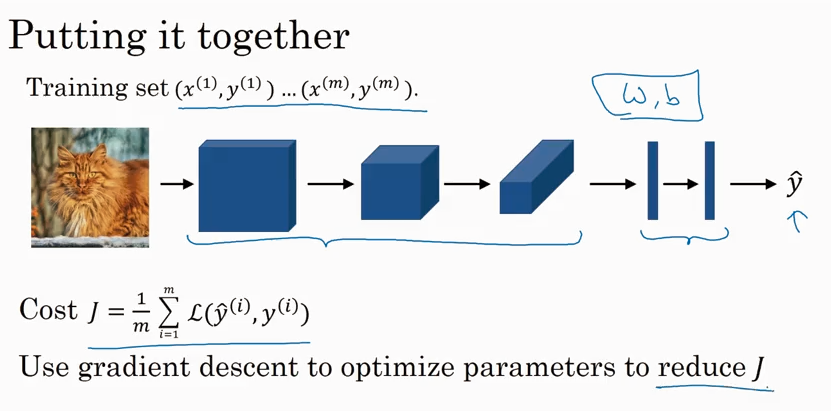
Coursera, Deep Learning 4, Convolutional Neural Networks - week1
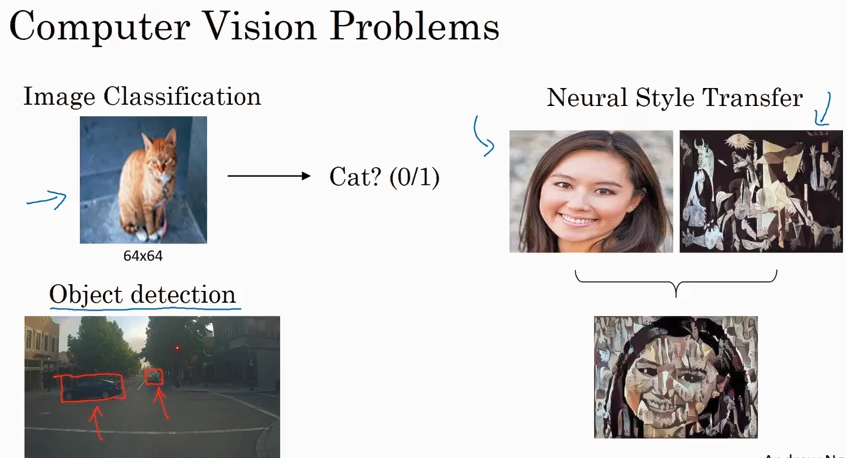
CNN 主要解决 computer vision 问题,同时解决input X 维度太大的问题.

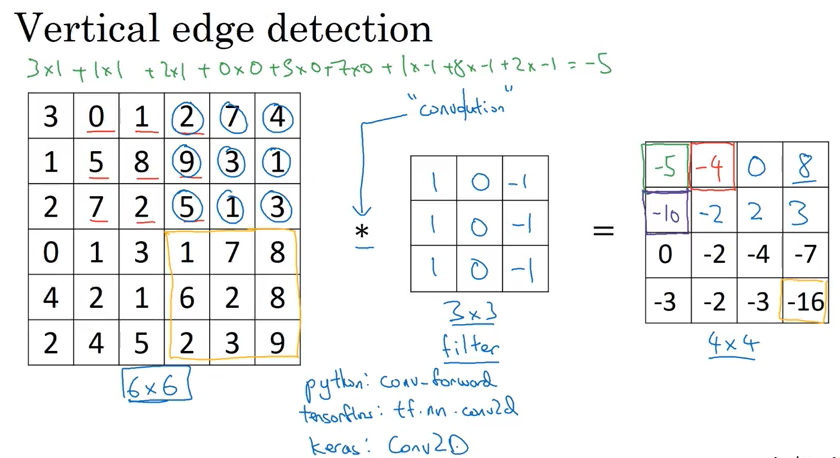
Edge detection
下面演示了convolution 的概念
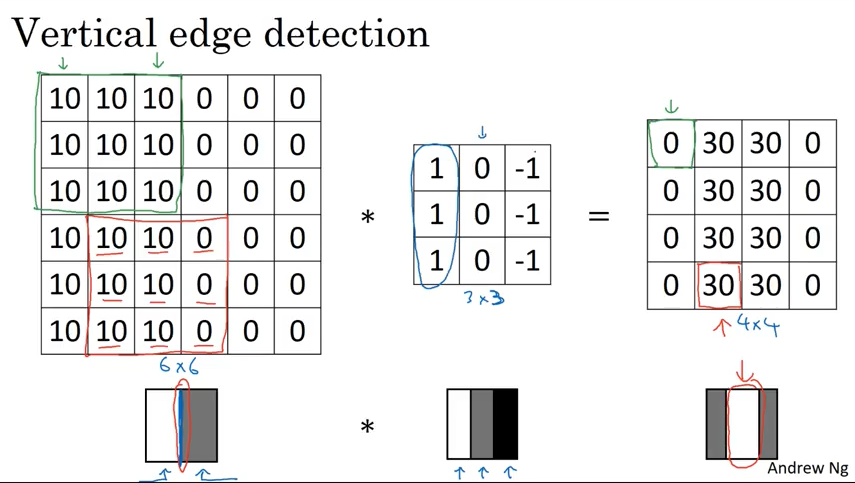
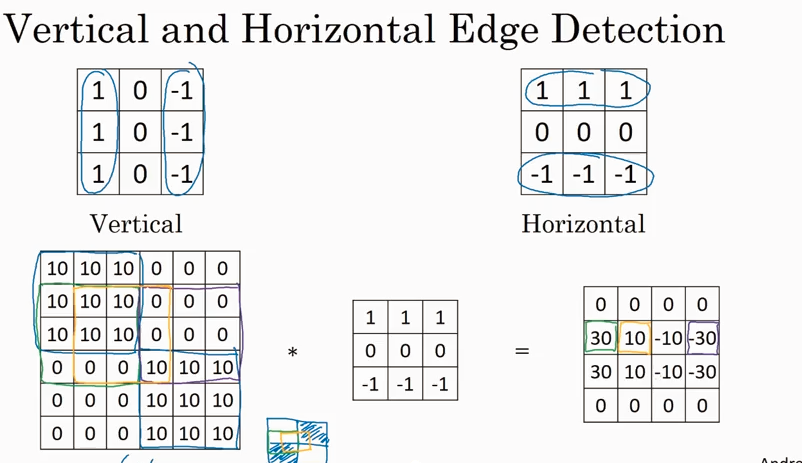
下图的 vertical edge 看起来有点厚,但是如果图片远比6x6像素大的话,就会看到效果非常不错.
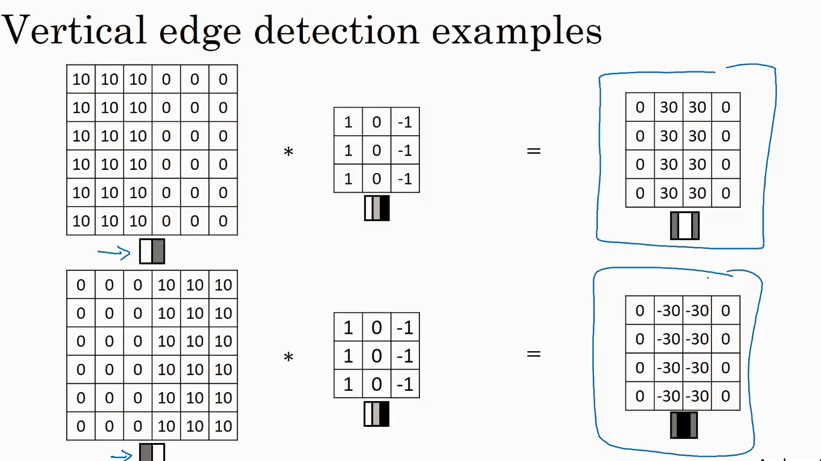
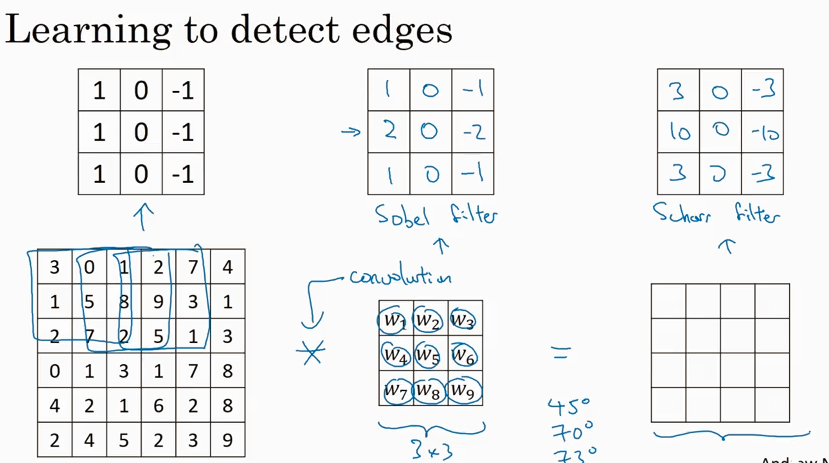
除了前面讲过的第一种filter, 还有两种 (Sobel filter, Scharr filter)
接下来会讲到 CNN 的两个重要的buiding block - padding, strided convolution. 也就是对前面所讲的basic convolution 的两种优化。
Padding
basic convolution 有两个问题, 一个是shrik output, 使得图像越来越小, 另一个是 throw away info from edge, 就是边缘的信息使用率不高. 为了解决这两个问题,在input image外围加了一个边框,就是padding.
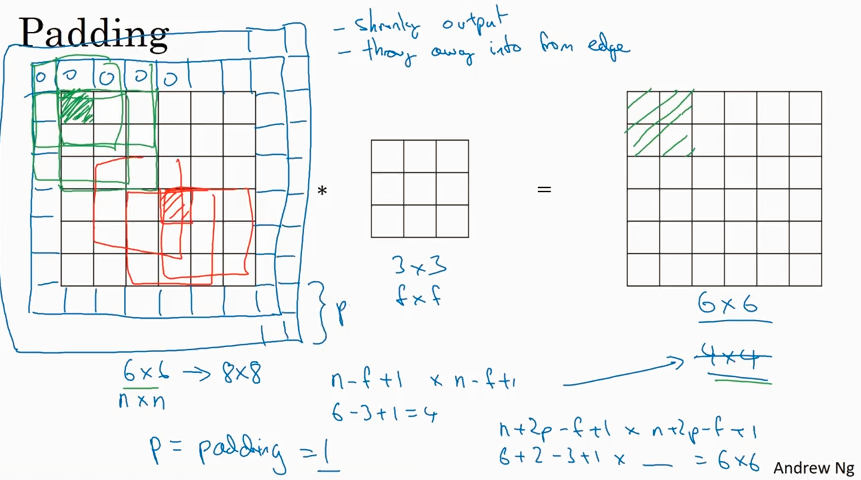
那么怎么来选取padding 值的大小呢?有两种方法 'Valid' (no padding), 和 'Same' (output size is same as input size). 要达到Same 的效果,只需要满足 p = (f-1)/2。 f 值通常选取奇数,Andrew 给出两个原因,一个是可以达到Same的效果,一个是可以在filter 里有center pixel 来描述位置.

Strided convolution
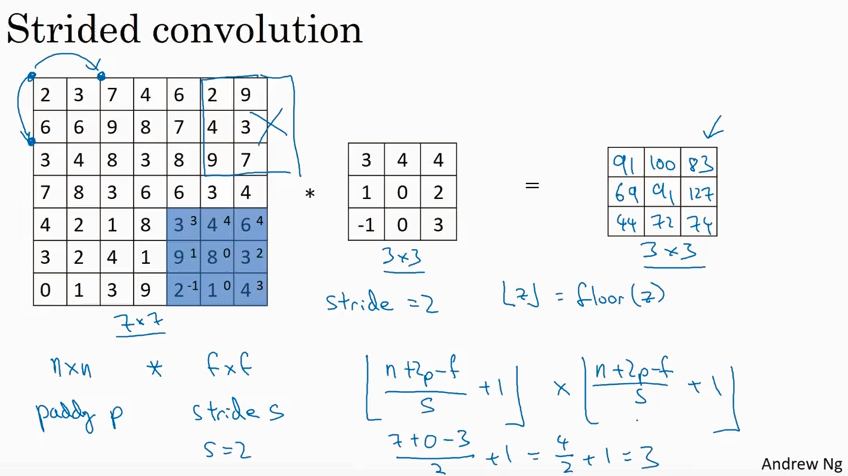
如果要使得output size 更小,可以用strided convolution 方法,就是计算卷积的时候使得步长s更大。

实际上在deep learing 里经常说的convolution 对应的是数学概念里的cross-correlation, 两者的区别是,数学里的convolution 比cross-correlation 多一步对filter翻转的操作. 也就是说deep learning里的convoluton 叫做cross-correlation更确切一些。但是翻转那一步对deep learning 没有影响,所以deep learning 里就用convolution 来指代cross-correlation. Andrew 提到这个是为了让读者在读数学论文时候不至于困惑。
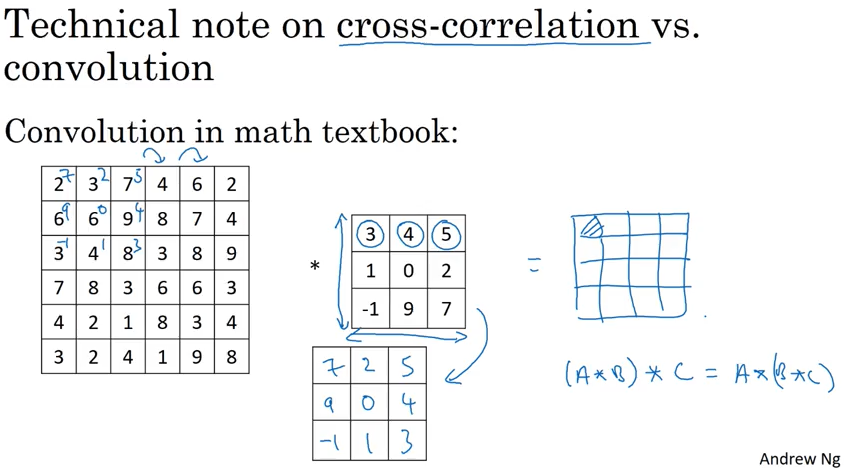
Convolution over volumes
前面讲的都是对2D 的image有卷积,现在开始讲对3D 的image 怎么求卷积。
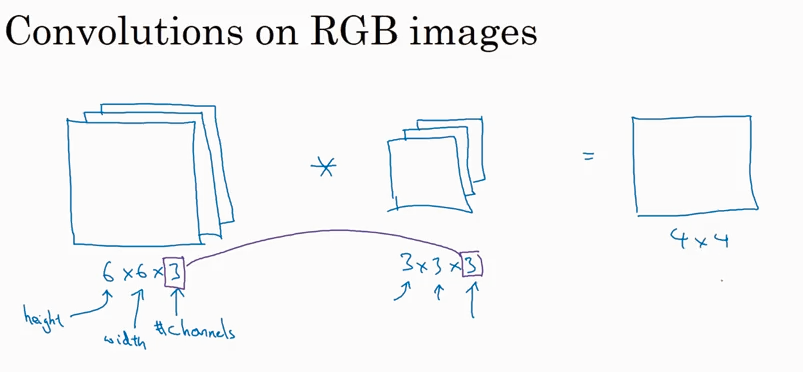
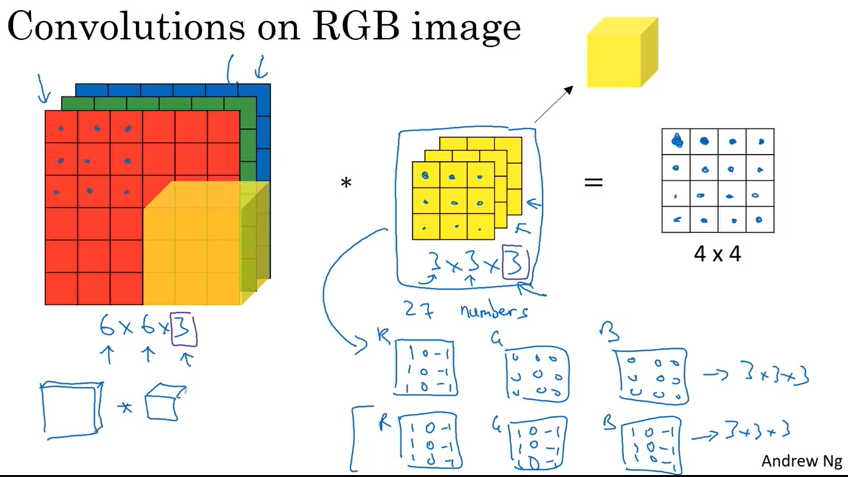
前面一直在讲用一个filter 来识别 vertical 或者 horizotal edge, 那如果要同时识别vertical 和 horizotal edge呢?答案是可以同时使用两个filter, 具体如下图。
这里提一下,第3个维度可以叫channel, 也有人叫depth.
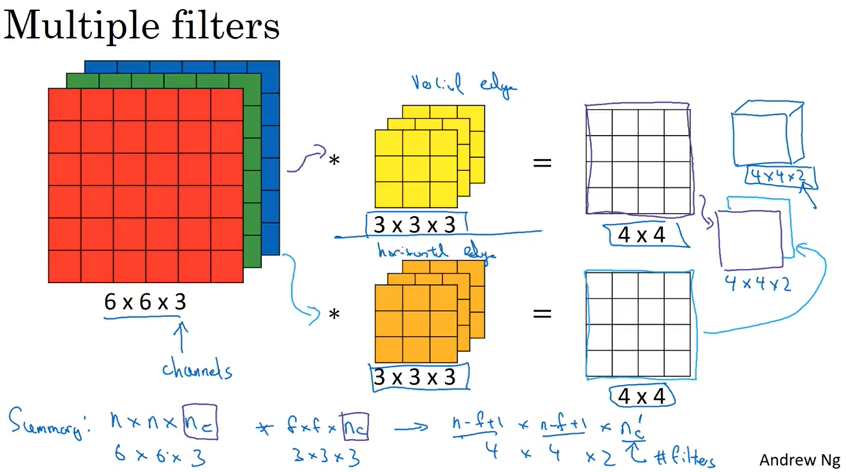
One Layer of convolutional network
一层convolution network 可以和传统的neural network 类比如下图。
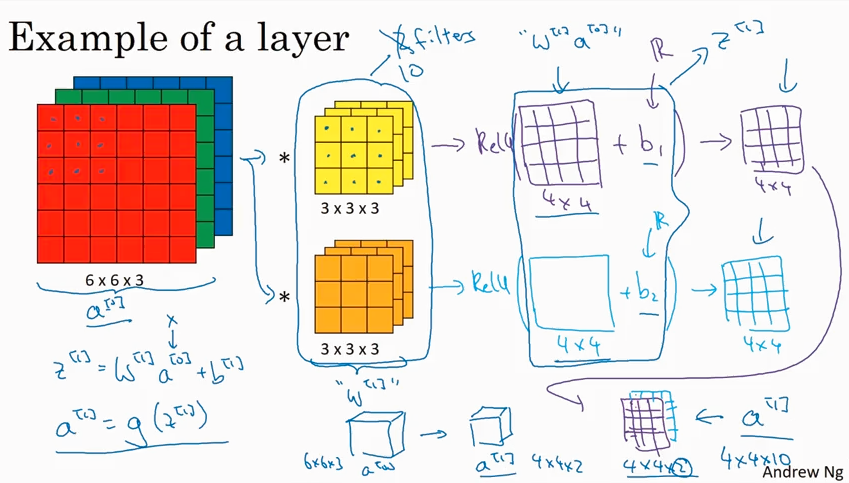
下图解释了convolutional network 中,无论input layer 的 X 维度多大(比如5000维),我们都可以用这10个filter 来充当W[1] 的角色,同时保持280个parameters不变。

下面是CNN中的一些notation. 需要说明的是本课程用了n[H][l] * n[W][l] * n[C][l] 这样的顺序,在CNN里也有用 n[C][l] * n[H][l] * n[W][l] 这样的顺序,效果一样.

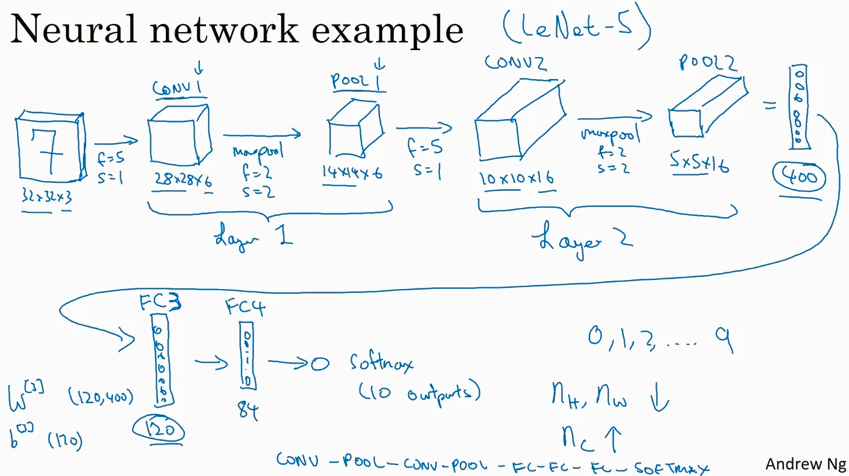
Simple convolutional network example
下图是一个多层ConvNet 网络,通常image size 会逐渐减小,而channel size会逐渐增大.

通常一个convolutional network里不仅有convoluional layer, 还会经常看到 pooling layer, 和fully connected layer.

Pooling layers
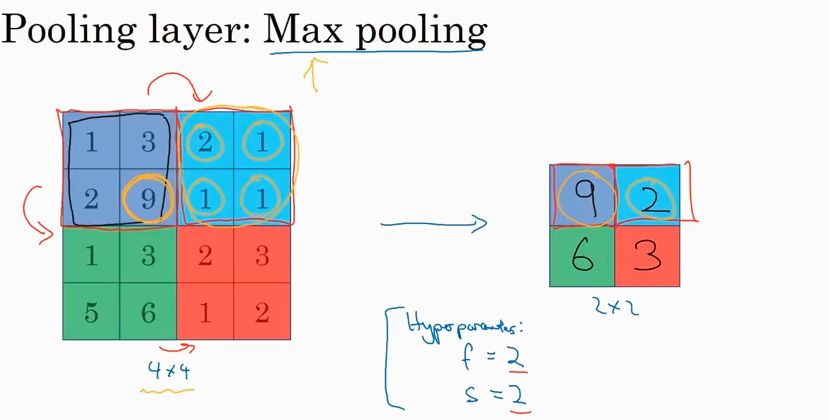
先看Max pooling, 就是根据filter 的大小在input image里取最大值。一旦filter 的维度f 和步长 s 确定了,就可以从input里得出output, 无需计算filter 的参数。
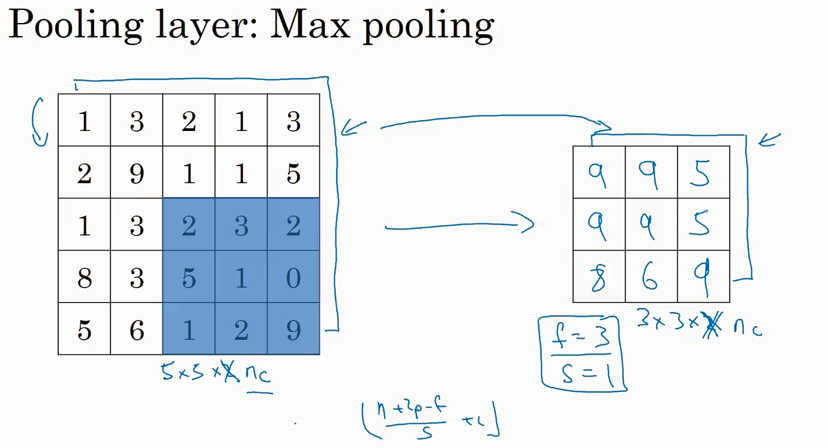
刚才是看的2D的情况,如果input lay 是3D的就是说有channel, 那么output 也会有相同的channel.
Max pooling 是求最大值,如果是求平均值,就叫average pooling. Average pooling 不常用.
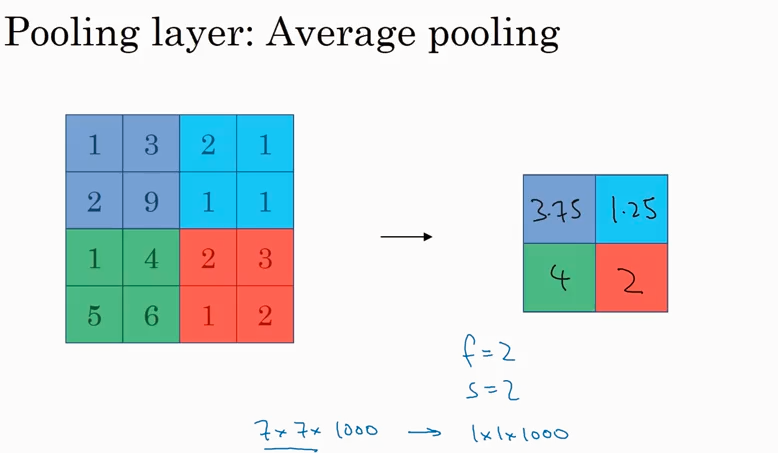
通常padding=0. f, s 最常见的值如下图.

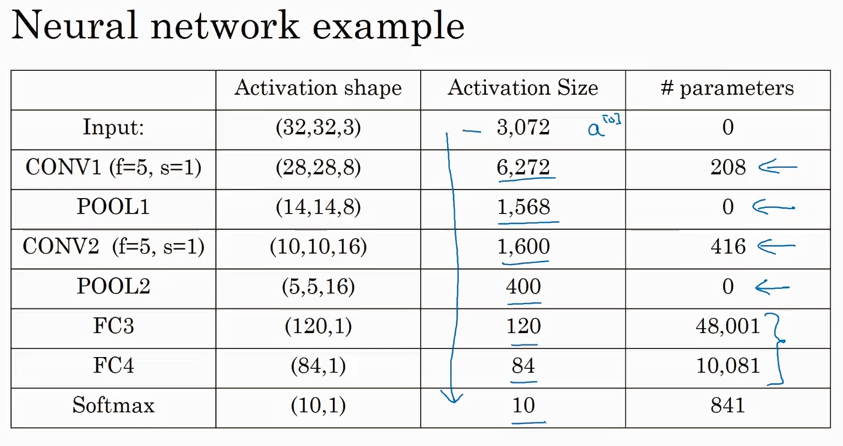
Typical CNN example
按照习惯conv layer 和 pooling layer 合起来叫一个network layer, 这是只计算了有weight 的conv layer 而pooling layer 没有weight 就没有算.
FC means Fully Connected layer. 其实就是传统的network layer.
Why convolutions?
相比于传统的fully connected network layer, convolutional layer 的parameters少的多.
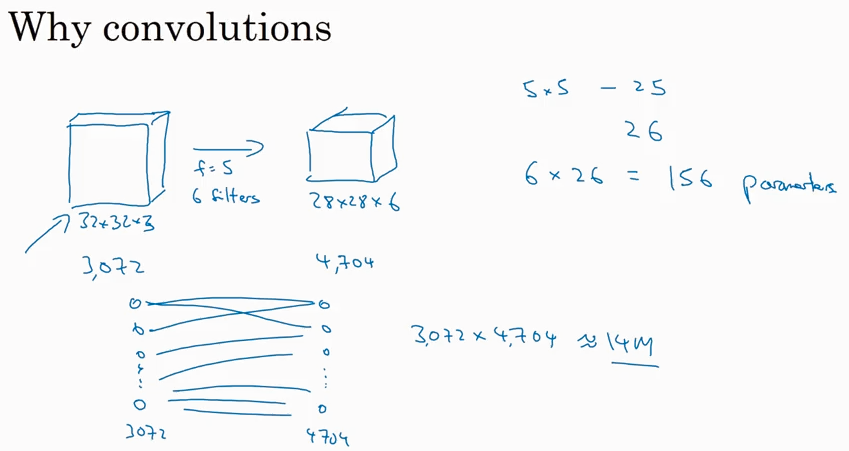
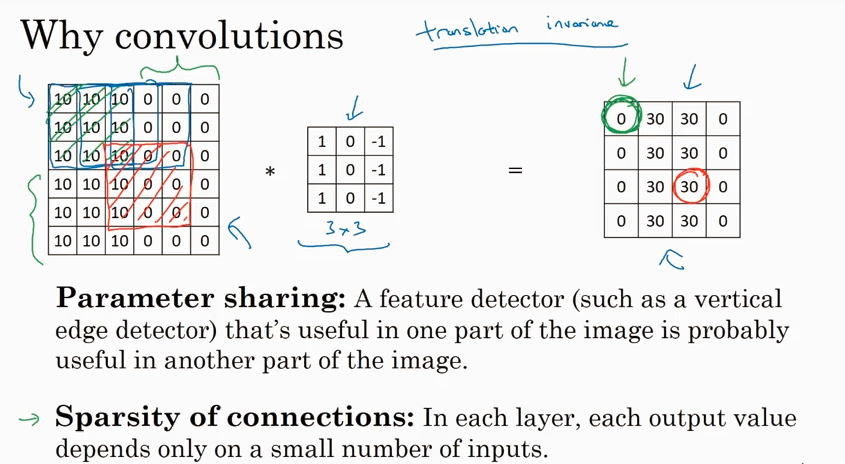
为什么parameters 少了那么多,还能达到很好的performance呢?
有以下两个原因:
feature sharing: 共享了3x3的filter,这个filter 的参数对每次convolutional 计算都是一样的。
sparsity of connections: output 中的一部分只取决于 input 中的一部分。
Coursera, Deep Learning 4, Convolutional Neural Networks - week1的更多相关文章
- Coursera, Deep Learning 4, Convolutional Neural Networks - week4,
Face recognition One Shot Learning 只看一次图片,就能以后识别, 传统deep learning 很难做到这个. 而且如果要加一个人到数据库里面,就要重新train ...
- Coursera, Deep Learning 4, Convolutional Neural Networks - week2
Case Study (Note: 红色表示不重要) LeNet-5 起初用来识别手写数字灰度图片 AlexNet 输入的是227x227x3 的图片,输出1000 种类的结果 VGG VGG比Ale ...
- Coursera, Deep Learning 4, Convolutional Neural Networks, week3, Object detection
学习目标 Understand the challenges of Object Localization, Object Detection and Landmark Finding Underst ...
- Deep Learning Tutorial - Convolutional Neural Networks(LENET)
CNN很多概述和要点在CS231n.Neural Networks and Deep Learning中有详细阐述,这里补充Deep Learning Tutorial中的内容.本节前提是前两节的内容 ...
- 论文笔记之:Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
Learning Multi-Domain Convolutional Neural Networks for Visual Tracking CVPR 2016 本文提出了一种新的CNN 框架来处理 ...
- [CVPR2015] Is object localization for free? – Weakly-supervised learning with convolutional neural networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 } p. ...
- 【论文阅读】Learning Dual Convolutional Neural Networks for Low-Level Vision
论文阅读([CVPR2018]Jinshan Pan - Learning Dual Convolutional Neural Networks for Low-Level Vision) 本文针对低 ...
- 【DeepLearning学习笔记】Coursera课程《Neural Networks and Deep Learning》——Week2 Neural Networks Basics课堂笔记
Coursera课程<Neural Networks and Deep Learning> deeplearning.ai Week2 Neural Networks Basics 2.1 ...
- 论文阅读:MDNet: Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
前言 CVPR2016 来自Korea的POSTECH这个团队 大部分算法(例如HCF, DeepLMCF)只是用在大量数据上训练好的(pretrain)的一些网络如VGG作为特征提取器,这些做法 ...
随机推荐
- 如何在 Linux/Unix/Windows 中发现隐藏的进程和端口
unhide 是一个小巧的网络取证工具,能够发现那些借助 rootkit.LKM 及其它技术隐藏的进程和 TCP/UDP 端口.这个工具在 Linux.UNIX 类.MS-Windows 等操作系统下 ...
- 【模板】ac自动机
本来是真的特别不想写这个的 但是有段时间洛谷天天智推这个可能是我太菜了 然后觉得这个也不难 乘着今早没事写下 来这保存下 方便下次食用 #include <bits/stdc++.h> u ...
- A1034. Head of a Gang
One way that the police finds the head of a gang is to check people's phone calls. If there is a pho ...
- 【洛谷P1483】序列变换
题目大意:给定一个长度为 N 的序列,有 M 个操作,支持将下标为 x 的倍数的数都加上 y,查询下标为 i 的元素的值. 题解:由于查询操作很少,相对的,修改操作很多.若直接模拟修改操作,即:枚举倍 ...
- [luogu2286][宠物收养所]
题目链接 思路 比较裸的一道平衡树的题.用一个变量S来表示当前树的情况,当S为负数时树内为宠物,当S为正数时树内为人.然后每次分情况讨论一下.如果树为空或者是与来的东西(人或宠物)与树内存的相同.那么 ...
- R语言绘图(FZ)
P-Value Central Lmit Theorem(CLT) mean(null>diff) hist(null) qqnorm(null) qqline(null) pops<-r ...
- 第三十三节,目标检测之选择性搜索-Selective Search
在基于深度学习的目标检测算法的综述 那一节中我们提到基于区域提名的目标检测中广泛使用的选择性搜索算法.并且该算法后来被应用到了R-CNN,SPP-Net,Fast R-CNN中.因此我认为还是有研究的 ...
- 第三十一节,目标检测算法之 Faster R-CNN算法详解
Ren, Shaoqing, et al. “Faster R-CNN: Towards real-time object detection with region proposal network ...
- 牛客网 2018年东北农业大学春季校赛 I题 wyh的物品
链接:https://www.nowcoder.com/acm/contest/93/I 来源:牛客网 时间限制:C/C++ 5秒,其他语言10秒空间限制:C/C++ 262144K,其他语言5242 ...
- (string stoi 栈)leetcode682. Baseball Game
You're now a baseball game point recorder. Given a list of strings, each string can be one of the 4 ...