细说shiro之七:缓存

一. 概述
Shiro作为一个开源的权限框架,其组件化的设计思想使得开发者可以根据具体业务场景灵活地实现权限管理方案,权限粒度的控制非常方便。
首先,我们来看看Shiro框架的架构图:
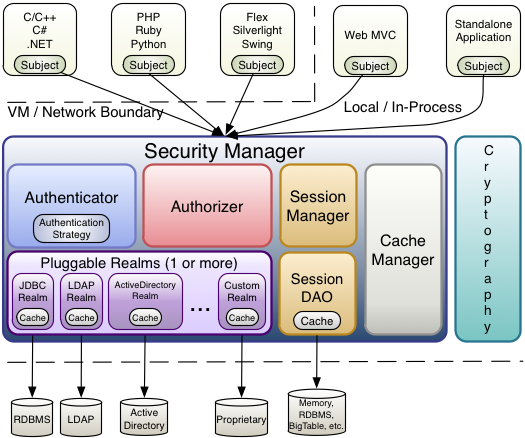
从上图我们可以很清晰地看到,CacheManager也是Shiro架构中的主要组件之一,Shiro正是通过CacheManager组件实现权限数据缓存。
当权限信息存放在数据库中时,对于每次前端的访问请求都需要进行一次数据库查询。特别是在大量使用shiro的jsp标签的场景下,对应前端的一个页面访问请求会同时出现很多的权限查询操作,这对于权限信息变化不是很频繁的场景,每次前端页面访问都进行大量的权限数据库查询是非常不经济的。因此,非常有必要对权限数据使用缓存方案。
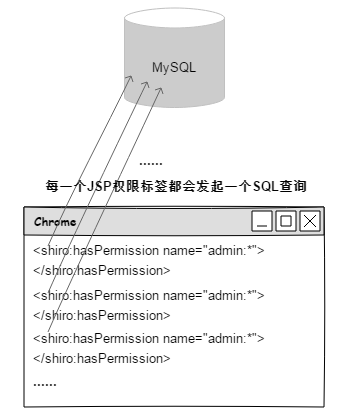
关于shiro权限数据的缓存方式,可以分为2类:其一,将权限数据缓存到集中式存储中间件中,比如redis或者memcached;其二,将权限数据缓存到本地。使用集中式缓存方案,页面的每次访问都会向缓存发起一次网络请求,如果大量使用了shiro的jsp标签,那么对应一个页面访问将会出现N个到集中缓存的网络请求,会给集中缓存组件带来一定的瞬时请求压力。另外,每个标签都需要经过一个网络查询,其实效率并不高。而采用本地缓存方式均不存在这些问题。所以,针对shiro的缓存方案,需要根据实际的使用场景进行权衡。如果在项目中并未使用shiro的jsp标签库,那么使用集中式的缓存方案也未尝不妥;但是,如果大量使用shiro的jsp标签库,那么采用本地缓存才是最佳选择。
二. 如何在shiro中使用缓存
根据Shiro官方的说法,虽然缓存在权限框架中非常重要,但是如果实现一套完整的缓存机制会使得shiro偏离了核心的功能(认证和授权)。因此,Shiro只提供了一个可以支持具体缓存实现(如:Hazelcast, Ehcache, OSCache, Terracotta, Coherence, GigaSpaces, JBossCache等)的抽象API接口,这样就允许Shiro用户根据自己的需求灵活地选择具体的CacheManager。当然,其实Shiro也自带了一个本地内存CacheManager:org.apache.shiro.cache.MemoryConstrainedCacheManager。
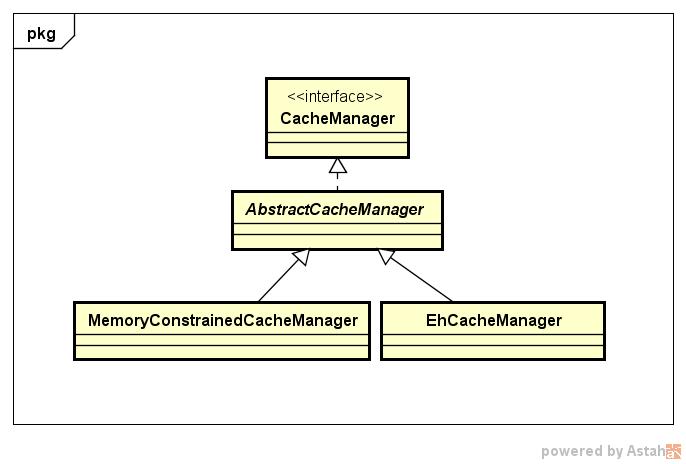
其实,从Shiro缓存组件类图可以看到,Shiro提供的缓存抽象API接口正是:org.apache.shiro.cache.CacheManager。
那么,我们应该如何配置和使用CacheManager呢?如下我们以使用Shiro提供的MemoryConstrainedCacheManager组件为例进行说明。
我们知道,SecurityManager是Shiro的核心控制器,我们来看一下其类图:
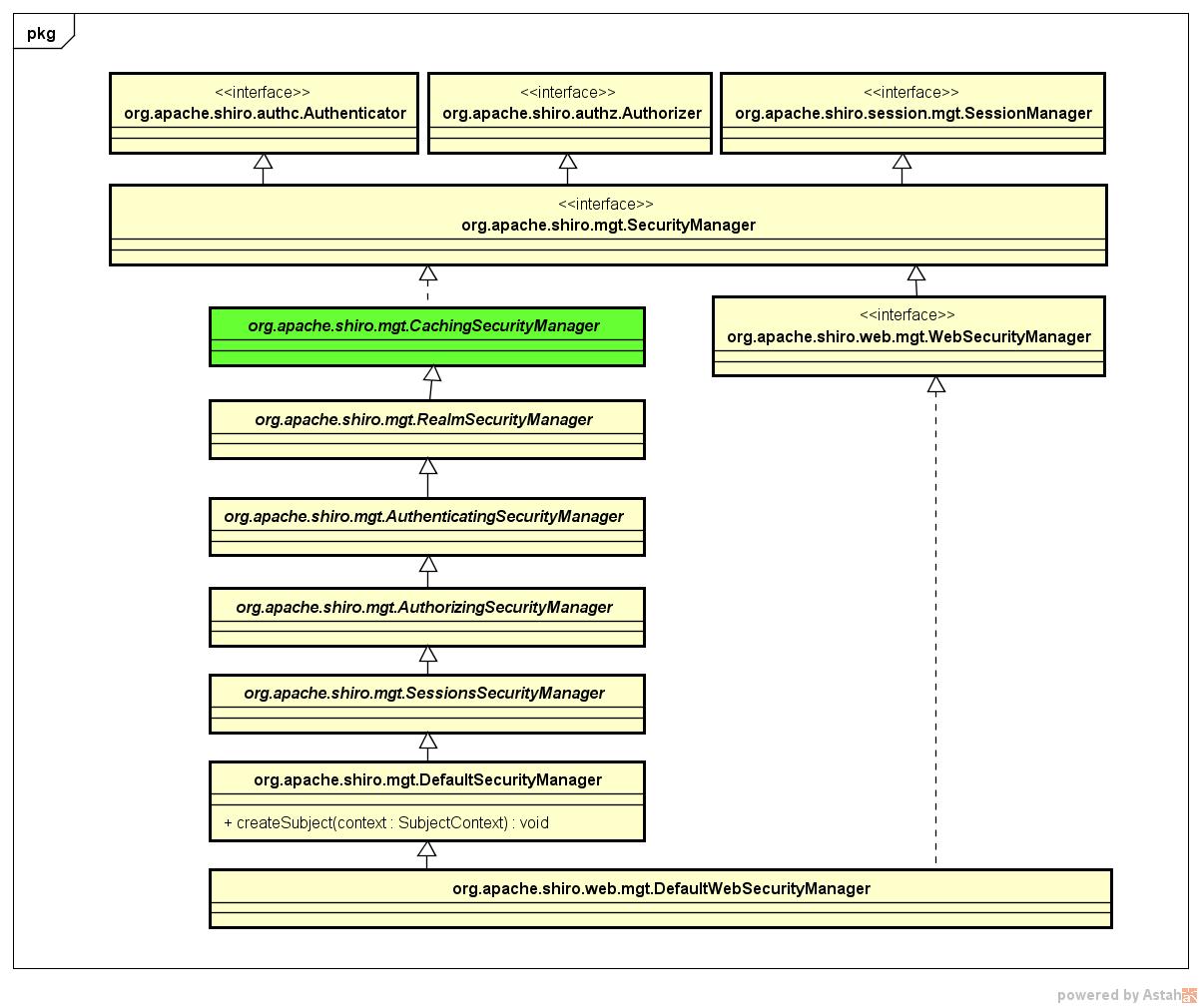
org.apache.shiro.mgt.CachingSecurityManager是Shiro中SecurityManager接口的基础抽象类,我们来看一下其源码结构:

从图中我们看到,在CachingSecurityManager中存在一个CacheManager类型的成员变量。
另外,接口org.apache.shiro.realm.Realm定义了权限数据的存储方式,我们看一下其类图:
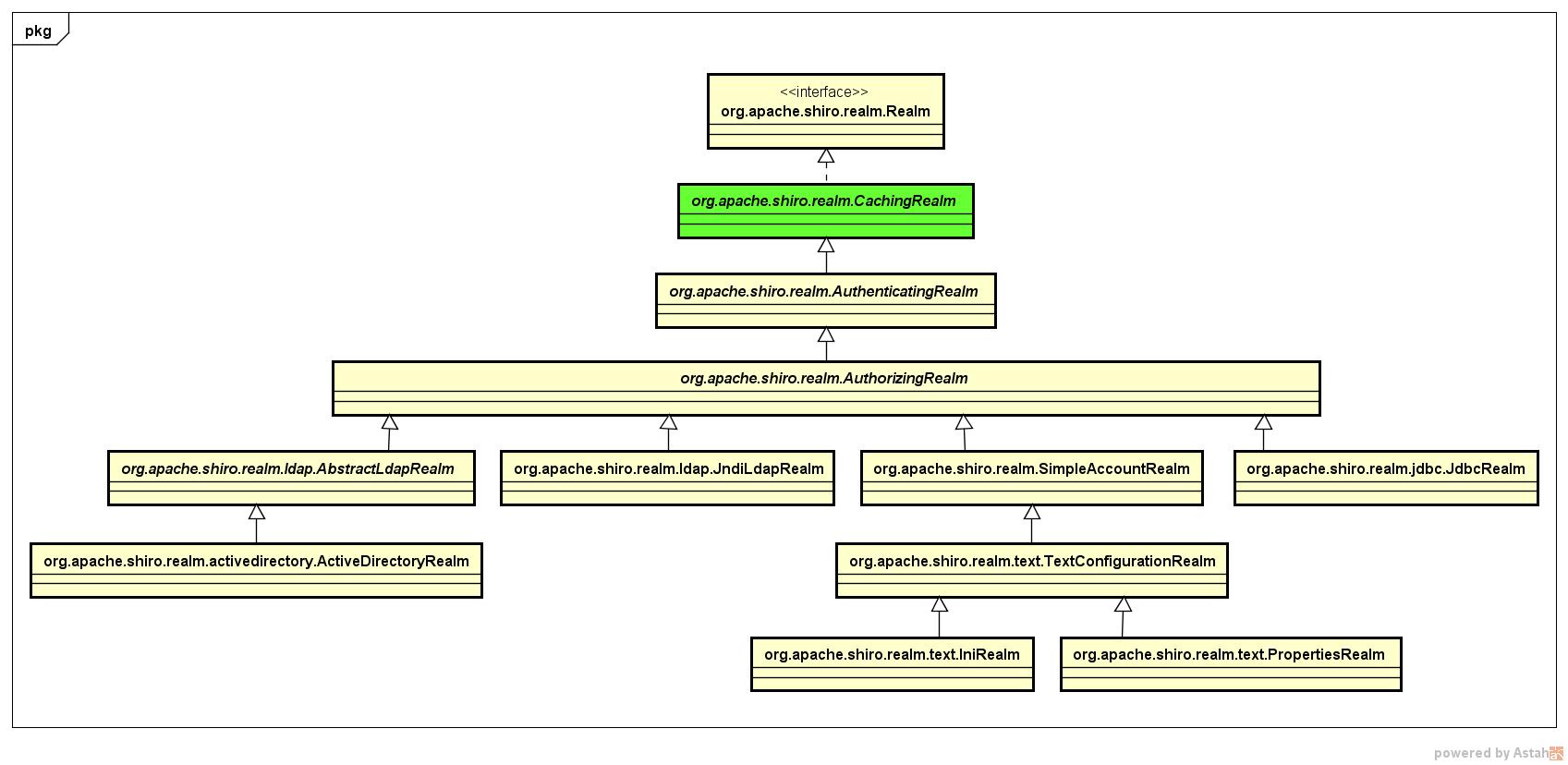
显然,org.apache.shiro.realm.CachingRealm是Shiro中Realm接口的基础实现类,我们同样来看一下其源码结构:
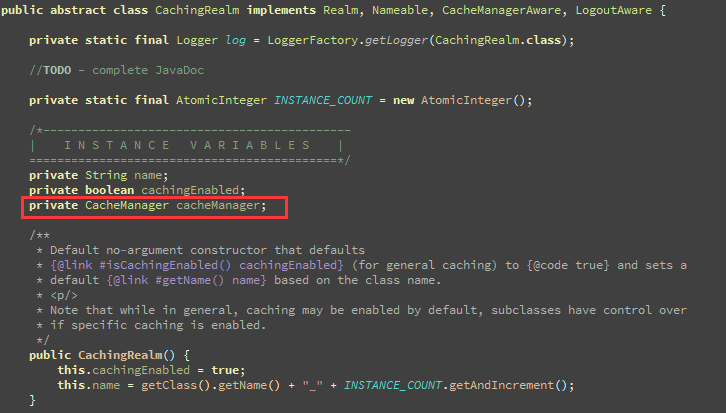
同样,在CachingRealm也存在一个CacheManager类型的成员变量。
从以上分析我们知道:Shiro支持在2个地方定义缓存管理器,既可以在SecurityManager中定义,也可以在Realm中定义,任选其一即可。
通常我们都会自定义Realm实现,例如将权限数据存放在数据库中,那么在Realm实现中定义缓存管理器再合适不过了。
举个例子,我们扩展了org.apache.shiro.realm.jdbc.JdbcRealm,在其中定义一个缓存组件。
<!-- Define the Shiro Realm implementation you want to use to connect to your back-end -->
<!-- security datasource: -->
<bean id="myRealm" class="org.chench.test.shiro.spring.dao.ShiroCacheJdbcRealm">
<property name="dataSource" ref="dataSource"/>
<property name="permissionsLookupEnabled" value="true"/>
<property name="cacheManager" ref="cacheManager" />
</bean>
<bean id="cacheManager" class="org.apache.shiro.cache.MemoryConstrainedCacheManager" />
当然,同样可以在SecurityManager中定义缓存组件:
<bean id="securityManager" class="org.apache.shiro.web.mgt.DefaultWebSecurityManager">
<!-- Single realm app. If you have multiple realms, use the 'realms' property instead. -->
<property name="realm" ref="myRealm" />
<property name="cacheManager" ref="cacheManager" />
</bean>
<bean id="cacheManager" class="org.apache.shiro.cache.MemoryConstrainedCacheManager" />
那么,我们不禁要问了:
第一:为什么Shiro要设计成既可以在Realm,也可以在SecurityManager中设置缓存管理器呢?
第二:分别在Realm和SecurityManager定义的缓存管理器,他们有什么区别或联系吗?
下面,我们追踪一下org.apache.shiro.mgt.RealmSecurityManage的源码实现:
protected void applyCacheManagerToRealms() {
CacheManager cacheManager = getCacheManager();
Collection<Realm> realms = getRealms();
if (cacheManager != null && realms != null && !realms.isEmpty()) {
for (Realm realm : realms) {
if (realm instanceof CacheManagerAware) {
((CacheManagerAware) realm).setCacheManager(cacheManager);
}
}
}
}
这下终于真相大白了吧!其实在SecurityManager中设置的CacheManager组中都会给Realm使用,即:真正使用CacheManager的组件是Realm。
三. 缓存方案
1. 集中式缓存
我们在前面分析了,使用集中式缓存方案只适用于那些没有使用shiro的jsp标签的场景,比如:前后端完全分离的项目。目前比较流行的集中式缓存组件有:Redis,Memcache等,我们可以借助于这样的集中式缓存实现shiro的缓存方案。
虽然使用了集中式缓存组件,但是不必要直接把权限数据本身存放到集中式缓存中,而是通过在集中式缓存中存放缓存标志即可。这样可以避免直接从集中式缓存中取权限数据,当权限数据比较大时,大量权限数据查询所占用的带宽也是比较可观的。
- 基于Redis的集中式缓存方案:https://github.com/alexxiyang/shiro-redis
- 基于Memcached的集中式缓存方案:https://github.com/mythfish/shiro-memcached
- 基于Ehcache集群模式的存放方案:http://www.ehcache.org/
2. 本地缓存
本地缓存的实现有几种方式:(1)直接存放到JVM堆内存(2)使用NIO存放在堆外内存,自定义实现或者借助于第三方缓存组件。
不论是采用集中式缓存还是使用本地缓存,shiro的权限数据本身都是直接存放在本地的,不同的是缓存标志的存放位置。采用本地缓存方案是,我们将缓存标志也存放在本地,这样就避免了查询缓存标志的网络请求,能更进一步提升缓存效率。
四. 缓存更新
不论是集中式缓存还是本地缓存方案,我们都需要考虑这样一个问题:如果使用了shiro框架的服务端进行了多实例部署,首先需要对session进行同步,因为shiro的认证信息是存放在session中的;其次,当前端操作在某个实例上修改了权限时,需要通知后端服务的多个实例重新获取最新的权限数据。那么有哪些方案可以实现通知到后端服务的多个实例呢?
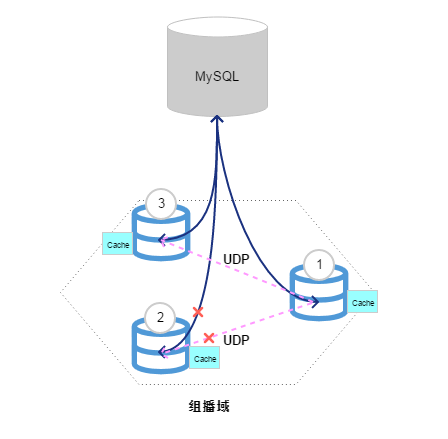
1. 组播通知
所谓组播通知即:当前端操作在后端服务的某个实例上修改了权限时,就采用组播消息的方式通知其他服务实例节点,把当前缓存的权限数据失效,重新从数据库中取最新的权限数据进行缓存。虽然组播通知非常高效,而且实现也很简单。但是,组播消息通过UDP发送,而UDP本身存在不可靠性。也就是说,如果在某个时刻发生某个修改了权限的后端服务实例发送给其他节点的组播消息丢失而导致其他节点未收到对缓存失效的通知时,将可能会导致系统的权限管理混乱,甚至导致系统不可用,并且不好排查具体是什么原因导致组播消息丢失,对于系统可用性的修复带来很大的不便利。因此,这种方式仅仅是作为一种参考实现,不在实际场景使用。
当然,组播方式有它使用的场景,但是在这里确实不适用。
2. zk通知
zookeeper最核心的功能就是统一配置,同时还可以用来实现服务注册与发现,在这里使用的zookeeper特性是:watcher机制。当某个节点的状态发生改变时,监控该节点状态的组件将会收到通知。利用这个特点,我们可以将shiro的缓存标志通过zookeeper及时通知的方式缓存在本地。当在某个后端服务节点上修改了权限时,同时修改zookeeper节点的状态,这样其他服务节点也能及时收到通知,从而可以更新自己本地的缓存标志。使用zookeeper方案的好处是:即便zookeeper节点故障了,也不会导致系统不可用,最多就是不能使用缓存数据而是每次都直接查找数据库。当zookeeper节点出现故障时后端的应用服务节点可以收到通知,更新缓存标志,并且可以发出通知。这样,我们也可以及时发现缓存方案不可用了,需要进行修复。当然,这样做的坏处就是引入了新的节点,增加了管理的复杂性。
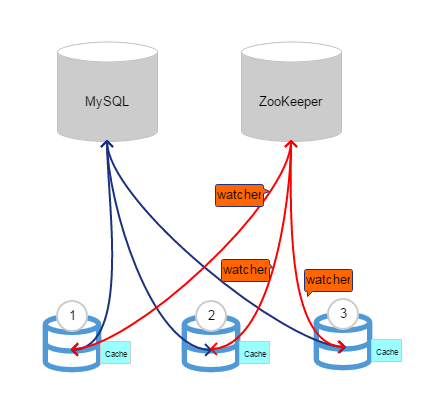
总之,使用zk方式来控制shiro的本地缓存更新比较灵活,即便是只有一个zk实例,也不会因为其单点故障导致程序不可用。而且,当zk故障恢复之后能够使得web应用的本地缓存更新机制恢复正常。
3. 具体实现
不论是组播通知还是zk通知,其目的都是为了解决缓存更新问题。那么,具体到代码实现应该怎么做呢?
举个例子,如果我们将权限数据存放在MySQL中,且自定义了JDBC Realm,那么可以在获取缓存信息时根据条件直接清空缓存即可。每次清空缓存之后,Shiro会重新从数据库中查询最新的权限数据进行缓存。缓存更新使用zk方式实现,千言万语都不如来一段代码示例:
/**
* 扩展使用了缓存组件的JDBC Realm
* @desc org.chench.test.shiro.spring.dao.ShiroCacheJdbcRealm
* @date 2017年12月14日
*/
public class ShiroCacheJdbcRealm extends JdbcRealm {
private static final Logger logger = LoggerFactory.getLogger(ShiroCacheJdbcRealm.class);
@Override
public Cache<Object, AuthorizationInfo> getAuthorizationCache() {
Cache<Object, AuthorizationInfo> cache = super.getAuthorizationCache();
if(cache == null) {
return cache;
}
if(!Constants.isConnected() || Constants.isRefresh()) {
if(logger.isWarnEnabled()) {
logger.warn("clear shiro cache");
}
cache.clear();
}
return cache;
}
}
/**
* 在应用上下文监听器中监听zk事件,从而实现shiro缓存更新通知.
* @desc org.chench.test.shiro.spring.listener.ShiroCacheListener
* @date 2017年12月13日
*/
public class ShiroCacheListener implements ServletContextListener, Watcher, StatCallback {
private Logger logger = LoggerFactory.getLogger(ShiroCacheListener.class);
private ZooKeeper zk = null;
@Override
public void contextInitialized(ServletContextEvent sce) {
logger.info("shiro cache listener context initialized");
init();
}
@Override
public void contextDestroyed(ServletContextEvent sce) {
logger.info("shiro cache listener context destroyed");
release();
}
private void init() {
try {
zk = new ZooKeeper(Constants.ZK_SERVERS, Constants.ZK_SESSION_TIMEOUT, this);
Stat stat = zk.exists(Constants.ZK_ZNODE_SHIRO_CACHE, false);
if(stat != null) {
zk.exists(Constants.ZK_ZNODE_SHIRO_CACHE, true, this, null);
return;
}
byte[] data = String.valueOf(Calendar.getInstance().getTime().getTime()).getBytes();
zk.create(Constants.ZK_ZNODE_SHIRO_CACHE, data, Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
} catch (Exception e) {
e.printStackTrace();
Constants.setRefresh(true);
}
}
private void release() {
try {
if(zk != null) {
zk.close();
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
zk = null;
}
}
@Override
public void process(WatchedEvent event) {
String path = event.getPath();
logger.info("watcher process path: " + path + " event type: " + event.getType());
if(Event.EventType.None == event.getType()) {
switch (event.getState()) {
case SyncConnected:
logger.info("watcher process SyncConnected");
Constants.setConnected(true);
break;
case Disconnected:
case Expired:
logger.info("watcher process {}", event.getState());
Constants.setConnected(false);
Constants.setRefresh(true);
break;
default:
break;
}
}else if(Event.EventType.NodeCreated == event.getType()) {
if(Constants.ZK_ZNODE_SHIRO_CACHE.equals(path)) {
zk.exists(Constants.ZK_ZNODE_SHIRO_CACHE, true, this, null);
}
}else if(Event.EventType.NodeDataChanged == event.getType()){
if(Constants.ZK_ZNODE_SHIRO_CACHE.equals(path)) {
zk.exists(Constants.ZK_ZNODE_SHIRO_CACHE, true, this, null);
Constants.setRefresh(true);
}
}else {
logger.info("do nothing");
}
}
// 读取znode数据
@Override
public void processResult(int rc, String path, Object ctx, Stat stat) {
logger.info("rc: {}, path:{}, ctx: {}, stat: {}", new Object[] {rc, path, ctx, stat});
switch (rc) {
case Code.Ok:
logger.info("statcallback proess result Ok");
break;
case Code.NoNode:
logger.info("statcallback proess result NoNode");
break;
case Code.ConnectionLoss:
logger.info("statcallback proess result ConnectionLoss");
break;
case Code.SessionExpired:
logger.info("statcallback proess result SessionExpired");
break;
case Code.OperationTimeout:
logger.info("statcallback proess result OperationTimeout");
break;
default:
zk.exists(Constants.ZK_ZNODE_SHIRO_CACHE, true, this, null);
break;
}
try {
byte[] bytes = zk.getData(Constants.ZK_ZNODE_SHIRO_CACHE, false, null);
long timestamp = Long.valueOf(new String(bytes, 0, bytes.length));
SimpleDateFormat format =new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
logger.info("修改时间: " + format.format(new Date(timestamp)));
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
【参考】
https://shiro.apache.org/caching.html
细说shiro之七:缓存的更多相关文章
- shiro之缓存
1 细说shiro之七:缓存:https://www.cnblogs.com/nuccch/p/8044226.html 2 Shiro缓存使用Redis.Ehcache.自带的MpCache实现的三 ...
- 细说shiro之一:shiro简介
官网:https://shiro.apache.org/ 一. Shiro是什么Shiro是一个Java平台的开源权限框架,用于认证和访问授权.具体来说,满足对如下元素的支持: 用户,角色,权限(仅仅 ...
- 细说shiro之二:组件架构
官网:https://shiro.apache.org/ Shiro主要组件包括:Subject,SecurityManager,Authenticator,Authorizer,SessionMan ...
- shiro 分布式缓存用户信息
很多分布式缓存登录用户信息一般都是存在redis类似的缓存里面.其中实现细节或者拆分都是大同小异. 一般用户登录权限管理都用shiro处理. 如果仔细分应该就是一下3种. 1,有一个单独的用户权限管理 ...
- Apache Shiro 会话+缓存+记住我(三)
1.会话管理SessionDao和SessionManager 1)安装Redis 2)依赖 <dependency> <groupId>redis.clients</g ...
- 细说shiro之六:session管理
官网:https://shiro.apache.org/ 我们先来看一下shiro中关于Session和Session Manager的类图. 如上图所示,shiro自己定义了一个新的Session接 ...
- 细说shiro之自定义filter
写在前面 我们知道,shiro框架在Java Web应用中使用时,本质上是通过filter方式集成的. 也就是说,它是遵循过滤器链规则的:filter的执行顺序与在web.xml中定义的顺序一致,如下 ...
- 细说shiro之五:在spring框架中集成shiro
官网:https://shiro.apache.org/ 1. 下载在Maven项目中的依赖配置如下: <!-- shiro配置 --> <dependency> <gr ...
- 细说shiro之四:在web应用中使用shiro
官网:https://shiro.apache.org/ 1. 下载在Maven项目中的依赖配置如下: <!-- shiro配置 --> <dependency> <gr ...
随机推荐
- Windows server 安装 OpenSSH
文件自己网上下载或百度云盘提取即可 执行setupssh.exe,一直 next 下去 把安装目录下的 sshd_config 文件 copy 到 C:\Program Files (x86)\Op ...
- Install Nagios (Agent) nrpe client and plugins in Ubuntu/Debian
安装apt-get install nagios-nrpe-server nagios-plugins 修改nrpe.cfgvi /etc/nagios/nrpe.cfg修改Allow Host,添加 ...
- ARC 086 E - Smuggling Marbles(dp + 启发式合并)
题意 Sunke 有一棵 \(N + 1\) 个点的树,其中 \(0\) 为根,每个点上有 \(0\) 或 \(1\) 个石子, Sunke 会不停的进行如下操作直至整棵树没有石子 : 把 \(0\) ...
- 「SHOI2014」三叉神经树 解题报告
「SHOI2014」三叉神经树 膜拜神仙思路 我们想做一个类似于动态dp的东西,首先得确保我们的运算有一个交换律,这样我们可以把一长串的运算转换成一块一块的放到矩阵上之类的东西,然后拿数据结构维护. ...
- bandwagon host
104.20.6.63 bandwagonhost.com 104.20.6.63 bwh1.net
- NOIP 飞扬的小鸟 题解
题目描述 Flappy Bird是一款风靡一时的休闲手机游戏.玩家需要不断控制点击手机屏幕的频率来调节小鸟的飞行高度,让小鸟顺利通过画面右方的管道缝隙.如果小鸟一不小心撞到了水管或者掉在地上的话,便宣 ...
- mysql查看正在执行的sql语句
有2个方法: 1.使用processlist,但是有个弊端,就是只能查看正在执行的sql语句,对应历史记录,查看不到.好处是不用设置,不会保存. -- use information_schema; ...
- 【CF1141G】Privatization of Roads in Treeland
题目大意:给定一个 N 个点的无根树,现给这个树进行染色.定义一个节点是坏点,若满足与该节点相连的至少两条边是相同的颜色,求至多有 k 个坏点的情况下最少需要几种颜色才能进行合法染色. 题解:考虑一个 ...
- TestNg 7.依赖测试
我本个测试方法执行的时候,依赖于其他的方法.用到关键字dependsOnmethods(依赖于那个方法)也有依赖于哪个组(dependsOnGroups). 看以下的一段代码: package com ...
- 关于python类变量和实例变量
今天在看python的类和实例的时候,突然发现了一个以前遗漏的点,也就是类变量和实例变量.首先需要理解一下类变量和实例变量的概念. 类全局变量:在类中定义,对类和由类生成的实例生效,如果通过方法对类变 ...