Java对epub电子书类型切割
Epub电子书切割
引言:由于公司存储电子书的格式是.epub。一本电子书加载的时候,如果电子书大的话,全部加载该电子书会非常的消耗时间和资源。非常的不合理。那么现在,将所有电子书按章切分。将拆分的电子书再上传至服务器,用户点击阅读电子书任何一章节,就加载该章节的数据。这里的具体逻辑不细写,主要细写如果切割电子书的过程。
准备
这里我用到了Epublib这个jar包,详细资料参考下方
maven库搜索 epublib-core ,kxml2
pom文件引入依赖
<!-- https://mvnrepository.com/artifact/nl.siegmann.epublib/epublib-core -->
<dependency>
<groupId>nl.siegmann.epublib</groupId>
<artifactId>epublib-core</artifactId>
<version>3.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/net.sf.kxml/kxml2 -->
<dependency>
<groupId>net.sf.kxml</groupId>
<artifactId>kxml2</artifactId>
<version>2.3.0</version>
</dependency>
分析
epub电子书结构
.epub电子书是怎么的结构。我这边下载了一本。我用winrar解压看下。如下图
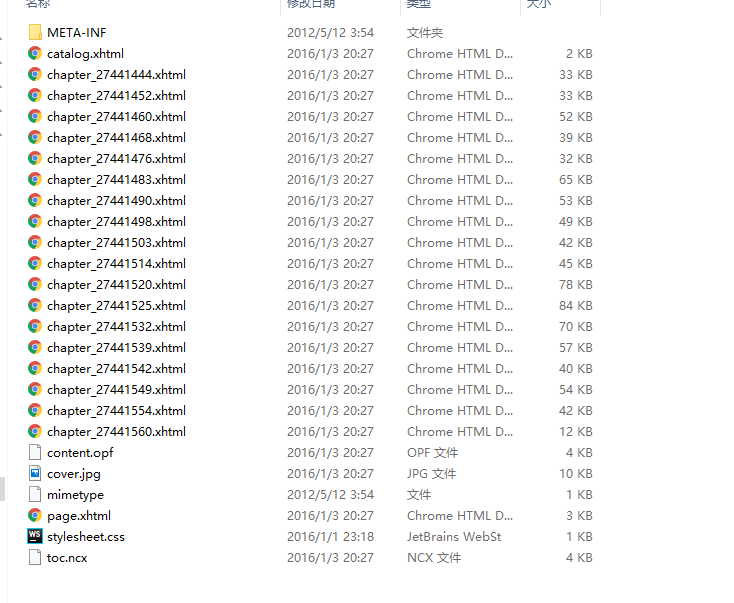
可以很清楚看见是由xhtml文件组成资源。关于content.opf ,toc.nxc等这些本来就是属于电子书的数据结构文件,可以自行网上查阅。
epublib中book数据结构
epub电子书抽象成epublib中的book 。epublib 中book的数据结构是怎么样子的呢,这里稍微介绍一下,网上确实资料太少了。
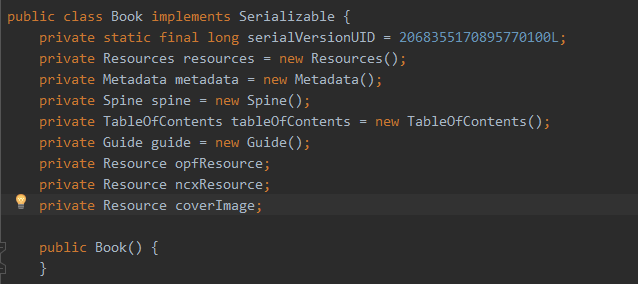
Resource数据结构
Resources类中又有一个HashMap,HashMap中的value为Resource,Resource的数据结构如下:
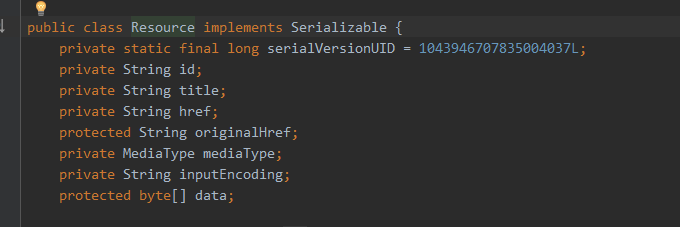
- id,href相当于Resources中那个HashMap中的key,可以找到Resource
- title 和 originalHref 表资源的名字和起始的href
- mediaType 资源的数据类型 inputEncoding 编码格式
- data 第一张图片上的.xhtml转string类型,然后再转成字节流的数据
Metadata
Book里的Metadata相当于电子书的头部,可以获取电子书的基本数据,数据结构如下:

Spine
Book中的骨架结构,用来链接Book资源文件,数据结构如下
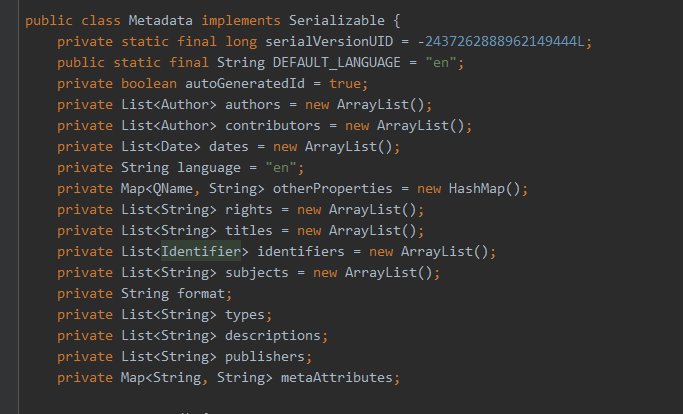
Resource 与ResourceReference 为关联,SpineReference是ResourceReference的父类。
在设置好Resouces后一定要设置相应的Spine中的Resouce,不然电子书打开,会无法识别。
TableOfContents
Book中目录对应的数据结构。有目录的名字,目录对应的Resource,对应的数据结构如下:

实战
Demo代码如下:
/**
* @Description: 按章节切分 电子书
* @Author: ouyangkang
* @CreateDate: 2018/9/28 17:41
* @Param [url]
*/
public static void segmentation(String url){
try {
// 获取网络资源
URL urlResource = new URL(url) ;
// 打开链接
HttpURLConnection conn = (HttpURLConnection) urlResource.openConnection();
// 建立链接
conn.connect();
// 读取电子书流
EpubReader epubReader = new EpubReader();
// 获取电子书
InputStream inputStream = conn.getInputStream();
if (inputStream == null){
return;
}
if (epubReader == null){
return;
}
Book book = epubReader.readEpub(inputStream);
if (book == null){
return;
}
// 获取电子书目录
TableOfContents tableOfContents = book.getTableOfContents();
// 电子书章节封装资源
List<SpineReference> spineReferences = book.getSpine().getSpineReferences();
// 电子书 章节Id 集合
List<String> resourceIds = new ArrayList<>(16);
// 获取所有资源href
Set<String> hrefs = (Set<String>) book.getResources().getAllHrefs();
// css 资源文件
List<String> hrefCss = new ArrayList<>();
hrefs.stream().forEach(href -> {
if (href.contains(".css")){
hrefCss.add(href);
}
});
spineReferences.stream().forEach(spineReference -> {
// 获取章节Id
resourceIds.add(spineReference.getResourceId());
});
// 电子书章节资源
Resources resources = new Resources();
// 写入电子书
EpubWriter epubWriter = new EpubWriter();
resourceIds.stream().forEach(resourceId -> {
// 电子书章节
Book bookChapter = new Book();
//章节导航
Spine spine = new Spine();
if (hrefCss.size() > 0){
hrefCss.stream().forEach(href -> {
resources.add(book.getResources().getByHref(href));
});
}
nl.siegmann.epublib.domain.Resource resource = book.getResources().getById(resourceId);
resources.add(resource);
// 获取图片资源
try {
String imageData = new String(resource.getData(),"UTF-8");
// 获取图片源
List<String> imagesHrefs = getImgSrc(imageData);
//添加该章节下的图片资源
imagesHrefs.stream().forEach(imagesHref -> {
nl.siegmann.epublib.domain.Resource resourceImage = book.getResources().getByHref(imagesHref);
resources.add(resourceImage);
});
//设置电子书资源
// 设置电子书导航文件
nl.siegmann.epublib.domain.Resource tocResource = book.getResources().getById("ncx");
if (tocResource != null){
// 发现有的电子书并不存在 toc.ncx 而是以一种toc.xhtml的文件存在
if (tocResource.getHref().contains("toc.ncx")) {
spine.setTocResource(tocResource);
} else {
resources.add(tocResource);
}
}
//添加章节资源
bookChapter.setResources(resources);
// 添加该章节骨架
spine.addSpineReference(new SpineReference(book.getResources().getById(resourceId)));
bookChapter.setSpine(spine);
// 添加该书的所有目录
bookChapter.setTableOfContents(tableOfContents);
//文件写入地址
String path = "D:\\ebook\\"+resourceId+".epub";
File file = new File(path);
if (!file.getParentFile().exists()){
file.getParentFile().mkdir();
}
epubWriter.write(bookChapter, new FileOutputStream(file));
} catch (IOException e) {
e.printStackTrace();
}finally {
conn.disconnect();
}
});
}catch (Exception e){
e.printStackTrace();
}
}
/**
* 获取img标签中的src值
* @param content
* @return
*/
public static List<String> getImgSrc(String content){
List<String> list = new ArrayList<String>();
//目前img标签标示有3种表达式
//<img alt="" src="1.jpg"/> <img alt="" src="1.jpg"></img> <img alt="" src="1.jpg">
//开始匹配content中的<img />标签
Pattern p_img = Pattern.compile("<(img|IMG|image|IMAGE)(.*?)(/>|></img>|>|></image)");
Matcher m_img = p_img.matcher(content);
boolean result_img = m_img.find();
if (result_img) {
while (result_img) {
//获取到匹配的<img />标签中的内容
String str_img = m_img.group(2);
//开始匹配<img />标签中的src
Pattern p_src = Pattern.compile("(src|SRC|href|HREF)=(\"|\')(.*?)(\"|\')");
Matcher m_src = p_src.matcher(str_img);
if (m_src.find()) {
String str_src = m_src.group(3);
if (str_src.contains("Image")){
str_src = str_src.substring(str_src.indexOf("I"),str_src.length());
}else {
str_src = str_src.substring(str_src.indexOf("i"),str_src.length());
}
list.add(str_src);
}
//结束匹配<img />标签中的src
//匹配content中是否存在下一个<img />标签,有则继续以上步骤匹配<img />标签中的src
result_img = m_img.find();
}
}
return list;
}
Java对epub电子书类型切割的更多相关文章
- Java 解析epub格式电子书,helloWorld程序,附带源程序和相关jar包
秀才坤坤出品 一.epub格式电子书 相关材料和源码均在链接中可以下载:http://pan.baidu.com/s/1bnm8YXT 包括 1.JAVA项目工程test_epub,里面包括了jar包 ...
- epub电子书--目录结构介绍
epub电子书简介 epub全称为Electronic Publication的缩写,意为:电子出版, epub于2007年9月成为国际数位出版论坛(IDPF)的正式标准,以取代旧的开放Open eB ...
- java中,字符串类型的时间数据怎样转换成date类型。
将字符串类型的时间转换成date类型可以使用SimpleDateFormat来转换,具体方法如下:1.定义一个字符串类型的时间:2.创建一个SimpleDateFormat对象并设置格式:3.最后使用 ...
- [原创开源项目]EPUBBuilder一款在线的epub电子书编辑工具
epub 感觉自己么么哒, epub书:国外最流行的电子书格式: epub电子书介绍: epub全称为Electronic Publication的缩写,意为:电子出版, epub于2007年9月成为 ...
- 详解Java 8中Stream类型的“懒”加载
在进入正题之前,我们需要先引入Java 8中Stream类型的两个很重要的操作: 中间和终结操作(Intermediate and Terminal Operation) Stream类型有两种类型的 ...
- Java笔记10-Object包装类型字符串
提纲: 1.java.lang.0bject中常用方法介绍 2.基本类型对应的包装类型的介绍 以及基本类型和包装类型之间的相互转换 3.java.lang.String 字符串处理类 java.lan ...
- Java中的Bigdecimal类型运算
Java中的Bigdecimal类型运算 双精度浮点型变量double可以处理16位有效数.在实际应用中,需要对更大或者更小的数进行运算和处理.Java在java.math包中提 供的API类BigD ...
- java获取获得Timestamp类型的当前系统时间。以及java.util.date 、java.sql.Date之间的转换
java获取取得Timestamp类型的当前系统时间java获取取得Timestamp类型的当前系统时间 格式:2010-11-04 16:19:42 方法1: Timestamp d = new T ...
- Java Hour 50 日期类型
Plan List: 1 Java 中的日期类型 2 mysql 相关 3 java code style 鉴于本问题太过普通,所以参考文章满大街都是,因此本文内容基本为转载和验证. java.sql ...
随机推荐
- Python基础学习(二)
前一段时间学习了Python数据类型,语句和函数,目前书写python的新特性,继续练手!!!! 一.切片 之前我们从python的list 或者 tuple中取得元素都是这样写,显然不够灵活 lis ...
- 样本服从正态分布,证明样本容量n乘样本方差与总体方差之比服从卡方分布x^2(n)
样本服从正态分布,证明样本容量n乘样本方差与总体方差之比服从卡方分布x^2(n) 正态分布的n阶中心矩参见: http://www.doc88.com/p-334742692198.html
- php-fpm的status可以查看汇总信息和详细信息
nginx.conf 配置文件 server { listen ; server_name localhost; index index.php index.html; root /home/tiny ...
- 深入分析Java Web技术内幕
深入web请求过程 发起一个http请求的过程就是建立一个socket通信的过程 HTTPClient是一个开源的实现了http请求的工具包 深入分析java I/O的工作机制 深入分析java We ...
- XMPP 基础
CHENYILONG Blog XMPP 基础 技术博客http://www.cnblogs.com/ChenYilong/ 新浪微博http://weibo.com/luohanchenyilong ...
- Spring Boot 多模块项目创建与配置 (一)
最近在负责的是一个比较复杂项目,模块很多,代码中的二级模块就有9个,部分二级模块下面还分了多个模块.代码中的多模块是用maven管理的,每个模块都使用spring boot框架.之前有零零散散学过一些 ...
- 2017/05/17 java 基础 随笔
- jquery.validate动态更改校验规则
有时候表单中有多个字段是相互关联的,以下遇到的就是证件类型和证件号码的关联,在下拉框中选择不同的证件类型,证件号码的值的格式都是不同的,这就需要动态的改变校验规则. 点击(此处)折叠或打开 <! ...
- 08 Go 1.8 Release Notes
Go 1.8 Release Notes Introduction to Go 1.8 Changes to the language Ports Known Issues Tools Assembl ...
- Python 3之str类型、string模块学习笔记
Windows 10家庭中文版,Python 3.6.4, Python 3.7官文: Text Sequence Type — str string — Common string operatio ...