Forward团队-爬虫豆瓣top250项目-开发文档
项目地址:https://github.com/xyhcq/top250
我在本次项目中负责写爬虫中对数据分析的一部分,根据马壮分析过的html,我来进一步写代码获取数据,具体的功能及实现方法我已经写在了注释里:
首先,通过访问要爬的网站,并将网站保存在变量里,为下一步数据分析做准备
def getData(html):
# 分析代码信息,提取数据
soup = BeautifulSoup(html, "html.parser")
这时,如果我们print soup,是会在窗口上显示出网站的源代码的。
先把第一部电影信息的源代码放这,便于理解

首先,我们要爬取电影名字,我们经过分析(网页代码层次还是比较清晰的)
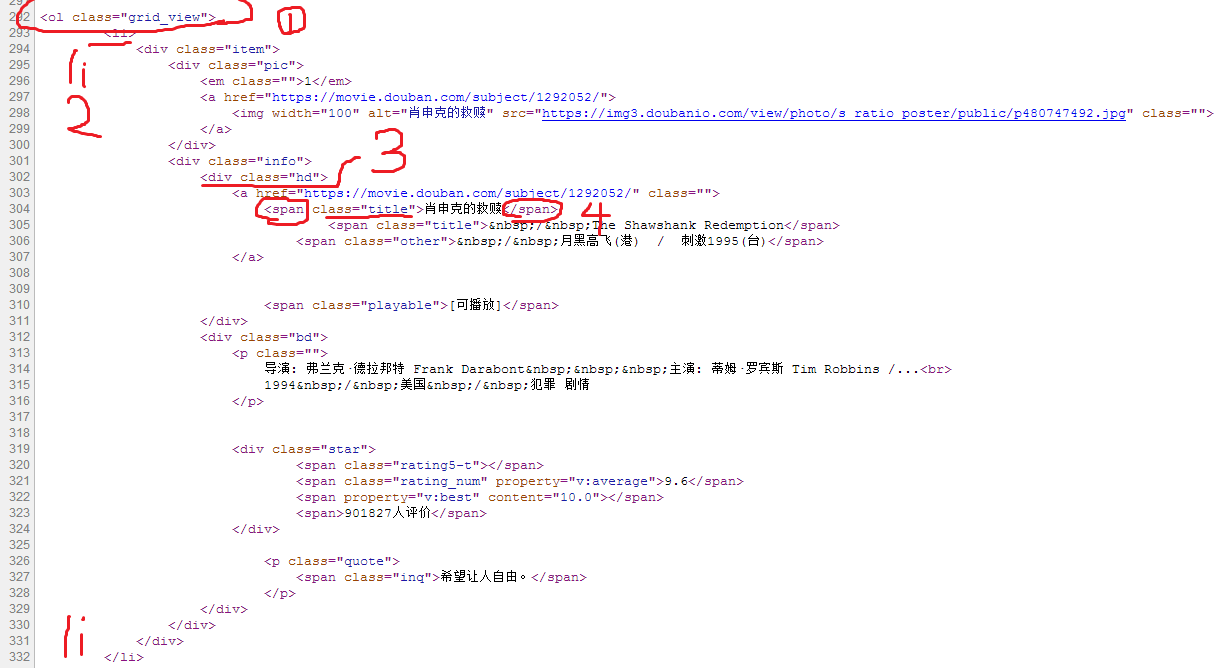
然后就可以写出爬取名字的部分了,
# 找到第一个class属性值为grid_view的ol标签
movieList=soup.find('ol',attrs={'class':'grid_view'}) # 找到所有的li标签
for movieLi in movieList.find_all('li'):
# 找到第一个class属性值为hd的div标签
movieHd=movieLi.find('div',attrs={'class':'hd'})
# 找到第一个class属性值为title的span标签 # 获取电影名字
movieName=movieHd.find('span',attrs={'class':'title'}).getText()
print movieName
经过运行,名字也确实能爬去并显示了,然后我们还是按照这种找标签的方法,以此类推,就能抓取其他的信息了:
# 获取电影链接
movieUrl=movieHd.find('a class="" href="')
print movieUrl # 获取电影导演/演员
movieBd = movieLi.find('div', attrs={'class': 'bd'})
movieSF=movieBd.find('p',attrs={'class':''}).getText()
print movieSF # 获取电影的评分
movieScore=movieLi.find('span',attrs={'class':'rating_num'}).getText()
print movieScore #获取电影的评论数
movieEval=movieLi.find('div',attrs={'class':'star'})
movieEvalNum=re.findall(r'\d+',str(movieEval))[-1]
print movieEvalNum
这里要说一下,如果找不到标签,有时候程序会卡住不动,排查发现问题出在简评上,所以;
# 获取电影短评
movieQuote = movieLi.find('span', attrs={'class': 'inq'})
# 有的电影没有短评,为防止报错,加次
if(movieQuote):
print movieQuote.getText()
else:
print ('没有短评!')

Forward团队-爬虫豆瓣top250项目-开发文档的更多相关文章
- 《Forward团队-爬虫豆瓣top250项目-开发文档》
码云地址:https://github.com/xyhcq/top250 模块功能:获取豆瓣top250网页的源代码,并分析. def getHTMLText(url,k): # 获取网页源代码 tr ...
- Forward团队-爬虫豆瓣top250项目-设计文档
组长地址:http://www.cnblogs.com/mazhuangmz/p/7603594.html 成员:马壮,李志宇,刘子轩,年光宇,邢云淇,张良 设计方案: 1.能分析HTML语言: 2. ...
- 《Forward团队-爬虫豆瓣top250项目-设计文档》
成员:马壮,李志宇,刘子轩,年光宇,邢云淇,张良 设计方案: 1.能分析HTML语言: 2.提取重要数据,并保存为文本文档: 3.用PY代码调取文本文档的数据: 4.编写提取部分数据的python代码 ...
- 爬虫豆瓣top250项目-开发文档
项目托管平台地址:https://github.com/gengwenhao/GetTop250.git 负责内容:1.使用python的request库先获取网页内容下来 2.再使用一个好用的lxm ...
- Forward团队-爬虫豆瓣top250项目-项目总结
托管平台地址:https://github.com/xyhcq/top250 小组名称:Forward团队 组长:马壮 成员:李志宇.刘子轩.年光宇.邢云淇.张良 我们这次团队项目内容是爬取豆瓣电影T ...
- Forward团队-爬虫豆瓣top250项目-最终程序
托管平台地址:https://github.com/xyhcq/top250 小组名称:Forward团队 小组成员合照: 程序运行方法: 在python中打开程序并运行:或者直接执行程序即可运行 程 ...
- Forward团队-爬虫豆瓣top250项目-项目进度
项目地址:https://github.com/xyhcq/top250 我们的项目是爬取豆瓣top250的电影的信息,在做这个项目前,我们都没有经验,完全是从零开始,过程中也遇到了很多困难,不过我们 ...
- Forward团队-爬虫豆瓣top250项目-模块测试
项目托管平台地址:https://github.com/xyhcq/top250 模块测试:爬虫对信息的处理部分 测试方法: 实际运行一下代码: 可以看见,信息都已经爬取出来了 其他补充说明: 原本系 ...
- Forward团队-爬虫豆瓣top250项目-模块开发过程
项目托管平台地址:https://github.com/xyhcq/top250 开发模块功能: 爬虫对信息的处理部分 开发时间:5天的下午空余时间(每天大约1小时,边学模块的使用边开发) 实现了:爬 ...
随机推荐
- 利用Access-Control-Allow-Origin响应头解决跨域请求原理
传统的跨域请求没有好的解决方案,无非就是jsonp和iframe,随着跨域请求的应用越来越多,W3C提供了跨域请求的标准方案(Cross-Origin Resource Sharing).IE8.Fi ...
- 使用MagickNet编辑图片
ImageMagick是一个免费的创建.编辑.合成图片的软件.它可以读取.转换.写入多种格式的图片.图片切割.颜色替换.各种效果的应用,图片的旋转.组合,文本,直线,多边形,椭圆,曲线 ...
- d3.js svg中 g 标签问题一览
svg 中的g标签, 算是比较特殊 1 没有x y属性 2 没有width height 属性 3 不能fill 4 .... g标签基本只管分组问题, 其他功能一概不提供 要解决这些问题, 直接在g ...
- HTTP 错误码
HTTP 400 – 请求无效 HTTP 401.1 – 未授权:登录失败 HTTP 401.2 – 未授权:服务器配置问题导致登录失败 HTTP 401.3 – ACL 禁止访问资源 HTTP 40 ...
- JVM性能优化读后笔记
java性能优化权威指南读后笔记 三重境界 1.花似雾中看:对于遇到的额问题还看不清,不知道真真假假,是是非非. 2.悠然见南山:虽然刚开始对这个领域还不清楚,但随着时间推移,你对它有许多自己的见解, ...
- ListBox设置背景色无效的问题。 listview类似
<Style TargetType="{x:Type ListBoxItem}"> <Setter Property="Template"&g ...
- 20175234 2018-2019-2 《Java程序设计》第八周学习总结
目录 20175234 2018-2019-2 <Java程序设计>第八周学习总结 教材学习内容总结 15.1泛型 15.2链表 15.3堆栈 15.4散列映射 15.5树集 15.6树映 ...
- 深入理解HashMap和CurrentHashMap
原文链接:https://segmentfault.com/a/1190000015726870 前言 Map 这样的 Key Value 在软件开发中是非常经典的结构,常用于在内存中存放数据. 本篇 ...
- localhost换成127.0.0.1和本机IP打不开本地项目了的问题
点击桌面右下角的小三角, iis express右键—>显示所有应用程序—>点击网站名称,配置文件路径,找到配置文件,以记事本打开, 按照configuration--system.app ...
- 探究osg中的程序设计模式【目录】
前序 探究osg中的程序设计模式---开篇 探究osg中的程序设计模式---创造性模式 探究osg中的程序设计模式---创造型模式---Factory(工厂)模式 探究osg中的程序设计模式---创造 ...