GZip、deflate和sdch压缩(网摘整理)
GZip和deflate:
gzip是一种数据格式,默认且目前仅使用deflate算法压缩data部分;
deflate是一种压缩算法,是huffman编码的一种加强。
deflate与gzip解压的代码几乎相同,可以合成一块代码。
区别仅有:
deflate使用inflateInit(),而gzip使用inflateInit2()进行初始化,比 inflateInit()多一个参数: -MAX_WBITS,表示处理raw deflate数据。因为gzip数据中的zlib压缩数据块没有zlib header的两个字节。使用inflateInit2时要求zlib库忽略zlib header。在zlib手册中要求windowBits为8..15,但是实际上其它范围的数据有特殊作用,见zlib.h中的注释,如负数表示raw deflate。
Apache的deflate变种可能也没有zlib header,需要添加假头后处理。即MS的错误deflate (raw deflate).zlib头第1字节一般是0x78, 第2字节与第一字节合起来的双字节应能被31整除,详见rfc1950。例如Firefox的zlib假头为0x7801,python zlib.compress()结果头部为0x789c。
deflate 是最基础的算法,gzip 在 deflate 的 raw data 前增加了 10 个字节的 gzheader,尾部添加了 8 个字节的校验字节(可选 crc32 和 adler32) 和长度标识字节。
SDCH:
我们知道,为了加快网络传输,一般都使用gzip对文本进行压缩。如果你现在用最新版的chrome去访问页面,然后打开network控制面板,查看http headers,细心的你会发现在Request Headers里的Accept-Encoding不再是gzip,deflate,而是多了个sdch,变成了gzip,deflate,sdch。如图:
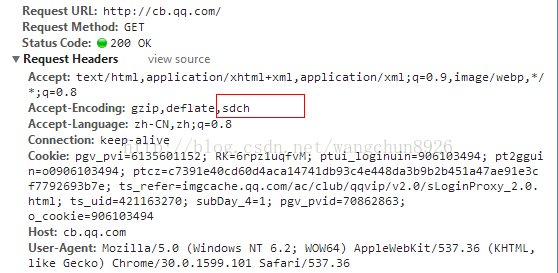
SDCH到底是什么
sdch是Shared Dictionary Compression over HTTP的缩写,即通过字典压缩算法对各个页面中相同的内容进行压缩,减少相同的内容的传输。
如:一个网站中一般都是共同的头部和尾部,甚至一些侧边栏也是共同的。之前的方式每个页面打开的时候这些共同的信息都要重新加载,但使用SDCH压缩方式的话,那些共同的内容只用传输一次就可以了。
sdch主要分为3个部分:首次请求,下载字典,之后的请求。
这种方式最开始的时候是Google工具栏里为IE准备的,目前Chrome已经完全支持了,不过暂时还没发现哪个网站在使用。
SDCH与ajax+pushState
SDCH压缩方式是为了减少相同内容的传输的,同时之前介绍的ajax+pushState也是减少相同内容的传输,他们想达到的效果是一样的。只是SDCH是Google出的,可能今后一段时间只有Chrome浏览器支持,但pushState是HTML5的一个标准,目前已经有Chrome和Firefox支持,之后会有越来越多的浏览器支持。
个人觉得SDCH可能没有什么太大的发展,但可以作为一个新方向研究,并且在合适的时候添加到标准里,让网络传输越来越迅速。
GZip、deflate和sdch压缩(网摘整理)的更多相关文章
- 从python爬虫引发出的gzip,deflate,sdch,br压缩算法分析
今天在使用python爬虫时遇到一个奇怪的问题,使用的是自带的urllib库,在解析网页时获取到的为b'\x1f\x8b\x08\x00\x00\x00\x00...等十六进制数字,尝试使用chard ...
- 笔记:服务器压缩方案 来源于 Accept-Encoding: gzip, deflate 问题
笔记:服务器压缩方案 来源于 Accept-Encoding: gzip, deflate 问题 事情起因:odoo demo 没有启动web 压缩 目前流行的 web 压缩技术 gzip br 支持 ...
- httpclient访问网站时设置Accept-Encoding为gzip,deflate返回的结果为乱码的问题
近期迷恋上httpclient模拟各种网站登陆,浏览器中的开发者工具中查看请求头信息,然后照葫芦画瓢写到httpclient的请求中去,requestheader中有这么一段设置: Accept-En ...
- WebClient 支持 gzip, deflate
低调偷偷的下别人数据 发现下出来乱码- 用F12看看请求,原来人家是用了gzip压缩的- 试着自己加个Heading wc.Headers.Add("Accept-Encoding" ...
- Delphi 中DataSnap技术网摘
Delphi2010中DataSnap技术网摘 一.为DataSnap系统服务程序添加描述 这几天一直在研究Delphi 2010的DataSnap,感觉功能真是很强大,现在足有理由证明Delphi7 ...
- Feedly订阅Blog部落格RSS网摘 - Blog透视镜
网络信息爆炸的时代,如何更有效率地阅读文章,订阅RSS网摘,可以快速地浏览文章标题,当对某些文章有兴趣时,才点下连结连到原网站,阅读更详细的文章,Feedly Reader阅读器除了提供在线版订阅RS ...
- Bloglines订阅Blog部落格RSS网摘 - Blog透视镜
网络信息蓬勃发展,Blog部落格越来越普及,如果逐一地去浏览网站,势必费时费力,倘若信息可以自己送上门,那就可以节省不少时间,就好像看报纸的标题,有兴趣才点连结,进到网站浏览文章内容,Blogline ...
- 惊喜:opera换webkit内核后完美支持SDCH压缩协议
csdn发邮件警告说再不发文章就取消我的专家头衔了.呵呵,其实我只是在csdn暴露了我的帐号密码以后不得已把csdn密码修改成一个我自己都记不住的货,所以很少上来了. 言归正传.我们从去年就在QQ空间 ...
- TCP/IP协议头部结构体(网摘小结)(转)
源:TCP/IP协议头部结构体(网摘小结) TCP/IP协议头部结构体(转) 网络协议结构体定义 // i386 is little_endian. #ifndef LITTLE_ENDIAN #de ...
随机推荐
- 简单备份mysql数据库
对于数据量不大的业务场景,可以每天做全量备份. 实现方式:编写备份数据库脚本,然后在crontab中每天定时执行脚本进行备份. 备份脚本示例: #!/bin/bash #Author: zhangsa ...
- 谷歌地图,国内使用Google Maps JavaScript API,国外业务
目前还是得墙 <!DOCTYPE html> <html> <head> <meta name="viewport" content=&q ...
- 23.Secondary Index
一. Secondary Index(二级索引)1.1. Secondary Index 介绍 • Clustered Index(聚集索引) ◦ 叶子节点存储所有记录(all row data) • ...
- 三十二、Linux 进程与信号——不可靠信号
32.1 不可靠信号问题 发生信号时关联动作被重置为默认设置 信号可能丢失 程序片段 在进入 sig_int 与再次调用 signal 之间发生的 SIGINT 信号将不会捕获 导致进程终止 以前版本 ...
- 二十七、Linux 进程与信号---进程组和组长进程
27.1 进程组 27.1.1 进程组介绍 进程组为一个或多个进程的集合 进程组可以接受同一终端的各种信号,同一个信号发送进程组等于发送给组中的所有进程 每个进程组有唯一的进程组 ID 进程组的消亡要 ...
- 关于PHP中的全局变量global和$GLOBALS的不同区分
1.global Global的作用是定义全局变量,但是这个全局变量不是应用于整个网站,而是应用于当前页面,包括include或require的所有文件. 但是在函数体内定义的global变量,函数体 ...
- Andrew NG 机器学习编程作业5 Octave
问题描述:根据水库中蓄水标线(water level) 使用正则化的线性回归模型预 水流量(water flowing out of dam),然后 debug 学习算法 以及 讨论偏差和方差对 该线 ...
- Docker 随 docker服务重启
在创建时添加 重启 docker run --restart=always -d --name web -p : -v /data/web:/usr/local/tomcat/webapps tom ...
- python中requests的用法总结
requests是一个很实用的Python HTTP客户端库,编写爬虫和测试服务器响应数据时经常会用到.可以说,Requests 完全满足如今网络的需求 本文全部来源于官方文档 http://docs ...
- python栈
class StackEmptyError(Exception): pass class StackFullError(Exception): pass class Stack: def __init ...