Python框架学习之Flask中的视图及路由
在前面一讲中我们学习如何创建一个简单的Flask项目,并做了一些简单的分析。接下来在这一节中就主要来讲讲Flask中最核心的内容之一:Werkzeug工具箱。Werkzeug是一个遵循WSGI协议的Python函数库。WSGI协议在前面的文章中也有提到(点我查看)。那Werkzeug有什么作用呢?它其实实现了很多底层的东西,如Request、Response和集成URL请求路由等。
一、Werkzeug的组成:
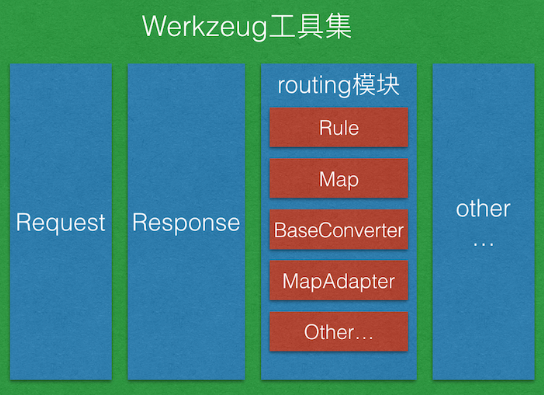
二、routing模块
routing模块的主要目的是负责实现URL解析。不同的URL能够对应不同的视图,从而得到不同的响应信息。
1.Rule类:class Rule(RuleFactory):
用来构造不同的url模式的对象。
if not string.startswith('/'):
raise ValueError('urls must start with a leading slash')
这个判断语句是Rule中的,表示url必须是以"/"开头的字符串!

2.Map类:
用来存储所有的URL规则和一些配置参数。

3.MapAdapter类
负责让url与视图建立关联。
4.BaseConverter
这是一个转换器基类,Flask中6个自带的转换器都是继承于它!当然了,如果我们想要自定义一个路由匹配规则的话,也需要通过继承它来实现。如自定义一个正则路由匹配。
流程:
(1). 导入BaseConverter类。在Flask中,所有 的路由的匹配规则都是使用转换器对象进行记录的。
(2). 自定义转换器。
(3). 把自定义转换器添加到默认转换器的字典当中去。
(4). 使用自定义转换器实现自定义匹配规则。
from flask import Flask
from werkzeug.routing import BaseConverter
app = Flask(__name__)
class RegexConverter(BaseConverter):
"""自定义一个正则转换器"""
def __init__(self, map, *args):
super(RegexConverter, self).__init__(map)
# 将url中第一个参数当做匹配规则进行保存
self.regex = args[0]
print(map)
print(args[0])
# 把自定义转换器添加到默认转换器的字典中,并将转换器命名为re
app.url_map.converters['re'] = RegexConverter
# print(app.url_map.converters)
# 定义一个正则的路由规则,匹配3个数字
@app.route('/regex/<re("[0-9]{3}"):u_id>')
def index(u_id):
return "user_id为%s" % u_id
if __name__ == "__main__":
print(app.url_map)
app.run(debug=True)
三、Request对象
Request是Flask中表示当前请求的request对象,一般称之为请求上下文变量(可以理解成全局变量,在任意一个视图中都可以访问到)。常用的属性有:
args:url中的查询字符串。本质上是键值对,跟在"?"后面,多个键值对之间使用"&"连接;
form:请求url中的表单数据。也是由键值对组成,一般使用post方法提交数据
cookies:请求中的cookie信息。由服务器生成的键值对,把值发送给客户端并保存,稍后重点讲解!
files:上传的文件
from flask import Flask, request
app = Flask(__name__)
# 127.0.0.1:5000/?a=4&b=5
@app.route('/')
def index():
a = request.args.get('a')
b = request.args.get('b')
print('a:%s, b:%s' % (a, b))
return '请求成功!!'
if __name__ == "__main__":
print(app.url_map)
app.run(debug=True)
四、状态保持
在分析Request对象的时候提到过Cookie,什么是Cookie?Cookie有什么用?以及如何通过Cookie及Session来实现状态保持呢?
(1). 为什么要有状态保持的功能?
因为HTTP是一种无状态协议,也就是说当用户每一次请求时,都是一个新的请求,服务器根本不知道这个用户做过什么。比如当你在某个网站上想要买个东西,但是你每做一步都需要进行登录直到下单成功,这样对用户来说就显得特别麻烦,用户体验就特别差。如果我们的网站可以记录该用户的一些信息,那么用户就不需要每次都进行登录了,用户体验就大大提高了。
(2).Cookie是什么?
Cookie是由键值对组成的字符串,为了辨别用户身份,进行会话跟踪而保存在本地的数据。
Cookie是服务器生成的,发送给客户端浏览器,浏览器将以键值对的形式保存着,当下一次请求同一网站的时候会携带着Cookie一起。
有了Cookie我们就可以在很多地方看到一些似曾相识的广告了!比如当你在某宝上买了什么玩意,然后系统会推荐很多很多的相似的东西好让你剁手!
Cookie是基于域名安全的,不同域名的Cookie是不能相互访问的。这就牵扯到CSRF了,这个留在模板中来说。
from flask import Flask, request, make_response
app = Flask(__name__)
@app.route('/set_cookie')
def set_cookie():
# make_response()用来生成一些响应头信息
# 参数作为响应体
resp_header = make_response('用来生成响应头信息')
# 设置cookie,key为unmae, value为python, 有效期为1分钟
resp_header.set_cookie('uname', 'python', max_age=60)
return resp_header
@app.route('/get_cookie')
def get_cookie():
name = request.cookies.get('uname',"没有获取到有效的cookie")
return name
if __name__ == "__main__":
print(app.url_map)
app.run(debug=True)
(3). session是什么?
在做Cookie的实验中,我们发现Cookie保存的信息是明文形式,这样是很不安全的。而且又是保存在本地的,不是保存在服务器上面。这样的话,我们一些很重要的私人信息是会很容易被盗取。那有没有一种保存在服务器的秘钥,而且又是被加密的,返回给浏览器的只是一个key呢?
那么session就是这样的,保存在服务器,而且是加密的,不容易被盗取。但是Session是依赖于Cookie的。
session在Flask中是一种请求上下文对象,用于处理HTTP请求中的一些数据。
如果要设置Session,那么必须要设置SECRET_KEY变量。SECRET_KEY 的作用主要是提供一个值做各种 HASH,可在 Flask 和多个第三方扩展中使用。
在上面提到过,一些配置信息最好不要和业务逻辑混合在一起。要么单独存放在一个文件中,如settings.py,要么存放在一个ini文件中,或者添加到系统环境变量里。这么做的好处是如果你不把这些文件暴露出去,那么其他人就很难看到!在Flask中都有提供这些操作接口(app.config.from_xxx()),很方便
from flask import Flask, session
# 自定义的配置文件,为了安全起见,里面可以做一些数据库连接、秘钥设置...
from settings import MyConfig
app = Flask(__name__)
# 从.py的配置文件中加载一些配置变量,如DEBUG, SECRET_KEY,...
app.config.from_object(MyConfig)
@app.route('/session')
def set_session():
session['name'] = 'python'
return '设置session成功'
if __name__ == "__main__":
print(app.url_map)
app.run()
五、请求钩子
在Flask中有一个请求钩子,就是4个装饰器。但是在其他框架中,如Django、Scrapy中被称为中间件,所以也可以把请求钩子称作是中间件!这其实是一种编程思想(AOP切面编程)的体现。对AOP编程感兴趣的读者可以自行搜索了解一下!这里主要讲讲Flask中的请求钩子。
Flask中的请求钩子分别是:before_first_request、before_request、after_request、teardown_request。这些请求钩子有什么作用呢?可以把他们想象成C++/Java中的构造函数和析构函数,即做一些初始化和销毁的工作!其中最主要的功能还是在请求结束时,指定数据的交互格式,如指定Json格式。
1.@app.before_first_request:在处理第一个请求前被执行,而且只会执行一次。
2.@app.before_request:每次请求前被执行,可以做一些预检工作,如果不满足某些条件就return,然后视图就不会被执行了
3.@app.after_request:在每个视图执行完毕之后并且没有错误时调用,可以设置一些响应头信息,等等操作。必须返回response
4.@app.teardown_request:每次请求后被调用,接受一个参数:错误信息。
from flask import Flask, request, abort
from settings import MyConfig
app = Flask(__name__)
# 配置信息
app.config.from_object(MyConfig)
# 第一次请求前被调用,相当于__init__方法
@app.before_first_request
def before_first_request():
print('我只会被调用一次哦!')
# 在每次请求前被调用,可以做一些请求检验
# 如果请求的检验不成功,可以直接在此方法中进行响应,直接return后,不在继续往下执行
@app.before_request
def before_request():
print(request.args.get('wd', '没有找到查询参数'))
if "?" not in request.url:
# 这个return 语句返回个客户端浏览器,并作为响应体
return 'url中没有查询参数'
print('你的请求URL:%s' % request.url)
# abort(500)
# 执行完视图函数之后被调用,并且会把视图函数生成的响应传入,可以对response做一些设置
#
@app.after_request
def after_request(response):
# print(response.headers)
# if response.headers.startswith('text'):
# response.headers['Content-Type'] = 'application/json'
print('对响应信息做了一些更改!')
# 必须返回一个response
return response
# 在每次请求之后都会被调用,会接受一个参数,参数是服务器出现的错误信息
@app.teardown_request
def teardown_request(e):
print('teardown_request')
print(e)
@app.route('/args/<int:p1>')
def index1(p1):
return "接收到参数%s" % p1
@app.route('/args/<int:p2>')
def index2(p2):
return "接收到参数%s" % p2
if __name__ == '__main__':
app.run()
六、上下文对象
1. 什么是上下文?
上下文可以当成一个容器,里面保存着从开始到目前为止发生的一些事情,就相当于一个日志一样。在Flask中,有两种的上下文:请求上下文(request context)和应用上下文(application context)。
2. 请求上下文:
请求对象指每次发生HTTP请求时,在Flask对象内部创建的对象。
请求上下文包括:request对象和session对象。
request:主要保存着当前本次请求的相关数据,上文提到的那些常用属性。针对的是HTTP请求。
session:用来保存请求会话中的信息,主要是用户信息。
3.应用上下文:
应用对象是当调用app=Flask(__name__)时创建的对象,主要是帮助request获取当前的应用。
应用上下文包括:current_app和g对象
current_app:用于存储程序中的变量,主要是做日志使用,生命周期比request上下文长
g:是一个临时变量,保存的是当期那请求的全局变量,不同的请求会有不同的全部变量。
4.区别:
请求上下文主要是保存客户端与服务器交互的数据;应用上下文是在程序运行过程中,保存着一些配置信息。
一般应用上下文的生命周期长于请求上下的,但只是current_app。
Python框架学习之Flask中的视图及路由的更多相关文章
- Python框架学习之Flask中的蓝图与单元测试
因为Flask框架的集成度很低,随着Flask项目文件的增多,会导致不太好管理.但如果对一个项目进行模块化管理的,那样子管理起来就会特别方便.而在Flask中刚好就提供了这么一个特别好用的工具蓝图(B ...
- Python框架学习之Flask中的常用扩展包
Flask框架是一个扩展性非常强的框架,所以导致它有非常多的扩展包.这些扩展包的功能都很强大.本节主要汇总一些常用的扩展包. 一. Flask-Script pip install flask-scr ...
- Python框架学习之Flask中的Jinja2模板
前面也提到过在Flask中最核心的两个组件是Werkzeug和Jinja2模板.其中Werkzeug在前一节已经详细说明了.现在这一节主要是来谈谈Jinja2模板. 一.为什么需要引入模板: 在进行软 ...
- Python框架学习之Flask中的数据库操作
数据库操作在web开发中扮演着一个很重要的角色,网站中很多重要的信息都需要保存到数据库中.如用户名.密码等等其他信息.Django框架是一个基于MVT思想的框架,也就是说他本身就已经封装了Model类 ...
- flask 中使用蓝图将路由分开写在不同文件
flask 若想将不同的路由写在不同的文件中(如将 user 对象的相关接口写在一个文件中,将 customer 对象的相关接口写在另一个文件中),可以使用蓝图来实现. 有关蓝图的定义:A Bluep ...
- Python框架学习之用Flask创建一个简单项目
在前面一篇讲了如何创建一个虚拟环境,今天这一篇就来说说如何创建一个简单的Flask项目.关于Flask的具体介绍就不详细叙述了,我们只要知道它非常简洁.灵活和扩展性强就够了.它不像Django那样集成 ...
- 初识Flask框架,以及Flask中的模板语言jinjia2和Flask内置的Session
一.web框架的对比 首先我们先来看下比较火的web框架 1.Django: 优点:大而全,所有组件都是组织内部开发高度定制化,教科书级别的框架 缺点:大到浪费资源,请求的时候需要的资源较高 2.Fl ...
- StrangeIoc框架学习----在项目中实战
最近,因为公司的项目一直在研究StrangeIoc框架,小有所得,略作记录. StrangeIoc是一款基于MVCS的一种框架,是对MVC思想的扩展,是专门针对unity开发的一款框架,非常好用. 一 ...
- PyQt(Python+Qt)学习随笔:QTreeView树形视图的allColumnsShowFocus属性
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 QTreeView树形视图的allColumnsShowFocus属性用于控制是否使视图中的所有列显 ...
随机推荐
- if判断
<!-- 查询用户信息 --> <select id="queryUser3" parameterType="org.pine.mybatis.util ...
- MySQL添加新用户、为用户创建数据库、为新用户分配权限
登录MySQL [root@VM_0_2_33_centos /]#mysql -u root -p 添加新用户 允许本地 IP 访问 localhost, 127.0.0.1 mysql>'; ...
- Linux配置防火墙端口 8080端口
1.查看防火墙状态,哪些端口开放了 /etc/init.d/iptables status 2.配置防火墙 vi /etc/sysconfig/iptables ################# ...
- 用webpack2.0构建vue2.0超详细精简版
初始化环境 npm init -y 初始化项目 安装各种依赖项 npm install --save vue 安装vue2.0 npm install --save-dev webpack@^2.1. ...
- font-face在ie无法识别问题
font-face在ie的时候,需要其他格式eot,但是按照网上的设置无法识别,需要把原来的fotmat设置成format('eot');
- Duplicate entry '0' for key 'PRIMARY'
一般使用ORM时,提交新增实体时, mysql会出现此错误:Duplicate entry '0' for key 'PRIMARY' 原因是插入语句,未提供主键的值,且主键是非自增长的. 解决办法是 ...
- mysql随笔系列-1
MySQL数据库管理 本人实验所用的MySQL数据库版本:5.5.56-MariaDB MariaDB Server 操作系统:centos7.5 1.创建数据库 MariaDB [(none)]& ...
- 网络基础 记一次HTTPS证书验证测试过程
记一次HTTPS证书验证测试过程 by:授客 QQ:1033553122 实践 1) 安装证书 选择主机A(假设10.202.95.88)上安装https证书 说明:采用https的服务器,必须安装数 ...
- Android为TV端助力 切换fragment的两种方式
使用add方法切换时:载入Fragment1Fragment1 onCreateFragment1 onCreateViewFragment1 onStartFragment1 onResume用以下 ...
- vue缓存页面
vue如何和ionic的缓存机制一样,可以缓存页面,在A页面跳转至B页面后返回A页面时A页面的数据还在? 在app.vue中将router-view使用keep-alive包起来,使用v-if来判断使 ...