python自动化开发-[第十八天]-django的ORM补充与ajax,分页器
今日概要:
1、ORM一对多,多对多
2、正向查询,反向查询
3、聚合查询与分组查询
4、F查询和Q查询
5、ajax
6、分页器
一、ORM补充:
django在终端打印sql语句设置:
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
<1> 添加记录方法
# create方式
#Book.objects.create(title="python",price=233)
# save 方式
book_obj=Book(title="Linux",price=122)
book_obj.save()
一对多添加方式:
Book.objects.create(title="python",price=223,publisher_id=2)
book_obj=Book(title="Linux",price=122,publisher=publish_obj)
多对多的添加方式:
ManyToManyField:
# 绑定关系
book_obj.authors.add(*author_list) # book_obj.authors: nid=2 的书籍关联的作者的对象集合
# 解除关系
book_obj.authors.clear() #清空当前对象所有绑定关系
book_obj.authors.remove() #只想删除某一条用remove
手动创建第三张表:
Book2Author.objects.create(book_id=1,author_id=1)
QuerySet惰性机制:
所谓惰性机制:Publisher.objects.all()或者.filter()等都只是返回了一个QuerySet(查询结果集对象),它并不会马上执行sql,而是当调用QuerySet的时候才执行。
QuerySet特点:
<1> 可迭代的
<2> 可切片
#objs=models.Book.objects.all()#[obj1,obj2,ob3...]
#QuerySet: 可迭代
# for obj in objs:#每一obj就是一个行对象
# print("obj:",obj)
# QuerySet: 可切片
# print(objs[1])
# print(objs[1:4])
# print(objs[::-1])
QuerySet的高效使用:
<1>Django的queryset是惰性的
Django的queryset对应于数据库的若干记录(row),通过可选的查询来过滤。例如,下面的代码会得
到数据库中名字为‘Dave’的所有的人:person_set = Person.objects.filter(first_name="Dave")
上面的代码并没有运行任何的数据库查询。你可以使用person_set,给它加上一些过滤条件,或者将它传给某个函数,
这些操作都不会发送给数据库。这是对的,因为数据库查询是显著影响web应用性能的因素之一。
<2>要真正从数据库获得数据,你可以遍历queryset或者使用if queryset,总之你用到数据时就会执行sql.
为了验证这些,需要在settings里加入 LOGGING(验证方式)
obj=models.Book.objects.filter(id=3)
# for i in obj:
# print(i)
# if obj:
# print("ok")
<3>queryset是具有cache的
当你遍历queryset时,所有匹配的记录会从数据库获取,然后转换成Django的model。这被称为执行
(evaluation).这些model会保存在queryset内置的cache中,这样如果你再次遍历这个queryset,
你不需要重复运行通用的查询。
obj=models.Book.objects.filter(id=3)
# for i in obj:
# print(i)
## models.Book.objects.filter(id=3).update(title="GO")
## obj_new=models.Book.objects.filter(id=3)
# for i in obj:
# print(i) #LOGGING只会打印一次
<4>
简单的使用if语句进行判断也会完全执行整个queryset并且把数据放入cache,虽然你并不需要这些
数据!为了避免这个,可以用exists()方法来检查是否有数据:
obj = Book.objects.filter(id=4)
# exists()的检查可以避免数据放入queryset的cache。
if obj.exists():
print("hello world!")
<5>当queryset非常巨大时,cache会成为问题
处理成千上万的记录时,将它们一次装入内存是很浪费的。更糟糕的是,巨大的queryset可能会锁住系统
进程,让你的程序濒临崩溃。要避免在遍历数据的同时产生queryset cache,可以使用iterator()方法
来获取数据,处理完数据就将其丢弃。
objs = Book.objects.all().iterator()
# iterator()可以一次只从数据库获取少量数据,这样可以节省内存
for obj in objs:
print(obj.name)
#BUT,再次遍历没有打印,因为迭代器已经在上一次遍历(next)到最后一次了,没得遍历了
for obj in objs:
print(obj.name)
#当然,使用iterator()方法来防止生成cache,意味着遍历同一个queryset时会重复执行查询。所以使
#用iterator()的时候要当心,确保你的代码在操作一个大的queryset时没有重复执行查询
总结:
queryset的cache是用于减少程序对数据库的查询,在通常的使用下会保证只有在需要的时候才会查询数据库。
使用exists()和iterator()方法可以优化程序对内存的使用。不过,由于它们并不会生成queryset cache,可能
会造成额外的数据库查询。
解释
对象查询,单表条件查询,多表条件关联查询
#--------------------对象形式的查找--------------------------
# 正向查找
ret1=models.Book.objects.first()
print(ret1.title)
print(ret1.price)
print(ret1.publisher)
print(ret1.publisher.name) #因为一对多的关系所以ret1.publisher是一个对象,而不是一个queryset集合 # 反向查找
ret2=models.Publish.objects.last()
print(ret2.name)
print(ret2.city)
#如何拿到与它绑定的Book对象呢?
print(ret2.book_set.all()) #ret2.book_set是一个queryset集合,通过书名的小写加 '_set' 来进行反查 #---------------了不起的双下划线(__)之单表条件查询---------------- # models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值
#
# models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据
# models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in
#
# models.Tb1.objects.filter(name__contains="ven")
# models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感
#
# models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and
#
# startswith,istartswith, endswith, iendswith, #----------------了不起的双下划线(__)之多表条件关联查询--------------- # 正向查找(条件) # ret3=models.Book.objects.filter(title='Python').values('id')
# print(ret3)#[{'id': 1}] #正向查找(条件)之一对多 ret4=models.Book.objects.filter(title='Python').values('publisher__city')
print(ret4) #[{'publisher__city': '北京'}] #正向查找(条件)之多对多
ret5=models.Book.objects.filter(title='Python').values('author__name')
print(ret5)
ret6=models.Book.objects.filter(author__name="alex").values('title')
print(ret6) #注意
#正向查找的publisher__city或者author__name中的publisher,author是book表中绑定的字段
#一对多和多对多在这里用法没区别 # 反向查找(条件) #反向查找之一对多:
#查询python这本书的出版社名字
ret8=models.Publisher.objects.filter(book__title='Python').values('name')
print(ret8)#[{'name': '人大出版社'}] 注意,book__title中的book就是Publisher的关联表名
#查询python这本书的作者id
ret9=models.Publisher.objects.filter(book__title='Python').values('book__authors')
print(ret9)#[{'book__authors': 1}, {'book__authors': 2}] #反向查找之多对多:
#查询python这本书的作者
ret10=models.Author.objects.filter(book__title='Python').values('name')
print(ret10)#[{'name': 'alex'}, {'name': 'alvin'}] #注意
#正向查找的book__title中的book是表名Book
#一对多和多对多在这里用法没区别
例子:
关联查询(多表查询)
sql:
子查询
select name from dep whrere id=
(select dep_id from emp whrere name="张三")
联表查询
select dep.name from emp inner join dep on emp_dep_id=dep.id where emp.name="张三" 两个手段: 1 对象 2 双下划线 1 对象
# 查询python这本书的出版社的联系方式 (一对多)
#ret=book_obj.publisher.email
#print(ret) # 查询Linux的所有作者的名字
book_obj = Book.objects.get(title="Linux") author_list=book_obj.authors.all()
for author in author_list:
print(author.name) 2 __ (******) 重点:filter方法与value方法都可以进行跨表查询 # 查询alex出版过的所有书籍名称
# 方式1 正向查询
# ret=Book.objects.filter(authors__name="alex").values("title") # 方式2 反向查询
# ret=Author.objects.filter(name="alex").values("book__title")
# print(ret) # <QuerySet [{'book__title': '水浒传'}]> # 查询出版了python这本书的出版社的名字
# 正向:
ret1=Book.objects.filter(title="python").values("publisher__name")
# 反向:
ret2=Publish.objects.filter(book__title="python").values("name")
注意:条件查询即与对象查询对应,是指在filter,values等方法中的通过__来明确查询条件
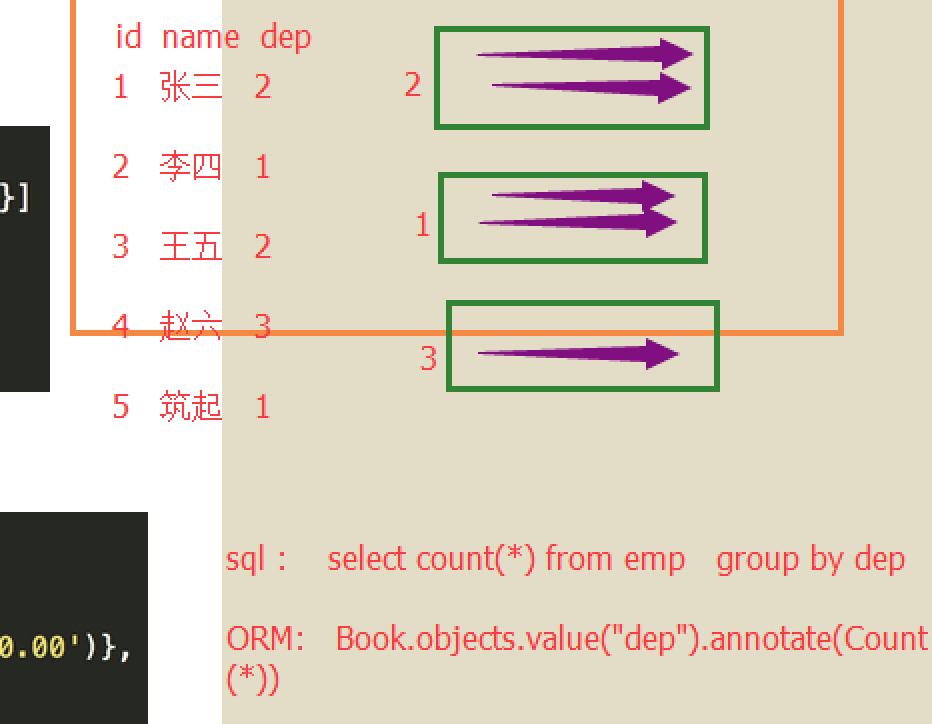
聚合查询和分组查询
aggregate(*args,**kwargs):
通过对QuerySet进行计算,返回一个聚合值的字典。aggregate()中每一个参数都指定一个包含在字典中的返回值。即在查询集上生成聚合。
sql语句中聚合字段:
sql:
聚合函数 max min count avg sum
select * from emp group by 字段
from django.db.models import Avg,Min,Sum,Max 从整个查询集生成统计值。比如,你想要计算所有在售书的平均价钱。Django的查询语法提供了一种方式描述所有
图书的集合。 >>> Book.objects.all().aggregate(Avg('price'))
{'price__avg': 34.35} aggregate()子句的参数描述了我们想要计算的聚合值,在这个例子中,是Book模型中price字段的平均值 aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的
标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定
一个名称,可以向聚合子句提供它:
>>> Book.objects.aggregate(average_price=Avg('price'))
{'average_price': 34.35} 如果你也想知道所有图书价格的最大值和最小值,可以这样查询:
>>> Book.objects.aggregate(Avg('price'), Max('price'), Min('price'))
{'price__avg': 34.35, 'price__max': Decimal('81.20'), 'price__min': Decimal('12.99')}
annotate(*args,**kwargs):
可以通过计算查询结果中每一个对象所关联的对象集合,从而得出总计值(也可以是平均值或总和),即为查询集的每一项生成聚合。
一般查询带每个内容的时候基本上都需要分组
查询alex出的书总价格

查询各个作者出的书的总价格,这里就涉及到分组了,分组条件是authors__name

查询各个出版社最便宜的书价是多少

F查询和Q查询
应用场景:当存在与或非查询的时候,单一查询就无法满足要求
仅仅靠单一的关键字参数查询已经很难满足查询要求。此时Django为我们提供了F和Q查询:
# F 使用查询条件的值,专门取对象中某列值的操作
# from django.db.models import F
# models.Tb1.objects.update(num=F('num')+1)
# Q 构建搜索条件
from django.db.models import Q
#1 Q对象(django.db.models.Q)可以对关键字参数进行封装,从而更好地应用多个查询
q1=models.Book.objects.filter(Q(title__startswith='P')).all()
print(q1)#[<Book: Python>, <Book: Perl>]
# 2、可以组合使用&,|操作符,当一个操作符是用于两个Q的对象,它产生一个新的Q对象。
Q(title__startswith='P') | Q(title__startswith='J')
# 3、Q对象可以用~操作符放在前面表示否定,也可允许否定与不否定形式的组合
Q(title__startswith='P') | ~Q(pub_date__year=2005)
# 4、应用范围:
# Each lookup function that takes keyword-arguments (e.g. filter(),
# exclude(), get()) can also be passed one or more Q objects as
# positional (not-named) arguments. If you provide multiple Q object
# arguments to a lookup function, the arguments will be “AND”ed
# together. For example:
Book.objects.get(
Q(title__startswith='P'),
Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6))
)
#sql:
# SELECT * from polls WHERE question LIKE 'P%'
# AND (pub_date = '2005-05-02' OR pub_date = '2005-05-06')
# import datetime
# e=datetime.date(2005,5,6) #2005-05-06
# 5、Q对象可以与关键字参数查询一起使用,不过一定要把Q对象放在关键字参数查询的前面。
# 正确:
Book.objects.get(
Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6)),
title__startswith='P')
# 错误:
Book.objects.get(
question__startswith='P',
Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6)))
update方法models对象不能调用update方法
mysql分组和orm分组对应关系:
二、ajax(重点)
什么是json?
定义:
JSON(JavaScript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式。
它基于 ECMAScript (w3c制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。
简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
讲json对象,不得不提到JS对象:
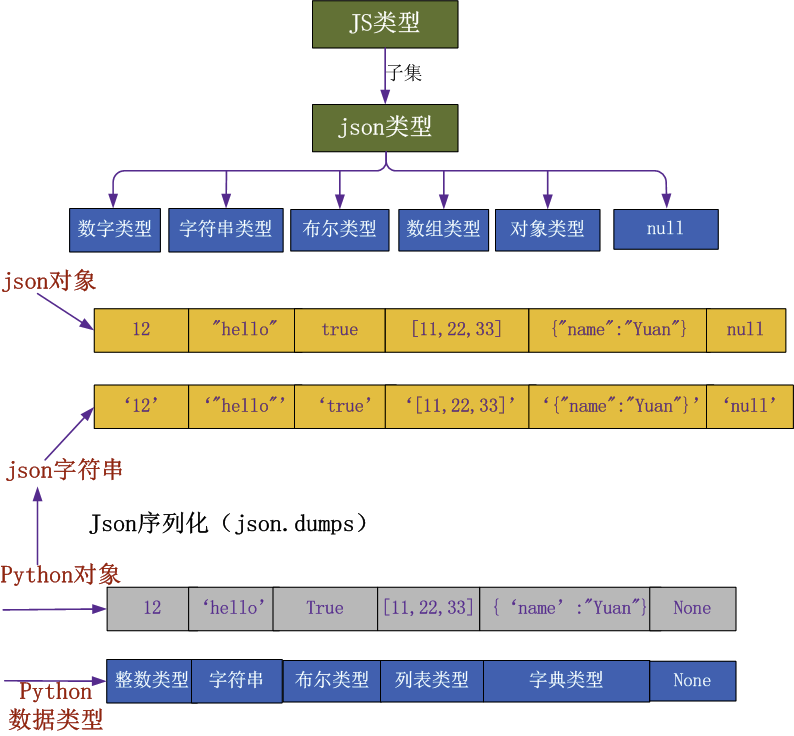
合格的json对象:
["one", "two", "three"]
{ "one": 1, "two": 2, "three": 3 }
{"names": ["张三", "李四"] }
[ { "name": "张三"}, {"name": "李四"} ]
不合格的json对象:
{ name: "张三", 'age': 32 } // 属性名必须使用双引号
[32, 64, 128, 0xFFF] // 不能使用十六进制值
{ "name": "张三", "age": undefined } // 不能使用undefined
{ "name": "张三",
"birthday": new Date('Fri, 26 Aug 2011 07:13:10 GMT'),
"getName": function() {return this.name;} // 不能使用函数和日期对象
}
****json不能使用单引号 '{"name":"alex","age":12}'
stringify与parse方法
JSON.parse(): 用于将一个 JSON 字符串转换为 JavaScript 对象
eg:
console.log(JSON.parse('{"name":"Yuan"}'));
console.log(JSON.parse('{name:"Yuan"}')) ; // 错误
console.log(JSON.parse('[12,undefined]')) ; // 错误 JSON.stringify(): 用于将 JavaScript 值转换为 JSON 字符串。
eg: console.log(JSON.stringify({'name':"egon"})) ;
和XML的比较
JSON 格式于2001年由 Douglas Crockford 提出,目的就是取代繁琐笨重的 XML 格式。
JSON 格式有两个显著的优点:书写简单,一目了然;符合 JavaScript 原生语法,可以由解释引擎直接处理,不用另外添加解析代码。所以,JSON迅速被接受,已经成为各大网站交换数据的标准格式,并被写入ECMAScript 5,成为标准的一部分。
XML和JSON都使用结构化方法来标记数据,下面来做一个简单的比较。
用XML表示中国部分省市数据如下:
<?xml version="1.0" encoding="utf-8"?>
<country>
<name>中国</name>
<province>
<name>黑龙江</name>
<cities>
<city>哈尔滨</city>
<city>大庆</city>
</cities>
</province>
<province>
<name>广东</name>
<cities>
<city>广州</city>
<city>深圳</city>
<city>珠海</city>
</cities>
</province>
<province>
<name>台湾</name>
<cities>
<city>台北</city>
<city>高雄</city>
</cities>
</province>
<province>
<name>新疆</name>
<cities>
<city>乌鲁木齐</city>
</cities>
</province>
</country>
用JSON表示如下:
{
"name": "中国",
"province": [{
"name": "黑龙江",
"cities": {
"city": ["哈尔滨", "大庆"]
}
}, {
"name": "广东",
"cities": {
"city": ["广州", "深圳", "珠海"]
}
}, {
"name": "台湾",
"cities": {
"city": ["台北", "高雄"]
}
}, {
"name": "新疆",
"cities": {
"city": ["乌鲁木齐"]
}
}]
}
可以看到,JSON 简单的语法格式和清晰的层次结构明显要比 XML 容易阅读,并且在数据交换方面,由于 JSON 所使用的字符要比 XML 少得多,可以大大得节约传输数据所占用得带宽。
注意:
数据交换
def login(request):
obj={'name':"alex111"}
return render(request,'index.html',{"objs":json.dumps(obj)})
#----------------------------------
<script>
var temp={{ objs|safe }}
alert(temp.name);
alert(temp['name'])
</script>
如果要通过js或者jquery给后端发送数据,那么就得用到ajax
ajax简介
AJAX(Asynchronous Javascript And XML)翻译成中文就是“异步Javascript和XML”。即使用Javascript语言与服务器进行异步交互,传输的数据为XML(当然,传输的数据不只是XML)。
- 同步交互:客户端发出一个请求后,需要等待服务器响应结束后,才能发出第二个请求;
- 异步交互:客户端发出一个请求后,无需等待服务器响应结束,就可以发出第二个请求。
AJAX除了异步的特点外,还有一个就是:浏览器页面局部刷新;(这一特点给用户的感受是在不知不觉中完成请求和响应过程)
js实现局部刷新:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title> <style>
.error{
color:red
}
</style>
</head>
<body> <form class="Form"> <p>姓名 <input class="v1" type="text" name="username" mark="用户名"></p>
<p>密码 <input class="v1" type="text" name="email" mark="邮箱"></p>
<p><input type="submit" value="submit"></p> </form> <script src="jquery-3.1.1.js"></script> <script> $(".Form :submit").click(function(){ flag=true; $("Form .v1").each(function(){ var value=$(this).val();
if (value.trim().length==0){
var mark=$(this).attr("mark");
var $span=$("<span>");
$span.html(mark+"不能为空!");
$span.prop("class","error");
$(this).after($span); setTimeout(function(){
$span.remove();
},800); flag=false;
return flag; }
});
return flag
}); </script> </body>
</html>
js实现局部刷新
AJAX常见应用情景
当我们在百度中输入一个“鲜花”字后,会马上出现一个下拉列表!列表中显示的是包含“传”字的4个关键字。
其实这里就使用了AJAX技术!当文件框发生了输入变化时,浏览器会使用AJAX技术向服务器发送一个请求,查询包含“传”字的前10个关键字,然后服务器会把查询到的结果响应给浏览器,最后浏览器把这4个关键字显示在下拉列表中。
- 整个过程中页面没有刷新,只是刷新页面中的局部位置而已!
- 当请求发出后,浏览器还可以进行其他操作,无需等待服务器的响应!

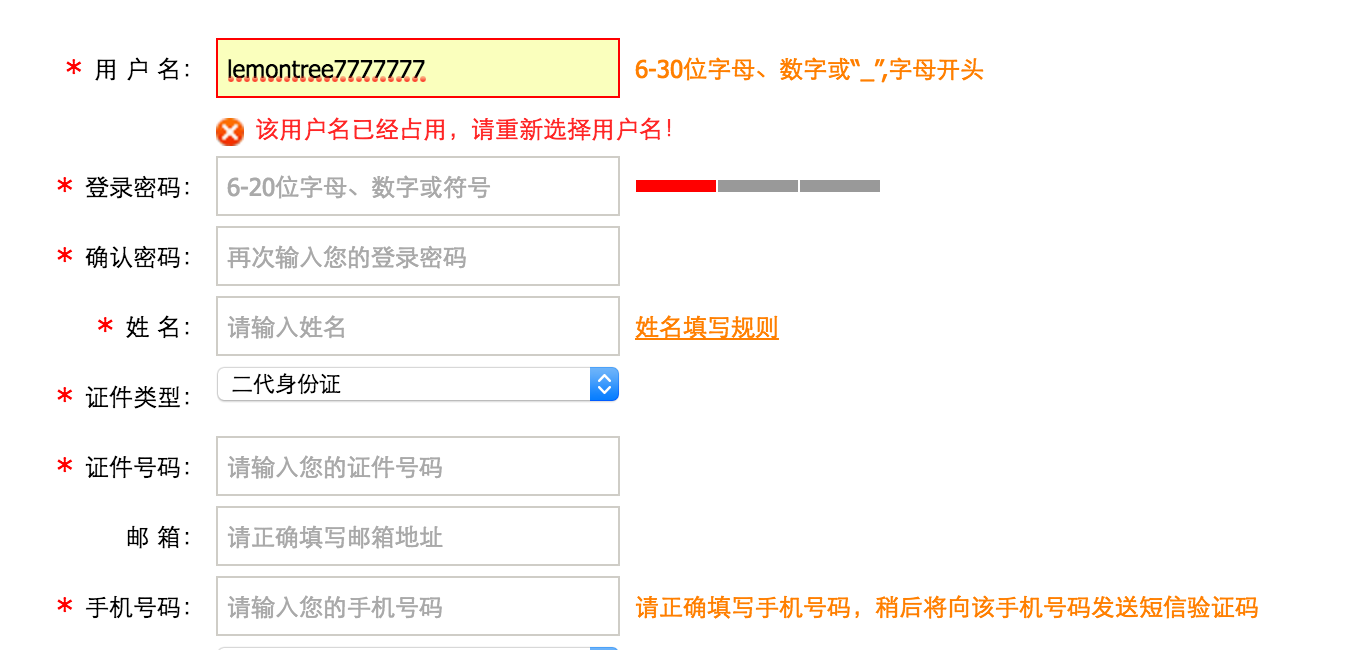
当输入用户名后,把光标移动到其他表单项上时,浏览器会使用AJAX技术向服务器发出请求,服务器会查询名为zhangSan的用户是否存在,最终服务器返回true表示名为lemontree7777777的用户已经存在了,浏览器在得到结果后显示“用户名已被注册!”。
- 整个过程中页面没有刷新,只是局部刷新了;
- 在请求发出后,浏览器不用等待服务器响应结果就可以进行其他操作;
ajax的优缺点:
优点:
- AJAX使用Javascript技术向服务器发送异步请求;
- AJAX无须刷新整个页面;
- 因为服务器响应内容不再是整个页面,而是页面中的局部,所以AJAX性能高;
缺点:
- AJAX并不适合所有场景,很多时候还是要使用同步交互;
- AJAX虽然提高了用户体验,但无形中向服务器发送的请求次数增多了,导致服务器压力增大;
- 因为AJAX是在浏览器中使用Javascript技术完成的,所以还需要处理浏览器兼容性问题;
一言以蔽之:不会Ajax,搞什么web,玩什么爬虫!
jquery实现ajax
{% load staticfiles %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script src="{% static 'JS/jquery-3.1.1.js' %}"></script>
</head>
<body>
<button class="send_Ajax">send_Ajax</button>
<script>
//$.ajax的两种使用方式:
//$.ajax(settings);
//$.ajax(url,[settings]);
$(".send_Ajax").click(function(){
$.ajax({
url:"/handle_Ajax/",
type:"POST",
data:{username:"Yuan",password:123},
dataType:"JSON" //这个地方定义了,就不需要手动解析json了
success:function(data){
alert(data)
},
//=================== error============
error: function (jqXHR, textStatus, err) {
// jqXHR: jQuery增强的xhr
// textStatus: 请求完成状态
// err: 底层通过throw抛出的异常对象,值与错误类型有关
console.log(arguments);
},
//=================== complete============
complete: function (jqXHR, textStatus) {
// jqXHR: jQuery增强的xhr
// textStatus: 请求完成状态 success | error
console.log('statusCode: %d, statusText: %s', jqXHR.status, jqXHR.statusText);
console.log('textStatus: %s', textStatus);
},
//=================== statusCode============
statusCode: {
'403': function (jqXHR, textStatus, err) {
console.log(arguments); //注意:后端模拟errror方式:HttpResponse.status_code=500
},
'400': function () {
}
}
})
})
</script>
</body>
</html>
import json
def index(request):
return render(request,"index.html")
def handle_Ajax(request):
username=request.POST.get("username")
password=request.POST.get("password")
print(username,password)
return HttpResponse(json.dumps("Error Data!"))
views
server端代码
$.ajax参数
######################------------data---------################
data: 当前ajax请求要携带的数据,是一个json的object对象,ajax方法就会默认地把它编码成某种格式
(urlencoded:?a=1&b=2)发送给服务端;此外,ajax默认以get方式发送请求。
function testData() {
$.ajax("/test",{ //此时的data是一个json形式的对象
data:{
a:1,
b:2
}
}); //?a=1&b=2
######################------------processData---------################
processData:声明当前的data数据是否进行转码或预处理,默认为true,即预处理;if为false,
那么对data:{a:1,b:2}会调用json对象的toString()方法,即{a:1,b:2}.toString()
,最后得到一个[object,Object]形式的结果。
######################------------contentType---------################
contentType:默认值: "application/x-www-form-urlencoded"。发送信息至服务器时内容编码类型。
用来指明当前请求的数据编码格式;urlencoded:?a=1&b=2;如果想以其他方式提交数据,
比如contentType:"application/json",即向服务器发送一个json字符串:
$.ajax("/ajax_get",{
data:JSON.stringify({
a:22,
b:33
}),
contentType:"application/json",
type:"POST",
}); //{a: 22, b: 33}
注意:contentType:"application/json"一旦设定,data必须是json字符串,不能是json对象
######################------------traditional---------################
traditional:一般是我们的data数据有数组时会用到 :data:{a:22,b:33,c:["x","y"]},
traditional为false会对数据进行深层次迭代;
响应参数:
/* dataType: 预期服务器返回的数据类型,服务器端返回的数据会根据这个值解析后,传递给回调函数。
默认不需要显性指定这个属性,ajax会根据服务器返回的content Type来进行转换;
比如我们的服务器响应的content Type为json格式,这时ajax方法就会对响应的内容
进行一个json格式的转换,if转换成功,我们在success的回调函数里就会得到一个json格式
的对象;转换失败就会触发error这个回调函数。如果我们明确地指定目标类型,就可以使用
data Type。
dataType的可用值:html|xml|json|text|script
见下dataType实例 */
例子:
from django.shortcuts import render,HttpResponse
from django.views.decorators.csrf import csrf_exempt #设置取消csrf保护
# Create your views here. import json def login(request): return render(request,'Ajax.html') def ajax_get(request): l=['alex','little alex']
dic={"name":"alex","pwd":123} #return HttpResponse(l) #元素直接转成字符串alexlittle alex
#return HttpResponse(dic) #字典的键直接转成字符串namepwd
return HttpResponse(json.dumps(l))
return HttpResponse(json.dumps(dic))# 传到前端的是json字符串,要想使用,需要JSON.parse(data) //---------------------------------------------------
function testData() { $.ajax('ajax_get', {
success: function (data) {
console.log(data);
console.log(typeof(data));
//console.log(data.name);
//JSON.parse(data);
//console.log(data.name);
},
//dataType:"json",
}
)} 注解:Response Headers的content Type为text/html,所以返回的是String;但如果我们想要一个json对象
设定dataType:"json"即可,相当于告诉ajax方法把服务器返回的数据转成json对象发送到前端.结果为object
当然,
return HttpResponse(json.dumps(a),content_type="application/json") 这样就不需要设定dataType:"json"了。
content_type="application/json"和content_type="json"是一样的!
csrf跨站请求伪造
$.ajaxSetup({
data: {csrfmiddlewaretoken: '{{ csrf_token }}' },
});
$(".sendAjax").click(function () {
$.ajaxSetup({
data: {csrfmiddlewaretoken: '{{ csrf_token }}' },
});
$.ajax({
url:"/sendAjax/",
type:"POST",
data:{"username":$("#user").val(),"password":$("#pwd").val()}, // data为一个json对象
success:function (data) {
//alert(data);
//alert(typeof data)
//dic=JSON.parse(data);
//alert(dic["name"])
dic=JSON.parse(data);
if (dic["flag"]){
alert("登陆成功!")
}
else {
alert("登录失败")
}
}
})
})
示例
js实现ajax
ajax核心(XMLHttpRequest)
其实AJAX就是在Javascript中多添加了一个对象:XMLHttpRequest对象。所有的异步交互都是使用XMLHttpServlet对象完成的。也就是说,我们只需要学习一个Javascript的新对象即可。
var xmlHttp = new XMLHttpRequest();(大多数浏览器都支持DOM2规范)
注意,各个浏览器对XMLHttpRequest的支持也是不同的!为了处理浏览器兼容问题,给出下面方法来创建XMLHttpRequest对象:
function createXMLHttpRequest() {
var xmlHttp;
// 适用于大多数浏览器,以及IE7和IE更高版本
try{
xmlHttp = new XMLHttpRequest();
} catch (e) {
// 适用于IE6
try {
xmlHttp = new ActiveXObject("Msxml2.XMLHTTP");
} catch (e) {
// 适用于IE5.5,以及IE更早版本
try{
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
} catch (e){}
}
}
return xmlHttp;
}
解决方法
使用流程
步骤1: 打开与服务器的连接(open方法)
当得到XMLHttpRequest对象后,就可以调用该对象的open()方法打开与服务器的连接了。open()方法的参数如下:
open(method, url, async):
- method:请求方式,通常为GET或POST;
- url:请求的服务器地址,例如:/ajaxdemo1/AServlet,若为GET请求,还可以在URL后追加参数;
- async:这个参数可以不给,默认值为true,表示异步请求;
var xmlHttp = createXMLHttpRequest();
xmlHttp.open("GET", "/ajax_get/", true);
步骤2: 发送请求
当使用open打开连接后,就可以调用XMLHttpRequest对象的send()方法发送请求了。send()方法的参数为POST请求参数,即对应HTTP协议的请求体内容,若是GET请求,需要在URL后连接参数。
注意:若没有参数,需要给出null为参数!若不给出null为参数,可能会导致FireFox浏览器不能正常发送请求!
xmlHttp.send(null);
步骤3: 接收服务器响应
当请求发送出去后,服务器端就开始执行了,但服务器端的响应还没有接收到。接下来我们来接收服务器的响应。
XMLHttpRequest对象有一个onreadystatechange事件,它会在XMLHttpRequest对象的状态发生变化时被调用。下面介绍一下XMLHttpRequest对象的5种状态:
- 0:初始化未完成状态,只是创建了XMLHttpRequest对象,还未调用open()方法;
- 1:请求已开始,open()方法已调用,但还没调用send()方法;
- 2:请求发送完成状态,send()方法已调用;
- 3:开始读取服务器响应;
- 4:读取服务器响应结束。
onreadystatechange事件会在状态为1、2、3、4时引发。
下面代码会被执行四次!对应XMLHttpRequest的四种状态!
xmlHttp.onreadystatechange = function() {
alert('hello');
};
但通常我们只关心最后一种状态,即读取服务器响应结束时,客户端才会做出改变。我们可以通过XMLHttpRequest对象的readyState属性来得到XMLHttpRequest对象的状态。
xmlHttp.onreadystatechange = function() {
if(xmlHttp.readyState == 4) {
alert('hello');
}
};
其实我们还要关心服务器响应的状态码是否为200,其服务器响应为404,或500,那么就表示请求失败了。我们可以通过XMLHttpRequest对象的status属性得到服务器的状态码。
最后,我们还需要获取到服务器响应的内容,可以通过XMLHttpRequest对象的responseText得到服务器响应内容。
xmlHttp.onreadystatechange = function() {
if(xmlHttp.readyState == 4 && xmlHttp.status == 200) {
alert(xmlHttp.responseText);
}
};
if 发送POST请求
<1>需要设置请求头:xmlHttp.setRequestHeader(“Content-Type”, “application/x-www-form-urlencoded”);注意 :form表单会默认这个键值对不设定,Web服务器会忽略请求体的内容。
<2>在发送时可以指定请求体了:xmlHttp.send(“username=yuan&password=123”)
js实现ajax小结:
/*
创建XMLHttpRequest对象;
调用open()方法打开与服务器的连接;
调用send()方法发送请求;
为XMLHttpRequest对象指定onreadystatechange事件函数,这个函数会在 XMLHttpRequest的1、2、3、4,四种状态时被调用; XMLHttpRequest对象的5种状态,通常我们只关心4状态。 XMLHttpRequest对象的status属性表示服务器状态码,它只有在readyState为4时才能获取到。 XMLHttpRequest对象的responseText属性表示服务器响应内容,它只有在
readyState为4时才能获取到! */
测试代码:
<h1>AJAX</h1>
<button onclick="send()">测试</button>
<div id="div1"></div> <script>
function createXMLHttpRequest() {
try {
return new XMLHttpRequest();//大多数浏览器
} catch (e) {
try {
return new ActiveXObject("Msxml2.XMLHTTP");
} catch (e) {
return new ActiveXObject("Microsoft.XMLHTTP");
}
}
} function send() {
var xmlHttp = createXMLHttpRequest();
xmlHttp.onreadystatechange = function() {
if(xmlHttp.readyState == 4 && xmlHttp.status == 200) {
var div = document.getElementById("div1");
div.innerText = xmlHttp.responseText;
div.textContent = xmlHttp.responseText;
}
}; xmlHttp.open("POST", "/ajax_post/", true);
//post: xmlHttp.setRequestHeader("Content-Type", "application/x-www-form-urlencoded");
xmlHttp.send(null); //post: xmlHttp.send("b=B");
} </script> #--------------------------------views.py
from django.views.decorators.csrf import csrf_exempt def login(request):
print('hello ajax')
return render(request,'index.html') @csrf_exempt #csrf防御
def ajax_post(request):
print('ok')
return HttpResponse('helloyuanhao')
测试代码
实例(用户名是否已被注册)
1、功能介绍
在注册表单中,当用户填写了用户名后,把光标移开后,会自动向服务器发送异步请求。服务器返回true或false,返回true表示这个用户名已经被注册过,返回false表示没有注册过。
客户端得到服务器返回的结果后,确定是否在用户名文本框后显示“用户名已被注册”的错误信息!
2、案例分析
- 页面中给出注册表单;
- 在username表单字段中添加onblur事件,调用send()方法;
- send()方法获取username表单字段的内容,向服务器发送异步请求,参数为username;
- django 的视图函数:获取username参数,判断是否为“yuan”,如果是响应true,否则响应false
3、参考代码:
<script type="text/javascript">
function createXMLHttpRequest() {
try {
return new XMLHttpRequest();
} catch (e) {
try {
return new ActiveXObject("Msxml2.XMLHTTP");
} catch (e) {
return new ActiveXObject("Microsoft.XMLHTTP");
}
}
} function send() {
var xmlHttp = createXMLHttpRequest();
xmlHttp.onreadystatechange = function() {
if(xmlHttp.readyState == 4 && xmlHttp.status == 200) {
if(xmlHttp.responseText == "true") {
document.getElementById("error").innerText = "用户名已被注册!";
document.getElementById("error").textContent = "用户名已被注册!";
} else {
document.getElementById("error").innerText = "";
document.getElementById("error").textContent = "";
}
}
};
xmlHttp.open("POST", "/ajax_check/", true, "json");
xmlHttp.setRequestHeader("Content-Type", "application/x-www-form-urlencoded");
var username = document.getElementById("username").value;
xmlHttp.send("username=" + username);
}
</script> //--------------------------------------------------index.html <h1>注册</h1>
<form action="" method="post">
用户名:<input id="username" type="text" name="username" onblur="send()"/><span id="error"></span><br/>
密 码:<input type="text" name="password"/><br/>
<input type="submit" value="注册"/>
</form> //--------------------------------------------------views.py
from django.views.decorators.csrf import csrf_exempt def login(request):
print('hello ajax')
return render(request,'index.html')
# return HttpResponse('helloyuanhao') @csrf_exempt
def ajax_check(request):
print('ok') username=request.POST.get('username',None)
if username=='yuan':
return HttpResponse('true')
return HttpResponse('false')
三、分页器paginator
分页器的使用
>>> from django.core.paginator import Paginator
>>> objects = ['john', 'paul', 'george', 'ringo']
>>> p = Paginator(objects, 2) >>> p.count #数据总数
4
>>> p.num_pages #总页数
2
>>> type(p.page_range) # `<type 'rangeiterator'>` in Python 2.
<class 'range_iterator'>
>>> p.page_range #页码的列表
range(1, 3) # =========[1,2] >>> page1 = p.page(1) #第1页的page对象
>>> page1
<Page 1 of 2>
>>> page1.object_list #第1页的数据
['john', 'paul'] >>> page2 = p.page(2)
>>> page2.object_list #第2页的数据
['george', 'ringo']
>>> page2.has_next() #是否有下一页
False
>>> page2.has_previous() #是否有上一页
True
>>> page2.has_other_pages() #是否有其他页
True
>>> page2.next_page_number() #下一页的页码
Traceback (most recent call last):
...
EmptyPage: That page contains no results
>>> page2.previous_page_number() #上一页的页码
1
>>> page2.start_index() # 本页第一条记录的序数(从1开始)
3
>>> page2.end_index() # 本页最后录一条记录的序数(从1开始)
4 >>> p.page(0) #错误的页,抛出异常
Traceback (most recent call last):
...
EmptyPage: That page number is less than 1
>>> p.page(3) #错误的页,抛出异常
Traceback (most recent call last):
...
EmptyPage: That page contains no results
实现一个分页的效果:
Template:
{% load staticfiles %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<link rel="stylesheet" href="{% static 'bootstrap.css' %}">
</head>
<body>
<div class="container">
<h4>分页器</h4>
<ul>
{% for book in book_list %}
<li>{{ book.title }} {{ book.price }}</li>
{% endfor %}
</ul>
<ul class="pagination" id="pager">
{% if book_list.has_previous %}
<li class="previous"><a href="/blog/?page={{ book_list.previous_page_number }}">上一页</a></li>
{% else %}
<li class="previous disabled"><a href="#">上一页</a></li>
{% endif %}
{% for num in paginator.page_range %}
{% if num == currentPage %}
<li class="item active"><a href="/blog/?page={{ num }}">{{ num }}</a></li>
{% else %}
<li class="item"><a href="/blog/?page={{ num }}">{{ num }}</a></li>
{% endif %}
{% endfor %}
{% if book_list.has_next %}
<li class="next"><a href="/blog/?page={{ book_list.next_page_number }}">下一页</a></li>
{% else %}
<li class="next disabled"><a href="#">下一页</a></li>
{% endif %}
</ul>
</div>
</body>
</html>
View:
from django.shortcuts import render,HttpResponse # Create your views here.
from django.core.paginator import Paginator, EmptyPage, PageNotAnInteger from app01.models import *
def index(request): '''
批量导入数据: Booklist=[]
for i in range(100):
Booklist.append(Book(title="book"+str(i),price=30+i*i))
Book.objects.bulk_create(Booklist) #bulk_create批量导入数据 ''' book_list=Book.objects.all() paginator = Paginator(book_list, 10)
page = request.GET.get('page',1)
currentPage=int(page) try:
print(page)
book_list = paginator.page(page)
except PageNotAnInteger:
book_list = paginator.page(1)
except EmptyPage:
book_list = paginator.page(paginator.num_pages) return render(request,"index.html",locals())
自定义分页(适用所有框架)
将分页包装成一个类,供别人调用
view:
from utils.page import PageInfo #导入模块 def users2(request):
all_count = models.UserInfo.objects.all().count() #生成总数 page_info = PageInfo(request.GET.get('p'),10,all_count,request.path_info) #实例化对象 user_list = models.UserInfo.objects.all()[page_info.start():page_info.end()] #截取用户列表 return render(request,'users2.html',{'user_list':user_list,'page_info': page_info})
PageInfo自定义模块:
"""
使用方式:
all_count = models.UserInfo.objects.all().count() page_info = PageInfo(request.GET.get('p'),10,all_count,request.path_info) user_list = models.UserInfo.objects.all()[page_info.start():page_info.end()] """ class PageInfo(object):
def __init__(self,current_page,per_page_num,all_count,base_url,page_range=11):
"""
:param current_page: 当前页
:param per_page_num: 每页显示数据条数
:param all_count: 数据库总个数
:param base_url: 页码标签的前缀
:param page_range: 页面最多显示的页码个数
"""
try:
current_page = int(current_page)
except Exception as e:
current_page = int(1)
self.current_page = current_page
self.per_page_num = per_page_num
self.all_count = all_count
a,b = divmod(all_count,per_page_num)
if b != 0:
self.all_page = a + 1
else:
self.all_page = a
self.base_url = base_url
self.page_range = page_range def start(self):
return (self.current_page - 1) * self.per_page_num def end(self):
return self.current_page * self.per_page_num def page_str(self):
"""
在HTML页面中显示页码信息
:return:
"""
page_list = [] if self.current_page <=1:
prev = '<li><a href="#">上一页</a></li>'
else:
prev = '<li><a href="%s?p=%s">上一页</a></li>' %(self.base_url,self.current_page-1,)
page_list.append(prev) # 总页数只有8页 小于page_range的数量,这样就显示当前一段页数
if self.all_page <= self.page_range:
start = 1
end = self.all_page + 1
else:
# 页数 18
if self.current_page > int(self.page_range/2):
# 当前页: 6,7,8,,9,100
if (self.current_page + int(self.page_range/2)) > self.all_page:
start = self.all_page - self.page_range + 1
end = self.all_page + 1
else:
start = self.current_page - int(self.page_range/2)
end = self.current_page + int(self.page_range/2) + 1
else:
# 当前页: 1,2,3,4,5,
start = 1
end = self.page_range + 1
for i in range(start,end):
if self.current_page == i:
temp = '<li class="active"><a href="%s?p=%s">%s</a></li>' %(self.base_url,i,i,)
else:
temp = '<li><a href="%s?p=%s">%s</a></li>' % (self.base_url, i, i,)
page_list.append(temp) if self.current_page >= self.all_page:
nex = '<li><a href="#">下一页</a></li>'
else:
nex = '<li><a href="%s?p=%s">下一页</a></li>' % (self.base_url,self.current_page + 1,)
page_list.append(nex) return "".join(page_list)
template:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<link rel="stylesheet" href="/static/bootstrap/css/bootstrap.css" />
</head>
<body>
<div style="width: 700px;margin: 0 auto;">
<h1>用户列表</h1>
<table class="table table-hover table-bordered">
<thead>
<tr>
<th>用户名</th>
<th>密码</th>
<th>邮箱</th>
</tr>
</thead>
<tbody>
{% for row in user_list %}
<tr>
<td>{{ row.username }}</td>
<td>{{ row.password }}</td>
<td>{{ row.email }}</td>
</tr>
{% endfor %}
</tbody>
</table>
</div>
<div>
<nav aria-label="...">
<ul class="pagination">
{{ page_info.page_str|safe }} </ul>
</nav> </div>
</body>
</html>
python自动化开发-[第十八天]-django的ORM补充与ajax,分页器的更多相关文章
- python自动化开发学习 进程, 线程, 协程
python自动化开发学习 进程, 线程, 协程 前言 在过去单核CPU也可以执行多任务,操作系统轮流让各个任务交替执行,任务1执行0.01秒,切换任务2,任务2执行0.01秒,在切换到任务3,这 ...
- python自动化开发学习 I/O多路复用
python自动化开发学习 I/O多路复用 一. 简介 socketserver在内部是由I/O多路复用,多线程和多进程,实现了并发通信.IO多路复用的系统消耗很小. IO多路复用底层就是监听so ...
- Django的ORM补充
Django的ORM补充 参考文档:https://www.cnblogs.com/wupeiqi/articles/6216618.html 1.查询性能补充 1.1 select_related ...
- Python自动化开发 - Django【基础篇】
Python的WEB框架有Django.Tornado.Flask 等多种,Django相较与其他WEB框架其优势为: 大而全,框架本身集成了ORM.模型绑定.模板引擎.缓存.Session等诸多功能 ...
- python的Web框架,Django的ORM,模型基础,MySQL连接配置及增删改查
Django中的ORM简介 ORM概念:对象关系映射(Object Relational Mapping,简称ORM): 用面向对象的方式描述数据库,去操作数据库,甚至可以达到不用编写SQL语句就能够 ...
- python自动化开发-[第十七天]-django的ORM与其他
今日概要: 1.name别名 2.模版的深度查询 3.模版语言之filter 4.自定义过滤器,filter和simpletag的区别 5.orm进阶 扫盲:url的组成 URL:协议+域名+端口+路 ...
- python自动化开发-[第十六天]-bootstrap和django
今日概要: 1.bootstrap使用 2.栅格系统 3.orm简介 4.路由系统 5.mvc和mtv模式 6.django框架 1.bootstrap的引用方式 1.Bootstrap 专门构建了免 ...
- Python自动化开发 - Django【进阶篇】
Model 到目前为止,当我们的程序涉及到数据库相关操作时,我们一般都会这么搞: 创建数据库,设计表结构和字段 使用 MySQLdb 来连接数据库,并编写数据访问层代码 业务逻辑层去调用数据访问层执行 ...
- Python自动化开发 - Django基础
本节内容 一.什么是web框架 二.MVC和MTV视图 三.Django基本命令 四.路由配置系统 五.编写视图 六.Template 七.ORM 一.什么是web框架 对于所有的web应用,本质上其 ...
随机推荐
- Nginx 优化缓冲区与传输效率
L:126 这里简单的做个计算 比如 我的服务器带宽是 5M=41943040字节 如果按照公网用PIND的得到延迟结果 icmp_seq=3 ttl=49 time=35.612 ms BDP = ...
- StringBuffer作为参数传递的问题
public class Foo {2. public static void main (String [] args) {3. StringBuffer a = new Strin ...
- Codeforces Round #507 Div. 1
D:类似于noip2018d1t3,子树内的链应该贪心的尽量合并而不是拆开.则设f[i]为i子树内满足选的链尽量多的情况下根所在的链的最长长度即可.于是可以线性对某个k求得答案. 注意到长度为k的链不 ...
- Mail.Ru Cup 2018 Round 3
A:签到 #include<iostream> #include<cstdio> #include<cmath> #include<cstdlib> # ...
- python_getpass 模块的使用
可以实现输入用户密码的时候隐藏输入显示.更加安全. 默认自带Password: 的提示 如果自己指定提示内容就用自己的替换默认 import getpass passwd = getpass.getp ...
- MT【307】周期数列
(2017浙江省数学竞赛) 设数列$\{a_n\}$满足:$|a_{n+1}-2a_n|=2,|a_n|\le2,n\in N^+$证明:如果$a_1$为有理数,则从某项后$\{a_n\}$为周期数列 ...
- iptables防火墙详解(三)
linux 高级路由 策略路由(mangle表) lartc(linux advanced routing and traffic control) http://www.lartc.org # rp ...
- 20165223 实验四 Android开发基础
实验四 Android开发基础 目录 一.实验报告封面 二.具体实验内容 (一)Android Stuidio的安装测试 (二)Activity测试 (三)UI测试 (四)布局测试 (五)教材代码测试 ...
- 构造器引用和直接用new创建对象区别
万事用事实说话 package cn.lonecloud; /** * @author lonecloud * @version v1.0 * @date 上午11:22 2018/4/30 */ p ...
- Spring Boot 1.X和2.X优雅重启实战
纯洁的微笑 今天 项目在重新发布的过程中,如果有的请求时间比较长,还没执行完成,此时重启的话就会导致请求中断,影响业务功能,优雅重启可以保证在停止的时候,不接收外部的新的请求,等待未完成的请求执行完成 ...