Kubernetes学习之路(二十一)之网络模型和网络策略
Kubernetes的网络模型和网络策略
1、Kubernetes网络模型和CNI插件
在Kubernetes中设计了一种网络模型,要求无论容器运行在集群中的哪个节点,所有容器都能通过一个扁平的网络平面进行通信,即在同一IP网络中。需要注意的是:在K8S集群中,IP地址分配是以Pod对象为单位,而非容器,同一Pod内的所有容器共享同一网络名称空间。
1.1、Docker网络模型
了解Docker的友友们都应该清楚,Docker容器的原生网络模型主要有3种:Bridge(桥接)、Host(主机)、none。
- Bridge:借助虚拟网桥设备为容器建立网络连接。
- Host:设置容器直接共享当前节点主机的网络名称空间。
- none:多个容器共享同一个网络名称空间。
#使用以下命令查看docker原生的三种网络
[root@localhost ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
0efec019c899 bridge bridge local
40add8bb5f07 host host local
ad94f0b1cca6 none null local
#none网络,在该网络下的容器仅有lo网卡,属于封闭式网络,通常用于对安全性要求较高并且不需要联网的应用
[root@localhost ~]# docker run -it --network=none busybox
/ # ifconfig
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
#host网络,共享宿主机的网络名称空间,容器网络配置和host一致,但是存在端口冲突的问题
[root@localhost ~]# docker run -it --network=host busybox
/ # ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast qlen 1000
link/ether 00:0c:29:69:a7:23 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.4/24 brd 192.168.1.255 scope global dynamic eth0
valid_lft 84129sec preferred_lft 84129sec
inet6 fe80::20c:29ff:fe69:a723/64 scope link
valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue
link/ether 02:42:29:09:8f:dd brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:29ff:fe09:8fdd/64 scope link
valid_lft forever preferred_lft forever
/ # hostname
localhost
#bridge网络,Docker安装完成时会创建一个名为docker0的linux bridge,不指定网络时,创建的网络默认为桥接网络,都会桥接到docker0上。
[root@localhost ~]# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.024229098fdd no
[root@localhost ~]# docker run -d nginx #运行一个nginx容器
c760a1b6c9891c02c992972d10a99639d4816c4160d633f1c5076292855bbf2b
[root@localhost ~]# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.024229098fdd no veth3f1b114
一个新的网络接口veth3f1b114桥接到了docker0上,veth3f1b114就是新创建的容器的虚拟网卡。进入容器查看其网络配置:
[root@localhost ~]# docker exec -it c760a1b6c98 bash
root@c760a1b6c989:/# apt-get update
root@c760a1b6c989:/# apt-get iproute
root@c760a1b6c989:/# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
38: eth0@if39: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
从上可以看到容器内有一个网卡eth0@if39,实际上eth0@if39和veth3f1b114是一对veth pair。veth pair是一种成对出现的特殊网络设备,可以想象它们由一根虚拟的网线进行连接的一对网卡,eth0@if39在容器中,veth3f1b114挂在网桥docker0上,最终的效果就是eth0@if39也挂在了docker0上。
桥接式网络是目前较为流行和默认的解决方案。但是这种方案的弊端是无法跨主机通信的,仅能在宿主机本地进行,而解决该问题的方法就是NAT。所有接入到该桥接设备上的容器都会被NAT隐藏,它们发往Docker主机外部的所有流量都会经过源地址转换后发出,并且默认是无法直接接受节点之外的其他主机发来的请求。当需要接入Docker主机外部流量,就需要进行目标地址转换甚至端口转换将其暴露在外部网络当中。如下图:
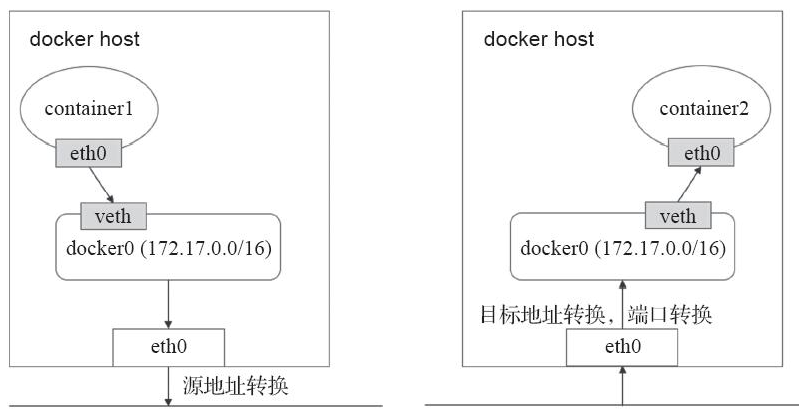
容器内的属于私有地址,需要在左侧的主机上的eth0上进行源地址转换,而右侧的地址需要被访问,就需要将eth0的地址进行NAT转换。SNAT---->DNAT
这样的通信方式会比较麻烦,从而需要借助第三方的网络插件实现这样的跨主机通信的网络策略。
1.2、Kubernetes网络模型
我们知道的是,在K8S上的网络通信包含以下几类:
容器间的通信:同一个Pod内的多个容器间的通信,它们之间通过lo网卡进行通信。
Pod之间的通信:通过Pod IP地址进行通信。
Pod和Service之间的通信:Pod IP地址和Service IP进行通信,两者并不属于同一网络,实现方式是通过IPVS或iptables规则转发。
Service和集群外部客户端的通信,实现方式:Ingress、NodePort、Loadbalance
K8S网络的实现不是集群内部自己实现,而是依赖于第三方网络插件----CNI(Container Network Interface)
flannel、calico、canel等是目前比较流行的第三方网络插件。
这三种的网络插件需要实现Pod网络方案的方式通常有以下几种:
虚拟网桥、多路复用(MacVLAN)、硬件交换(SR-IOV)
无论是上面的哪种方式在容器当中实现,都需要大量的操作步骤,而K8S支持CNI插件进行编排网络,以实现Pod和集群网络管理功能的自动化。每次Pod被初始化或删除,kubelet都会调用默认的CNI插件去创建一个虚拟设备接口附加到相关的底层网络,为Pod去配置IP地址、路由信息并映射到Pod对象的网络名称空间。
在配置Pod网络时,kubelet会在默认的/etc/cni/net.d/目录中去查找CNI JSON配置文件,然后通过type属性到/opt/cni/bin中查找相关的插件二进制文件,如下面的"portmap"。然后CNI插件调用IPAM插件(IP地址管理插件)来配置每个接口的IP地址:
[root@k8s-master ~]# cat /etc/cni/net.d/10-flannel.conflist
{
"name": "cbr0",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
kubelet调用第三方插件,进行网络地址的分配
CNI主要是定义容器网络模型规范,链接容器管理系统和网络插件,两者主要通过上面的JSON格式文件进行通信,实现容器的网络功能。CNI的主要核心是:在创建容器时,先创建好网络名称空间(netns),然后调用CNI插件为这个netns配置网络,最后在启动容器内的进程。
常见的CNI网络插件包含以下几种:
- Flannel:为Kubernetes提供叠加网络的网络插件,基于TUN/TAP隧道技术,使用UDP封装IP报文进行创建叠 加网络,借助etcd维护网络的分配情况,缺点:无法支持网络策略访问控制。
- Calico:基于BGP的三层网络插件,也支持网络策略进而实现网络的访问控制;它在每台主机上都运行一个虚拟路由,利用Linux内核转发网络数据包,并借助iptables实现防火墙功能。实际上Calico最后的实现就是将每台主机都变成了一台路由器,将各个网络进行连接起来,实现跨主机通信的功能。
- Canal:由Flannel和Calico联合发布的一个统一网络插件,提供CNI网络插件,并支持网络策略实现。
- 其他的还包括Weave Net、Contiv、OpenContrail、Romana、NSX-T、kube-router等等。而Flannel和Calico是目前最流行的选择方案。
1.3、Flannel网络插件
在各节点上的Docker主机在docker0上默认使用同一个子网,不同节点的容器都有可能会获取到相同的地址,那么在跨节点通信时就会出现地址冲突的问题。并且在多个节点上的docker0使用不同的子网,也会因为没有准确的路由信息导致无法准确送达报文。
而为了解决这一问题,Flannel的解决办法是,预留一个使用网络,如10.244.0.0/16,然后自动为每个节点的Docker容器引擎分配一个子网,如10.244.1.0/24和10.244.2.0/24,并将分配信息保存在etcd持久存储。
第二个问题的解决,Flannel是采用不同类型的后端网络模型进行处理。其后端的类型有以下几种:
- VxLAN:使用内核中的VxLAN模块进行封装报文。也是flannel推荐的方式,其报文格式如下:

- host-gw:即Host GateWay,通过在节点上创建目标容器地址的路由直接完成报文转发,要求各节点必须在同一个2层网络,对报文转发性能要求较高的场景使用。
- UDP:使用普通的UDP报文封装完成隧道转发。
1.4、VxLAN后端和direct routing
VxLAN(Virtual extensible Local Area Network)虚拟可扩展局域网,采用MAC in UDP封装方式,具体的实现方式为:
- 1、将虚拟网络的数据帧添加到VxLAN首部,封装在物理网络的UDP报文中
- 2、以传统网络的通信方式传送该UDP报文
- 3、到达目的主机后,去掉物理网络报文的头部信息以及VxLAN首部,并交付给目的终端
跨节点的Pod之间的通信就是以上的一个过程,整个过程中通信双方对物理网络是没有感知的。如下网络图:
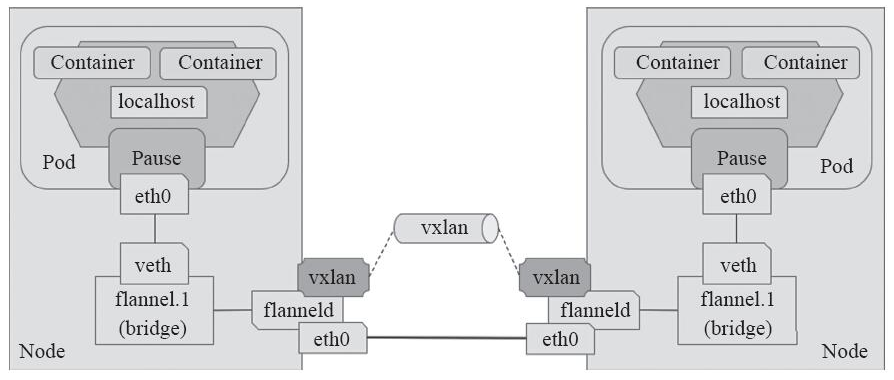
VxLAN的部署可以直接在官方上找到其YAML文件,如下:
[root@k8s-master:~# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/bc79dd1505b0c8681ece4de4c0d86c5cd2643275/Documentation/kube-flannel.yml
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.extensions/kube-flannel-ds-amd64 created
daemonset.extensions/kube-flannel-ds-arm64 created
daemonset.extensions/kube-flannel-ds-arm created
daemonset.extensions/kube-flannel-ds-ppc64le created
daemonset.extensions/kube-flannel-ds-s390x created
#输出如下结果表示flannel可以正常运行了
[root@k8s-master ~]# kubectl get daemonset -n kube-system
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
kube-flannel-ds 3 3 3 3 3 beta.kubernetes.io/arch=amd64 202d
kube-proxy 3 3 3 3 3 beta.kubernetes.io/arch=amd64 202d
运行正常后,flanneld会在宿主机的/etc/cni/net.d目录下生成自已的配置文件,kubelet将会调用它。
网络插件运行成功后,Node状态才Ready。
[root@k8s-master ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master Ready master 202d v1.11.2
k8s-node01 Ready <none> 202d v1.11.2
k8s-node02 Ready <none> 201d v1.11.2
flannel运行后,在各Node宿主机多了一个网络接口:
#master节点的flannel.1网络接口,其网段为:10.244.0.0
[root@k8s-master ~]# ifconfig flannel.1
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.0.0 netmask 255.255.255.255 broadcast 0.0.0.0
inet6 fe80::31:5dff:fe01:4bc0 prefixlen 64 scopeid 0x20<link>
ether 02:31:5d:01:4b:c0 txqueuelen 0 (Ethernet)
RX packets 1659239 bytes 151803796 (144.7 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 2115439 bytes 6859187242 (6.3 GiB)
TX errors 0 dropped 10 overruns 0 carrier 0 collisions 0
#node1节点的flannel.1网络接口,其网段为:10.244.1.0
[root@k8s-node01 ~]# ifconfig flannel.1
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.1.0 netmask 255.255.255.255 broadcast 0.0.0.0
inet6 fe80::2806:4ff:fe71:2253 prefixlen 64 scopeid 0x20<link>
ether 2a:06:04:71:22:53 txqueuelen 0 (Ethernet)
RX packets 136904 bytes 16191144 (15.4 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 180775 bytes 512637365 (488.8 MiB)
TX errors 0 dropped 8 overruns 0 carrier 0 collisions 0
#node2节点的flannel.1网络接口,其网段为:10.244.2.0
[root@k8s-node02 ~]# ifconfig flannel.1
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.2.0 netmask 255.255.255.255 broadcast 0.0.0.0
inet6 fe80::58b7:7aff:fe8d:2d prefixlen 64 scopeid 0x20<link>
ether 5a:b7:7a:8d:00:2d txqueuelen 0 (Ethernet)
RX packets 9847824 bytes 12463823121 (11.6 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 2108796 bytes 185073173 (176.4 MiB)
TX errors 0 dropped 13 overruns 0 carrier 0 collisions 0
从上面的结果可以知道 :
- flannel默认就是VXLAN模式,即Overlay Network。
- flanneld创建了一个flannel.1接口,它是专门用来封装隧道协议的,默认分给集群的Pod网段为10.244.0.0/16。
- flannel给k8s-master节点配置的Pod网络为10.244.0.0段,给k8s-node01节点配置的Pod网络为10.244.1.0段,给k8s-node01节点配置的Pod网络为10.244.2.0段,如果有更多的节点,以此类推。
举个实际例子
#启动一个nginx容器,副本为3
[root@k8s-master ~]# kubectl run nginx --image=nginx:1.14 --port=80 --replicas=3
deployment.apps/nginx created
#查看Pod
[root@k8s-master ~]# kubectl get pods -o wide |grep nginx
nginx-5bd76bcc4f-8s64s 1/1 Running 0 2m 10.244.2.85 k8s-node02
nginx-5bd76bcc4f-mr6k5 1/1 Running 0 2m 10.244.1.146 k8s-node01
nginx-5bd76bcc4f-pb257 1/1 Running 0 2m 10.244.0.17 k8s-master
可以看到,3个Pod都分别运行在各个节点之上,其中master上的Pod的ip为:10.244.0.17,在master节点上查看网络接口可以发现在各个节点上多了一个虚拟接口cni0,其ip地址为10.244.0.1。它是由flanneld创建的一个虚拟网桥叫cni0,在Pod本地通信使用。 这里需要注意的是,cni0虚拟网桥,仅作用于本地通信!!!!
[root@k8s-master ~]# ifconfig cni0
cni0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.0.1 netmask 255.255.255.0 broadcast 0.0.0.0
inet6 fe80::848a:beff:fe44:4959 prefixlen 64 scopeid 0x20<link>
ether 0a:58:0a:f4:00:01 txqueuelen 1000 (Ethernet)
RX packets 2772994 bytes 300522237 (286.6 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 3180562 bytes 928687288 (885.6 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
flanneld为每个Pod创建一对veth虚拟设备,一端放在容器接口上,一端放在cni0桥上。 使用brctl查看该网桥:
#可以看到有一veth的网络接口桥接在cni0网桥上
[root@k8s-master ~]# brctl show cni0
bridge name bridge id STP enabled interfaces
cni0 8000.0a580af40001 no veth020fafae
#宿主机ping测试访问Pod ip
[root@k8s-master ~]# ping 10.244.0.17
PING 10.244.0.17 (10.244.0.17) 56(84) bytes of data.
64 bytes from 10.244.0.17: icmp_seq=1 ttl=64 time=0.291 ms
64 bytes from 10.244.0.17: icmp_seq=2 ttl=64 time=0.081 ms
^C
--- 10.244.0.17 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3000ms
rtt min/avg/max/mdev = 0.055/0.129/0.291/0.094 ms
在现有的Flannel VxLAN网络中,两台主机上的Pod间通信,也是正常的,如master节点上的Pod访问node01上的Pod:
[root@k8s-master ~]# kubectl exec -it nginx-5bd76bcc4f-pb257 -- /bin/bash
root@nginx-5bd76bcc4f-pb257:/# ping 10.244.1.146
PING 10.244.1.146 (10.244.1.146) 56(84) bytes of data.
64 bytes from 10.244.1.146: icmp_seq=1 ttl=62 time=1.44 ms
64 bytes from 10.244.1.146: icmp_seq=2 ttl=62 time=0.713 ms
64 bytes from 10.244.1.146: icmp_seq=3 ttl=62 time=0.713 ms
64 bytes from 10.244.1.146: icmp_seq=4 ttl=62 time=0.558 ms
^C
--- 10.244.1.146 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3004ms
rtt min/avg/max/mdev = 0.558/0.858/1.448/0.346 ms
可以看到容器跨主机是可以正常通信的,那么容器的跨主机通信是如何实现的呢?????master上查看路由表信息:
[root@k8s-master ~]# ip route
......
10.244.1.0/24 via 10.244.1.0 dev flannel.1 onlink
10.244.2.0/24 via 10.244.2.0 dev flannel.1 onlink
......
发送到10.244.1.0/24和10.244.20/24网段的数据报文发给本机的flannel.1接口,即进入二层隧道,然后对数据报文进行封装(封装VxLAN首部-->UDP首部-->IP首部-->以太网首部),到达目标Node节点后,由目标Node上的flannel.1进行解封装。使用tcpdump进行 抓一下包,如下:
#在宿主机和容器内都进行ping另外一台主机上的Pod ip并进行抓包
[root@k8s-master ~]# ping -c 10 10.244.1.146
[root@k8s-master ~]# kubectl exec -it nginx-5bd76bcc4f-pb257 -- /bin/bash
root@nginx-5bd76bcc4f-pb257:/# ping 10.244.1.146
[root@k8s-master ~]# tcpdump -i flannel.1 -nn host 10.244.1.146
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on flannel.1, link-type EN10MB (Ethernet), capture size 262144 bytes
#宿主机ping后抓包情况如下:
22:22:35.737977 IP 10.244.0.0 > 10.244.1.146: ICMP echo request, id 29493, seq 1, length 64
22:22:35.738902 IP 10.244.1.146 > 10.244.0.0: ICMP echo reply, id 29493, seq 1, length 64
22:22:36.739042 IP 10.244.0.0 > 10.244.1.146: ICMP echo request, id 29493, seq 2, length 64
22:22:36.739789 IP 10.244.1.146 > 10.244.0.0: ICMP echo reply, id 29493, seq 2, length 64
#容器ping后抓包情况如下:
22:33:49.295137 IP 10.244.0.17 > 10.244.1.146: ICMP echo request, id 837, seq 1, length 64
22:33:49.295933 IP 10.244.1.146 > 10.244.0.17: ICMP echo reply, id 837, seq 1, length 64
22:33:50.296736 IP 10.244.0.17 > 10.244.1.146: ICMP echo request, id 837, seq 2, length 64
22:33:50.297222 IP 10.244.1.146 > 10.244.0.17: ICMP echo reply, id 837, seq 2, length 64
22:33:51.297556 IP 10.244.0.17 > 10.244.1.146: ICMP echo request, id 837, seq 3, length 64
22:33:51.298054 IP 10.244.1.146 > 10.244.0.17: ICMP echo reply, id 837, seq 3, length 64
可以看到报文都是经过flannel.1网络接口进入2层隧道进而转发
VXLAN是Linux内核本身支持的一种网络虚拟化技术,是内核的一个模块,在内核态实现封装解封装,构建出覆盖网络,其实就是一个由各宿主机上的Flannel.1设备组成的虚拟二层网络。
由于VXLAN由于额外的封包解包,导致其性能较差,所以Flannel就有了host-gw模式,即把宿主机当作网关,除了本地路由之外没有额外开销,性能和calico差不多,由于没有叠加来实现报文转发,这样会导致路由表庞大。因为一个节点对应一个网络,也就对应一条路由条目。
host-gw虽然VXLAN网络性能要强很多。,但是种方式有个缺陷:要求各物理节点必须在同一个二层网络中。物理节点必须在同一网段中。这样会使得一个网段中的主机量会非常多,万一发一个广播报文就会产生干扰。在私有云场景下,宿主机不在同一网段是很常见的状态,所以就不能使用host-gw了。
VXLAN还有另外一种功能,VXLAN也支持类似host-gw的玩法,如果两个节点在同一网段时使用host-gw通信,如果不在同一网段中,即 当前pod所在节点与目标pod所在节点中间有路由器,就使用VXLAN这种方式,使用叠加网络。 结合了Host-gw和VXLAN,这就是VXLAN的Direct routing模式
Flannel VxLAN的Direct routing模式配置
修改kube-flannel.yml文件,将flannel的configmap对象改为:
[root@k8s-master ~]# vim kube-flannel.yml
......
net-conf.json: |
{
"Network": "10.244.0.0/16", #默认网段
"Backend": {
"Type": "vxlan",
"Directrouting": true #增加
}
}
......
[root@k8s-master ~]# kubectl apply -f kube-flannel.yml
clusterrole.rbac.authorization.k8s.io/flannel configured
clusterrolebinding.rbac.authorization.k8s.io/flannel configured
serviceaccount/flannel unchanged
configmap/kube-flannel-cfg configured
daemonset.extensions/kube-flannel-ds-amd64 created
daemonset.extensions/kube-flannel-ds-arm64 created
daemonset.extensions/kube-flannel-ds-arm created
daemonset.extensions/kube-flannel-ds-ppc64le created
daemonset.extensions/kube-flannel-ds-s390x created
#查看路由信息
[root@k8s-master ~]# ip route
......
10.244.1.0/24 via 192.168.56.12 dev eth0
10.244.2.0/24 via 192.168.56.13 dev eth0
......
从上面的结果可以看到,发往10.244.1.0/24和10.244.1.0/24的包都是直接经过eth0网络接口直接发出去的,这就是Directrouting。如果两个节点是跨网段的,则flannel自动降级为VxLAN模式。
此时,在各 个 集群节点上执行“iptables -nL”命令 可以 看到, iptables filter 表 的 FORWARD 链 上 由其 生成 了 如下 两条 转发 规则, 它 显 式 放行 了 10. 244. 0. 0/ 16 网络 进出 的 所有 报文, 用于 确保 由 物理 接口 接收 或 发送 的 目标 地址 或 源 地址 为10. 244. 0. 0/ 16网络 的 所有 报文 均能 够 正常 通行。 这些 是 Direct Routing 模式 得以 实现 的 必要条件:
target prot opt source destination
ACCEPT all -- 10. 244. 0. 0/ 16 0. 0. 0. 0/ 0
ACCEPT all -- 0. 0. 0. 0/ 0 10. 244. 0. 0/ 16
再在此之前创建的Pod和宿主机上进行ping测试,可以看到在flannel.1接口上已经抓不到包了,在eth0上可以用抓到ICMP的包,如下:
[root@k8s-master ~]# tcpdump -i flannel.1 -nn host 10.244.1.146
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on flannel.1, link-type EN10MB (Ethernet), capture size 262144 bytes
^C
0 packets captured
0 packets received by filter
0 packets dropped by kernel
[root@k8s-master ~]# tcpdump -i eth0 -nn host 10.244.1.146
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
22:48:52.376393 IP 10.244.0.17 > 10.244.1.146: ICMP echo request, id 839, seq 1, length 64
22:48:52.376877 IP 10.244.1.146 > 10.244.0.17: ICMP echo reply, id 839, seq 1, length 64
22:48:53.377005 IP 10.244.0.17 > 10.244.1.146: ICMP echo request, id 839, seq 2, length 64
22:48:53.377621 IP 10.244.1.146 > 10.244.0.17: ICMP echo reply, id 839, seq 2, length 64
22:50:28.647490 IP 192.168.56.11 > 10.244.1.146: ICMP echo request, id 46141, seq 1, length 64
22:50:28.648320 IP 10.244.1.146 > 192.168.56.11: ICMP echo reply, id 46141, seq 1, length 64
22:50:29.648958 IP 192.168.56.11 > 10.244.1.146: ICMP echo request, id 46141, seq 2, length 64
22:50:29.649380 IP 10.244.1.146 > 192.168.56.11: ICMP echo reply, id 46141, seq 2, length 64
1.5、Host-gw后端
Flannel除了上面2种数据传输的方式以外,还有一种是host-gw的方式,host-gw后端是通过添加必要的路由信息使用节点的二层网络直接发送Pod的通信报文。它的工作方式类似于Directrouting的功能,但是其并不具备VxLan的隧道转发能力。
编辑kube-flannel的配置清单,将ConfigMap资源kube-flannel-cfg的data字段中网络配置进行修改,如下:
[root@k8s-master ~]# vim kube-flannel.yml
......
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "host-gw"
}
}
......
[root@k8s-master ~]# kubectl apply -f kube-flannel.yml
配置完成后,各节点会生成类似directrouting一样的 路由和iptables规则,用于实现二层转发Pod网络的通信报文,省去了隧道转发模式的额外开销。但是存在的问题点是,对于不在同一个二层网络的报文转发,host-gw是无法实现的。延续上面的例子,进行抓包查看:
master上的Pod:10.244.0.17向node01节点上的Pod:10.244.1.146发送ICMP报文
#查看路由表信息,可以看到其报文的发送方向都是和Directrouting是一样的
[root@k8s-master ~]# ip route
......
10.244.1.0/24 via 192.168.56.12 dev eth0
10.244.2.0/24 via 192.168.56.13 dev eth0
.....
#进行ping包测试
[root@k8s-master ~]# ping -c 2 10.244.1.146
#在eth0上进行抓包
[root@k8s-master ~]# tcpdump -i eth0 -nn host 10.244.1.146
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
23:11:05.556972 IP 192.168.56.11 > 10.244.1.146: ICMP echo request, id 59528, seq 1, length 64
23:11:05.557794 IP 10.244.1.146 > 192.168.56.11: ICMP echo reply, id 59528, seq 1, length 64
23:11:06.558231 IP 192.168.56.11 > 10.244.1.146: ICMP echo request, id 59528, seq 2, length 64
23:11:06.558610 IP 10.244.1.146 > 192.168.56.11: ICMP echo reply, id 59528, seq 2, length 64
该模式下,报文转发的相关流程如下:
1、Pod(10.244.0.17)向Pod(10.244.1.146)发送报文,查看到报文中的目的地址为:10.244.1.146,并非本地网段,会直接发送到网关(192.168.56.11);
2、网关发现该目标地址为10.244.1.146,要到达10.244.1.0/24网段,需要送达到node2 的物理网卡,node2接收以后发现该报文的目标地址属于本机上的另一个虚拟网卡,然后转发到相对应的Pod(10.244.1.146)
工作模式流程图如下:
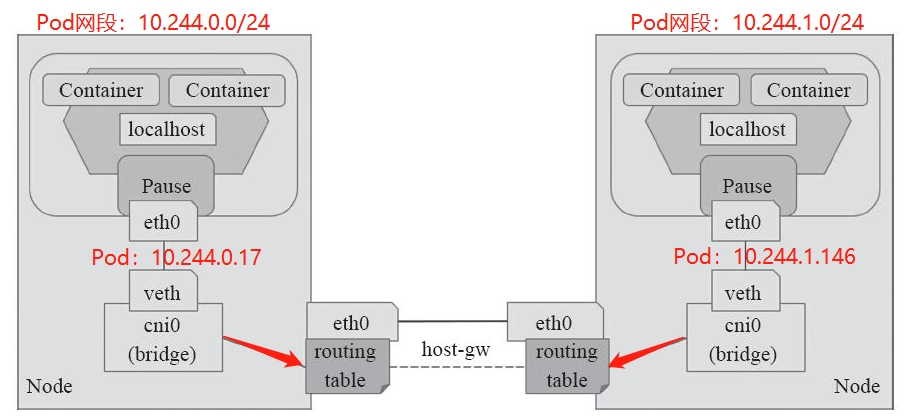
以上就是Flannel网络模型的三种工作模式,但是flannel自身并不具备为Pod网络实现网络策略和网络通信隔离的功能,为此只能借助于Calico联合统一的项目Calnal项目进行构建网络策略的功能。
2、网络策略
网络策略(Network Policy )是 Kubernetes 的一种资源。Network Policy 通过 Label 选择 Pod,并指定其他 Pod 或外界如何与这些 Pod 通信。
Pod的网络流量包含流入(Ingress)和流出(Egress)两种方向。默认情况下,所有 Pod 是非隔离的,即任何来源的网络流量都能够访问 Pod,没有任何限制。当为 Pod 定义了 Network Policy,只有 Policy 允许的流量才能访问 Pod。
Kubernetes的网络策略功能也是由第三方的网络插件实现的,因此,只有支持网络策略功能的网络插件才能进行配置网络策略,比如Calico、Canal、kube-router等等。
PS:Kubernetes自1.8版本才支持Egress网络策略,在该版本之前仅支持Ingress网络策略。
2.1、部署Canal提供网络策略功能
Calico可以独立地为Kubernetes提供网络解决方案和网络策略,也可以和flannel相结合,由flannel提供网络解决方案,Calico仅用于提供网络策略,此时将Calico称为Canal。结合flannel工作时,Calico提供的默认配置清单式以flannel默认使用的10.244.0.0/16为Pod网络,因此在集群中kube-controller-manager启动时就需要通过--cluster-cidr选项进行设置使用该网络地址,并且---allocate-node-cidrs的值应设置为true。
#设置RBAC
[root@k8s-master ~]# kubectl apply -f https://docs.projectcalico.org/v3.2/getting-started/kubernetes/installation/hosted/canal/rbac.yaml
#部署Canal提供网络策略
[root@k8s-master ~]# kubectl apply -f https://docs.projectcalico.org/v3.2/getting-started/kubernetes/installation/hosted/canal/canal.yaml
[root@k8s-master ~]# kubectl get ds canal -n kube-system
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
canal 3 3 0 3 0 beta.kubernetes.io/os=linux 2m
部署canal需要的镜像,建议先拉取镜像,避免耗死资源:
quay.io/calico/node:v3.2.6
quay.io/calico/cni:v3.2.6
quay.io/coreos/flannel:v0.9.1
[root@k8s-master ~]# kubectl get pods -n kube-system -o wide |grep canal
canal-2hqwt 3/3 Running 0 1h 192.168.56.11 k8s-master
canal-c5pxr 3/3 Running 0 1h 192.168.56.13 k8s-node02
canal-kr662 3/3 Running 6 1h 192.168.56.12 k8s-node01
Canal作为DaemonSet部署到每个节点,属于kube-system这个名称空间。需要注意的是,Canal只是直接使用了Calico和flannel项目,代码本身没有修改,Canal只是一种部署的模式,用于安装和配置项目。
2.2、配置网络策略
在Kubernetes系统中,报文的流入和流出的核心组件是Pod资源,它们也是网络策略功能的主要应用对象。NetworkPolicy对象通过podSelector选择 一组Pod资源作为控制对象。NetworkPolicy是定义在一组Pod资源之上用于管理入站流量,或出站流量的一组规则,有可以是出入站规则一起生效,规则的生效模式通常由spec.policyTypes进行 定义。如下图:
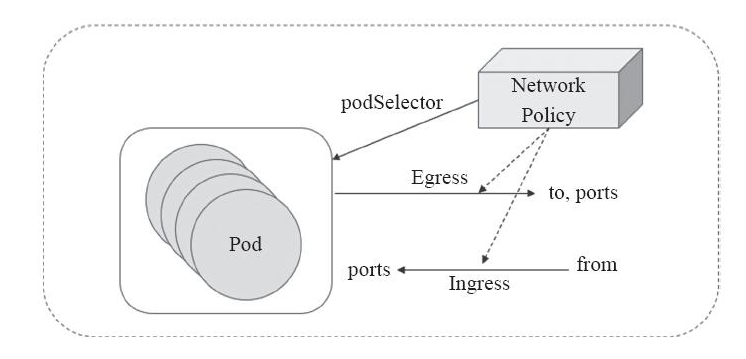
默认情况下,Pod对象的流量控制是为空的,报文可以自由出入。在附加网络策略之后,Pod对象会因为NetworkPolicy而被隔离,一旦名称空间中有任何NetworkPolicy对象匹配了某特定的Pod对象,则该Pod将拒绝NetworkPolicy规则中不允许的所有连接请求,但是那些未被匹配到的Pod对象依旧可以接受所有流量。
就特定的Pod集合来说,入站和出站流量默认是放行状态,除非有规则可以进行匹配。还有一点需要注意的是,在spec.policyTypes中指定了生效的规则类型,但是在networkpolicy.spec字段中嵌套定义了没有任何规则的Ingress或Egress时,则表示拒绝入站或出站的一切流量。定义网络策略的基本格式如下:
apiVersion: networking.k8s.io/v1 #定义API版本
kind: NetworkPolicy #定义资源类型
metadata:
name: allow-myapp-ingress #定义NetwokPolicy的名字
namespace: default
spec: #NetworkPolicy规则定义
podSelector: #匹配拥有标签app:myapp的Pod资源
matchLabels:
app: myapp
policyTypes ["Ingress"] #NetworkPolicy类型,可以是Ingress,Egress,或者两者共存
ingress: #定义入站规则
- from:
- ipBlock: #定义可以访问的网段
cidr: 10.244.0.0/16
except: #排除的网段
- 10.244.3.0/24
- podSelector: #选定当前default名称空间,标签为app:myapp可以入站
matchLabels:
app: myapp
ports: #开放的协议和端口定义
- protocol: TCP
port: 80
该网络策略就是将default名称空间中拥有标签"app=myapp"的Pod资源开放80/TCP端口给10.244.0.0/16网段,并排除10.244.3.0/24网段的访问,并且也开放给标签为app=myapp的所有Pod资源进行访问。
为了看出Network Policy的效果,先部署一个httpd的应用。配置清单文件如下:
[root@k8s-master ~]# mkdir network-policy-demo
[root@k8s-master ~]# cd network-policy-demo/
[root@k8s-master network-policy-demo]# vim httpd.yaml
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: httpd
spec:
replicas: 3
template:
metadata:
labels:
run: httpd
spec:
containers:
- name: httpd
image: httpd:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: httpd-svc
spec:
type: NodePort
selector:
run: httpd
ports:
- protocol: TCP
nodePort: 30000
port: 8080
targetPort: 80
创建三个副本,通过NodePort类型的Service对外方服务,部署应用:
[root@k8s-master network-policy-demo]# kubectl apply -f httpd.yaml
deployment.apps/httpd unchanged
service/httpd-svc created
[root@k8s-master network-policy-demo]# kubectl get pods -o wide |grep httpd
httpd-75f655479d-882hz 1/1 Running 0 4m 10.244.0.2 k8s-master
httpd-75f655479d-h7lrr 1/1 Running 0 4m 10.244.2.2 k8s-node02
httpd-75f655479d-kzr5g 1/1 Running 0 4m 10.244.1.2 k8s-node01
[root@k8s-master network-policy-demo]# kubectl get svc httpd-svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
httpd-svc NodePort 10.99.222.179 <none> 8080:30000/TCP 4m
当前没有定义任何Network Policy,验证应用的访问:
#启动一个busybox Pod,可以访问Service,也可以ping副本的Pod
[root@k8s-master ~]# kubectl run busybox --rm -it --image=busybox /bin/sh
If you don't see a command prompt, try pressing enter.
/ # wget httpd-svc:8080
Connecting to httpd-svc:8080 (10.99.222.179:8080)
index.html 100% |*********************************************************************************************| 45 0:00:00 ETA
/ # ping -c 2 10.244.1.2
PING 10.244.1.2 (10.244.1.2): 56 data bytes
64 bytes from 10.244.1.2: seq=0 ttl=63 time=0.507 ms
64 bytes from 10.244.1.2: seq=1 ttl=63 time=0.228 ms
--- 10.244.1.2 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.228/0.367/0.507 ms
#集群节点也可以访问Sevice和ping通副本Pod
[root@k8s-node01 ~]# curl 10.99.222.179:8080
<html><body><h1>It works!</h1></body></html>
[root@k8s-node01 ~]# ping -c 2 10.244.2.2
PING 10.244.2.2 (10.244.2.2) 56(84) bytes of data.
64 bytes from 10.244.2.2: icmp_seq=1 ttl=63 time=0.931 ms
64 bytes from 10.244.2.2: icmp_seq=2 ttl=63 time=0.812 ms
--- 10.244.2.2 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 0.812/0.871/0.931/0.066 ms
#集群外部访问192.168.56.11:30000也是通的
[root@localhost ~]# curl 192.168.56.11:30000
<html><body><h1>It works!</h1></body></html>
那么下面再去设置不同的Network Policy来管控Pod的访问。
2.3、管控入站流量
NetworkPolicy资源属于名称空间级别,它的作用范围为其所属的名称空间。
1、设置默认的Ingress策略
用户可以创建一个NetworkPolicy来为名称空间设置一个默认的隔离策略,该策略选择所有的Pod对象,然后允许或拒绝任何到达这些Pod的入站流量,如下:
[root@k8s-master network-policy-demo]# vim policy-demo.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: deny-all-ingress
spec:
podSelector: {}
policyTypes: ["Ingress"]
#指明了Ingress生效规则,但不定义任何Ingress字段,因此不能匹配任何源端点,从而拒绝所有的入站流量
[root@k8s-master network-policy-demo]# kubectl apply -f policy-demo.yaml
networkpolicy.networking.k8s.io/deny-all-ingress created
[root@k8s-master network-policy-demo]# kubectl get networkpolicy
NAME POD-SELECTOR AGE
deny-all-ingress <none> 11s
#此时再去访问测试,是无法ping通,无法访问的
[root@k8s-master ~]# kubectl run busybox --rm -it --image=busybox /bin/sh
If you don't see a command prompt, try pressing enter.
/ # wget httpd-svc:8080
Connecting to httpd-svc:8080 (10.99.222.179:8080)
wget: can't connect to remote host (10.99.222.179): Connection timed out
如果要将默认策略设置为允许所有入站流量,只需要定义Ingress字段,并将这个字段设置为空,以匹配所有源端点,但本身不设定网络策略,就已经是默认允许所有入站流量访问的,下面给出一个定义的格式:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: deny-all-ingress
spec:
podSelector: {}
policyTypes: ["Ingress"]
ingress:
- {}
实践中,通常将默认的网络策略设置为拒绝所有入站流量,然后再放行允许的源端点的入站流量。
2、放行特定的入站流量
[root@k8s-master network-policy-demo]# vim policy-demo.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: access-httpd
spec:
podSelector:
matchLabels:
run: httpd
policyTypes: ["Ingress"]
ingress:
- from:
- ipBlock:
cidr: 10.244.0.0/16
except:
- 10.244.2.0/24
- 10.244.1.0/24
- podSelector:
matchLabels:
access: "true"
ports:
- protocol: TCP
port: 80
[root@k8s-master network-policy-demo]# kubectl apply -f policy-demo.yaml
networkpolicy.networking.k8s.io/access-httpd created
[root@k8s-master network-policy-demo]# kubectl get networkpolicy
NAME POD-SELECTOR AGE
access-httpd run=httpd 6s
验证NetworkPolicy的有效性:
#创建带有标签的busybox pod访问,是可以正常访问的,但是因为仅开放了TCP协议,所以PING是无法ping通的
[root@k8s-master ~]# kubectl run busybox --rm -it --labels="access=true" --image=busybox /bin/sh
If you don't see a command prompt, try pressing enter.
/ # wget httpd-svc:8080
Connecting to httpd-svc:8080 (10.99.222.179:8080)
index.html 100% |*********************************************************************************************| 45 0:00:00 ETA
/ # ping -c 3 10.244.0.2
PING 10.244.0.2 (10.244.0.2): 56 data bytes
--- 10.244.0.2 ping statistics ---
3 packets transmitted, 0 packets received, 100% packet loss
2.4、管控出站流量
通常,出站的流量默认策略应该是允许通过的,但是当有精细化需求,仅放行那些有对外请求需要的Pod对象的出站流量,也可以先为名称空间设置“禁止所有”的默认策略,再细化制定准许的策略。networkpolicy.spec中嵌套的Egress字段用来定义出站流量规则。
1、设定默认Egress策略
和Igress一样,只需要通过policyTypes字段指明生效的Egress类型规则,然后不去定义Egress字段,就不会去匹配到任何目标端点,从而拒绝所有的出站流量。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: deny-all-egress
spec:
podSelector: {}
policyTypes: ["Egress"]
实践中,需要进行严格隔离的环境通常将默认的策略设置为拒绝所有出站流量,再去细化配置允许到达的目标端点的出站流量。
2、放行特定的出站流量
下面举个例子定义一个Egress规则,对标签run=httpd的Pod对象,到达标签为access=true的Pod对象的80端口的流量进行放行。
[root@k8s-master network-policy-demo]# vim egress-policy.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: httpd-egress
spec:
podSelector:
matchLabels:
run: httpd
policyTypes: ["Egress"]
egress:
- to:
- podSelector:
matchLabels:
access: "true"
ports:
- protocol: TCP
port: 80
#NetworkPolicy检测,一个带有access=true标签,一个不带
[root@k8s-master ~]# kubectl run busybox --rm -it --labels="access=true" --image=busybox /bin/sh
If you don't see a command prompt, try pressing enter.
/ # wget httpd-svc:8080
Connecting to httpd-svc:8080 (10.99.222.179:8080)
index.html 100% |*********************************************************************************************| 45 0:00:00 ETA
/ # exit
Session ended, resume using 'kubectl attach busybox-686cb649b6-6j4qx -c busybox -i -t' command when the pod is running
deployment.apps "busybox" deleted
[root@k8s-master ~]# kubectl run busybox2 --rm -it --image=busybox /bin/sh
If you don't see a command prompt, try pressing enter.
/ # wget httpd-svc:8080
Connecting to httpd-svc:8080 (10.99.222.179:8080)
wget: can't connect to remote host (10.99.222.179): Connection timed out
从上面的检测结果可以看到,带有标签access=true的Pod才能访问到httpd-svc,说明上面配置的Network Policy已经生效。
2.5、隔离名称空间
实践中,通常需要彼此隔离所有的名称空间,但是又需要允许它们可以和kube-system名称空间中的Pod资源进行流量交换,以实现监控和名称解析等各种管理功能。下面的配置清单示例在default名称空间定义相关规则,在出站和入站都默认均为拒绝的情况下,它用于放行名称空间内部的各Pod对象之间的通信,以及和kube-system名称空间内各Pod间的通信。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: namespace-deny-all
namespace: default
spec:
policyTypes: ["Ingress","Egress"]
podSelector: {}
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: namespace-allow
namespace: default
spec:
policyTypes: ["Ingress","Egress"]
podSelector: {}
ingress:
- from:
- namespaceSelector:
matchExpressions:
- key: name
operator: In
values: ["default","kube-system"]
egress:
- to:
- namespaceSelector:
matchExpressions:
- key: name
operator: In
values: ["default","kube-system"]
需要注意的是,有一些额外的系统附件可能会单独部署到独有的名称空间中,比如将prometheus监控系统部署到prom名称空间等,这类具有管理功能的附件所在的名称空间和每一个特定的名称空间的出入流量也是需要被放行的。
Kubernetes学习之路(二十一)之网络模型和网络策略的更多相关文章
- kubernetes学习笔记之十三:基于calico的网络策略入门
一..安装calico [root@k8s-master01 ~]# kubectl apply -f https://docs.projectcalico.org/v3.3/getting-star ...
- Kubernetes学习之路(十一)之Pod状态和生命周期管理
一.什么是Pod? Pod是kubernetes中你可以创建和部署的最小也是最简的单位.一个Pod代表着集群中运行的一个进程. Pod中封装着应用的容器(有的情况下是好几个容器),存储.独立的网络IP ...
- 嵌入式Linux驱动学习之路(二十一)字符设备驱动程序总结和块设备驱动程序的引入
字符设备驱动程序 应用程序是调用C库中的open read write等函数.而为了操作硬件,所以引入了驱动模块. 构建一个简单的驱动,有一下步骤. 1. 创建file_operations 2. 申 ...
- Kubernetes学习之路(五)之Flannel网络二进制部署和测试
一.K8S的ip地址 Node IP:节点设备的IP,如物理机,虚拟机等容器宿主的实际IP. Pod IP:Pod的IP地址,是根据docker0网络IP段进行分配的. Cluster IP:Serv ...
- Kubernetes学习之路目录
Kubernetes基础篇 环境说明 版本说明 系统环境 Centos 7.2 Kubernetes版本 v1.11.2 Docker版本 v18.09 Kubernetes学习之路(一)之概念和架构 ...
- Directx11学习笔记【二十一】 封装键盘鼠标响应类
原文:Directx11学习笔记[二十一] 封装键盘鼠标响应类 摘要: 本文由zhangbaochong原创,转载请注明出处:http://www.cnblogs.com/zhangbaochong/ ...
- FastAPI 学习之路(十一)请求体 - 嵌套模型
系列文章: FastAPI 学习之路(一)fastapi--高性能web开发框架 FastAPI 学习之路(二) FastAPI 学习之路(三) FastAPI 学习之路(四) FastAPI 学习之 ...
- Redis——学习之路二(初识redis服务器命令)
上一章我们已经知道了如果启动redis服务器,现在我们来学习一下,以及如何用客户端连接服务器.接下来我们来学习一下查看操作服务器的命令. 服务器命令: 1.info——当前redis服务器信息 s ...
- Kubernetes学习之路(二十)之K8S组件运行原理详解总结
目录 一.看图说K8S 二.K8S的概念和术语 三.K8S集群组件 1.Master组件 2.Node组件 3.核心附件 四.K8S的网络模型 五.Kubernetes的核心对象详解 1.Pod资源对 ...
随机推荐
- Python+Selenium笔记(十六)屏幕截图
(一) 方法 方法 简单说明 save_screenshot(filename) 获取当前屏幕截图并保存为指定文件 filename:路径/文件名 get_screenshot_as_base64 ...
- 【mongoDB运维篇③】replication set复制集
介绍 replicattion set 多台服务器维护相同的数据副本,提高服务器的可用性,总结下来有以下好处: 数据备份与恢复 读写分离 MongoDB 复制集的结构以及基本概念 正如上图所示,Mon ...
- kafka入门1:安装及配置
1下载 官方下载地址:https://kafka.apache.org/downloads 案例使用版本:kafka_2.11-1.1.0.tgz 2上传服务器 使用ftp工具将压缩包放置到服务器上 ...
- c#WebApi使用form表单提交excel,实现批量写入数据库
思路:用户点击下载模板按钮,获取到excel模板,然后向里面填写数据保存.from表单提交的时候选择保存好的excel,实现数据的批量导入过程 先把模板放在服务器的项目目录下面:如 模板我一般放在:F ...
- JVM & GC 笔记
0. 说明 转载并修改自JVM 1. JVM 1.1 什么是JVM JVM为Java虚拟机(Java Virtual Machine) Runtime data area,运行时数据区. 包含5个区域 ...
- Priority Queue
优先队列 集合性质的数据类型离不开插入删除这两操作,主要区别就在于删除的时候删哪个,像栈删最晚插入的,队列删最早插入的,随机队列就随便删,而优先队列删除当前集合里最大(或最小)的元素.优先队列有很多应 ...
- 【Alpha 冲刺】 12/12
今日任务总结 人员 今日原定任务 完成情况 遇到问题 贡献值 胡武成 完成app端api编写 已完成 JAVA后端跨域访问没有处理(目前已解决),导致前端localhost请求失败而误以为自己操作失误 ...
- console.time方法与console.timeEnd方法
在Node.js中,当需要统计一段代码的执行时间时,可以使用console.time方法与console.timeEnd方法,其中console.time方法用于标记开始时间,console.time ...
- MySQL备份与恢复.md
备份与恢复使用的命令 mysqldump 常用选项 -A, --all-databases:导出全部数据库 -B, --databases:导出几个数据库.参数后面所有名字参量都被看作数据库名. -- ...
- C#实现的协同过滤算法
using System;using System.Collections.Generic;using System.Linq;using System.Text; namespace SlopeOn ...