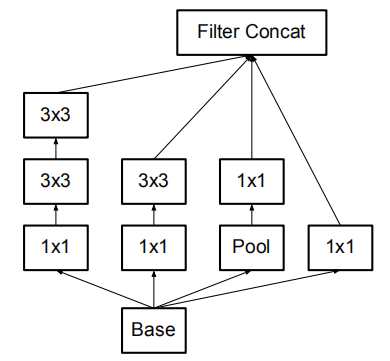
使用2个3x3替换5x5后的Inception结构(figure 5)
通过使用3*3的卷积核替换5*5的卷积核,最终得到一个计算量减少到\(\frac {9+9}{25}\)的网络
不过,这个设置提出了两个一般性的问题:这种替换是否会导致任何表征力的丧失?如果我们的主要目标是对计算的线性部分进行分解,是不是建议在第一层保持线性激活?实验证明,在分解的所有阶段中使用线性激活总是逊于使用修正线性单元。研究者将这个收益归因于网络可以学习的增强的空间变化
空间分解为不对称卷积
上述结果表明,大于3×3的卷积滤波器可能不是通常有用的,因为它们总是可以简化为3×3卷积层序列。我们仍然可以问这个问题,是否应该把它们分解成更小的,例如2×2的卷积。然而,通过使用非对称卷积,可以做出甚至比2×2更好的效果,即n×1。例如使用3×1卷积后接一个1×3卷积,相当于以与3×3卷积相同的感受野滑动两层网络

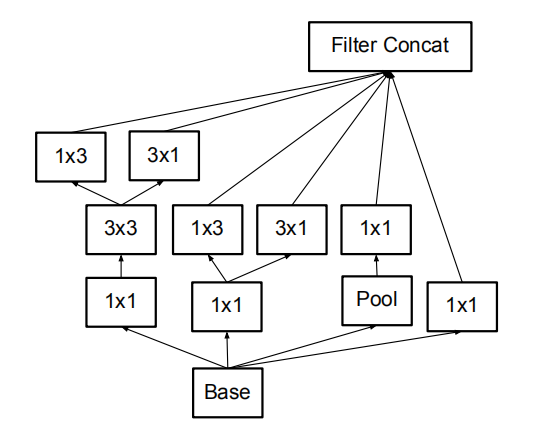
在理论上,可以进一步论证,可以通过1×n卷积和后面接一个n×1卷积替换任何n×n卷积,并且随着n增长,计算成本节省显著增加
n×n卷积分解后的Inception模块(figure 6)

利用辅助分类器
引入辅助分类器的概念,是为了改善非常深的网络的收敛。最初的动机是将有用的梯度推向较低层,使其立即有用,并通过抵抗非常深的网络中的消失梯度问题来提高训练过程中的收敛。但是,研究人员发现辅助分类器在训练早期并没有改善收敛:在两个模型达到高精度之前,有无侧边网络的训练进度看起来几乎相同;接近训练结束,辅助分支网络开始超越没有任何分支的网络的准确性,达到了更高的稳定水平
研究者认为辅助分类器起着正则化项的作用。这是由于如果侧分支是批标准化的或具有丢弃层,则网络的主分类器性能更好。这也为推测批标准化作为正则化项给出了一个弱支持证据
有效的网格尺寸减少
传统上,卷积网络使用一些池化操作来缩减特征图的网格大小。为了避免表示瓶颈,在应用最大池化或平均池化之前,需要扩展网络滤波器的激活维度。开始有一个带有k个滤波器的d×d网格,如果我们想要达到一个带有2k个滤波器的\(\frac{d}{2}×\frac{d}{2}\)网格,我们首先需要用2k个滤波器计算步长为1的卷积,然后应用一个额外的池化步骤。这样虽然能够将计算量降低为原来的四分之一,但是因为表示的整体维度下降到\((\frac {d}{2})^2k\),会导致网络的表示能力较弱,在此,作者建议另一种变体,不仅进一步降低了计算成本,同时消除了表示瓶颈,即使用两个平行的步长为2的块:P和C。P是一个池化层(平均池化或最大池化)的激活,两者都是步长为2
前一种变化
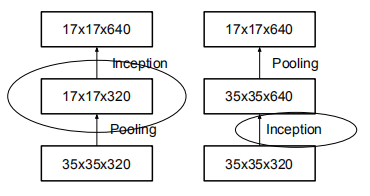
建议的变体

Inception-v2
在这里,连接上面的点,并提出了一个新的架构
网络布局
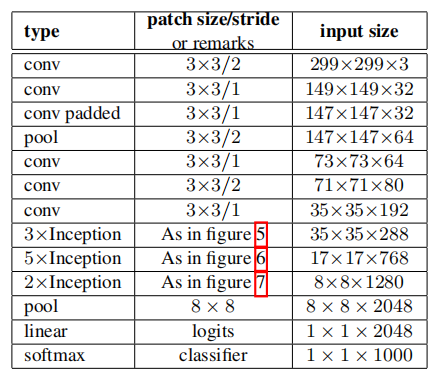
把7x7卷积替换为3个3x3卷积。包含3个Inception部分。第一部分是35x35x288,使用了2个3x3卷积代替了传统的5x5;第二部分减小了feature map,增多了filters,为17x17x768,使用了nx1->1xn结构;第三部分增多了filter,使用了卷积池化并行结构。网络有42层,但是计算量只有GoogLeNet的2.5倍
figure 7具有扩展的滤波器组输出的Inception模块。这种架构被用于最粗糙的(8×8)网格,以提升高维表示。仅在最粗的网格上使用了此解决方案,因为这是产生高维度的地方,稀疏表示是最重要的,因为与空间聚合相比,局部处理(1×1 卷积)的比率增加
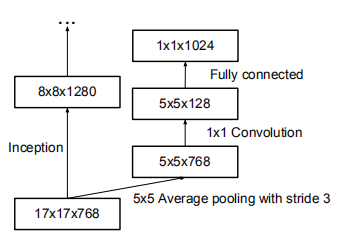
最后17×17层之上的辅助分类器
通过标签平滑进行模型正则化
研究者提出了一种通过估计训练期间标签丢弃的边缘化效应来对分类器层进行正则化的机制
对于每个训练样本\(x\),我们的模型计算每个标签的概率 \(k \in \begin{Bmatrix}1...K\end{Bmatrix}: p(k|x) = \frac{exp(z_k)}{\sum_{i=1}^k exp(z_i)}\)。这里\(z_i\)是对数单位或未归一化的对数概率。为了简洁,省略\(p\)和\(q\)对样本\(x\)的依赖。将样本损失定义为交叉熵:\(ℓ = -\sum_{k=1}^K log(p(k))q(k)\)。最小化交叉熵等价于最大化标签对数似然期望,其中标签是根据它的实际分布\(q(k)\)选择的。如果对应实际标签的逻辑单元远大于其它的逻辑单元,那么对数概率会接近最大值。然而这可能会引起两个问题。首先,它可能导致过拟合:如果模型学习到对于每一个训练样本,分配所有概率到实际标签上,那么它不能保证泛化能力。第二,它鼓励最大的逻辑单元与所有其它逻辑单元之间的差距变大,与有界限的梯度\(\frac {∂ℓ}{∂_{z_k}}\)相结合这会降低模型的适应能力。直观上讲这会发生,因为模型变得对它的预测过于自信
研究者因此提出了一个鼓励模型不那么自信的机制这个方法很简单。考虑标签\(u(k)\)的分布和平滑参数\(ϵ\),与训练样本\(x\)相互独立。对于一个真实标签为\(y\)的训练样本,使用
\[
q′(k|x)=(1−ϵ)δ_{k,y}+ϵu(k)
\]
代替标签分布\(q(k|x)=δ_{k,y}\)。这可以看作获得标签k的分布如下:首先,将其设置为真实标签\(k=y\);其次,用分布\(u(k)\)中的采样和概率\(ϵ\)替代\(k\)。建议使用标签上的先验分布作为\(u(k)\)。在实验中,使用了均匀分布\(u(k)=1/K\),以便使得
\[
q′(k)=(1−ϵ)δ_{k,y}+\frac {ϵ}{K}
\]
将真实标签分布中的这种变化称为标签平滑正则化,或LSR。LSR实现了期望的目标,阻止了最大的逻辑单元变得比其它的逻辑单元更大。实际上,如果发生这种情况,则一个\(q(k)\)将接近1,而所有其它的将会接近0。这会导致\(q′(k)\)有一个大的交叉熵,因为不同于\(q(k)=δ_{k,y}\),所有的\(q′(k)\)都有一个正的下界
LSR等价于用一对这样的损失\(H(q,p)\)和\(H(u,p)\)来替换单个交叉熵损失\(H(q,p)\)。第二个损失惩罚预测的标签分布\(p\)与先验\(u\)之间的偏差,其中相对权重为\(\frac {ϵ}{1−ϵ}\),这个偏差可以等价地被KL散度捕获。当\(u\)是均匀分布时,\(H(u,p)\)是度量预测分布\(p\)与均匀分布不同的程度
结论
本研究提供了几个设计原则来扩展卷积网络,并在Inception体系结构的背景下进行研究。这个指导可以造就高性能的视觉网络,与更简单、更单一的体系结构相比,它具有相对适中的计算成本。
总结
文章提出了四个深度网络设计指导原则,并将该原则应用于改进网络
网络的改进方法
- 把大的卷积层分解为小的卷积层,提高计算效率
- 将卷积层进行非对称分解
- 发现辅助分类器在早期并不能加快网络的训练,只会在最后的时候提高一点性能
- 提出了有效的减小网格尺寸的方法
- 提出了LSR
参考文章
Rethinking the inception architecture for computer vision的 paper 相关知识
GoogLeNetv1 论文研读笔记
GoogLeNetv2 论文研读笔记
GoogLeNetv4 论文研读笔记
GoogLeNetv3 论文研读笔记的更多相关文章
- GoogLeNetv4 论文研读笔记
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning 原文链接 摘要 向传统体系结构中引入 ...
- GoogLeNetv2 论文研读笔记
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift 原文链接 摘要 ...
- GoogLeNetv1 论文研读笔记
Going deeper with convolutions 原文链接 摘要 研究提出了一个名为"Inception"的深度卷积神经网结构,其目标是将分类.识别ILSVRC14数据 ...
- ResNet 论文研读笔记
Deep Residual Learning for Image Recognition 原文链接 摘要 深度神经网络很难去训练,本文提出了一个残差学习框架来简化那些非常深的网络的训练,该框架使得层能 ...
- < AlexNet - 论文研读个人笔记 >
Alexnet - 论文研读个人笔记 一.论文架构 摘要: 简要说明了获得成绩.网络架构.技巧特点 1.introduction 领域方向概述 前人模型成绩 本文具体贡献 2.The Dataset ...
- 《DSLR-Quality Photos on Mobile Devices with Deep Convolutional Networks》研读笔记
<DSLR-Quality Photos on Mobile Devices with Deep Convolutional Networks>研读笔记 论文标题:DSLR-Quality ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
随机推荐
- 《mysql必知必会》学习_第11章_20180801_欢
第11章:使用数据处理函数. P69 文本处理函数,upper()函数把文本变成大写字体. select vend_name,upper(vend_name) as vend_name_upcase ...
- java 堆排序的实现
堆就是一个完全二叉树,堆要求是指 该节点大于它的两个子节点.而两个字节点大小不一定. 堆排序的最坏时间复杂度为nlog(n),平均也为nlog(n),占用空间为o(1),是一种比较排序算法. 堆排序也 ...
- Linux分区之parted命令
之前使用最多的分区命令无疑是fdisk了,大多数情况下fdisk可以满足日常工作上的需求,极个别情况就需要使用parted命令了,至于及个别情况就要从MBR和GPT说起. MBR主引导扇区 主 ...
- Django:model中的ForeignKey理解
有两个数据模型栏目模型和文章模型ArticleColumn和ArticlePost ArticleColumn: class ArticleColumn(models.Model): # 用户与栏目是 ...
- .net core 与ELK(1)安装Elasticsearch
1.安装java jdk [elsearch@localhost bin]$ java -version openjdk version "1.8.0_181" OpenJDK R ...
- 用WPF写一个登录界面,我想在输入完密码后按回车就能够验证登陆,而不需要用鼠标单击登陆按钮
在wpf中,将按钮的IsDefault设置为true
- Spring Cloud实践之集中配置Spring-config
将一个系统中各个应用的配置文件集中起来,方便管理. import org.springframework.boot.SpringApplication; import org.springframew ...
- Mongodb-- python中使用pymongo连接mongodb数据库
一.使用 通过pip或者pychrm下载pymongo模块 import json from pymongo import MongoClient from bson import ObjectId ...
- 配置kali linux
在7月底的时候,安全加介绍Fireeye出品的 免费恶意软件分析工具FlareVM,还可进行逆向工程和渗透测试 .今天是看到绿盟科技的一篇介绍Kali Linux配置的文章,这个工具也进入了 渗透测试 ...
- 《Python自动化运维之路》 业务服务监控(二)
文件内容差异对比方法 使用diffie模块实现文件内容差异对比.dmib作为 Python的标准库模块,无需安装,作用是对比文本之间的差异,且支持输出可读性比较强的HTML文档,与 Linux下的di ...