[Linux]关于字节序的解析
剥鸡蛋的故事
《格列佛游记》中记载了两个征战的强国,你不会想到的是,他们打仗竟然和剥鸡蛋的姿势有关。
很多人认为,剥鸡蛋时应该打破鸡蛋较大的一端,这群人被称作“大端(Big endian)派”。可是当今皇帝的祖父小时候吃鸡蛋的时候碰巧将一个手指弄破了。所以,他的父亲(当时的皇帝)就下令剥鸡蛋必须打破鸡蛋较小的一端,违令者重罚,由此产生了“小端(Little endian)派”。
老百姓们对这项命令极其反感,由此引发了6次叛乱,其中一个皇帝送了命,另一个丢了王位。据估计,先后几次有11000人情愿受死也不肯去打破鸡蛋较小的一端!
话题扯远了,不过关于字节序的big endian和little endian的命名确实来源于此典故;
在理解字节序前,先来说说我们平时不那么留意的阅读习惯常识,如果我不说,你还真的反应不过来,反正我是这样的。
1.数位阅读习惯
人类在阅读数字的时候一般的认知是从左到右这样阅读的,比如256,读作“二百五十六”,大的数位在左边小的依次往右,这是人类的阅读习惯
2.文章阅读习惯
人类在阅读文章的时候一般的认知也是从左到右阅读的,比如你正在阅读的这段文字,我打赌你不会从最后一个字往回阅读,这又是一个人类的阅读习惯
开始了,我们都清楚,计算机世界里面,最小的存储是字节(byte),就好像阅读数字一样,我们会把大的位数放在左边
比如:
00010010
它等于十进制的18,很明显这没有任何问题,所以说,当一段文字它只是包含一个数字的情况下,是不会出现字节序问题的,人类都公认越往左边就应该保存位数越高的值,例如UTF-8,解析程序每次只会取一个字节出来进行解析,便不会存在字节序的问题。
问题出现在当一段文字包含好几个数字或者更多个数字的时候,打个比方,
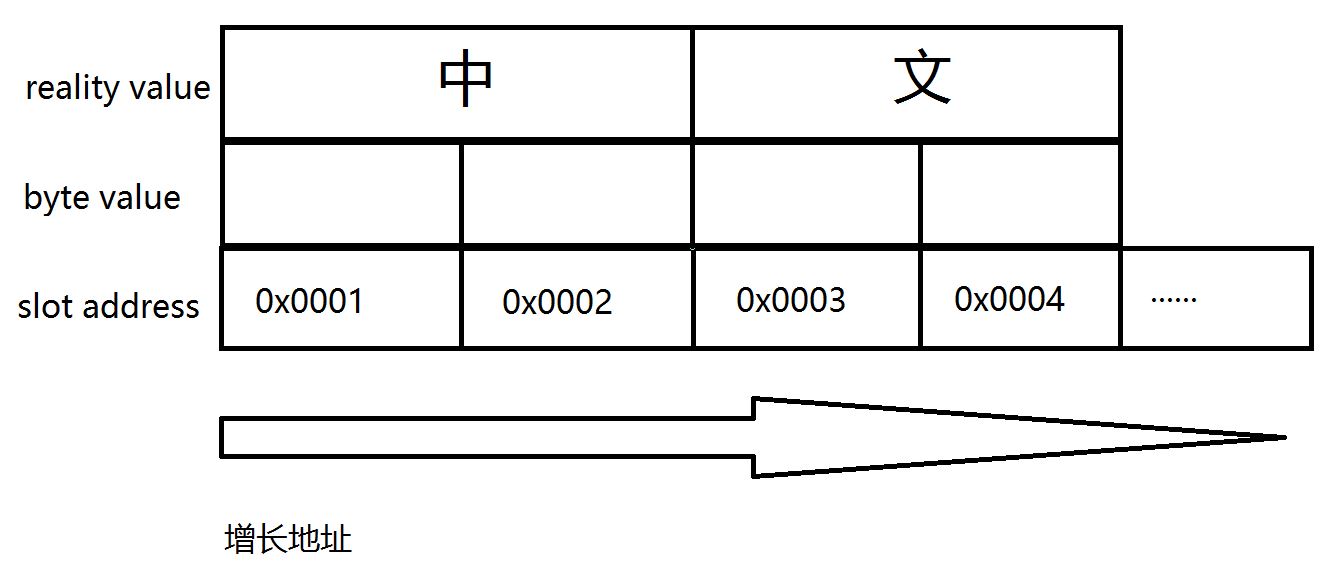
UTF-16编码,它是一种由两个字节构成的Unicode字符编码方式,也就是说,无论保存任何字符,它都要用到两个字节:
UTF-16编码 4E2D 对应的是中文的“中”字,很明显,要保存这个“中”字,必须动用两个字节,于是问题来了,我是先保存4E在左边呢,还是先保存2D在左边呢?
就是这丁点事儿,不同计算机厂商和各个计算机技术协会几乎打起来了,而且一直没有解决问题,存在着争议;
好啦,来看看我们刚才提到的两个人类阅读习惯常识,来结合UTF-16的“中文”两个字,就能说明问题!
很明显“中文”不是一个文字,而是一段文字,按照人类对文章的阅读习惯,肯定是先读“中”后读“文”,这个是没有异议的,全世界都没有异议,
所以,计算机的内存地址是从左往右排序的,左边起是第一个然后是第二个。。。
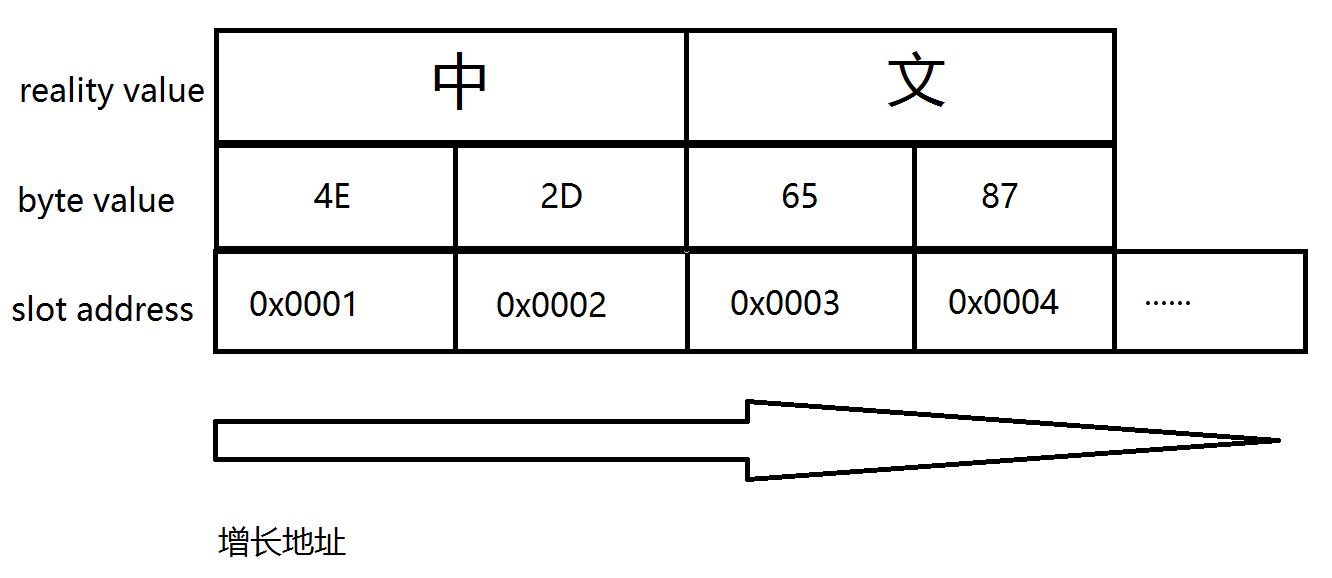
big endian:
大端序认为,按照人类对数字的阅读习惯,把大的数字保存在左边是最合适的
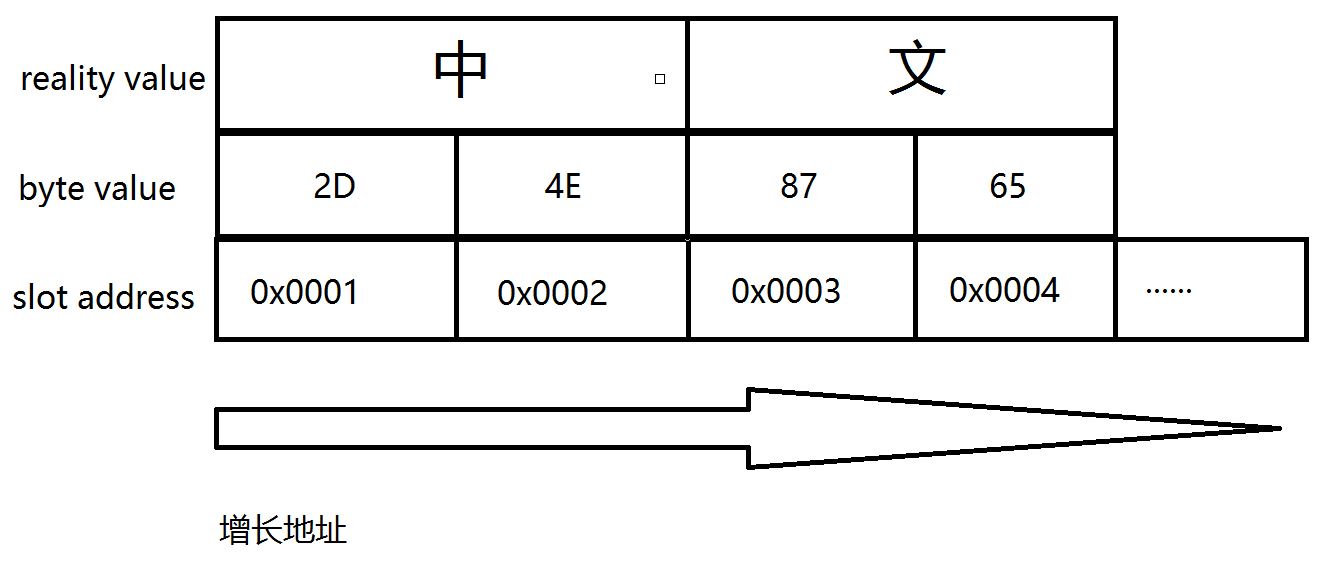
little endian:
小端序认为,这个单元式的字节段压根就跟数字不是一回事,应该按照人类阅读文章的习惯,把小的数字保存在左边
公说公有理婆说婆有理,貌似不同的CPU厂商并没有达成一致:
- x86,MOS Technology 6502,Z80,VAX,PDP-11等处理器为Little endian。
- Motorola 6800,Motorola 68000,PowerPC 970,System/370,SPARC(除V9外)等处理器为Big endian。
- ARM, PowerPC (除PowerPC 970外), DEC Alpha, SPARC V9, MIPS, PA-RISC and IA64的字节序是可配置的。
大端也好,小端也罢,就权当是个人爱好吧,只要你不影响别人就行,对不?
网络字节序
前面的大端和小端都是在说计算机自己,也被称作主机字节序。其实,只要自己能够自圆其说是没啥问题的。问题是,网络的出现使得计算机可以通信了。通信,就意味着相处,相处必须得有共同语言啊,得说普通话,要不然就容易会错意,下了一个小时的小电影发现打不开,理解错误了!
但是每个计算机都有自己的主机字节序啊,还都不依不饶,坚持做自己,怎么办?
TCP/IP协议隆重出场,RFC1700规定使用“大端”字节序为网络字节序,其他不使用大端的计算机要注意了,发送数据的时候必须要将自己的主机字节序转换为网络字节序(即“大端”字节序),接收到的数据再转换为自己的主机字节序。这样就与CPU、操作系统无关了,实现了网络通信的标准化。突然觉得,TCP/IP协议好任性啊有木有!
为了程序的兼容,你会看到,程序员们每次发送和接受数据都要进行转换,这样做的目的是保证代码在任何计算机上执行时都能达到预期的效果。
这么常用的操作,BSD Socket提供了封装好的转换接口,方便程序员使用。包括从主机字节序到网络字节序的转换函数:htons、htonl;从网络字节序到主机字节序的转换函数:ntohs、ntohl。当然,有了上面的理论基础,也可以编写自己的转换函数。
下面的一段代码可以用来判断计算机是大端的还是小端的,判断的思路是确定一个多字节的值(下面使用的是4字节的整数),将其写入内存(即赋值给一个变量),然后用指针取其首地址所对应的字节(即低地址的一个字节),判断该字节存放的是高位还是低位,高位说明是Big endian,低位说明是Little endian。
#include <stdio.h>
int main ()
{
unsigned int x = 0x12345678;
char *c = (char*)&x;
if (*c == 0x78) {
printf("Little endian");
} else {
printf("Big endian");
}
return ;
}
身边的字节序
字符编码方式UTF-16、UTF-32同样面临字节序的问题,因为他们分别使用2个字节和4个字节编码Unicode字符,一旦某个值用多个字节表示,就必须要考虑存储的顺序了。于是,采用了最简单粗暴的方式,给文件头部写几个字符,用来表示是大端呢还是小端:
头部的字符 编码 字节序 FF FE UTF-16/UCS-2 Little endian FE FF UTF-16/UCS-2 Big endian FF FE 00 00 UTF-32/UCS-4 Little endian 00 00 FE FF UTF-32/UCS-4 Big-endian
这里不得不提一下UTF-8啊,明明人家是单个字节的,不存在什么字节序的问题。微软为了统一UTF-X,硬生生给他的头部也加了几个字符!是的,这几个字符就是BOM(Byte Order Mark),这就是Windows下的UTF-8。
相信很多人都被UTF-8的BOM给坑过,多了这个BOM的UTF-8文件,会导致很多问题啊。比如,写的Shell脚本,内容为#!/usr/bin/env bash,在UTF-8有BOM和UTF-8无BOM的编码下,对应的16进制为:
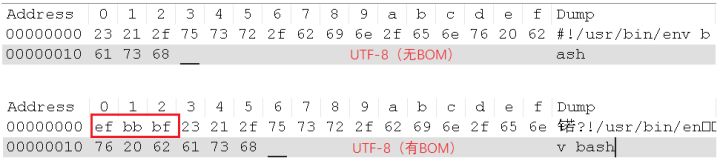
所以,有BOM的话,Shell解释器就报错啦。原因在于,解释器希望遇到#!/usr/bin/env bash,而使用UTF-8有BOM进行编码的内容会多了3个字节的EF BB BF。
对于UTF-8和UTF-8无BOM两种编码格式,我们更多的使用UTF-8无BOM。
[Linux]关于字节序的解析的更多相关文章
- 判别linux机器字节序为大端还是小端
代码如下: #include <iostream> #include <arpa/inet.h> #include <cstdio> using namespace ...
- Linux 网络编程详解一(IP套接字结构体、网络字节序,地址转换函数)
IPv4套接字地址结构 struct sockaddr_in { uint8_t sinlen;(4个字节) sa_family_t sin_family;(4个字节) in_port_t sin_p ...
- linux程序设计——主机字节序和网络字节序(第十五章)
15.2.10 主机字节序和网络字节序 当在基于intel处理器的linux机器上执行新版本号的server和客户程序时,能够用netstat命令查看网络连接状况.它显示了客户/server连接 ...
- linux kernel如何处理大端小端字节序
(转)http://blog.csdn.net/skyflying2012/article/details/43771179 最近在做将kernel由小端处理器(arm)向大端处理器(ppc)的移植的 ...
- Linux 字节序
小心不要假设字节序. PC 存储多字节值是低字节为先(小端为先, 因此是小端), 一些高 级的平台以另一种方式(大端)工作. 任何可能的时候, 你的代码应当这样来编写, 它不在 乎它操作的数据的字节序 ...
- linux的大小端、网络字节序问题 .
1.80X86使用小端法,网络字节序使用大端法. 2.二进制的网络编程中,传送数据,最好以unsigned char, unsigned short, unsigned int来处理, unsigne ...
- linux网路编程:字节序(大端、小端、网络、主机)
字节序:就是数据在内存中的存放顺序,也可称之为端模式. 大端模式和小端模式的定义 1) Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端. 2) Big-End ...
- Linux网络编程--字节序
1 .谈到字节序,那么会有朋友问什么是字节序 非常easy:[比如一个16位的整数.由2个字节组成,8位为一字节,有的系统会将高字节放在内存低的地址上,有的则将低字节放在内存高的地址上,所以存在字节序 ...
- 【Linux 网络编程】字节序和地址装换
(3)字节序 <1>大端字节序 最高的有效位存储于最低内存地址处,最低有效位存储于最高内存地址处. <2>小端字节序 最高的有效位存储于 ...
随机推荐
- Python正则匹配之有名分组
参考:http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html # re.match import re m = re.match(r'( ...
- Spring Bean的ref属性和IoC注入集合
这是一个Demo 1.Phone.java package com.cn.pojo; public class Phone { private String name; private double ...
- 去掉MyEclipse 中烦人的黄线和感叹号!
Window>>Preferences>>General>>Editors>>Text Editors>>Annotations 选中右边的 ...
- Devexpress Winform 使用MVVM
MVVM在WPF里很早就有了,在Winform里Devexpress最近几个大版本才有的事,上一段代码. 现在对话框上添加三个控件simpleButton1,simpleButton2,textEdi ...
- POSIX信号和自定义signal函数
一.信号的概念 信号(signal)就是告知某个进程发生了某个事件的通知:信号通常是异步发生的,也就是说接受信号的进程不知道信号的准确 发生时刻:信号可以(1)由一个进程发给另一个进程:(2)由内核发 ...
- 二十四、Linux 进程与信号---wait 函数
24.1 wait 函数说明 24.1.1 waitpid---等待子进程中断或结束 waitpid(等待子进程中断或结束) 相关函数 wait,fork #include <sys/types ...
- treap基本操作
利用rand保持堆的特性 const int N=; int ls[N],rs[N],v[N],p[N],cnt[N],siz[N]; // 权值 优先级 inline void update(int ...
- 002_Add Two Numbers
# Definition for singly-linked list. # class ListNode: # def __init__(self, x): # self.val = x # sel ...
- C++中extern(转)
1 基本解释:extern可以置于变量或者函数前,以标示变量或者函数的定义在别的文件中,提示编译器遇到此变量和函数时在其他模块中寻找其定义.此外extern也可用来进行链接指定. 也就是说extern ...
- jQuery.extend 函数使用
JQuery的extend扩展方法: Jquery的扩展方法extend是我们在写插件的过程中常用的方法,该方法有一些重载原型,在此,我们一起去了解了解. 一.Jquery的扩展方 ...