HDFS概要
--HDFS--
Hadoop Distributed File System
HDFS一个分布式,高容错,可线性扩展的文件系统
简介:
Hadoop分布式文件系统(HDFS)是一种分布式文件系统,设计用于在商用硬件上运行。它与现有的分布式文件系统有许多相似之处。但是,与其他分布式文件系统的差异很大。HDFS具有高度容错能力,旨在部署在低成本硬件上。HDFS提供对应用程序数据的高吞吐量访问,适用于具有大型数据集的应用程序。HDFS放宽了一些POSIX要求,以实现对文件系统数据的流式访问。HDFS最初是作为Apache Nutch网络搜索引擎项目的基础设施而构建的。HDFS是Apache Hadoop Core项目的一部分。
HDFS架构
HDFS具有主/从架构。HDFS集群由单个NameNode,管理文件系统命名空间的主服务器和管理客户端对文件的访问组成。此外,还有许多DataNode,通常是群集中每个节点一个,用于管理连接到它们运行的节点的存储。HDFS公开文件系统命名空间,并允许用户数据存储在文件中。在内部,文件被分成一个或多个块,这些块存储在一组DataNode中。NameNode执行文件系统命名空间操作,如打开,关闭和重命名文件和目录。它还确定了块到DataNode的映射。DataNode负责提供来自文件系统客户端的读写请求。DataNodes还执行块创建,删除。
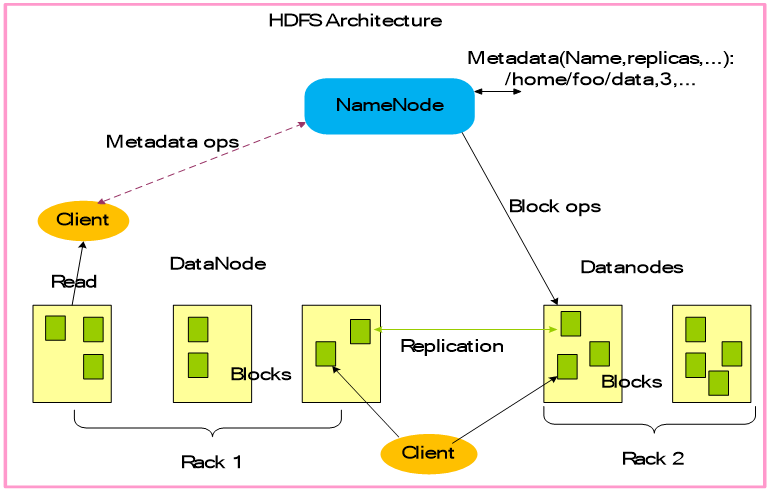
HDFS架构包含三个部分:NameNode,DataNode,Client。
Replication:复制 Metadata ops
:元数据操作 Rack:机架
NameNode(命名节点):存储、生成文件系统的元数据。运行一个命名节点。
DataNode(数据节点):存储实际的数据,将自己管理的数据块信息上报给NameNode ,运行多个数据节点。
Client(客户端):支持业务访问HDFS,从NameNode
,DataNode获取数据返回给业务。可以多个客户端,和业务一起运行。
HDFS的读写流程
文件写流程:
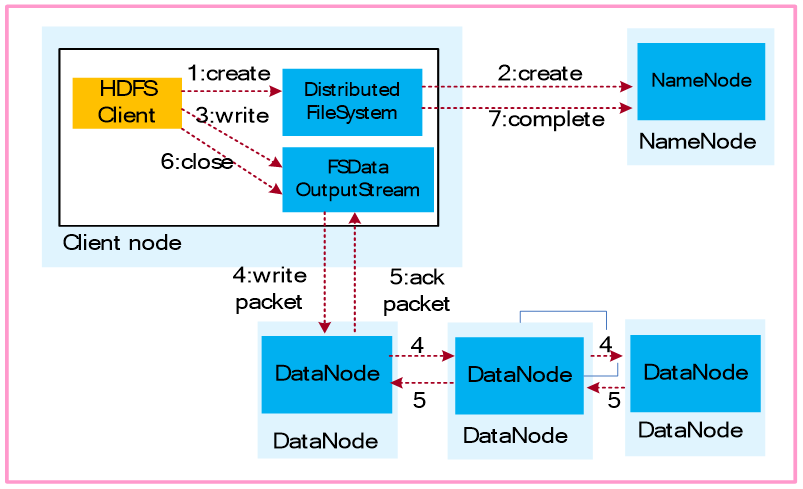
1.业务应用调用HDFS Client提供的API,请求写入文件。
2.HDFS Client联系NameNode,NameNode在元数据中创建文件节点。
3.业务应用调用write API写入文件。
4.HDFS Client收到业务数据后,从NameNode获取到数据块编号、位置信息后,联系DataNode,并将需要写入数据的DataNode建立起流水线。完成后,客户端再通过自有协议写入数据到DataNode1,再由DataNode1复制到DataNode2, DataNode3。
5.写完的数据,将返回确认信息给HDFS Client。
6.所有数据确认完成后,业务调用HDFS Client关闭文件。
7.业务调用close, flush后HDFS Client联系NameNode,确认数据写完成,NameNode持久化元数据。
文件读流程:
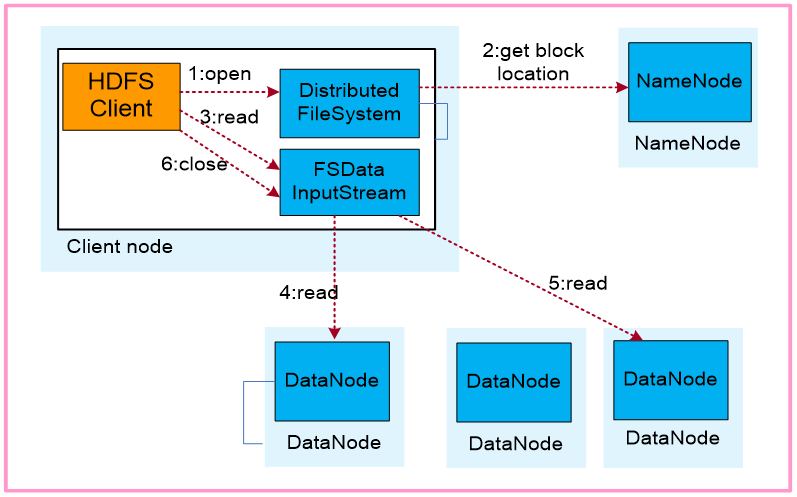
1.业务应用调用HDFS Client提供的API打开文件。
2.HDFS Client联系NameNode,获取到文件信息(数据块、DataNode位置信息)。
业务应用调用read API读取文件。
3.HDFS Client根据从NameNode获取到的信息,联系DataNode,获取相应的数据块。(Client采用就近原则读取数据)。
4.5.HDFS Client会与多个DataNode通讯获取数据块。
6.数据读取完成后,业务调用close关闭连接。
DistributedFileSystem对象(java):HDFS客户端通过调用DistributedFileSystem对象的open()方法打开需要读取的文件。
FSDataInputStream对象:DistributedFileSystem通过对NameNode发出RPC请求,确定要读取文件的block的位置。DistributedFileSystem返回一个FSDataInputStream(输入流,读操作)给HDFS客户端,让它从FSDataInputStream中读取数据。FSDataInputStream接着包装一个DFSInputStream(输入流),用来与DataNode及NameNode的I/O 通信。
HDFS的关键特性
HDFS的高可靠性是如何实现的?
.HA高可靠机制:

HDFS的高可靠性(HA)主要体现在利用zookeeper实现主备NameNode,以解决单点NameNode故障问题。
ZooKeeper主要用来存储HA下的状态文件,主备信息。ZK个数建议3个及以上且为奇数个。
NameNode主备模式,主提供服务,备同步主元数据并作为主的热备。
ZKFC(ZooKeeper
Failover Controller)用于监控NameNode节点的主备状态。
JN(JournalNode)用于存储Active NameNode生成的Editlog。Standby NameNode加载JN上Editlog,同步元数据。
ZKFC控制NameNode主备仲裁
ZKFC作为一个精简的仲裁代理,其利用zookeeper的分布式锁功能,实现主备仲裁,再通过命令通道,控制NameNode的主备状态。ZKFC与NN部署在一起,两者个数相同。
元数据同步
主NameNode对外提供服务。生成的Editlog同时写入本地和JN,同时更新主NameNode内存中的元数据。
备NameNode监控到JN上Editlog变化时,加载Editlog进内存,生成新的与主NameNode一样的元数据。元数据同步完成。
主备的FSImage仍保存在各自的磁盘中,不发生交互。FSImage是内存中元数据定时写到本地磁盘的副本,也叫元数据镜像。
1. ZKFC控制NameNode主备仲裁
ZKFC作为一个精简的仲裁代理,其利用zookeeper的分布式锁功能,实现主备仲裁,再通过命令通道,控制NameNode的主备状态。ZKFC与NN部署在一起,两者个数相同。
2. 采用共享存储同步日志
主用NameNode对外提供服务,同时对元数据的修改采用写日志的方式写入共享存储,同时修改内存中的元数据。
备用NameNode周期读取共享存储中的日志,并生成新的元数据文件,持久化到硬盘,同时回传给主NameNode。
.元数据持久化机制:
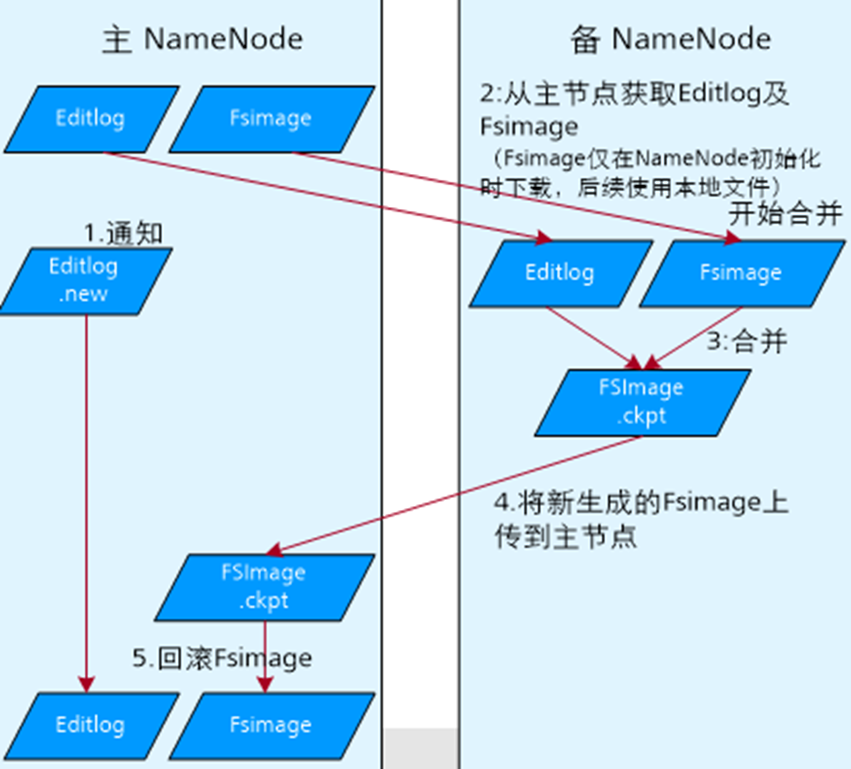
EditLog:记录用户的操作日志,用以在FSImage的基础上生成新的文件系统镜像。
FSImage:用以阶段性保存文件镜像。
FSImage.ckpt:在内存中对fsimage文件和EditLog文件合并(merge)后产生新的fsimage,写到磁盘上,这个过程叫checkpoint.。备用NameNode加载完fsimage和EditLog文件后,会将merge(合并)后的结果同时写到本地磁盘和NFS(网络文件系统)。此时磁盘上有一份原始的fsimage文件和一份新生成的checkpoint文件:fsimage.ckpt. 而后将fsimage.ckpt改名为fsimage(覆盖原有的fsimage)。
EditLog.new:
NameNode每隔1小时或Editlog满64MB就触发合并,合并时,将数据传到Standby
NameNode时,因数据读写不能同步进行,此时NameNode产生一个新的日志文件Editlog.new用来存放这段时间的操作日志。Standby NameNode合并成fsimage后回传给主NameNode替换掉原有fsimage,并将Editlog.new 命名为Editlog。
Datanode会周期性地向主备namenode上报数据块和datanode的对应信息
.三副本机制:
为确保文件的容错性,同时提供更快的数据读取,默认每个数据块有3个副本,且分布在不同的存储节点DN上。
第一个副本在本节点。(本地节点)
第二个副本在远端机架的节点。(同机架不同节点)
第三个副本看之前的两个副本是否在同一机架,如果是则选择其他机架(其他机架),否则选择和第一个副本相同机架的不同节点,第四个及以上,随机选择副本存放位置。
HDFS概要的更多相关文章
- HDFS原理介绍
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据google发表的论文翻版的.论文为GFS(Google File System)Googl ...
- hadoop(一):深度剖析hdfs原理
在配置hbase集群将 hdfs 挂接到其它镜像盘时,有不少困惑的地方,结合以前的资料再次学习; 大数据底层技术的三大基石起源于Google在2006年之前的三篇论文GFS.Map-Reduce. ...
- Alluxio1.0.1最新版(Tachyon为其前身)介绍,+HDFS分布式环境搭建
Alluxio(之前名为Tachyon)是世界上第一个以内存为中心的虚拟的分布式存储系统.它统一了数据访问的方式,为上层计算框架和底层存储系统构建了桥梁. 应用只需要连接Alluxio即可访问存储在底 ...
- HDFS(Hadoop Distributed File System )
HDFS(Hadoop Distributed File System ) HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据google发表 ...
- HDFS 命令大全
目录 概要 用户命令 dfs 命令 追加文件内容 查看文件内容 得到文件的校验信息 修改用户组 修改文件权限 修改文件所属用户 本地拷贝到 hdfs hdfs 拷贝到本地 获取目录,文件数量及大小 h ...
- hdfs基本操作-python接口
安装hdfs包 pip install hdfs 查看hdfs目录 [root@hadoop hadoop]# hdfs dfs -ls -R / drwxr-xr-x - root supergro ...
- hadoop之 HDFS fs 命令总结
版本:Hadoop 2.7.4 -- 查看hadoop fs帮助信息[root@hadp-master sbin]# hadoop fsUsage: hadoop fs [generic option ...
- HDFS的介绍
设计思想 分而治之:将大文件.大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析: 在大数据系统中作用:为各类分布式运算框架(如:mapreduce,spark,te ...
- 深度剖析hdfs原理
大数据底层技术的三大基石起源于Google在2006年之前的三篇论文GFS.Map-Reduce. Bigtable,其中GFS.Map-Reduce技术直接支持了Apache Hadoop项目的诞生 ...
随机推荐
- Firefox table 不居中解决办法 解决火狐层或 table 不居中
Firefox table 不居中解决办法: table 使用 align="center" ,IE正常,Firefox 却是居左了,网上有各种解决的办法,比如在table外面再套 ...
- js监听键盘触发按钮事件,回车提交表单
/*回车提交表单*/ $(document).keydown(function(event){ if(event.keyCode == 13){ //alert('你按下了Enter'); $(&qu ...
- Typecho 插件开发基础
<?php /** * 标题 插件说明 * * @package 添加标题 * @author Fan * @version 1.0.0 * @link http://cnblogs.com/f ...
- ArcMap等值面
先说一下题目,ArcMap中没有由栅格直接生成等值面的功能,但由栅格直接生成等值线的功能存在,可通过如下方式得到等值面: 1.提取等值线 由dem直接提取等值线:Spatial Analyst Too ...
- xmlns 实例分析
<?xml version="1.0" encoding="UTF-8"?> <!-- Licensed to the Apache Soft ...
- UNIX之父肯和丹尼斯(连载二)
从那一场“黑客招聘会”说起 2012年7月末在拉斯维加斯召开的全球黑客大会,已经是这系列会议的第二十一次.除了惯常的Bug发表.技术展示之外,最近几年的黑客大会也开始变得越来越像招聘会.IT业 ...
- UIActivityIndicatorView 的使用
// // UIActivityIndicator.m // ToolBar // // Created by lanouhn on 15/1/3. // Copyright (c) 2015 ...
- mysql查询 根据年月日的查询
select * from call_loan_info where DATE_FORMAT(create_time,'%Y-%m-%d') = '2017-06-16'
- (暴力 记录)Camellia的难题 -- zzuli -- 1784
http://acm.zzuli.edu.cn/problem.php?id=1784 Camellia的难题 Time Limit: 2 Sec Memory Limit: 128 MBSubmi ...
- noip第12课资料