支持向量机-完整Platt-SMO算法加速优化
完整版SMO算法与简单的SMO算法:
实现alpha的更改和代数运算的优化环节一模一样,唯一的不同就是选择alpha的方式。完整版应用了一些能够提速的方法。
同样使用Jupyter实现,后面不在赘述
参考地址:https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/6.SVM/svm-complete_Non-Kernel.py
1. 加载数据(与SMO相同)
from numpy import *
import matplotlib.pyplot as plt
def loadDataSet(fileName):
"""loadDataSet(对文件进行逐行解析,从而得到第行的类标签和整个数据矩阵)
Args:
fileName 文件名
Returns:
dataMat 数据矩阵
labelMat 类标签
"""
dataMat = []
labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat, labelMat
2. 辅助函数(与SMO相同)
def clipAlpha(aj, H, L):
"""clipAlpha(调整aj的值,使aj处于 L<=aj<=H)
Args:
aj 目标值
H 最大值
L 最小值
Returns:
aj 目标值
"""
if aj > H:
aj = H
if L > aj:
aj = L
return aj
3. 完整版SMO算法的支持函数
1. 构建一个仅包含init方法的optStruct类,来保存所有的重要值
# 1. 误差缓存
class optStruct:
def __init__(self, dataMatIn, classLabels, C, toler): # Initialize the structure with the parameters
self.X = dataMatIn
self.labelMat = classLabels
self.C = C
self.tol = toler
self.m = shape(dataMatIn)[0]
self.alphas = mat(zeros((self.m, 1)))
self.b = 0
self.eCache = mat(zeros((self.m, 2)))
2. 计算E值并返回
# 2. 预测结果与真实结果比对,计算误差Ek
def calcEk(oS, k):
"""calcEk(求 Ek误差:预测值-真实值的差)
该过程在完整版的SMO算法中陪出现次数较多,因此将其单独作为一个方法
Args:
oS optStruct对象
k 具体的某一行
Returns:
Ek 预测结果与真实结果比对,计算误差Ek
"""
fXk = float(multiply(oS.alphas, oS.labelMat).T * (oS.X * oS.X[k, :].T)) + oS.b
Ek = fXk - float(oS.labelMat[k])
return Ek
3. 选择第二个alpha。选择合适的第二个alpha以保证每次优化采用最大步长
def selectJ(i, oS, Ei): # this is the second choice -heurstic, and calcs Ej
"""selectJ(返回最优的j和Ej)
内循环的启发式方法。
选择第二个(内循环)alpha的alpha值
这里的目标是选择合适的第二个alpha值以保证每次优化中采用最大步长。
该函数的误差与第一个alpha值Ei和下标i有关。
Args:
i 具体的第i一行
oS optStruct对象
Ei 预测结果与真实结果比对,计算误差Ei
Returns:
j 随机选出的第j一行
Ej 预测结果与真实结果比对,计算误差Ej
"""
maxK = -1
maxDeltaE = 0
Ej = 0
oS.eCache[i] = [1, Ei]
validEcacheList = nonzero(oS.eCache[:, 0].A)[0]
if (len(validEcacheList)) > 1:
for k in validEcacheList: # 在所有的值上进行循环,并选择其中使得改变最大的那个值
if k == i:
continue # don't calc for i, waste of time # 求 Ek误差:预测值-真实值的差
Ek = calcEk(oS, k)
deltaE = abs(Ei - Ek)
if (deltaE > maxDeltaE):
maxK = k
maxDeltaE = deltaE
Ej = Ek
return maxK, Ej
else: # 如果是第一次循环,则随机选择一个alpha值
j = selectJrand(i, oS.m) # 求 Ek误差:预测值-真实值的差
Ej = calcEk(oS, j)
return j, Ej
4. 计算误差值并存入缓存中
def updateEk(oS, k): # after any alpha has changed update the new value in the cache
"""updateEk(计算误差值并存入缓存中。)
在对alpha值进行优化之后会用到这个值。
Args:
oS optStruct对象
k 某一列的行号
""" # 求 误差:预测值-真实值的差
Ek = calcEk(oS, k)
oS.eCache[k] = [1, Ek]
4. 完整版Platt SMO算法的优化例程
def innerL(i, oS):
"""innerL
内循环代码
Args:
i 具体的某一行
oS optStruct对象
Returns:
0 找不到最优的值
1 找到了最优的值,并且oS.Cache到缓存中
""" # 求 Ek误差:预测值-真实值的差
Ei = calcEk(oS, i) # 约束条件 (KKT条件是解决最优化问题的时用到的一种方法。我们这里提到的最优化问题通常是指对于给定的某一函数,求其在指定作用域上的全局最小值)
# 0<=alphas[i]<=C,但由于0和C是边界值,我们无法进行优化,因为需要增加一个alphas和降低一个alphas。
# 表示发生错误的概率:labelMat[i]*Ei 如果超出了 toler, 才需要优化。至于正负号,我们考虑绝对值就对了。
'''
# 检验训练样本(xi, yi)是否满足KKT条件
yi*f(i) >= 1 and alpha = 0 (outside the boundary)
yi*f(i) == 1 and 0<alpha< C (on the boundary)
yi*f(i) <= 1 and alpha = C (between the boundary)
'''
if ((oS.labelMat[i] * Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i] * Ei > oS.tol) and (oS.alphas[i] > 0)):
# 选择最大的误差对应的j进行优化。效果更明显
j, Ej = selectJ(i, oS, Ei)
alphaIold = oS.alphas[i].copy()
alphaJold = oS.alphas[j].copy() # L和H用于将alphas[j]调整到0-C之间。如果L==H,就不做任何改变,直接return 0
if (oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L == H:
print("L==H")
return 0 # eta是alphas[j]的最优修改量,如果eta==0,需要退出for循环的当前迭代过程
# 参考《统计学习方法》李航-P125~P128<序列最小最优化算法>
eta = 2.0 * oS.X[i, :] * oS.X[j, :].T - oS.X[i, :] * oS.X[i, :].T - oS.X[j, :] * oS.X[j, :].T
if eta >= 0:
print("eta>=0")
return 0 # 计算出一个新的alphas[j]值
oS.alphas[j] -= oS.labelMat[j] * (Ei - Ej) / eta
# 并使用辅助函数,以及L和H对其进行调整
oS.alphas[j] = clipAlpha(oS.alphas[j], H, L)
# 更新误差缓存
updateEk(oS, j) # 检查alpha[j]是否只是轻微的改变,如果是的话,就退出for循环。
if (abs(oS.alphas[j] - alphaJold) < 0.00001):
print("j not moving enough")
return 0 # 然后alphas[i]和alphas[j]同样进行改变,虽然改变的大小一样,但是改变的方向正好相反
oS.alphas[i] += oS.labelMat[j] * oS.labelMat[i] * (alphaJold - oS.alphas[j])
# 更新误差缓存
updateEk(oS, i) # 在对alpha[i], alpha[j] 进行优化之后,给这两个alpha值设置一个常数b。
# w= Σ[1~n] ai*yi*xi => b = yj Σ[1~n] ai*yi(xi*xj)
# 所以: b1 - b = (y1-y) - Σ[1~n] yi*(a1-a)*(xi*x1)
# 为什么减2遍? 因为是 减去Σ[1~n],正好2个变量i和j,所以减2遍
b1 = oS.b - Ei - oS.labelMat[i] * (oS.alphas[i] - alphaIold) * oS.X[i, :] * oS.X[i, :].T - oS.labelMat[j] * (oS.alphas[j] - alphaJold) * oS.X[i, :] * oS.X[j, :].T
b2 = oS.b - Ej - oS.labelMat[i] * (oS.alphas[i] - alphaIold) * oS.X[i, :] * oS.X[j, :].T - oS.labelMat[j] * (oS.alphas[j] - alphaJold) * oS.X[j, :] * oS.X[j, :].T
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]):
oS.b = b1
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]):
oS.b = b2
else:
oS.b = (b1 + b2) / 2.0
return 1
else:
return 0
这个函数与smosimple很像。有几点不同:1.使用selectJ()而不是selectJrand()来选择第二个alpha值。2. 在alpha值改变时更新Ecache。不同处代码中用黄色表示
5. 完整版Platt SMO的外循环代码
def smoP(dataMatIn, classLabels, C, toler, maxIter):
"""
完整SMO算法外循环,与smoSimple有些类似,但这里的循环退出条件更多一些
Args:
dataMatIn 数据集
classLabels 类别标签
C 松弛变量(常量值),允许有些数据点可以处于分隔面的错误一侧。
控制最大化间隔和保证大部分的函数间隔小于1.0这两个目标的权重。
可以通过调节该参数达到不同的结果。
toler 容错率
maxIter 退出前最大的循环次数
Returns:
b 模型的常量值
alphas 拉格朗日乘子
""" # 创建一个 optStruct 对象
oS = optStruct(mat(dataMatIn), mat(classLabels).transpose(), C, toler)
iter = 0
entireSet = True
alphaPairsChanged = 0 # 循环遍历:循环maxIter次 并且 (alphaPairsChanged存在可以改变 or 所有行遍历一遍)
# 循环迭代结束 或者 循环遍历所有alpha后,alphaPairs还是没变化
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0 # 当entireSet=true or 非边界alpha对没有了;就开始寻找 alpha对,然后决定是否要进行else。
if entireSet:
# 在数据集上遍历所有可能的alpha
for i in range(oS.m):
# 是否存在alpha对,存在就+1
alphaPairsChanged += innerL(i, oS)
print("fullSet, iter: %d i:%d, pairs changed %d" % (iter, i, alphaPairsChanged))
iter += 1
# 对已存在 alpha对,选出非边界的alpha值,进行优化。
else:
# 遍历所有的非边界alpha值,也就是不在边界0或C上的值。
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBoundIs:
alphaPairsChanged += innerL(i, oS)
print("non-bound, iter: %d i:%d, pairs changed %d" % (iter, i, alphaPairsChanged))
iter += 1 # 如果找到alpha对,就优化非边界alpha值,否则,就重新进行寻找,如果寻找一遍 遍历所有的行还是没找到,就退出循环。
if entireSet:
entireSet = False # toggle entire set loop
elif (alphaPairsChanged == 0):
entireSet = True
print("iteration number: %d" % iter)
return oS.b, oS.alphas
dataArr, labelArr = loadDataSet('F:/迅雷下载/machinelearninginaction/Ch06/testSet.txt')
b, alphas = smoP(dataArr, labelArr, 0.6, 0.001, 40)
fullSet, iter: 0 i:0, pairs changed 1
fullSet, iter: 0 i:1, pairs changed 1
...
fullSet, iter: 0 i:6, pairs changed 4
fullSet, iter: 0 i:7, pairs changed 4
j not moving enough
fullSet, iter: 0 i:8, pairs changed 4
fullSet, iter: 0 i:9, pairs changed 4
...
6. 基于alpha值得到超平面,计算w值
# 基于alpha值计算w值
def calcWs(alphas, dataArr, classLabels):
"""
基于alpha计算w值
Args:
alphas 拉格朗日乘子
dataArr feature数据集
classLabels 目标变量数据集
Returns:
wc 回归系数
"""
X = mat(dataArr)
labelMat = mat(classLabels).transpose()
m, n = shape(X)
w = zeros((n, 1))
for i in range(m):
w += multiply(alphas[i] * labelMat[i], X[i, :].T)
return w
ws = calcWs(alphas, dataArr, labelArr)
ws
array([[ 0.65433215],
[-0.3462154 ]])
对第一个数据点进行分类:
datMat = mat(dataArr)
datMat[0]*mat(ws) + b
matrix([[-1.20033343]])
如果该值大于0,那么其属于1类;如果该值小于0,那么属于-1类,对于数据点0,应该得到类别标签是-1
labelArr[0]
-1.0
继续检查其他数据分类结果的正确性:
datMat[2]*mat(ws) + b
matrix([[2.65453687]])
labelArr[2]
1.0
datMat[1]*mat(ws) + b
matrix([[-1.7433995]])
labelArr[1]
-1.0
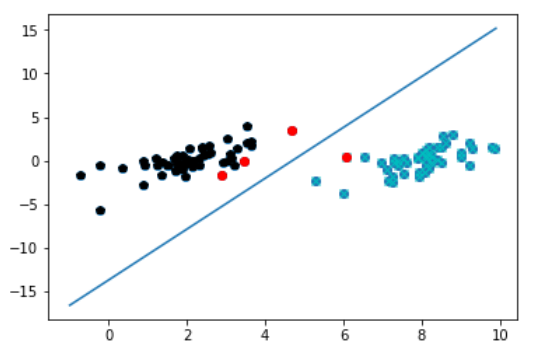
7. 画图
def plotfig_SVM(xArr, yArr, ws, b, alphas):
"""
参考地址:
http://blog.csdn.net/maoersong/article/details/24315633
http://www.cnblogs.com/JustForCS/p/5283489.html
http://blog.csdn.net/kkxgx/article/details/6951959
""" xMat = mat(xArr)
yMat = mat(yArr) # b原来是矩阵,先转为数组类型后其数组大小为(1,1),所以后面加[0],变为(1,)
b = array(b)[0]
fig = plt.figure()
ax = fig.add_subplot(111) # 注意flatten的用法
ax.scatter(xMat[:, 0].flatten().A[0], xMat[:, 1].flatten().A[0]) # x最大值,最小值根据原数据集dataArr[:, 0]的大小而定
x = arange(-1.0, 10.0, 0.1) # 根据x.w + b = 0 得到,其式子展开为w0.x1 + w1.x2 + b = 0, x2就是y值
y = (-b-ws[0, 0]*x)/ws[1, 0]
ax.plot(x, y) for i in range(shape(yMat[0, :])[1]):
if yMat[0, i] > 0:
ax.plot(xMat[i, 0], xMat[i, 1], 'cx')
else:
ax.plot(xMat[i, 0], xMat[i, 1], 'kp') # 找到支持向量,并在图中标红
for i in range(100):
if alphas[i] > 0.0:
ax.plot(xMat[i, 0], xMat[i, 1], 'ro')
plt.show() plotfig_SVM(dataArr, labelArr, ws, b, alphas)
支持向量机-完整Platt-SMO算法加速优化的更多相关文章
- 机器学习算法实践:Platt SMO 和遗传算法优化 SVM
机器学习算法实践:Platt SMO 和遗传算法优化 SVM 之前实现了简单的SMO算法来优化SVM的对偶问题,其中在选取α的时候使用的是两重循环通过完全随机的方式选取,具体的实现参考<机器学习 ...
- Platt SMO 和遗传算法优化 SVM
机器学习算法实践:Platt SMO 和遗传算法优化 SVM 之前实现了简单的SMO算法来优化SVM的对偶问题,其中在选取α的时候使用的是两重循环通过完全随机的方式选取,具体的实现参考<机器学习 ...
- 机器学习——支持向量机(SVM)之Platt SMO算法
Platt SMO算法是通过一个外循环来选择第一个alpha值的,并且其选择过程会在两种方式之间进行交替: 一种方式是在所有数据集上进行单遍扫描,另一种方式则是在非边界alpha中实现单遍扫描. 所谓 ...
- 支持向量机原理(四)SMO算法原理
支持向量机原理(一) 线性支持向量机 支持向量机原理(二) 线性支持向量机的软间隔最大化模型 支持向量机原理(三)线性不可分支持向量机与核函数 支持向量机原理(四)SMO算法原理 支持向量机原理(五) ...
- 支持向量机SMO算法实现(注释详细)
一:SVM算法 (一)见西瓜书及笔记 (二)统计学习方法及笔记 (三)推文https://zhuanlan.zhihu.com/p/34924821 (四)推文 支持向量机原理(一) 线性支持向量机 ...
- Sequential Minimal Optimization (SMO) 算法
SVM 最终关于 $a$ 目标函数为凸优化问题,该问题具有全局最优解,许多最优化算法都可以解决该问题,但当样本容量相对很大时,通常采用 SMO 算法(比如 LIBSVM),该算法为启发式算法,考虑在约 ...
- 支持向量机(Support Vector Machine)-----SVM之SMO算法(转)
此文转自两篇博文 有修改 序列最小优化算法(英语:Sequential minimal optimization, SMO)是一种用于解决支持向量机训练过程中所产生优化问题的算法.SMO由微软研究院的 ...
- 机器学习之支持向量机(二):SMO算法
注:关于支持向量机系列文章是借鉴大神的神作,加以自己的理解写成的:若对原作者有损请告知,我会及时处理.转载请标明来源. 序: 我在支持向量机系列中主要讲支持向量机的公式推导,第一部分讲到推出拉格朗日对 ...
- [笔记]关于支持向量机(SVM)中 SMO算法的学习(一)理论总结
1. 前言 最近又重新复习了一遍支持向量机(SVM).其实个人感觉SVM整体可以分成三个部分: 1. SVM理论本身:包括最大间隔超平面(Maximum Margin Classifier),拉格朗日 ...
随机推荐
- ROS tf 两个常用的函数
/** \brief Get the transform between two frames by frame ID. * \param target_frame The frame to wh ...
- [转]python3之paramiko模块(基于ssh连接进行远程登录服务器执行命令和上传下载文件的功能)
转自:https://www.cnblogs.com/zhangxinqi/p/8372774.html 阅读目录 1.paramiko模块介绍 2.paramiko的使用方法 回到顶部 1.para ...
- mac安装adb
安装 brew cask install android-platform-tools 测试 adb devices
- Windows PowerShell 入門(3)-スクリプト編
これまでの記事 Windows PowerShell 入門(1)-基本操作編 Windows PowerShell 入門(2)-基本操作編 2 対象読者 Windows PowerShellでコマンド ...
- Nginx 测试环境配置,留作笔记使用
Nginx 测试环境配置,留做笔记 以下全是配置文件的配置,如果有疑问还请移步Nginx官网参考官方文档. 环境: [root@CentOS6-M01 conf]# cat /etc/redhat-r ...
- ESXI常用命令
1.简介 VMware vSphere ESXi6.0常用命令使用,对于一些个人认为比较常用的命令进行总结,如果读者需要了解更多请访问VMware官网下载文档,链接如下:https://www.vmw ...
- Linux多台主机间配置SSH免密登陆
1.安装ssh. sudo apt-get install ssh. 安装完成后会在~目录(当前用户主目录,即这里的/home/xuhui)下产生一个隐藏文件夹.ssh(ls -a 可以查看隐藏文件 ...
- git命令(版本控制之道读书笔记)
1.在Windows中安装完git后,需要进行一下配置:$ git config --global user.name "zhangliang"$ git config --glo ...
- js 数组不重复添加元素
1 前言 由于使用JS的push会导致元素重复,而ES5之前没有set(集合)方法,重复元素还要做去重处理,比较麻烦些,所以直接写一个新push来处理 2 代码 Array.prototype.pus ...
- 14)django-模板(计数器)
模块中for循环自带计数器. 使用场景:表格数据相增加序列号. 问:可以使用表的自增加序列做为序列号,但是这个存在个问题,即表中数据被删除,则会出现序列不连续. 1)每个循环都有6个公共方法,双循环有 ...