[转帖]Huge Page 是否是拯救性能的万能良药?
Huge Page 是否是拯救性能的万能良药?
本文将分析是否Huge Page在任何条件下(特别是NUMA架构下)都能带来性能提升。
文章欢迎转载,但转载时请保留本段文字,并置于文章的顶部 作者:卢钧轶(cenalulu) 本文原文地址:http://cenalulu.github.io/linux/huge-page-on-numa/
准备知识
在阅读本文之前,需要读者至少了解以下基础知识
- CPU Cache的基本概念,具体可参见 关于CPU Cache – 程序猿需要知道的那些事。
- NUMA的基本概念,具体可参见博客之前的科普介绍
- 目前Linux基于多核CPU繁忙程度的线程调度机制,参看
Chip Multi Processing aware Linux Kernel Scheduler论文
关于Huge Page
在正式开始本文分析前,我们先大概介绍下Huge Page的历史背景和使用场景。
为什么需要Huge Page 了解CPU Cache大致架构的话,一定听过TLB Cache。Linux系统中,对程序可见的,可使用的内存地址是Virtual Address。每个程序的内存地址都是从0开始的。而实际的数据访问是要通过Physical Address进行的。因此,每次内存操作,CPU都需要从page table中把Virtual Address翻译成对应的Physical Address,那么对于大量内存密集型程序来说page table的查找就会成为程序的瓶颈。所以现代CPU中就出现了TLB(Translation Lookaside Buffer) Cache用于缓存少量热点内存地址的mapping关系。然而由于制造成本和工艺的限制,响应时间需要控制在CPU Cycle级别的Cache容量只能存储几十个对象。那么TLB Cache在应对大量热点数据Virual Address转换的时候就显得捉襟见肘了。我们来算下按照标准的Linux页大小(page size) 4K,一个能缓存64元素的TLB Cache只能涵盖4K*64 = 256K的热点数据的内存地址,显然离理想非常遥远的。于是Huge Page就产生了。 Tips: 这里不要把Virutal Address和Windows上的虚拟内存搞混了。后者是为了应对物理内存不足,而将内容从内存换出到其他设备的技术(类似于Linux的SWAP机制)。
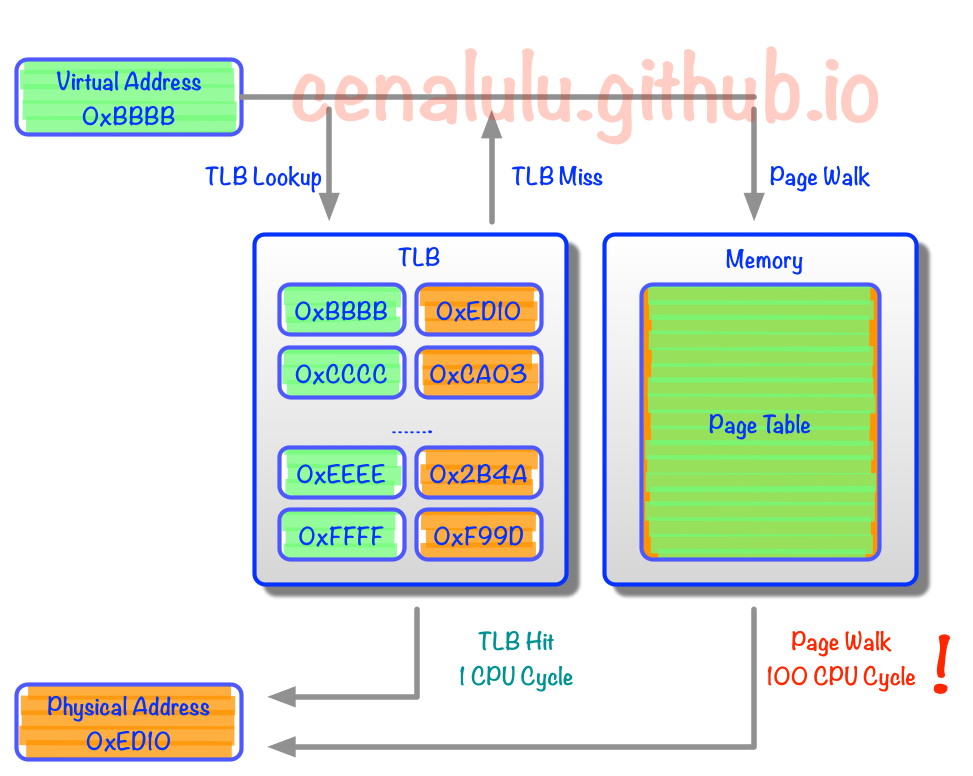
什么是Huge Page 既然改变不了TLB Cache的容量,那么只能从系统层面增加一个TLB Cache entry所能对应的物理内存大小,从而增加TLB Cache所能涵盖的热点内存数据量。假设我们把Linux Page Size增加到16M,那么同样一个容纳64个元素的TLB Cache就能顾及64*16M = 1G的内存热点数据,这样的大小相较上文的256K就显得非常适合实际应用了。像这种将Page Size加大的技术就是Huge Page。
Huge Page是万能的?
了解了Huge Page的由来和原理后,我们不难总结出能从Huge Page受益的程序必然是那些热点数据分散且至少超过64个4K Page Size的程序。此外,如果程序的主要运行时间并不是消耗在TLB Cache Miss后的Page Table Lookup上,那么TLB再怎么大,Page Size再怎么增加都是徒劳。在LWN的一篇入门介绍中就提到了这个原理,并且给出了比较详细的估算方法。简单的说就是:先通过oprofile抓取到TLB Miss导致的运行时间占程序总运行时间的多少,来计算出Huge Page所能带来的预期性能提升。 简单的说,我们的程序如果热点数据只有256K,并且集中在连续的内存page上,那么一个64个entry的TLB Cache就足以应付了。说道这里,大家可能有个疑问了:既然我们比较难预测自己的程序访问逻辑是否能从开启Huge Page中受益。反正Huge Page看上去只改了一个Page Size,不会有什么性能损失。那么我们就索性对所有程序都是用Huge Page好啦。 其实这样的想法是完全错误的!也正是本文想要介绍的一个主要内容,在目前常见的NUMA体系下Huge Page也并非万能钥匙,使用不当甚至会使得程序或者数据库性能下降10%。下面我们重点分析。
Huge Page on NUMA
Large Pages May Be Harmful on NUMA Systems一文的作者曾今做过一个实验,测试Huge Page在NUMA环境的各种不同应用场景下带来的性能差异。从下图可以看到Huge Page对于相当一部分的应用场景并不能很好的提升性能,甚至会带来高达10%的性能损耗。 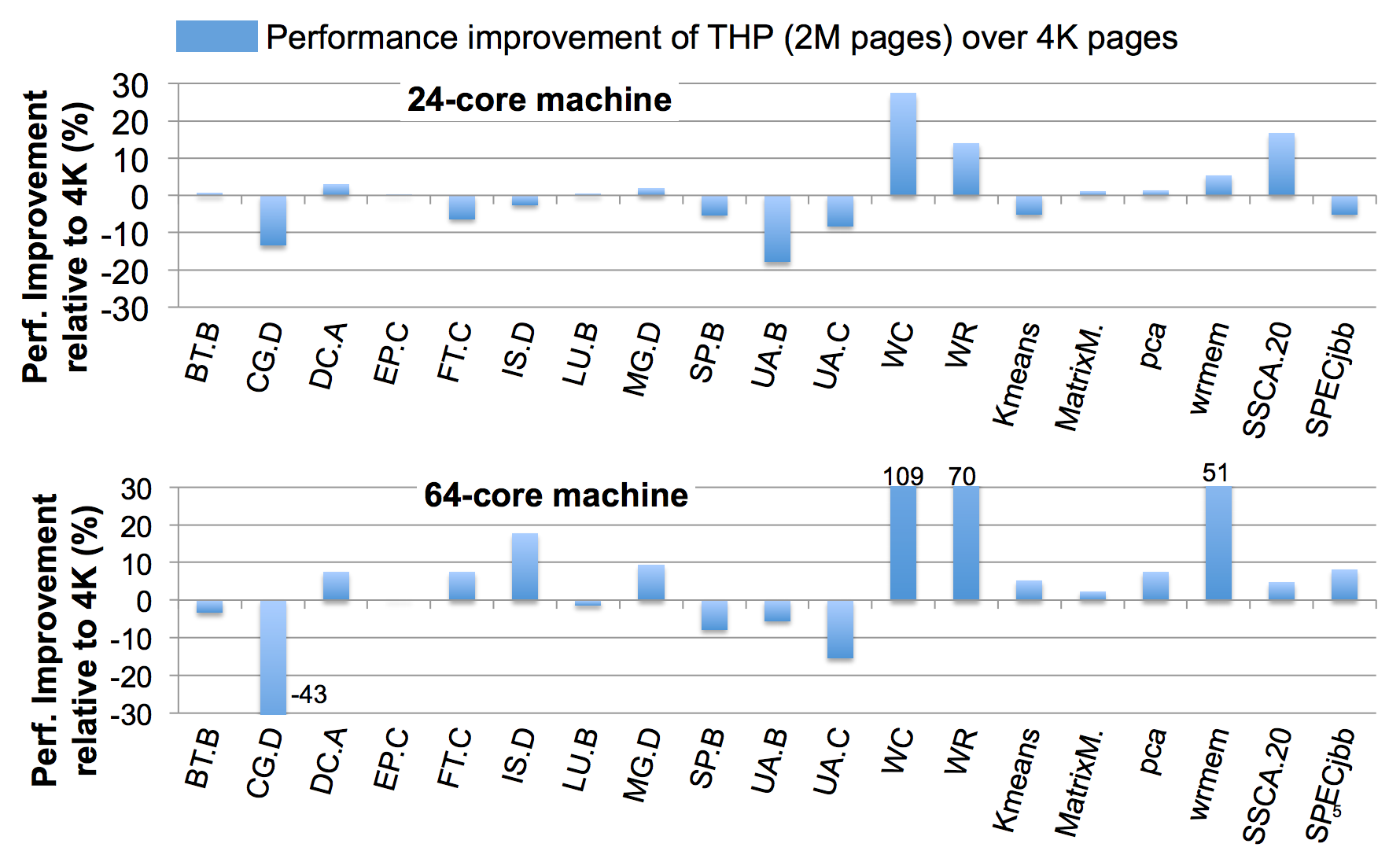
性能下降的原因主要有以下两点
CPU对同一个Page抢占增多
对于写操作密集型的应用,Huge Page会大大增加Cache写冲突的发生概率。由于CPU独立Cache部分的写一致性用的是MESI协议,写冲突就意味:
- 通过CPU间的总线进行通讯,造成总线繁忙
- 同时也降低了CPU执行效率。
- CPU本地Cache频繁失效
类比到数据库就相当于,原来一把用来保护10行数据的锁,现在用来锁1000行数据了。必然这把锁在线程之间的争抢概率要大大增加。
连续数据需要跨CPU读取(False Sharing)
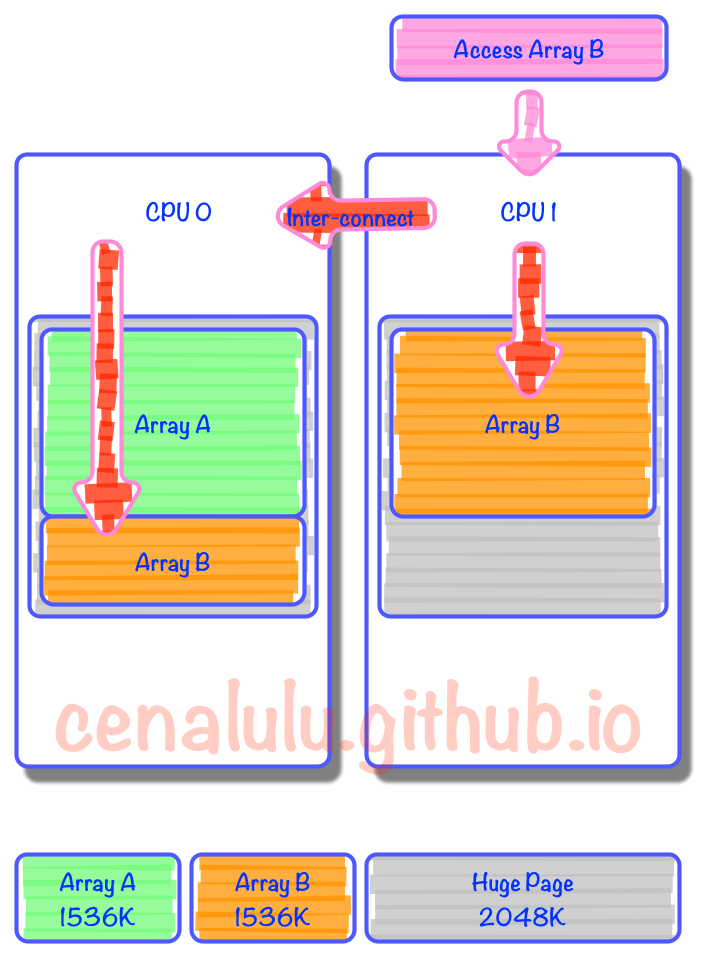
从下图我们可以看到,原本在4K小页上可以连续分配,并因为较高命中率而在同一个CPU上实现locality的数据。到了Huge Page的情况下,就有一部分数据为了填充统一程序中上次内存分配留下的空间,而被迫分布在了两个页上。而在所在Huge Page中占比较小的那部分数据,由于在计算CPU亲和力的时候权重小,自然就被附着到了其他CPU上。那么就会造成:本该以热点形式存在于CPU2 L1或者L2 Cache上的数据,不得不通过CPU inter-connect去remote CPU获取数据。 假设我们连续申明两个数组,Array A和Array B大小都是1536K。内存分配时由于第一个Page的2M没有用满,因此Array B就被拆成了两份,分割在了两个Page里。而由于内存的亲和配置,一个分配在Zone 0,而另一个在Zone 1。那么当某个线程需要访问Array B时就不得不通过代价较大的Inter-Connect去获取另外一部分数据。
delays re-sulting from traversing a greater physical distance to reach a remote node, are not the most important source of performance overhead. On the other hand, congestion on interconnect links and in memory controllers, which results from high volume of data flowing across the system, can dramatically hurt performance.
Under interleaving, the memory latency re- duces by a factor of 2.48 for Streamcluster and 1.39 for PCA. This effect is entirely responsible for performance improvement under the better policy. The question is, what is responsible for memory latency improvements? It turns out that interleaving dramatically reduces memory controller and interconnect congestion by allevi- ating the load imbalance and mitigating traffic hotspots.
对策
理想
我们先谈谈理想情况。上文提到的论文其实他的主要目的就是讨论一种适用于NUMA架构的Huge Page自动内存管理策略。这个管理策略简单的说是基于Carrefour的一种对Huge Page优化的变种。(注:不熟悉什么是Carrefour的读者可以参看博客之前的科普介绍或者阅读原文) 下面是一些相关技术手段的简要概括:
- 为了减少只读热点数据跨NUMA Zone的访问,可以将读写比非常高的Page,使用Replication的方式在每个NUMA Zone的Direct内存中都复制一个副本,降低响应时间。
- 为了减少
False Sharing,监控造成大量Cache Miss的Page,并进行拆分重组。将同一CPU亲和的数据放在同一个Page中
现实
谈完了理想,我们看看现实。现实往往是残酷的,由于没有硬件级别的PMU(Performance Monitor Unit)支持,获取精准的Page访问和Cache Miss信息性能代价非常大。所以上面的理想仅仅停留在实验和论文阶段。那么在理想实现之前,我们现在该怎么办呢? 答案只有一个就是测试
实际测试 实际测试的结果最具有说服力。所谓实际测试就是把优化对象给予真实环境的压力模拟。通过对比开启和关闭Huge Page时的性能差别来验证Huge Page是否会带来性能提升。当然大多数应用程序,要想模拟真实环境下的运行情况是非常困难的。那么我们就可以用下面这种理论测试
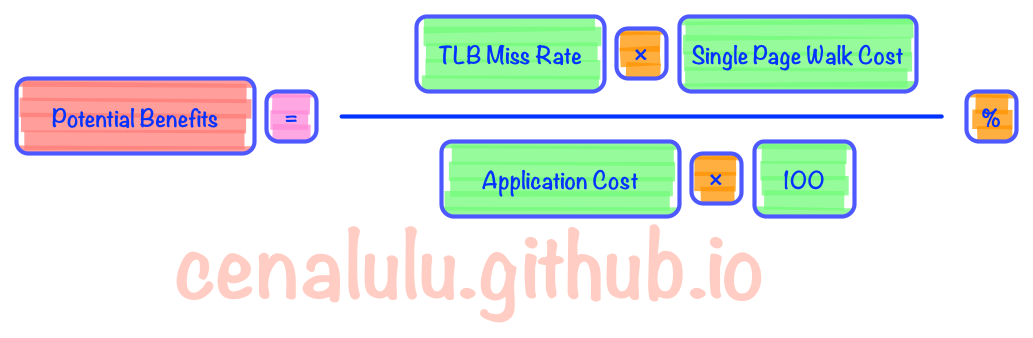
理论测试 理论测试可以通过profile预估出Huge Page能够带来的潜在提升。具体原理就是计算当前应用程序运行时TLB Miss导致的Page Walk成本占程序总执行时间的占比。当然这种测试方式没有把上文提到的那两种性能损失考虑进去,所以只能用于计算Huge Page所能带来的潜在性能提升的上限。如果计算出来这个值非常低,那么可以认为使用Huge Page则会带来额外的性能损失。具体方法见LWN上介绍的方法 具体的计算公式如下图:
如果没有hardware的PMU支持的话,计算需要用到oprofile和calibrator。
总结
并不是所有的优化方案都是0性能损失的。充分的测试和对于优化原理的理解是一个成功优化的前提条件。
Reference
[转帖]Huge Page 是否是拯救性能的万能良药?的更多相关文章
- Huge Page 是否是拯救性能的万能良药?
本文将分析是否Huge Page在任何条件下(特别是NUMA架构下)都能带来性能提升. 本博客已经迁移至: http://cenalulu.github.io/ 为了更好的体验,请通过此链接阅读: h ...
- huge page 能给MySQL 带来性能提升吗?
最近一直在做性能压测相关的事情,有公众号的读者朋友咨询有赞的数据库服务器有没有开启huge page,我听说过huge page会对性能有所提升,本文就一探究竟.对过程没有兴趣的可以直接看结论. 二 ...
- Linux就这个范儿 第15章 七种武器 linux 同步IO: sync、fsync与fdatasync Linux中的内存大页面huge page/large page David Cutler Linux读写内存数据的三种方式
Linux就这个范儿 第15章 七种武器 linux 同步IO: sync.fsync与fdatasync Linux中的内存大页面huge page/large page David Cut ...
- 大页(Huge Page)简单介绍
x86(包括x86-32和x86-64)架构的CPU默认使用4KB大小的内存页面(getconf PAGESIZE),但是它们也支持较大的内存页,如x86-64系统就支持2MB大小的大页(huge p ...
- [转帖]为什么HikariCP被号称为性能最好的Java数据库连接池,如何配置使用
为什么HikariCP被号称为性能最好的Java数据库连接池,如何配置使用 原创Clement-Xu 发布于2015-07-17 15:53:14 阅读数 57066 收藏 展开 HiKariCP是 ...
- 【转帖】编译-O 选项对性能提升作用
编译-O 选项对性能提升作用 https://www.cnblogs.com/pigerhan/p/3526889.html GCC -O 选项 这个选项控制所有的优化等级.使用优化选项会使编译过程耗 ...
- [转帖]功耗降50%,性能升35%!三星3nm GAA 2021年量产
功耗降50%,性能升35%!三星3nm GAA 2021年量产 http://www.chinaflashmarket.com/Instructor 在三星晶圆代工技术论坛(Samsung Found ...
- [转帖]当 K8s 集群达到万级规模,阿里巴巴如何解决系统各组件性能问题?
改天学习一下. https://www.cnblogs.com/alisystemsoftware/p/11570806.html 当 K8s 集群达到万级规模,阿里巴巴如何解决系统各组件性能问题 ...
- [转帖]NUMA架构的CPU -- 你真的用好了么?
NUMA架构的CPU -- 你真的用好了么? 本文从NUMA的介绍引出常见的NUMA使用中的陷阱,继而讨论对于NUMA系统的优化方法和一些值得关注的方向. 文章欢迎转载,但转载时请保留本段文字,并置于 ...
随机推荐
- nodejs前后分离
proxy: { '/api': { target: 'http://localhost:3000/', pathRewrite: {'^/api' : ''}, changeOrigin: true ...
- 阿里云ECS配置踩坑之路
1.利用shadowsocks配置SVN(用于软件部署环境) 2.安全组设置 3.FTP搭建 https://www.cnblogs.com/hexige/p/7809481.html
- An Introduction To The SQLite C/C++ Interface
1. Summary The following two objects and eight methods comprise the essential elements of the SQLite ...
- UVA11584-Partitioning by Palindromes(动态规划基础)
Problem UVA11584-Partitioning by Palindromes Accept: 1326 Submit: 7151Time Limit: 3000 mSec Problem ...
- Python中使用class(),面向对象有什么优势 转自知乎
https://www.zhihu.com/question/19729316 首先我是辣鸡,然后这个问题的确有点意思 首先,类是一个集合,包含了数据,操作描述的一个抽象集合 你可以首先只把类当做一个 ...
- 【ES6】=>含义
=>是es6语法中的arrow function (x) => x + 6 相当于 function(x){ return x + 6; }; var ids = this.sels.ma ...
- Raid卡介绍
raid0条带卷 最少需要一块硬盘 可以把所有硬盘的容量都叠加在一起,可以拥有很高的读写速度,硬盘空间也能得到很好的利用 但是只要其中一块硬盘换了,数据就全丢失了 raid1镜像卷 最少需要两块硬盘, ...
- 摒弃FORM表单上传图片,异步批量上传照片
之前作图像处理一直在用form表单做图片数据传输, 个人感觉low到爆炸而且用户体验极差,现在介绍一个一部批量上传图片的小技巧,忘帮助他人的同时也警醒自己在代码的编写时不要只顾着方便,也要考虑代码的健 ...
- python魔法方法、构造函数、序列与映射、迭代器、生成器
在Python中,所有以__双下划线包起来的方法,都统称为"魔术方法".比如我们接触最多的__init__,魔法方法也就是具有特殊功能的方法. 构造函数 构造函数不同于普通方法,将 ...
- day93之微信推送
python之微信推送详解 用什么推送 -邮件 -微信推送 -短信推送微信推送 -公众号(不能主动给用户发消息) -认证的公众号:需要营业执照,需要交钱,可以发多篇文章 - ...