rabbitMQ学习2-Python与rabbitmq
- python客户端
# rabbitmq官方推荐的python客户端pika模块
pip3 install pika
应用场景1:单发送单接收
1.生产-消费者模型
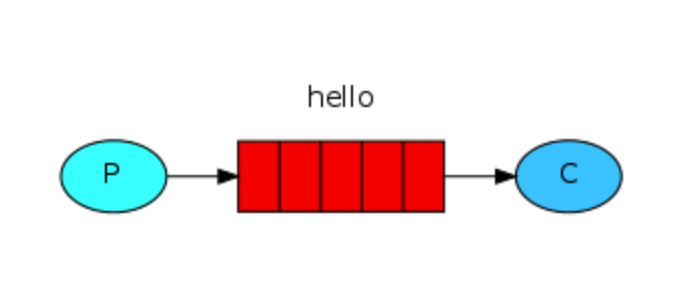
P 是生产者
C 是消费者
中间hello是消息队列
可以有多个P、多个C
P发送消息给hello队列,C消费者从队列中获取消息,默认轮询方式
生产者send.py
我们的第一个程序send.py将向队列发送一条消息。我们需要做的第一件事是建立与RabbitMQ服务器的连接。
#!/usr/bin/env python
import pika
# 创建凭证,使用rabbitmq用户密码登录
# 去邮局取邮件,必须得验证身份
credentials = pika.PlainCredentials("s14","123")
# 新建连接,这里localhost可以更换为服务器ip
# 找到这个邮局,等于连接上服务器
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.119.10',credentials=credentials))
# 创建频道
# 建造一个大邮箱,隶属于这家邮局的邮箱,就是个连接
channel = connection.channel()
# 声明一个队列,用于接收消息,队列名字叫“水许传”
channel.queue_declare(queue='水许传')
# 注意在rabbitmq中,消息想要发送给队列,必须经过交换(exchange),初学可以使用空字符串交换(exchange=''),它允许我们精确的指定发送给哪个队列(routing_key=''),参数body值发送的数据
channel.basic_publish(exchange='',
routing_key='水许传',
body='武松又去打老虎啦2')
print("已经发送了消息")
# 程序退出前,确保刷新网络缓冲以及消息发送给rabbitmq,需要关闭本次连接
connection.close()
接受者receive.py
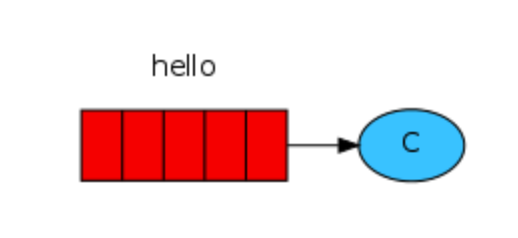
可以同时存在多个接受者,等待接收队列的消息,默认是轮训方式分配消息
可以运行多次,运行多个消费者
import pika
# 建立与rabbitmq的连接
credentials = pika.PlainCredentials("s14","123")
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.119.10',credentials=credentials))
channel = connection.channel()
channel.queue_declare(queue="水许传")
def callbak(ch,method,properties,body):
print("消费者接收到了任务:%r"%body.decode("utf8"))
# 有消息来临,立即执行callbak,没有消息则夯住,等待消息
# 老百姓开始去邮箱取邮件啦,队列名字是水许传
channel.basic_consume(callbak,queue="水许传",no_ack=True)
# 开始消费,接收消息
channel.start_consuming()
练习:
分别启动生产者、两个消费者,往队列发送数据,查看消费者的结果
应用场景2:单发送多接收
使用场景:一个发送端,多个接收端,如分布式的任务派发。为了保证消息发送的可靠性,不丢失消息,使消息持久化了。同时为了防止接收端在处理消息时down掉,只有在消息处理完成后才发送ack消息
rabbitmq消息确认之ack
默认情况下,生产者发送数据给队列,消费者取出消息后,数据将被清除。
特殊情况,如果消费者处理过程中,出现错误,数据处理没有完成,那么这段数据将从队列丢失
官网资料:http://www.rabbitmq.com/tutorials/tutorial-two-python.html
no-ack机制
不确认机制也就是说每次消费者接收到数据后,不管是否处理完毕,rabbitmq-server都会把这个消息标记完成,从队列中删除
ACK机制
ACK机制用于保证消费者如果拿了队列的消息,客户端处理时出错了,那么队列中仍然还存在这个消息,提供下一位消费者继续取
流程
1.生产者无须变动,发送消息
2.消费者如果no_ack=True啊,数据消费后如果出错就会丢失;反之no_ack=False,数据消费如果出错,数据也不会丢失
3.ack机制在消费者代码中演示
生产者.py
只负责发送数据即可,无须变动
#!/usr/bin/env python
import pika
# 创建凭证,使用rabbitmq用户密码登录 - 去邮局取邮件,必须得验证身份
credentials = pika.PlainCredentials("s14","123")
# 新建连接,这里localhost可以更换为服务器ip - 找到这个邮局,等于连接上服务器
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.119.10',credentials=credentials))
# 创建频道 - 建造一个大邮箱,隶属于这家邮局的邮箱,就是个连接
channel = connection.channel()
# 新建一个hello队列,用于接收消息 - 这个邮箱可以收发各个班级的邮件,通过
channel.queue_declare(queue='金品没')
# 注意在rabbitmq中,消息想要发送给队列,必须经过交换(exchange),初学可以使用空字符串交换(exchange=''),它允许我们精确的指定发送给哪个队列(routing_key=''),参数body值发送的数据
channel.basic_publish(exchange='',
routing_key='金品没',
body='潘金莲又出去。。。')
print("已经发送了消息")
# 程序退出前,确保刷新网络缓冲以及消息发送给rabbitmq,需要关闭本次连接
connection.close()
消费者.py
给予ack回复,拿到消息必须给rabbitmq服务端回复ack消息,否则消息不会被删除,防止客户端出错,数据丢失
import pika
credentials = pika.PlainCredentials("s14","123")
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.119.10',credentials=credentials))
channel = connection.channel()
# 声明一个队列(创建一个队列)
channel.queue_declare(queue='金品没')
def callback(ch, method, properties, body):
print("消费者接受到了任务: %r" % body.decode("utf-8"))
# int('asdfasdf')
# 我告诉rabbitmq服务端,我已经取走了消息
# 回复方式在这
ch.basic_ack(delivery_tag=method.delivery_tag)
# 关闭no_ack,代表给与服务端ack回复,确认给与回复
channel.basic_consume(callback,queue='金品没',no_ack=False)
channel.start_consuming()
消息持久化
演示
1.执行生产者,向队列写入数据,产生一个新队列queue
2.重启服务端,队列丢失
3.开启生产者数据持久化后,重启rabbitmq,队列不丢失
4.依旧可以读取数据
消息的可靠性是RabbitMQ的一大特色,那么RabbitMQ是如何保证消息可靠性的呢——消息持久化。 为了保证RabbitMQ在退出或者crash等异常情况下数据没有丢失,需要将queue,exchange和Message都持久化。
生产者.py
import pika
# 无密码
# connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61'))
# 有密码
credentials = pika.PlainCredentials("s14","123")
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.119.10',credentials=credentials))
channel = connection.channel()
# 声明一个队列(创建一个队列)
# 默认此队列不支持持久化,如果服务挂掉,数据丢失
# durable=True 开启持久化,必须新开启一个队列,原本的队列已经不支持持久化了
'''
实现rabbitmq持久化条件
delivery_mode=2
使用durable=True声明queue是持久化
'''
channel.queue_declare(queue='LOL',durable=True)
channel.basic_publish(exchange='',
routing_key='LOL', # 消息队列名称
body='德玛西亚万岁',
# 支持数据持久化
properties=pika.BasicProperties(
delivery_mode=2,#代表消息是持久的 2
)
)
connection.close()
消费者.py
import pika
credentials = pika.PlainCredentials("s14","123")
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.119.10',credentials=credentials))
channel = connection.channel()
# 确保队列持久化
channel.queue_declare(queue='LOL',durable=True)
'''
必须确保给与服务端消息回复,代表我已经消费了数据,否则数据一直持久化,不会消失
'''
def callback(ch, method, properties, body):
print("消费者接受到了任务: %r" % body.decode("utf-8"))
# 模拟代码报错
# int('asdfasdf') # 此处报错,没有给予回复,保证客户端挂掉,数据不丢失
# 告诉服务端,我已经取走了数据,否则数据一直存在
ch.basic_ack(delivery_tag=method.delivery_tag)
# 关闭no_ack,代表给与回复确认
channel.basic_consume(callback,queue='LOL',no_ack=False)
channel.start_consuming()
Exchange模型
rabbitmq发送消息首先是发给exchange,然后再通过exchange发送消息给队列(queue)

exchange有四种模式
fanout
exchange将消息发送给和该exchange连接的所有queue;也就是所谓的广播模式;此模式下忽略routing_key;
direct
路由模式,通过routing_key将消息发送给对应的queue; 如下面这句即可设置exchange为direct模式,只有routing_key为"black"时才将其发送到队列queue_name;
channel.queue_bind(exchange=exchange_name,queue=queue_name,routing_key='black')
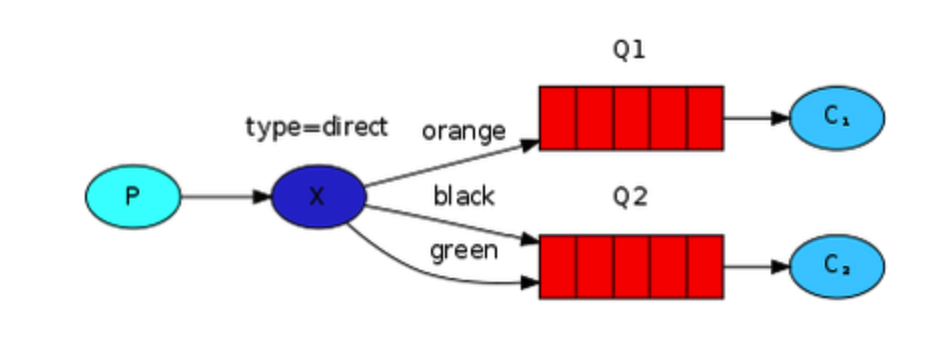
在上图中,Q1和Q2可以绑定同一个key,如绑定routing_key=‘KeySame’,那么收到routing_key为KeySame的消息时将会同时发送给Q1和Q2,退化为广播模式;
top
topic模式类似于direct模式,只是其中的routing_key变成了一个有“.”分隔的字符串,“.”将字符串分割成几个单词,每个单词代表一个条件;
headers
headers类型的Exchange不依赖于routing key与binding key的匹配规则来路由消息,而是根据发送的消息内容中的headers属性进行匹配。
官方教程:http://www.rabbitmq.com/tutorials/tutorial-three-python.html
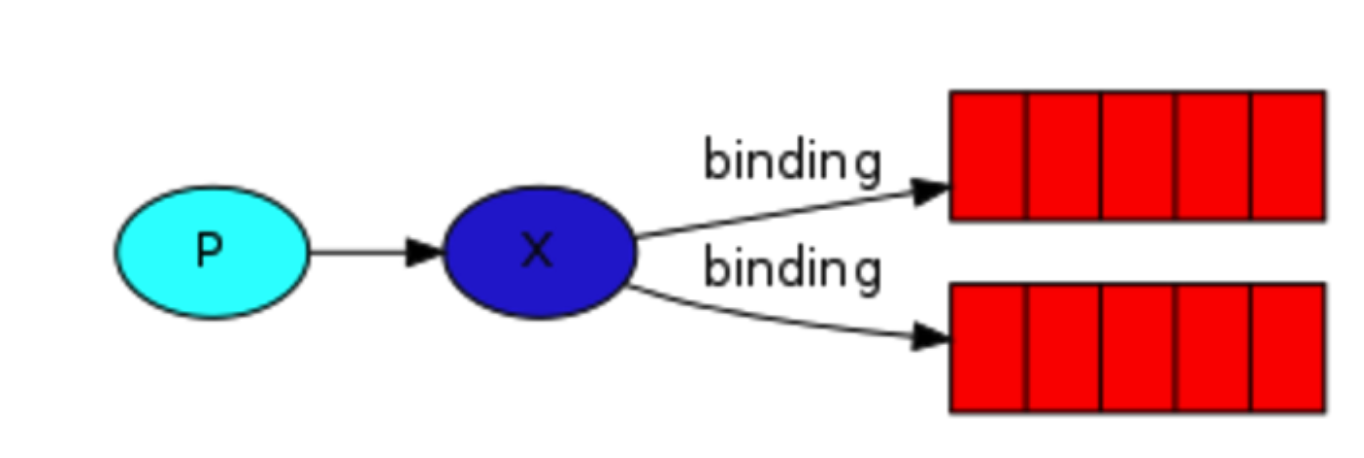
发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
# fanout所有的队列放一份/给某些队列发
# 传送消息的模式
# 与exchange有关的模式都发
exchange_type = fanout
消费者_订阅.py
可以运行多次,运行多个消费者,等待消息
import pika
credentials = pika.PlainCredentials("root","123")
connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61',credentials=credentials))
channel = connection.channel()
# exchange='m1',exchange(秘书)的名称
# exchange_type='fanout' , 秘书工作方式将消息发送给所有的队列
channel.exchange_declare(exchange='m1',exchange_type='fanout')
# 随机生成一个队列
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
# 让exchange和queque进行绑定.
channel.queue_bind(exchange='m1',queue=queue_name)
def callback(ch, method, properties, body):
print("消费者接受到了任务: %r" % body)
channel.basic_consume(callback,queue=queue_name,no_ack=True)
channel.start_consuming()
生产者_发布者.py
import pika
credentials = pika.PlainCredentials("root","123")
connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61',credentials=credentials))
channel = connection.channel()
# 指定exchange
channel.exchange_declare(exchange='m1',exchange_type='fanout')
channel.basic_publish(exchange='m1',
routing_key='',# 这里不再指定队列,由exchange分配,如果是fanout模式,每一个队列放一份
body='haohaio')
connection.close()
实例:
1.可以运行多个消费者,相当于有多个滴滴司机,等待着Exchange同一个电台发消息
2.运行发布者,发送消息给Exchange,查看是否给所有的队列(滴滴司机)发送了消息
关键字发布Exchange
之前事例,发送消息时明确指定某个队列并向其中发送消息,RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。
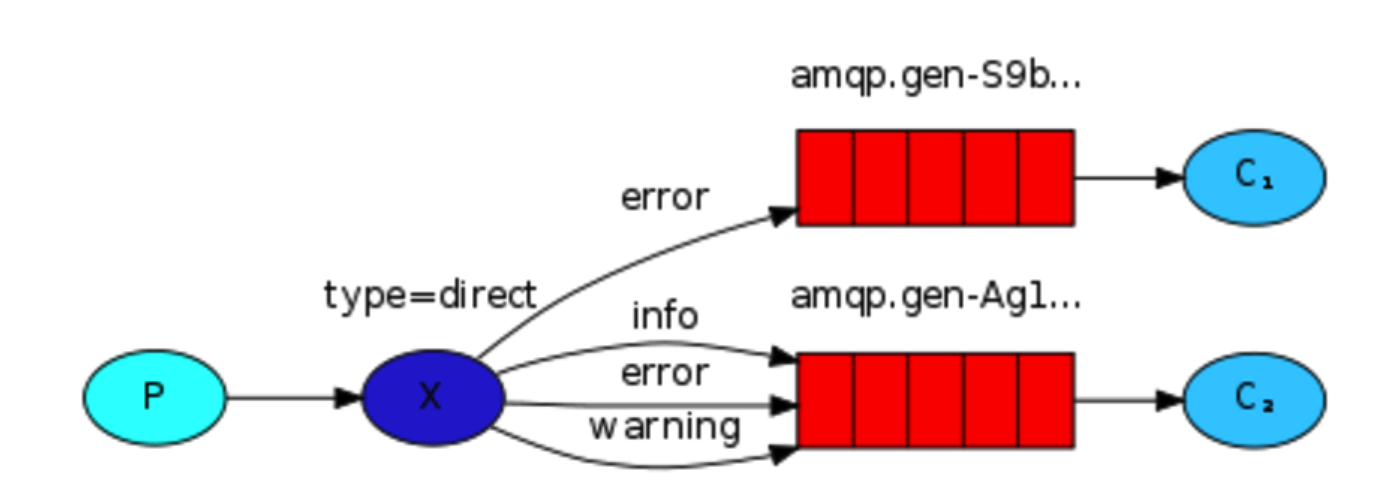
消费者1.py
路由关键字是sb,alex
# -*- coding: utf-8 -*-
# __author__ = "maple"
import pika
credentials = pika.PlainCredentials("root","123")
connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61',credentials=credentials))
channel = connection.channel()
# exchange='m1',exchange(秘书)的名称
# exchange_type='fanout' , 秘书工作方式将消息发送给所有的队列
channel.exchange_declare(exchange='m2',exchange_type='direct')
# 随机生成一个队列,队列退出时,删除这个队列
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
# 让exchange和queque进行绑定,只要
channel.queue_bind(exchange='m2',queue=queue_name,routing_key='alex')
channel.queue_bind(exchange='m2',queue=queue_name,routing_key='sb')
def callback(ch, method, properties, body):
print("消费者接受到了任务: %r" % body)
channel.basic_consume(callback,queue=queue_name,no_ack=True)
channel.start_consuming()
消费者2.py
路由关键字sb
# -*- coding: utf-8 -*-
# __author__ = "maple"
import pika
credentials = pika.PlainCredentials("root","123")
connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61',credentials=credentials))
channel = connection.channel()
# exchange='m1',exchange(秘书)的名称
# exchange_type='fanout' , 秘书工作方式将消息发送给所有的队列
channel.exchange_declare(exchange='m2',exchange_type='direct')
# 随机生成一个队列
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
# 让exchange和queque进行绑定.
channel.queue_bind(exchange='m2',queue=queue_name,routing_key='sb')
def callback(ch, method, properties, body):
print("消费者接受到了任务: %r" % body)
channel.basic_consume(callback,queue=queue_name,no_ack=True)
channel.start_consuming()
生产者.py
发送消息给匹配的路由,sb或者alex
# -*- coding: utf-8 -*-
# __author__ = "yugo"
import pika
credentials = pika.PlainCredentials("root","123")
connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61',credentials=credentials))
channel = connection.channel()
# 路由模式的交换机会发送给绑定的key和routing_key匹配的队列
channel.exchange_declare(exchange='m2',exchange_type='direct')
# 发送消息,给有关sb的路由关键字
channel.basic_publish(exchange='m2',
routing_key='sb',
body='aaaalexlaolelaodi')
connection.close()
rabbitMQ学习2-Python与rabbitmq的更多相关文章
- RabbitMQ学习笔记五:RabbitMQ之优先级消息队列
RabbitMQ优先级队列注意点: 1.只有当消费者不足,不能及时进行消费的情况下,优先级队列才会生效 2.RabbitMQ3.5以后才支持优先级队列 代码在博客:RabbitMQ学习笔记三:Java ...
- RabbitMQ学习系列一安装RabbitMQ服务
RabbitMQ学习系列一:windows下安装RabbitMQ服务 http://www.80iter.com/blog/1437026462550244 Rabbit MQ 是建立在强大的Erla ...
- RabbitMQ学习3----运行和管理RabbitMQ
1.服务为管理 Erlang天生就是为了让应用程序无需知道对方是否存在同一台机器上即可互相通信. Erlang节点:Erlang虚拟机的每个实例.多个Erlang应用程序可以运行在同一个节点之上.节点 ...
- 【RabbitMQ学习之二】RabbitMQ四种交换机模式应用
环境 win7 rabbitmq-server-3.7.17 Erlang 22.1 一.概念1.队列队列用于临时存储消息和转发消息.队列类型有两种,即时队列和延时队列. 即时队列:队列中的消息会被立 ...
- RabbitMq学习笔记——MingW编译RabbitMQ C
1.安装cmak,下载地址:https://cmake.org/download/,当前最新版本3.15.1,下载cmake-3.15.1-win64-x64.msi 注意:安装时勾选将bin目录添加 ...
- RabbitMQ学习笔记四:RabbitMQ命令(附疑难问题解决)
本来今天是想做RabbitMQ之优先级队列的,但是,在RabbitMQ Server创建queue时,增加优先级的最大值,头脑发热写了9999999,导致电脑内存直接飙到100%,只能重启电脑,并卸载 ...
- RabbitMQ学习笔记六:RabbitMQ之消息确认
使用消息队列,必须要考虑的问题就是生产者消息发送失败和消费者消息处理失败,这两种情况怎么处理. 生产者发送消息,成功,则确认消息发送成功;失败,则返回消息发送失败信息,再做处理. 消费者处理消息,成功 ...
- 消息队列之rabbitmq学习使用
消息队列之rabbitmq学习使用 1.RabbitMQ简介 1.1.什么是RabbitMQ? RabbitMQ是一个开源的消息代理和队列服务器,用来通过普通协议在完全不同的应用之间共享数据,Rabb ...
- 官网英文版学习——RabbitMQ学习笔记(二)RabbitMQ安装
一.安装RabbitMQ的依赖Erlang 要进行RabbitMQ学习,首先需要进行RabbitMQ服务的安装,安装我们可以根据官网指导进行http://www.rabbitmq.com/downlo ...
- openresty 学习笔记番外篇:python访问RabbitMQ消息队列
openresty 学习笔记番外篇:python访问RabbitMQ消息队列 python使用pika扩展库操作RabbitMQ的流程梳理. 客户端连接到消息队列服务器,打开一个channel. 客户 ...
随机推荐
- 【UVA】11400 照明系统设计 排序+dp
题目中有一个重要的信息是:每一种灯泡只能换成比它电压更大的灯泡,因此电压的大小限制了状态的转移.因此,在这里按照电压从小到大把每种灯泡排序,使得在考虑后面的灯泡时,前面的灯泡自然可以换成后面的灯泡.状 ...
- mybatis 直接执行sql 【我】
Connection conn = getConnection();// Connection conn = this.ss.getConnection(); 返回Connect ...
- Day29--Python--缓冲区, 粘包
tcp: 属于长连接,与一个客户端进行连接了以后,其他的客户端要等待.要想连接另外一个客户端,需要优雅地断开当前客户端的连接 允许地址重用:server.setsockopt(socket.SOL_S ...
- hdu 4279"Number"(数论)
传送门 参考资料: [1]:https://www.2cto.com/kf/201308/233613.html 题意,题解在上述参考资料中已经介绍的非常详细了,接下来的内容只是记录一下我的理解: 我 ...
- c#UDP协议
UDP协议是不可靠的协议,传输速率快 服务器端: using System; using System.Collections.Generic; using System.Linq; using Sy ...
- Linux(centos7)如何安装Zend Optimizer Zend Guard Loader
下载地址:http://www.zend.com/en/products/loader/downloads#Linux 1.解压 wget http://downloads.zend.com/guar ...
- Pyhton之subprocess模块和configparser模块
一.subprocess模式 # import os # while True: # cmd=input('>>').strip() # if not cmd:continue # if ...
- 关于indexOf,charAt,subString的区别
@Test public void indexOf() { // 注意:在Unicode表中A-Z的十进制对应:65-90 // a-z的进制对应:97-122 // 0-9的十进制对应:48-57 ...
- bzoj2957 奥妙重重的线段树
https://www.lydsy.com/JudgeOnline/problem.php?id=2957 线段树的query和update竟然还可以结合起来用! 题意:小A的楼房外有一大片施工工地, ...
- 图论分支-倍增Tarjan求LCA
LCA,最近公共祖先,这是树上最常用的算法之一,因为它可以求距离,也可以求路径等等 LCA有两种写法,一种是倍增思想,另一种是Tarjan求法,我们可以通过一道题来看一看, 题目描述 欢乐岛上有个非常 ...