spring Mongodb查询索引报错 java.lang.NumberFormatException: empty String
最近事情比较多,本篇文章算是把遇到的问题杂糅到一起了。
背景:笔者最近在写一个mongo查询小程序,由于建立索引时字段名用大写,而查询的时候用小写。
代码如下:
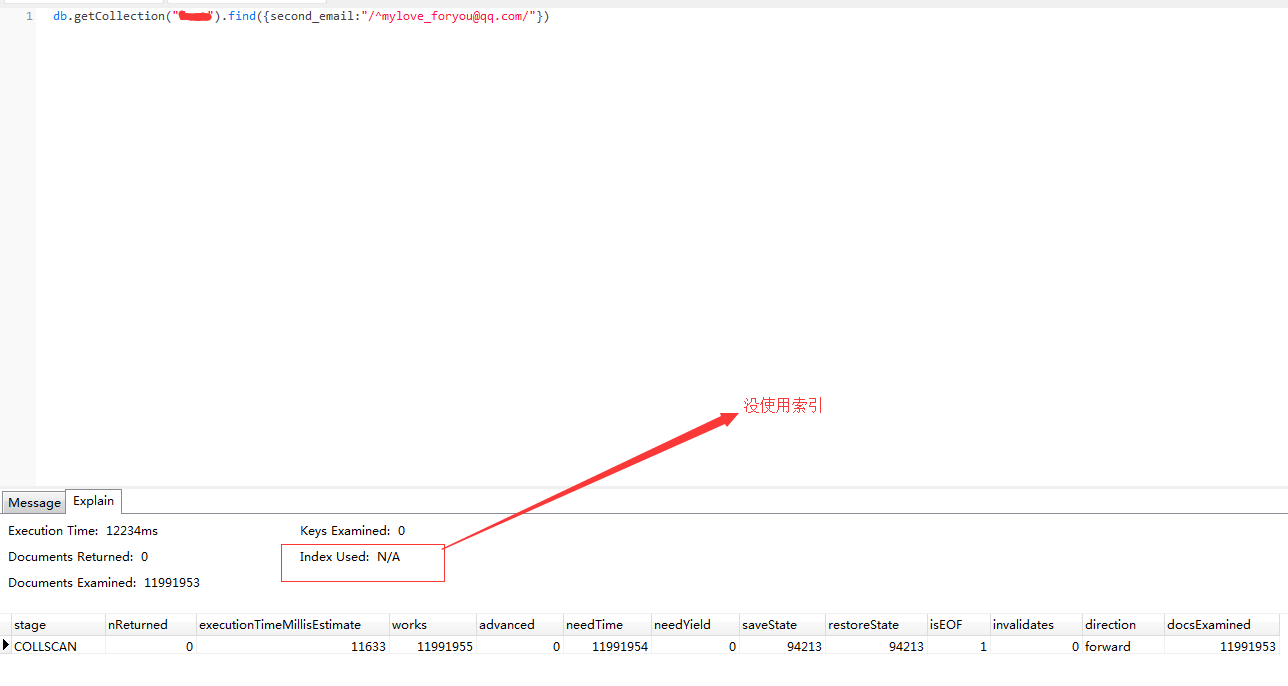
db.getCollection("xxx.aa").find({second_email:"/^mylove_foryou@qq.com/"})
1200万的数据,第一次执行耗时:43.741秒,这在正式环境肯定是不允许的。
通过查询执行计划,发现并没有使用时索引,导致查询的时候很慢。
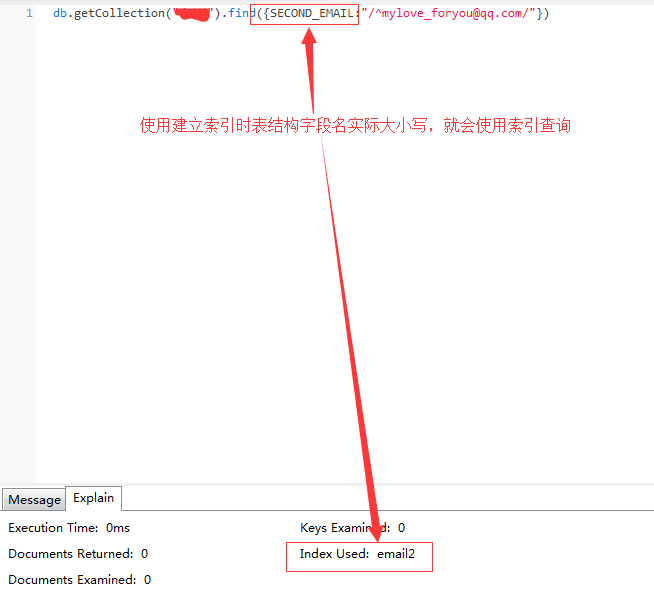
笔者在mongo3.4/4.0环境下使用以下命令创建索引,
db.getCollection("xxx.com").createIndex({
SECOND_EMAIL: ""
}, {
name: "email1"
})
而是用表结构字段大小写,则会使用索引
笔者是通过配置文件将原始字段(from属性)映射成xx系统内标准字段(to属性)名称。

由于将来还有很多不确定的表结构进来,也懒得在查询时去维护字段名大小写,
最终想到通过to属性给定的字段名,进行字符串比较,匹配对应集合(collection)中实际字段大小写,翻译成建立索引的字段名。
例如查询时使用realname,而建立索引使用second_email,通过遍历索引,把second_email转译成SECOND_EMAIL,以便使用索引。
于是编写执行以下demo查询索引
mongoTemplate.indexOps(collection).getIndexInfo(); #笔者正式环境不是这么写的,这里方便大家理解,使用语法糖式代码 ;p
每次走到xxx.com表的时候总是报错
Exception in thread "Configuration Initializer" java.lang.NumberFormatException: empty String
at sun.misc.FloatingDecimal.readJavaFormatString(FloatingDecimal.java:1842)
at sun.misc.FloatingDecimal.parseDouble(FloatingDecimal.java:110)
at java.lang.Double.parseDouble(Double.java:538)
at java.lang.Double.<init>(Double.java:608)
at org.springframework.data.mongodb.core.IndexConverters.lambda$getDocumentIndexInfoConverter$1(IndexConverters.java:147)
at org.springframework.data.mongodb.core.DefaultIndexOperations$1.getIndexData(DefaultIndexOperations.java:126)
at org.springframework.data.mongodb.core.DefaultIndexOperations$1.doInCollection(DefaultIndexOperations.java:116)
at org.springframework.data.mongodb.core.DefaultIndexOperations$1.doInCollection(DefaultIndexOperations.java:110)
at org.springframework.data.mongodb.core.DefaultIndexOperations.execute(DefaultIndexOperations.java:141)
at org.springframework.data.mongodb.core.DefaultIndexOperations.getIndexInfo(DefaultIndexOperations.java:110)
at com.xmd.model.db.MongoDBHelper$1.run(MongoDBHelper.java:97)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
本地是jar版本是托管给maven,笔者本地mongodb配置如下
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-commons</artifactId>
<version>2.0.0.M1</version>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-mongodb</artifactId>
<version>2.0.0.M1</version>
</dependency>
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>bson</artifactId>
<version>3.9.1</version>
</dependency>
如果使用2.0.1版本则不需要那个bson的jar包,最初怀疑是框架bug,想整合新版本(2.13)进去,浪费了好久时间最终没能成功。
又回到了2.0.0.M1,最终硬着头皮调试。
用navicat mongo查看索引,的确是没有排序

后来想到mongo控制台创建索引有1,-1两个值,1是正序 -1是倒序;而笔者创建索引时指定了空字符串,格式化自然就失败了,于是到官方查询文档
db.collection.createIndex(keys, options)
For an ascending index on a field, specify a value of 1; for descending index, specify a value of -1.
问题的症结就是没有建立索引,到这里基本解决问题了,方法如下:
1、删除索引
db.getCollection('xxx.com').dropIndex("mobile_mac")
2、重建索引
db.getCollection("xxx.com").createIndex({
mobile: 1
}, {
name: "mobile_mac"
})
spring Mongodb查询索引报错 java.lang.NumberFormatException: empty String的更多相关文章
- Exception in thread “main” com.google.gson.JsonSyntaxException: java.lang.NumberFormatException: empty String
String json="A valid json"; Job job = new Gson().fromJson(json, Job.class); Exception in t ...
- hadoop ha环境下的datanode启动报错java.lang.NumberFormatException: For input string: "10m"
hadoop ha环境启动start-dfs.sh的时候datanode启动不了,并且报错. [hadoop@datanode2 ~]$ cat /home/hadoop/hadoop-2.7.3/l ...
- mybatis mapper.xml 写关联查询 运用 resultmap 结果集中 用 association 关联其他表 并且 用 association 的 select 查询值 报错 java.lang.IllegalArgumentException: Mapped Statements collection does not contain value for mybatis.map
用mybaits 写一个关联查询 查询商品表关联商品规格表,并查询规格表中的数量.价格等,为了sql重用性,利用 association 节点 查询 结果并赋值报错 商品表的mapper文件为Gooo ...
- java.lang.NumberFormatException: empty String 错误
原因:前台获取的字符串,后台类型转换,与之对应的实体类中却是Integer类型,所以会报错. 排错情况:1.先检查数据库与实体类中的类型是否一致 2.检查类型转换代码,如果需要加入异常处理
- 解决 Spring Oauth2 RedisTokenStore storeAccessToken 报错 java.lang.NoSuchMethodError: org.springframework.data.redis.connection.RedisConnection.set
原因是Spring 版本兼容问题 参考: https://blog.csdn.net/smollsnail/article/details/78954225 继承 RedisTokenStore 修改 ...
- solr索引报错(java.lang.OutOfMemoryError:GC overhead limit exceeded)
配置文件修改如下: <dataSource driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3 ...
- Window启动Zookeeper报错java.lang.NumberFormatException: For input string:
用zkServer start命令报如题的错误,改为直接用zkServer启动则ok 还有在window下,myid文件不能是myid.txt,不能带文件格式 dataDir=D:/zookeeper ...
- Spring boot Unable to start embedded Tomcat报错 java.lang.NoSuchMethodError: javax.servlet.ServletContext.getVirtualServerName()
Spring boot Unable to start embedded Tomcat 报错 java.lang.NoSuchMethodError: javax.servlet.ServletCon ...
- 解决spring boot启动报错java.lang.NoClassDefFoundError: ch/qos/logback/classic/Level
解决spring boot启动报错java.lang.NoClassDefFoundError: ch/qos/logback/classic/Level 学习了:https://blog.csdn. ...
随机推荐
- rabbitmq (五)RPC
Remote Procedure Call or RPC(远程函数调用) 当我们需要在远程计算机上运行一个函数,并且等待结果的时候,我们用到RPC 在rabbitmq客户端使用call函数,发送RPC ...
- jquery中文档处理的总结
jQuery文档处理总结 1.返回值:append(content|fn) $("p").append("<b>Hello</b>"); ...
- python selenium 基本常用操作
最近学习UI自动化,把一些常用的方法总结一下,方便自己以后查阅需要.因本人水平有限,有不对之处多多包涵!欢迎指正! 一.xpath模糊匹配定位元素 武林至尊,宝刀屠龙刀(xpath),倚天不出(css ...
- C# xml 读xml、写xml、Xpath、Xml to Linq、xml添加节点 xml修改节点
#region XDocument //创建XDocument XDocument xdoc2 = new XDocument(); XElement xel1= new XElement(" ...
- oracle入坑日记<四>表空间
1 表空间是什么 1.1.数据表看做的货品,表空间就是存放货品的仓库.SQLserver 用户可以把表空间看做 SQLserver 中的数据库. 1.2.引用[日记二]的总结来解释表空间. 一个数 ...
- [SQL]删除约束
来源:http://www.archonsystems.com/devblog/2012/05/25/how-to-drop-a-column-with-a-default-value-constra ...
- TinkPHP框架学习-01基本知识
1-----目录结构 2-----访问地址 3-----MVC开发 一 目录结构 |--Application 程序文件夹 |--Common 公共方法函数 |--Home 模块 |也可以自 ...
- docker 独立搭建linux + php 随笔
参考了 https://www.jianshu.com/p/fcd0e542a6b2 dodos大佬的一些经验 1.首先,由于nginx跟php的特性,使得二者可以单独作为独立容器存在,所以为了使h ...
- 每日算法之递推排序(P1866 编号)
兔子也是数字控:每个兔子都有自己喜欢的数字区间,找出能让所有兔子都满意的组合. 将所有兔子喜欢的序号按从小到大排序,此时如果小序号的兔子选择了一个数字,则之后的兔子只要排除排在它之前的兔子数(由于已经 ...
- Servlet学习记录4
带进度条的文件上传 UploadServlet只实现了普通的文件上传,并附带普通文本域的提交.如果需要显示上传进度条,实时显示上传速度等,需要配合使用Ajax技术.这里仍然使用Apache的commo ...