python 字符串 切片
####################概念######################
'''
int 整数
str 字符串 一般不存放大量的数据
bool 布尔值,用来判断。 True,False
list 列表。存放大量数据,[]表示,里面可以放各种数据类型
tuple 元祖,只读列表 ()表示
dict 字典。 {key:value}
set 集合。 去重
'''
'''
大小写转换:*——记住
* upper() 全大写
title() 首字母大写(只要是不属于英文字母的都是分隔符)
切来切去:
center(10,'*') 强行用*在原字符串左右两端拼接,拼接成十个长度
* strip() 去除前后两边的空格 lstrip() rstrip()
* replace(old,new) 替换
* split() 切割(切完的结果是一个列表里面装着字符串)
注意:贴边则是有空字符串
* startswith() endswith 以什么开头
都可以进行索引的操作
* count() 计算出现的次数
* find() 查找xxx在字符串中出现的位置索引,只找第一个,找不到返回-1
* index() 查找xxx在字符串中出现的位置索引,只找第一个,找不到报错
条件判断:
.isalnum 字母数字
.isdigit 数字
.isalpha 字母
.isnumeric 中文数字大小写都可以
字符串长度:
* len() 字符串中字符的个数 (python中的内置函数) 迭代: ——for循环表示把迭代的对象中的每一个元素赋值给前面的变量
for 变量 in 可迭代对象:
循环体,也存在break和continue
else:
当循环结束的时候才会执行 '''
#############切片思路#########################
索引: 下标从0开始的数字. 指示的是字符串中的每一个字符
切片: 从源字符串中截取一部分内容作为新字符串
s[start: end: step]
start: 开始
end: 结束. 取不到
step: 步长, 默认是1. 每step取一个. 通过符号来控制方向. +从左往右, -从右往左
s = "中间的,你们为什么不说话.难受"
# print(s[3:7]) # ,你们为
# print(s[-3:-7]) # 切不到东西, 默认是从左往右切 # print (s[::2]) 中间 的, 你们 为什 么不 说话 .难 受
每个支撑点取第一个
结果 中 的 你 为 么 说 . 手 #print(s[1:5:3]) # (间的,你们) 间 你 取每个支撑位
#print(s[7:3:-1]) #
中间的,你们为什 #先是取7个 然后去掉3个 再把 (你们为什)反过来
print(s[-1:-8: -2])
什么不说话.难受
么 说 数 . 受
#################作业######################
name = "aleX leNb" # 1)移除 name 变量对应的值两边的空格,并输出处理结果
# a=name.strip()
# print(a) #2)移除name变量左边的"al"并输出处理结果
# print(name.lstrip('al')) #3)移除name变量右的"Nb",并输出处理结果
# print(name.rstrip('Nb')) # 4)移除name变量开头的a"与最后的"b",并输出处理结果 # print(name.lstrip('a').rstrip()) # 5)判断 name 变量是否以 "al" 开头,并输出结果
# print(name.startswith('al')) # 6)判断name变量是否以"Nb"结尾,并输出结果
# print(name.endswith('Nb')) # 7)将 name 变量对应的值中的 所有的"l" 替换为 "p",并输出结果
# print(name.replace('l','p')) # 8)将name变量对应的值中的第1个"l"替换成"p",并输出结果
#print(name.replace('l','p',1))
# 9)将 name 变量对应的值根据 所有的"l" 分割,并输出结果。
# print(name.split('l')) # 10)将name变量对应的值根据第一个"l"分割,并输出结果。
# print(name.split('l')) # 11)将 name 变量对应的值变大写,并输出结果
# print(name.upper()) # 12)将 name 变量对应的值变小写,并输出结果
# print(name.lower()) # 13)将name变量对应的值首字母"a"大写,并输出结果
# print(name.capitalize()) # 14)判断name变量对应的值字统计"l"出现次数,并输出结果
# print(name.count('l')) # 15)如果判断name变量对应的值前四位"l"出现几次,并输出结果
# print(name.count('l',0,5)) # 16)从name变量对应的值中找到"N"对应的索引(如果找不到则报错),并输出结果
# print(name.index('N')) # 17)从name变量对应的值中找到"N"对应的索引(如果找不到则返回-1)输出结果
# print(name.find('N')) # 18)从name变量对应的值中找到"X le"对应的索引,并输出结果 # print(name.index("X le")) # 19)请输出 name 变量对应的值的第 2 个字符? # print(name[1]) # 20)请输出 name 变量对应的值的前 3 个字符? # print(name[0:3]) # 21)请输出 name 变量对应的值的后 2 个字符? # print(name[-2:]) # 22)请输出 name 变量对应的值中 "e" 所在索引位置? # print(name.find("e"))
# 2.有字符串
s = "123a4b5c"
# 1)通过对s切⽚形成新的字符串s1,s1 = "123"
# print(s[0:3]) # 2)通过对s切⽚形成新的字符串s2,s2 = "a4b"
# print(s[3:6]) # 3)通过对s切⽚形成新的字符串s3,s3 = "1345"
# print(s[::2]) # 4)通过对s切⽚形成字符串s4,s4 = "2ab"
# print(s[1:6:2])
# 5)通过对s切⽚形成字符串s5,s5 = "c"
# print(s[7:100])
# 6)通过对s切⽚形成字符串s6,s6 = "ba2"
# s = "123a4b5c"
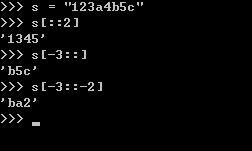
# print(s[-3:-2]) # print(s[-3::-2]) #3.使⽤while和for循环分别打印字符串s="asdfer"中每个元素。
# s="asdfer"
#
# for i in s:
# print(i) #4.使⽤for循环对s="asdfer"进⾏循环,但是每次打印的内容都是"asdfer"。
# s="asdfer"
# for i in s:
# print(s) # 5.使⽤for循环对s="abcdefg"进⾏循环,每次打印的内容是每个字符加上sb,
# 例如:asb, bsb,csb,...gsb。
# s="abcdefg"
# for i in s:
# print(i+'sb') # 6.使⽤for循环对s="321"进⾏循环,打印的内容依次是:"倒计时3秒","倒计时
# 2秒","倒计时1秒","出发!"。 # s="321"
# for i in s:
# print(f'倒计时{i}秒') # 7,实现一个整数加法计算器(两个数相加):
# 如:content = input("请输入内容:") ⽤户输入:5+9或5+ 9或5 + 9,然后进⾏分割再进⾏计算
content=input("请输入内容>>>")
a=content.split('+')
c=int(a[0])+int(a[1])
print("结果为%s" %(c))
content= input('请输入内容>>>')
num = content.split('+')
s = (int(num[0].strip()) + int(num[1].strip()))
print(s)
# 8,升级题:实现一个整数加法计算器(多个数相加):
# 如:content = input("请输入内容:") ⽤户输入:5+9+6 +12+ 13,然后进⾏
# 分割再进⾏计算。
content=input(">>>>")
a=content.split('+')
sum=0
for i in a:
sum=sum+int(i)
print(sum)
content = input('>>>').strip()
n = content.split('+')
sum = 0
for i in n:
sum += int(i)
print('终极运算之最后结果:%s'%sum)
# 9,计算⽤户输⼊的内容中有几个整数(以个位数为单位)。
# 如:content = input("请输入内容:") # 如fhdal234slfh98769fjdla
count=0
content = input("请输入内容:")
for i in content:
if i.isdigit()
count+=1
print(count)
10、写代码,完成下列需求:
⽤户可持续输⼊(⽤while循环),⽤户使⽤的情况:
输⼊A,则显示⾛⼤路回家,然后在让⽤户进⼀步选择:
是选择公交,还是步⾏? ①,选择公交,显示10分钟到家,并退出整个程序。
②,选择步⾏,显示20分钟到家,并退出整个程序。
输⼊B,则显示⾛⼩路回家,并退出整个程序。
输⼊C,则显示绕道回家,然后在让⽤户进⼀步选择:是选择游戏厅玩会,还是网吧?
选择游戏厅,则显示 ‘⼀个半小时到家,爸爸在家,拿棍等你。’并让其重新输⼊A,B,C选项。
选择网吧,则显示‘两个小时到家,妈妈已做好了战⽃准备。’并让其重新输⼊A,B,C选项。
while True:
content = input('请输入A B C:')
if content=='A':
home=int(input('1,是选择公交,2,还是步行?'))
if home ==int(1):
print('①,选择公交,显示10分钟到家,并退出整个程序')
break
elif home ==int(2):
print('①,选择步行,显示20分钟到家,并退出整个程序')
break
elif content =='B':
print('则显示小路回家,并退出整个程序')
break
elif content =='C':
wang = input('是选择游戏厅玩会,还是网吧?')
if wang =='游戏厅':
print('一个半小时到家,爸爸在家,拿棍等你。')
else:
print('两个小时到家,妈妈已做好了战准备')
else:
print("输入错误. ")
11、写代码:计算 1 - 2 + 3 ... + 99 中除了88以外所有数的总和?
count = 1
sum = 0
while count <100:
if count % 2 == 0:
if count == 88:
count =count+1 #如果不自加1,count一直是88,跳不出去循环
continue
sum -= count
print(sum)
else:
sum += count
count += 1
print(sum)
12. (升级题)判断一句话是否是回文.回⽂: 正着念和反着念是⼀样的. 例如, 上海
自来水来自海上(升级题)
content=input('请输入')
if content[::-1] == content:
print('是回文')
else:
print('元宝是元宝')
13. 输入一个字符串,要求判断在这个字符串中大写字母,小写字母,数字,
其它字符共出现了多少次,并输出出来
coutent=input('请输入>>>'.strip())
upper=0
lower=0
number=0
other=0
for i in coutent:
if i.isupper():
upper=upper+1
elif i.islower():
lower=lower+1
elif i.isdigit():
number+=1
else:
other+=1
print(f"大写{upper},小写{lower},数字{number},其他{other}")
14、制作趣味模板程序需求:等待用户输入名字、地点、爱好,根据用户的名字和爱好进行任意现实
如:敬爱可亲的xxx,最喜欢在xxx地方干xxx
name=input("请输入姓名:")
place=input("请输入地点:")
love=input("请输入爱好:")
print(f'敬爱的{name},最喜欢在{place}爱好{love}')
15.给出百家姓. 然后用户输入一个的名字. 判断这个人是否是百家姓中的姓氏(升级题)
first_names = """
赵钱孙李,周吴郑王。
冯陈褚卫,蒋沈韩杨。
朱秦尤许,何吕施张。
孔曹严华,⾦魏陶姜。
戚谢邹喻,柏⽔窦章。
云苏潘葛,奚范彭郎。
鲁⻙昌⻢,苗凤花⽅。
俞任袁柳,酆鲍史唐。
费廉岑薛,雷贺倪汤。
滕殷罗毕,郝邬安常。
乐于时傅,⽪卞⻬康。
伍余元⼘,顾孟平⻩。
和穆萧尹,姚邵湛汪。
祁⽑禹狄,⽶⻉明臧。
计伏成戴,谈宋茅庞。
熊纪舒屈,项祝董梁。
杜阮蓝闵,席季麻强。
贾路娄危,江童颜郭。
梅盛林刁,钟徐邱骆。
⾼夏蔡⽥,樊胡凌霍。
虞万⽀柯,昝管卢莫。
经房裘缪,⼲解应宗。
丁宣贲邓,郁单杭洪。
包诸左⽯,崔吉钮龚。
程嵇邢滑,裴陆荣翁。
荀⽺於惠,甄曲家封。
芮羿储靳,汲邴糜松。
井段富巫,乌焦巴⼸。
牧隗⼭⾕,⻋侯宓蓬。
全郗班仰,秋仲伊宫。
宁仇栾暴,⽢钭厉戎。
祖武符刘,景詹束⻰。
叶幸司韶,郜黎蓟薄。
印宿⽩怀,蒲邰从鄂。
索咸籍赖,卓蔺屠蒙。
池乔阴鬱,胥能苍双。
闻莘党翟,谭贡劳逄。
姬申扶堵,冉宰郦雍。
卻璩桑桂,濮⽜寿通。
边扈燕冀,郏浦尚农。
温别庄晏,柴瞿阎充。
慕连茹习,宦艾⻥容。
向古易慎,⼽廖庾终。
暨居衡步,都耿满弘。
匡国⽂寇,⼴禄阙东。
欧⽎沃利,蔚越夔隆。
师巩厍聂,晁勾敖融。
冷訾⾟阚,那简饶空。
曾毋沙乜,养鞠须丰。
巢关蒯相,查后荆红。
游竺权逯,盖益桓公。
万俟司⻢,上官欧阳。
夏侯诸葛,闻⼈东⽅。
赫连皇甫,尉迟公⽺。
澹台公冶,宗政濮阳。
淳于单于,太叔申屠。
公孙仲孙,轩辕令狐。
钟离宇⽂,⻓孙慕容。
鲜于闾丘,司徒司空。
丌官司寇,仉督⼦⻋。
颛孙端⽊,巫⻢公⻄。
漆雕乐正,壤驷公良。
拓跋夹⾕,宰⽗⾕梁。
晋楚闫法,汝鄢涂钦。
段⼲百⾥,东郭南⻔。
呼延归海,⽺⾆微⽣。
岳帅缑亢,况郈有琴。
梁丘左丘,东⻔⻄⻔。
商牟佘佴,伯赏南宫。
墨哈谯笪,年爱阳佟。
第五⾔福,百家姓终。
""" content=input("请输入你的姓名:")
if content[0] in first_names:
print('你的名字在百家姓中')
else:
print('你的名字不在百家姓中')
python 字符串 切片的更多相关文章
- Python字符串切片操作知识详解
Python字符串切片操作知识详解 这篇文章主要介绍了Python中字符串切片操作 的相关资料,需要的朋友可以参考下 一:取字符串中第几个字符 print "Hello"[0] 表 ...
- DAY3(PYTHON)字符串切片
字符串调整: capitalize() #首字母大写 upper() #全大写 lower() #全小写 swapcase() #大小写翻转 字符串切片: 顾头不顾尾!!! ...
- Python字符串切片
1.字符串切片:从字符串中取出相应的元素,重新组成一个新的字符串 语法: 字符串[ 开始元素下标 : 结束元素下标 : 步长 ] # 字符串的每个元素都有正负两种下标 步长: ...
- Python 字符串切片
#-*- coding:utf-8 -*- #字符串切片 names = "abcdefgh" ''' 切片语法 names[起始位置:终止位置:步长] 起始位置:即字符串的下标, ...
- python 字符串切片知识巩固
切片操作(slice)可以从一个字符串中获取子字符串(字符串的一部分).我们使用一对方括号.起始偏移量start.终止偏移量end 以及可选的步长step 来定义一个分片. 格式: [start:en ...
- Python 字符串切片(slice)
切片操作(slice)可以从一个字符串中获取子字符串(字符串的一部分).我们使用一对方括号.起始偏移量start.终止偏移量end 以及可选的步长step 来定义一个分片. 格式: [start:en ...
- python学习第四天 --字符编码 与格式化及其字符串切片
字符编码 与格式化 第三天已经知道了字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题. 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采 ...
- python中的字符串切片
python中的字符串切片,似乎有点乱,例如: >>>pystr='Python' >>>pystr[2:5] 就会输出 'tho' 这该怎样理解呢?中括号[2:5 ...
- Python 对字符串切片
对字符串切片字符串 'xxx'和 Unicode字符串 u'xxx'也可以看成是一种list,每个元素就是一个字符.因此,字符串也可以用切片操作,只是操作结果仍是字符串:>>> 'A ...
随机推荐
- [踩过的坑]Elasticsearch.Net 官网示例的坑
经过昨天的ElasticSearch 安装,服务以及可以启动了,接下来就可以开发了,找到了官网提供的API以及示例,Es 官方提供的.net 客户端有两个版本一个低级版本: [Elasticsearc ...
- 启发式合并&线段树合并/分裂&treap合并&splay合并
启发式合并 有\(n\)个集合,每次让你合并两个集合,或询问一个集合中是否存在某个元素. 我们可以用平衡树/set维护集合. 对于合并两个\(A,B\),如果\(|A|<|B|\),那么 ...
- 网络文件系统(NFS)简介
网络文件系统(Network File System, NFS)是一种分布式文件系统协议,最初由Sun Microsystems公司开发,并于1984年发布.其功能旨在允许客户端主机可以像访问本地存储 ...
- Nowcoder | [题解-N210]牛客OI月赛2-提高组
比赛连接戳这里^_^ 我才不会说这是我出的题(逃) 周赛题解\((2018.10.14)\) \(T1\) \(25\sim50\)分做法\(:\)直接爆搜 作为一个良心仁慈又可爱的出题人当然\(T1 ...
- [luogu2617][bzoj1901][Zju2112]Dynamic Rankings【树套树+树状数组+主席树】
题目网址 [传送门] 题目大意 请你设计一个数据结构,支持单点修改,区间查询排名k. 感想(以下省略脏话inf个字) 真的强力吹爆洛谷数据,一般的树套树还给我T了一般的点,加强的待修主席树还给我卡了几 ...
- 「九省联考 2018」IIIDX 解题报告
「九省联考 2018」IIIDX 这什么鬼题,送的55分要拿稳,实测有60? 考虑把数值从大到小摆好,每个位置\(i\)维护一个\(f_i\),表示\(i\)左边比它大的(包括自己)还有几个数可以选 ...
- One Person Game ZOJ - 3329(期望dp, 数学)
There is a very simple and interesting one-person game. You have 3 dice, namely Die1, Die2 and Die3. ...
- 仓鼠找sugar(LCA)
小仓鼠的和他的基(mei)友(zi)sugar住在地下洞穴中,每个节点的编号为1~n.地下洞穴是一个树形结构.这一天小仓鼠打算从从他的卧室(a)到餐厅(b),而他的基友同时要从他的卧室(c)到图书馆( ...
- hdu 2609 How many(最小表示法)
Problem Description Give you n ( n < 10000) necklaces ,the length of necklace will not large than ...
- Linux:文件系统层次结构标准(Filesystem Hierarchy Standard)
Linux FHS_2.3标准文档:http://refspecs.linuxfoundation.org/FHS_3.0/fhs-3.0.pdf