Python-爬虫-租房Ziroom
目标站点需求分析
涉及的库
import requests
import time
import pymongo
from lxml import etree
from requests.exceptions import RequestException
获取单页源码
def get_one_page(page):
'''获取单页源码'''
try:
url = "http://sh.ziroom.com/z/nl/z2.html?p=" + str(page)
print('url',url)
headers = {
'Referer':'http://sh.ziroom.com/',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
res = requests.get(url,headers=headers)
time.sleep(1)
if res.status_code == 200:
return res.text
return None
except RequestException:
return None
解析单页源码
def parse_one_page(sourcehtml):
'''解析单页源码'''
contentTree = etree.HTML(sourcehtml) #解析源代码
results = contentTree.xpath('//ul[@id="houseList"]/li') #利用XPath提取相应内容
for result in results:
title = result.xpath("./div/h3/a/text()")[0][5:] if len(result.xpath("./div/h3/a/text()")[0]) > 0 else ""
area = " ".join(result.xpath("./div/div/p[1]/span/text()")).replace(" ", "", 1) # 使用join方法将列表中的内容以" "字符连接
nearby = result.xpath("./div/div/p[2]/span/text()")[0].strip() if len(result.xpath("./div/div/p[2]/span/text()"))>0 else ""
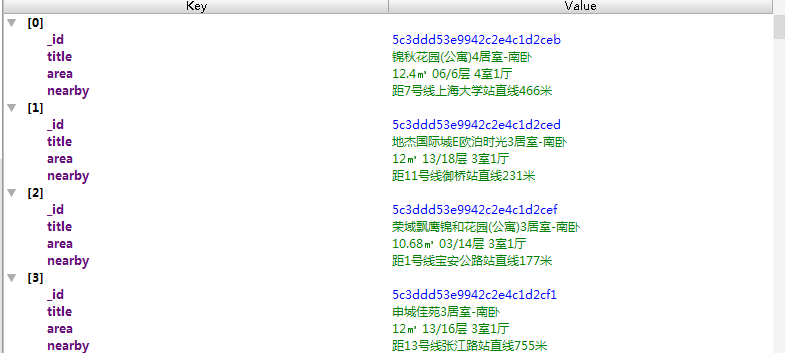
data = {
"title": title,
"area": area,
"nearby": nearby
}
print(data)
save_to_mongodb(data)
抓取总页数,保存到Mongobd中
def get_pages():
"""得到总页数"""
page = 1
html = get_one_page(page)
contentTree = etree.HTML(html)
pages = int(contentTree.xpath('//div[@class="pages"]/span[2]/text()')[0].strip("共页"))
return pages def save_to_mongodb(result):
"""存储到MongoDB中"""
# 创建数据库连接对象, 即连接到本地
client = pymongo.MongoClient(host="localhost")
# 指定数据库,这里指定ziroom和表名
db = client.iroomz
db_table = db.roominfo
try:
#插入到数据库
if db_table.insert(result):
print("抓取成功",result)
except Exception as reason:
print("抓取失败",reason)
def task():
pages = get_pages()
print('总共',pages)
for page in range(1,int(pages)+1):
html = get_one_page(page)
parse_one_page(html)
Python-爬虫-租房Ziroom的更多相关文章
- python 爬虫入门----案例爬取上海租房图片
前言 对于一个net开发这爬虫真真的以前没有写过.这段时间学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup. ...
- python爬虫项目(scrapy-redis分布式爬取房天下租房信息)
python爬虫scrapy项目(二) 爬取目标:房天下全国租房信息网站(起始url:http://zu.fang.com/cities.aspx) 爬取内容:城市:名字:出租方式:价格:户型:面积: ...
- python 爬虫入门案例----爬取某站上海租房图片
前言 对于一个net开发这爬虫真真的以前没有写过.这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSou ...
- Python爬虫(四)——开封市58同城数据模型训练与检测
前文参考: Python爬虫(一)——开封市58同城租房信息 Python爬虫(二)——对开封市58同城出租房数据进行分析 Python爬虫(三)——对豆瓣图书各模块评论数与评分图形化分析 数据的构建 ...
- Python爬虫之PyQuery使用(六)
Python爬虫之PyQuery使用 PyQuery简介 pyquery能够通过选择器精确定位 DOM 树中的目标并进行操作.pyquery相当于jQuery的python实现,可以用于解析HTML网 ...
- FocusBI: 使用Python爬虫为BI准备数据源(原创)
关注微信公众号:FocusBI 查看更多文章:加QQ群:808774277 获取学习资料和一起探讨问题. <商业智能教程>pdf下载地址 链接:https://pan.baidu.com/ ...
- 高德API+Python解决租房问题(.NET版)
源码地址:https://github.com/liguobao/58HouseSearch 在线地址:58公寓高德搜房(全国版):http://codelover.link:8080/ 周末闲着无事 ...
- Python爬虫:设置Cookie解决网站拦截并爬取蚂蚁短租
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Eastmount PS:如有需要Python学习资料的小伙伴可以加 ...
- GitHub 上有哪些优秀的 Python 爬虫项目?
目录 GitHub 上有哪些优秀的 Python 爬虫项目? 大型爬虫项目: 实用型爬虫项目: 其它有趣的Python爬虫小项目: GitHub 上有哪些优秀的 Python 爬虫项目? 大型爬虫项目 ...
- Python爬虫系统化学习(5)
Python爬虫系统化学习(5) 多线程爬虫,在之前的网络编程中,我学习过多线程socket进行单服务器对多客户端的连接,通过使用多线程编程,可以大大提升爬虫的效率. Python多线程爬虫主要由三部 ...
随机推荐
- luogu 2878 贪心
其实这题不难,只是想告诉自己:贪心不全是真的脑残拿最大就AC 此题实际上就是比较x,y优先级利用时间计算得到a[i]t/a[i].d(没错时间在上,并非惯性思维的d在上) t*a[x].d+(t+a[ ...
- 利用ssh操控远程服务器
这里的”远程”操控的方法实际上也不是真正的远程.,這此操作方法主要是在一个局域网内远程操控电脑 (在一个路由器下).可以把它做成在互联网中的远程操控, 不过技术难度上加了一个等级, 如果你想是想人在公 ...
- Docker 添加环境系统文件配置
在 docker 启动文件添加默认环境系统配置 " /etc/default/docker ": 添加 Environment File 配置: # vi /usr/lib/sy ...
- Debian Security Advisory(Debian安全报告) DSA-4410-1 openjdk-8 security update
Debian Security Advisory(Debian安全报告) DSA-4410-1 openjdk-8 security update Package :openjdk-8 CVE ID: ...
- Coursera, Deep Learning 4, Convolutional Neural Networks - week4,
Face recognition One Shot Learning 只看一次图片,就能以后识别, 传统deep learning 很难做到这个. 而且如果要加一个人到数据库里面,就要重新train ...
- 配置mongo
Windows 平台安装 MongoDB MongoDB 下载 MongoDB 提供了可用于 32 位和 64 位系统的预编译二进制包,你可以从MongoDB官网下载安装,MongoDB 预编译二进制 ...
- vue-CLI踩坑记
vue init webpack vue-demo 使用 windows 7 DOS命令行和gitbash都有选择和实际选择结果不一致的问题, DOS命令行只在 Vue build有问题, gitba ...
- modbus 寄存器介绍
modbus 的查询命令 命令 地址开始(两个地址) 地址长度(两个地址) 检验 01 xx xx xx ...
- window 编译lua 5.3
由于lua 5.1 不支持左移右移的操作符,所以要移植lua 5.3.方便在window 下编译调试 参考链接: http://www.linuxidc.com/Linux/2014-02/96459 ...
- Python Django 实用小案例2
动态导入模块 Django返回序列化数据 动态导入模块 在Django里面,经常会看到一些方法或者类是动态导入,尤其是以settings文件为代表,经常把一些类放在里面动态调配,比如随便拿Djang ...