java itext替换PDF中的文本
itext没有提供直接替换PDF文本的接口,我们可以通过在原有的文本区域覆盖一个遮挡层,再在上面加上文本来实现。
所需jar包:
1.先在PDF需要替换的位置覆盖一个白色遮挡层(颜色可根据PDF文字背景色自行定义)
import com.itextpdf.text.BaseColor;
import com.itextpdf.text.DocumentException;
import com.itextpdf.text.pdf.PdfContentByte;
import com.itextpdf.text.pdf.PdfReader;
import com.itextpdf.text.pdf.PdfStamper;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException; /**
* <p>PDF增加遮盖层<p>
* @version 1.0
* @author li_hao
* @date 2018年3月14日
*/
public class HighLightByAddingContent { public void manipulatePdf(String src, String dest) throws IOException, DocumentException {
PdfReader reader = new PdfReader(src);
PdfStamper stamper = new PdfStamper(reader, new FileOutputStream(dest));
PdfContentByte canvas = stamper.getUnderContent(1); //不可遮挡文字
// PdfContentByte canvas = stamper.getOverContent(1); //可以遮挡文字
canvas.saveState();
canvas.setColorFill(BaseColor.YELLOW); //黄色遮挡层
// canvas.setColorFill(BaseColor.WHITE); //白色遮挡层
canvas.rectangle(116, 726, 66, 16);
canvas.fill();
canvas.restoreState();
stamper.close();
reader.close();
} /**
* 测试
*/
public static void main(String[] args) throws IOException, DocumentException { String SRC = "D:/testpdf/test.pdf";
String DEST = "D:/testpdf/test2.pdf"; File file = new File(DEST);
file.getParentFile().mkdirs();
new HighLightByAddingContent().manipulatePdf(SRC, DEST);
}
}
测试结果(不遮挡文字+黄色背景):
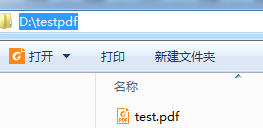
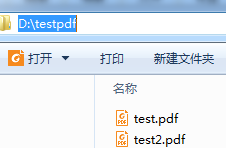


测试结果(遮挡文字+白色背景):

2. PDF增加遮盖层+文字
import com.itextpdf.text.BaseColor;
import com.itextpdf.text.DocumentException;
import com.itextpdf.text.Font;
import com.itextpdf.text.pdf.BaseFont;
import com.itextpdf.text.pdf.PdfContentByte;
import com.itextpdf.text.pdf.PdfReader;
import com.itextpdf.text.pdf.PdfStamper;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException; /**
* <p>PDF增加遮盖层+文字<p>
* @version 1.0
* @author li_hao
* @date 2018年3月13日
*/
public class HighLightByAddingContent { public void manipulatePdf(String src, String dest) throws IOException, DocumentException {
PdfReader reader = new PdfReader(src);
PdfStamper stamper = new PdfStamper(reader, new FileOutputStream(dest));
//添加一个遮挡处,可以把原内容遮住,后面在上面写入内容
// PdfContentByte canvas = stamper.getUnderContent(1); //不可以遮挡文字
PdfContentByte canvas = stamper.getOverContent(1); //可以遮挡文字 float height=780;
System.out.println(canvas.getHorizontalScaling());
float x,y;
x= 116;
y = height -49.09F;
canvas.saveState();
canvas.setColorFill(BaseColor.YELLOW); //遮挡层颜色:黄色
// canvas.setColorFill(BaseColor.WHITE); //遮挡层颜色:白色
canvas.rectangle(x, y-5, 43, 15); canvas.fill();
canvas.restoreState();
//开始写入文本
canvas.beginText();
//BaseFont bf = BaseFont.createFont(URLDecoder.decode(CutAndPaste.class.getResource("/AdobeSongStd-Light.otf").getFile()), BaseFont.IDENTITY_H, BaseFont.EMBEDDED);
BaseFont bf = BaseFont.createFont("STSong-Light", "UniGB-UCS2-H", BaseFont.EMBEDDED);
Font font = new Font(bf,10,Font.BOLD);
//设置字体和大小
canvas.setFontAndSize(font.getBaseFont(), 10);
//设置字体的输出位置
canvas.setTextMatrix(x, y);
//要输出的text
canvas.showText("我是替换" ); canvas.endText();
stamper.close();
reader.close();
System.out.println("complete");
} /**
* 测试
*/
public static void main(String[] args) throws IOException, DocumentException {
String SRC = "D:/testpdf/test.pdf";
String DEST = "D:/testpdf/test_a.pdf";
File file = new File(DEST);
file.getParentFile().mkdirs();
new HighLightByAddingContent().manipulatePdf(SRC, DEST);
}
}
测试结果:

下面是自动查找旧文字替换新文字完整代码:
1. 需要替换的区域
/**
* <p>需要替换的区域 <p>
* @version 1.0
* @author li_hao
* @date 2018年3月14日
*/
public class ReplaceRegion { private String aliasName;
private Float x;
private Float y;
private Float w;
private Float h; public ReplaceRegion(String aliasName){
this.aliasName = aliasName;
} /**
* 替换区域的别名
* @return
*/
public String getAliasName() {
return aliasName;
}
public void setAliasName(String aliasName) {
this.aliasName = aliasName;
}
public Float getX() {
return x;
}
public void setX(Float x) {
this.x = x;
}
public Float getY() {
return y;
}
public void setY(Float y) {
this.y = y;
}
public Float getW() {
return w;
}
public void setW(Float w) {
this.w = w;
}
public Float getH() {
return h;
}
public void setH(Float h) {
this.h = h;
}
}
2. 解析PDF中文本的x,y位置
import java.io.FileInputStream;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import com.itextpdf.text.pdf.PdfReader;
import com.itextpdf.text.pdf.parser.PdfReaderContentParser; /**
* <p>解析PDF中文本的x,y位置<p>
* @version 1.0
* @author li_hao
* @date 2018年3月14日
*/
public class PdfPositionParse { private PdfReader reader;
private List<String> findText = new ArrayList<String>(); //需要查找的文本
private PdfReaderContentParser parser; public PdfPositionParse(String fileName) throws IOException{
FileInputStream in = null;
try{
in =new FileInputStream(fileName);
byte[] bytes = new byte[in.available()];
in.read(bytes);
init(bytes);
}finally{
in.close();
}
} public PdfPositionParse(byte[] bytes) throws IOException{
init(bytes);
} private boolean needClose = true;
/**
* 传递进来的reader不会在PdfPositionParse结束时关闭
* @param reader
*/
public PdfPositionParse(PdfReader reader){
this.reader = reader;
parser = new PdfReaderContentParser(reader);
needClose = false;
} public void addFindText(String text){
this.findText.add(text);
} private void init(byte[] bytes) throws IOException {
reader = new PdfReader(bytes);
parser = new PdfReaderContentParser(reader);
} /**
* 解析文本
* @return
* @throws IOException
*/
public Map<String, ReplaceRegion> parse() throws IOException{
try{
if(this.findText.size() == 0){
throw new NullPointerException("没有需要查找的文本");
}
PositionRenderListener listener = new PositionRenderListener(this.findText);
parser.processContent(1, listener);
return listener.getResult();
}finally{
if(reader != null && needClose){
reader.close();
}
}
}
}
3. PDF渲染监听,当找到渲染的文本时,得到文本的坐标x,y,w,h
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import com.itextpdf.awt.geom.Rectangle2D.Float;
import com.itextpdf.text.pdf.parser.ImageRenderInfo;
import com.itextpdf.text.pdf.parser.RenderListener;
import com.itextpdf.text.pdf.parser.TextRenderInfo; /**
* <p>pdf渲染监听,当找到渲染的文本时,得到文本的坐标x,y,w,h<p>
* @version 1.0
* @author li_hao
* @date 2018年3月14日
*/
public class PositionRenderListener implements RenderListener{ private List<String> findText;
private float defaultH; ///出现无法取到值的情况,默认为12
private float fixHeight; //可能出现无法完全覆盖的情况,提供修正的参数,默认为2
public PositionRenderListener(List<String> findText, float defaultH,float fixHeight) {
this.findText = findText;
this.defaultH = defaultH;
this.fixHeight = fixHeight;
} public PositionRenderListener(List<String> findText) {
this.findText = findText;
this.defaultH = 12;
this.fixHeight = 2;
} @Override
public void beginTextBlock() { } @Override
public void endTextBlock() { } @Override
public void renderImage(ImageRenderInfo imageInfo) {
} private Map<String, ReplaceRegion> result = new HashMap<String, ReplaceRegion>();
@Override
public void renderText(TextRenderInfo textInfo) {
String text = textInfo.getText();
for (String keyWord : findText) {
if (null != text && text.equals(keyWord)){
Float bound = textInfo.getBaseline().getBoundingRectange();
ReplaceRegion region = new ReplaceRegion(keyWord);
region.setH(bound.height == 0 ? defaultH : bound.height);
region.setW(bound.width);
region.setX(bound.x);
region.setY(bound.y-this.fixHeight);
result.put(keyWord, region);
}
}
} public Map<String, ReplaceRegion> getResult() {
for (String key : findText) { //补充没有找到的数据
if(this.result.get(key) == null){
this.result.put(key, null);
}
}
return this.result;
}
}
4. 替换PDF文件某个区域内的文本
import java.io.ByteArrayOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
import com.itextpdf.text.BaseColor;
import com.itextpdf.text.DocumentException;
import com.itextpdf.text.Font;
import com.itextpdf.text.log.Logger;
import com.itextpdf.text.log.LoggerFactory;
import com.itextpdf.text.pdf.BaseFont;
import com.itextpdf.text.pdf.PdfContentByte;
import com.itextpdf.text.pdf.PdfReader;
import com.itextpdf.text.pdf.PdfStamper; /**
* <p>替换PDF文件某个区域内的文本 <p>
* @version 1.0
* @author li_hao
* @date 2018年3月14日
*/
public class PdfReplacer {
private static final Logger logger = LoggerFactory.getLogger(PdfReplacer.class); private int fontSize;
private Map<String, ReplaceRegion> replaceRegionMap = new HashMap<String, ReplaceRegion>();
private Map<String, Object> replaceTextMap =new HashMap<String, Object>();
private ByteArrayOutputStream output;
private PdfReader reader;
private PdfStamper stamper;
private PdfContentByte canvas;
private Font font; public PdfReplacer(byte[] pdfBytes) throws DocumentException, IOException{
init(pdfBytes);
} public PdfReplacer(String fileName) throws IOException, DocumentException{
FileInputStream in = null;
try{
in =new FileInputStream(fileName);
byte[] pdfBytes = new byte[in.available()];
in.read(pdfBytes);
init(pdfBytes);
}finally{
in.close();
}
} private void init(byte[] pdfBytes) throws DocumentException, IOException{
logger.info("初始化开始");
reader = new PdfReader(pdfBytes);
output = new ByteArrayOutputStream();
stamper = new PdfStamper(reader, output);
canvas = stamper.getOverContent(1);
setFont(10);
logger.info("初始化成功");
} private void close() throws DocumentException, IOException{
if(reader != null){
reader.close();
}
if(output != null){
output.close();
} output=null;
replaceRegionMap=null;
replaceTextMap=null;
} public void replaceText(float x, float y, float w,float h, String text){
ReplaceRegion region = new ReplaceRegion(text); //用文本作为别名
region.setH(h);
region.setW(w);
region.setX(x);
region.setY(y);
addReplaceRegion(region);
this.replaceText(text, text);
} public void replaceText(String name, String text){
this.replaceTextMap.put(name, text);
} /**
* 替换文本
* @throws DocumentException
* @throws IOException
*/
private void process() throws DocumentException, IOException{
try{
parseReplaceText();
canvas.saveState();
Set<Entry<String, ReplaceRegion>> entrys = replaceRegionMap.entrySet();
for (Entry<String, ReplaceRegion> entry : entrys) {
ReplaceRegion value = entry.getValue();
canvas.setColorFill(BaseColor.WHITE);
canvas.rectangle(value.getX(),value.getY(),value.getW(),value.getH());
}
canvas.fill();
canvas.restoreState();
//开始写入文本
canvas.beginText();
for (Entry<String, ReplaceRegion> entry : entrys) {
ReplaceRegion value = entry.getValue();
//设置字体
canvas.setFontAndSize(font.getBaseFont(), getFontSize());
canvas.setTextMatrix(value.getX(),value.getY()+2/*修正背景与文本的相对位置*/);
canvas.showText((String) replaceTextMap.get(value.getAliasName()));
}
canvas.endText();
}finally{
if(stamper != null){
stamper.close();
}
}
} /**
* 未指定具体的替换位置时,系统自动查找位置
*/
private void parseReplaceText() {
PdfPositionParse parse = new PdfPositionParse(reader);
Set<Entry<String, Object>> entrys = this.replaceTextMap.entrySet();
for (Entry<String, Object> entry : entrys) {
if(this.replaceRegionMap.get(entry.getKey()) == null){
parse.addFindText(entry.getKey());
}
} try {
Map<String, ReplaceRegion> parseResult = parse.parse();
Set<Entry<String, ReplaceRegion>> parseEntrys = parseResult.entrySet();
for (Entry<String, ReplaceRegion> entry : parseEntrys) {
if(entry.getValue() != null){
this.replaceRegionMap.put(entry.getKey(), entry.getValue());
}
}
} catch (IOException e) {
logger.error(e.getMessage(), e);
} } /**
* 生成新的PDF文件
* @param fileName
* @throws DocumentException
* @throws IOException
*/
public void toPdf(String fileName) throws DocumentException, IOException{
FileOutputStream fileOutputStream = null;
try{
process();
fileOutputStream = new FileOutputStream(fileName);
fileOutputStream.write(output.toByteArray());
fileOutputStream.flush();
}catch(IOException e){
logger.error(e.getMessage(), e);
throw e;
}finally{
if(fileOutputStream != null){
fileOutputStream.close();
}
close();
}
logger.info("文件生成成功");
} /**
* 将生成的PDF文件转换成二进制数组
* @return
* @throws DocumentException
* @throws IOException
*/
public byte[] toBytes() throws DocumentException, IOException{
try{
process();
logger.info("二进制数据生成成功");
return output.toByteArray();
}finally{
close();
}
} /**
* 添加替换区域
* @param replaceRegion
*/
public void addReplaceRegion(ReplaceRegion replaceRegion){
this.replaceRegionMap.put(replaceRegion.getAliasName(), replaceRegion);
} /**
* 通过别名得到替换区域
* @param aliasName
* @return
*/
public ReplaceRegion getReplaceRegion(String aliasName){
return this.replaceRegionMap.get(aliasName);
} public int getFontSize() {
return fontSize;
} /**
* 设置字体大小
* @param fontSize
* @throws DocumentException
* @throws IOException
*/
public void setFont(int fontSize) throws DocumentException, IOException{
if(fontSize != this.fontSize){
this.fontSize = fontSize;
BaseFont bf = BaseFont.createFont("STSong-Light", "UniGB-UCS2-H", BaseFont.EMBEDDED); //使用iTextAsian.jar中的字体
// BaseFont bf = BaseFont.createFont("C:/WINDOWS/Fonts/STSONG.TTF", BaseFont.IDENTITY_H,BaseFont.NOT_EMBEDDED); //使用Windows系统字体(TrueType)
// BaseFont bf = BaseFont.createFont("/STSONG.TTF", BaseFont.IDENTITY_H,BaseFont.NOT_EMBEDDED); //使用资源字体(ClassPath) font = new Font(bf,this.fontSize,Font.BOLD);
}
} public void setFont(Font font){
if(font == null){
throw new NullPointerException("font is null");
}
this.font = font;
} /**
* 测试
*/
public static void main(String[] args) throws IOException, DocumentException {
PdfReplacer textReplacer = new PdfReplacer("D:/testpdf/test.pdf");
textReplacer.replaceText("我是测试名称", "李大锤李大锤李大锤");
textReplacer.replaceText("我是测试内容", "张三丰张三丰张三丰");
textReplacer.toPdf("D:/testpdf/test3.pdf");
}
}
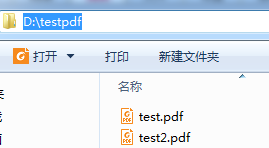
测试结果:


以上就是java使用itext替换PDF中的文本的代码,在替换文本时可以自动查找文本的内容,当然也可以自定义坐标区域替换。
注:如果不好确定替换区域的坐标位置,而PDF对应区域又是空白的话,可以在生成PDF的时候,在需要替换的区域先写入“特定文字内容”,预设的文字颜色设置和背景色相同,这样PDF看起来似乎是空的,但是却可以用查找文本的方式替换,替换后的就能显示出替换后的内容了,这样有时候可以方便很多。
附:替换后的文本在PC端、Android端、iOS端都是可以打开和使用,在HTML5开发时使用PDF.js插件时发现替换后的字体不显示的情况,这是由于PDF.js插件不识别iTextAsign.jar中的字体,把:BaseFont bf = BaseFont.createFont("STSong-Light", "UniGB-UCS2-H", BaseFont.EMBEDDED)做下修改,可以使用Windows中的字体:BaseFont bf = BaseFont.createFont("C:/WINDOWS/Fonts/STSONG.TTF", BaseFont.IDENTITY_H,BaseFont.NOT_EMBEDDED),字体和路径路径可以自行设置,linux中先安装中文字体库,再使用相应字体的路径即可。替换字体后,网页中使用PDF.js插件也没问题了。
源码:https://github.com/piaoliudelaoyaoguai/pdfReplaceWordsDemo.git
java itext替换PDF中的文本的更多相关文章
- 使用itext直接替换PDF中的文本
直接说问题,itext没有直接提供替换PDF中文本的接口(查看资料得到的结论是PDF不支持这种操作),不过存在解决思路:在需要替换的文本上覆盖新的文本.按照这个思路我们需要解决以下几个问题: itex ...
- Java 替换PDF中的字体
文档中可通过应用不同的字体来呈现不一样的视觉效果,通过字体来实现文档布局.排版等设计需要.应用字体时,可在创建文档时指定字体,也可以用新字体去替换文档中已有的字体.下面,以Java代码展示如何来替换P ...
- servlet操作本地文件汇总: 判断文件是否存在;文件重命名;文件复制; 获取文件属性信息,转成Json对象; 获取指定类型的文件; 查找替换.txt中的文本
package servlet; import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; ...
- Java Itext 生成PDF文件
利用Java Itext生成PDF文件并导出,实现效果如下: PDFUtil.java package com.jeeplus.modules.order.util; import java.io.O ...
- C# 设置或验证 PDF中的文本域格式
概述 PDF中的文本域可以通过设置不同格式,用于显示数字.货币.日期.时间.邮政编码.电话号码和社保号等等.Adobe Acrobat提供了许多固定的JavaScripts用来设置和验证文本域的格式, ...
- Java 读取PDF中的文本和图片
本文将介绍通过Java程序来读取PDF文档中的文本和图片的方法.分别调用方法extractText()和extractImages()来读取. 使用工具:Free Spire.PDF for Ja ...
- Java 设置PDF中的文本旋转、倾斜
本文介绍通过Java程序在PDF文档中设置文本旋转.倾斜的方法.设置文本倾斜时,通过定义方法TransformText(page);并设置page.getCanvas().skewTransform( ...
- java 如何在pdf中生成表格
1.目标 在pdf中生成一个可变表头的表格,并向其中填充数据.通过泛型动态的生成表头,通过反射动态获取实体类(我这里是User)的get方法动态获得数据,从而达到动态生成表格. 每天生成一个文件夹存储 ...
- Java动态替换InetAddress中DNS的做法简单分析1
在java.net包描述中, 简要说明了一些关键的接口. 其中负责networking identifiers的是Addresses. 这个类的具体实现类是InetAddress, 底层封装了Inet ...
随机推荐
- 京东饭粒捡漏V1.1.0
20180624 更新 V1.1.01.解决进程残留问题:2.加入急速下单模式: 功能介绍1.京东商城专用,支持饭粒模式下单,自己获得京豆返利 2.捡漏模式:帮助用户监控抢购商品,有库存的时候进行抢单 ...
- 记一次gitlab-ce数据恢复过程
使用的gitlab是用docker启动的,数据目录的owner/group信息被意外全部更改成了root:root导致服务不可用.最终通过复原文件所有者的方式恢复了服务. 步骤如下: 1. 打包备份g ...
- 刘志梅201771010115.《面向对象程序设计(java)》第十七周学习总结
实验十七 线程同步控制 实验时间 2018-12-10 1.实验理论知识 多线程 多线程是进程执行过程中产生的多条执行线索.进程 线程是比进程执行更小的单位.线程不能独立存在,必须存在于 ...
- Layout-2相关代码:3列布局代码演化[一]
<!doctype html> <html> <head> <meta charset="utf-8"> <title> ...
- hive 一次更新多个分区的数据
类似订单数据之类的表,因为有状态要更新,比如订单状态,物流状态之类的, 这样就需要同步很久之前的数据,目前我的订单表是更新前面100天的数据. hive中操作是先删除前面100个分区的数据,然后重新动 ...
- ubuntu环境部署项目
安装python3.6 第一步:sudo add-apt-repository ppa:jonathonf/python-3.6 如果报错为:sudo: add-apt-repository: com ...
- 判断单向连通图(拓扑排序+tarjan缩点)
题意: 给你一个有向图,如果对于图中的任意一对点u和v都有一条从u到v的路或从v到u的路,那么就输出’Yes’,否则输出’No’. 理解:当出现两个及以上入度为0的点(有一个就可能是别人到它,有两个的 ...
- 学习笔记:python3,PIP安装第三方库(2017)
https://pip.pypa.io/en/latest/quickstart/ pip的使用文档 http://www.lfd.uci.edu/~gohlke/pythonlibs/ .whl ...
- 关于各种O,DO/BO/DTO/VO/AO/PO
阿里巴巴Java开发手册 链接:https://pan.baidu.com/s/11I9ViOrat-Bw_HA8yItXwA 密码:x5yi 2. DO/BO/DTO/VO/AO/PO PO(per ...
- 打造适合自己的vim编辑器方法总结
vim使用方法总结 说明:这是打造适合自己的vim编辑器的进阶方法,关于vim基础知识,请自行百度.也可参考文章末尾推荐blog网址 如果觉得自己打造vim编辑器麻烦,可以从github上面克隆一个, ...