深入分析Zookeeper的实现原理
zookeeper 的由来:
分布式系统的很多难题,都是由于缺少协调机制造成的。在分布式协调这块做得比较好的,有 Google 的 Chubby 以及 Apache 的 Zookeeper。Google Chubby 是一个分布式锁服务,通过 Google Chubby 来解决分布式协作、Master 选举等与分布式锁服务相关的问题。
Zookeeper 也是类似,因为当时在雅虎内部的很多系统都需要依赖一个系统来进行分布式协调,但是谷歌的Chubby是不开源的,所以后来雅虎基于 Chubby 的思想开发了 zookeeper,并捐赠给了 Apache。
zookeeper解决了什么问题:
zookeeper是一个精简的文件系统。这点它和hadoop有点像,但是zookeeper这个文件系统是管理小文件的,而hadoop是管理超大文件的。
zookeeper提供了丰富的“构件”,这些构件可以实现很多协调数据结构和协议的操作。例如:分布式队列、分布式锁以及一组同级节点的“领导者选举”算法。
zookeeper是高可用的,它本身的稳定性是相当之好,分布式集群完全可以依赖zookeeper集群的管理,利用zookeeper避免分布式系统的单点故障的问题。
zookeeper采用了松耦合的交互模式。这点在zookeeper提供分布式锁上表现最为明显,zookeeper可以被用作一个约会机制,让参入的进程不在了解其他进程的(或网络)的情况下能够彼此发现并进行交互,参入的各方甚至不必同时存在,只要在zookeeper留下一条消息,在该进程结束后,另外一个进程还可以读取这条信息,从而解耦了各个节点之间的关系。
zookeeper为集群提供了一个共享存储库,集群可以从这里集中读写共享的信息,避免了每个节点的共享操作编程,减轻了分布式系统的开发难度。
zookeeper的设计采用的是观察者的设计模式,zookeeper主要是负责存储和管理大家关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper 就将负责通知已经在 Zookeeper 上注册的那些观察者做出相应的反应,从而实现集群中类似 Master/Slave 管理模式。
- 。。。。。
数据节点:
在 ZooKeeper中,每个数据节点都是有生命周期的,其生命周期的长短取决于数据节点的节点类型。在 ZooKeeper中,节点类型可以分为持久节点(PERSISTENT)、临时节点(EPHEMERAL)和顺序节点(SEQUENTIAL)三大类,具体在节点创建过程中,通过组合使用,可以生成以下四种组合型节点类型:
- 持久节点(PERSISTENT):持久节点是 ZooKeeper中最常见的一种节点类型。所谓持久节点,是指该数据节点被创建后,就会一直存在于 ZooKeeper服务器上,直到有删除操作来主动清除这个节点。
- 持久顺序节点(PERSISTENT SEQUENTIAL):持久顺序节点的基本特性和持久节点是一致的,额外的特性表现在顺序性上。在ZooKeeper中,每个父节点都会为它的第一级子节点维护一份顺序,用于记录下每个子节点创建的先后顺序。基于这个顺序特性,在创建子节点的时候,可以设置这个标记,那么在创建节点过程中, ZooKeeper会自动为给定节点名加上一个数字后缀,作为一个新的、完整的节点名。另外需要注意的是,这个数字后缀的上限是整型的最大值。
- 临时节点(EPHEMERAL):和持久节点不同的是,临时节点的生命周期和客户端的会话绑定在一起,也就是说,如果客户端会话失效,那么这个节点就会被自动清理掉。注意,这里提到的是客户端会话失效,而非TCP连接断开。另外, ZooKeeper规定了不能基于临时节点来创建子节点,即临时节点只能作为叶子节点。
- 临时顺序节点(EPHEMERAL SEQUENTIAL):临时顺序节点的基本特性和临时节点也是一致的,同样是在临时节点的基础上,添加了顺序的特性。
如果自己设计一个类似 zookeeper 这个中间件,我们需要考虑到什么呢?:
1. 防止单点故障
如果要防止 zookeeper 这个中间件的单点故障,那就势必要做集群。而且这个集群如果要满足高性能要求的话,还得是一个高性能高可用的集群。高性能意味着这个集群能够分担客户端的请求流量,高可用意味着集群中的某一个节点宕机以后,不影响整个集群的数据和继续提供服务的可能性。结论: 所以这个中间件需要考虑到集群,而且这个集群还需要分摊客户端的请求流量,实现服务的高性能。
2. 接着上面那个结论再来思考,如果要满足这样的一个高性能集群,我们最直观的想法应该是,每个节点都能接收到请求,并且每个节点的数据都必须要保持一致。要实现各个节点的数据一致性,就势必要一个 leader 节点负责协调和数据同步操作。这个我想大家都知道,如果在这样一个集群中没有 leader 节点,每个节点都可以接收所有请求,那么这个集群的数据同步的复杂度是非常大。结论:所以这个集群中涉及到数据同步以及会存在leader 节点
3.继续思考,如何在这些节点中选举出 leader 节点,以及leader 挂了以后,如何恢复呢?结论:所以 zookeeper 用了基于 paxos 理论所衍生出来的 ZAB 协议
.4. leader 节点如何和其他节点保证数据一致性,并且要求是强一致的。在分布式系统中,每一个机器节点虽然都能够明确知道自己进行的事务操作过程是成功和失败,但是却无法直接获取其他分布式节点的操作结果。所以当一个事务操作涉及到跨节点的时候,就需要用到分布式事务,分布式事务的数据一致性协议有 2PC 协议和3PC 协议。
Zookeeper 集群角色:
Leader 角色:Leader 服务器是整个 zookeeper 集群的核心,主要的工作任务有两项1. 事务请求的唯一调度和处理者,保证集群事物处理的顺序性2. 集群内部各服务器的调度者
Follower 角色:Follower 角色的主要职责是1. 处理客户端非事务请求、转发事务请求给 leader 服务器2. 参与事物请求 Proposal 的投票(需要半数以上服务器通过才能通知 leader commit 数据; Leader 发起的提案,要求 Follower 投票)3. 参与 Leader 选举的投票
Observer 角色:Observer 是 zookeeper3.3 开始引入的一个全新的服务器角色,从字面来理解,该角色充当了观察者的角色。观察 zookeeper 集群中的最新状态变化并将这些状态变化同步到 observer 服务器上。Observer 的工作原理与follower 角色基本一致,而它和 follower 角色唯一的不同在于 observer 不参与任何形式的投票,包括事务请求Proposal的投票和leader选举的投票。简单来说,observer服务器只提供非事务请求服务,通常在于不影响集群事物处理能力的前提下提升集群非事务处理的能力
zookeeper 的集群:
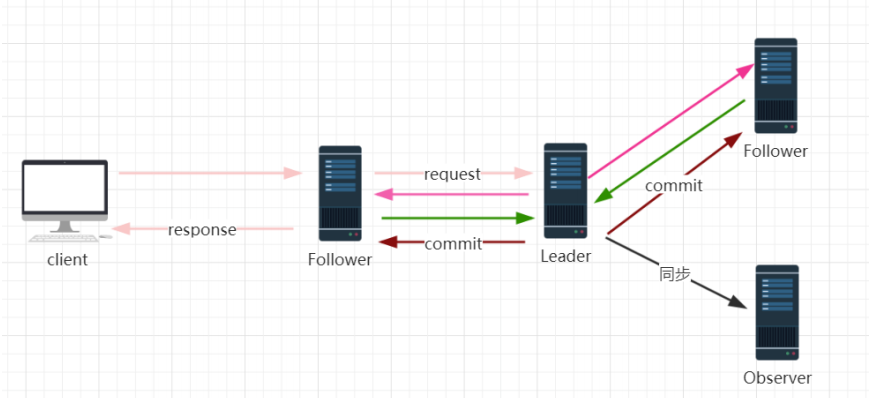
如上图,在 zookeeper 中,客户端会随机连接到 zookeeper 集群中的一个节点,如果是读请求,就直接从当前节点中读取数据,如果是写请求,那么请求会被转发给 leader 提交事务,然后 leader 会广播事务,只要有超过半数节点写入成功,那么写请求就会被提交(类 2PC 事务)
通常 zookeeper 是由 2n+1 台 server 组成,每个 server 都知道彼此的存在。对于 2n+1 台 server,只要有 n+1 台(大多数)server 可用,整个系统保持可用。我们已经了解到,一个 zookeeper 集群如果要对外提供可用的服务,那么集群中必须要有过半的机器正常工作并且彼此之间能够正常通信,基于这个特性,如果向搭建一个能够允许 F 台机器down 掉的集群,那么就要部署 2*F+1 台服务器构成的zookeeper 集群。因此 3 台机器构成的 zookeeper 集群,能够在挂掉一台机器后依然正常工作。一个 5 台机器集群的服务,能够对 2 台机器down掉的情况下进行容灾。如果一台由 6 台服务构成的集群,同样只能挂掉 2 台机器。因此,5 台和 6 台在容灾能力上并没有明显优势,反而增加了网络通信负担。系统启动时,集群中的 server 会选举出一台server 为 Leader,其它的就作为 follower(这里先不考虑observer 角色)。
之所以要满足这样一个等式,是因为一个节点要成为集群中的 leader,需要有超过及群众过半数的节点支持,这个涉及到 leader 选举算法。同时也涉及到事务请求的提交投票。
所有事务请求必须由一个全局唯一的服务器来协调处理,这个服务器就是 Leader 服务器,其他的服务器就是follower。leader 服务器把客户端的失去请求转化成一个事务 Proposal(提议),并把这个 Proposal 分发给集群中的所有 Follower 服务器。之后 Leader 服务器需要等待所有Follower 服务器的反馈,一旦超过半数的 Follower 服务器进行了正确的反馈,那么 Leader 就会再次向所有的Follower 服务器发送 Commit 消息,要求各个 follower 节点对前面的一个 Proposal 进行提交;
ZAB协议:
ZAB(Zookeeper Atomic Broadcast) 协议是为分布式协调服务 ZooKeeper 专门设计的一种支持崩溃恢复的原子广播协议。在 ZooKeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性,基于该协议,ZooKeeper 实现了一种主备模式的系统架构来保持集群中各个副本之间的数据一致性。ZAB 协议包含两种基本模式,分别是
1. 崩溃恢复
2. 原子广播
当整个集群在启动时,或者当 leader 节点出现网络中断、崩溃等情况时,ZAB 协议就会进入恢复模式并选举产生新的 Leader,当 leader 服务器选举出来后,并且集群中有过半的机器和该 leader 节点完成数据同步后(同步指的是数据同步,用来保证集群中过半的机器能够和 leader 服务器的数据状态保持一致),ZAB 协议就会退出恢复模式。当集群中已经有过半的 Follower 节点完成了和 Leader 状态同步以后,那么整个集群就进入了消息广播模式。这个时候,在 Leader 节点正常工作时,启动一台新的服务器加入到集群,那这个服务器会直接进入数据恢复模式,和 leader 节点进行数据同步。同步完成后即可正常对外提供非事务请求的处理。
消息广播的实现原理 :
消息广播的过程实际上是一个简化版本的二阶段提交过程。如下图:
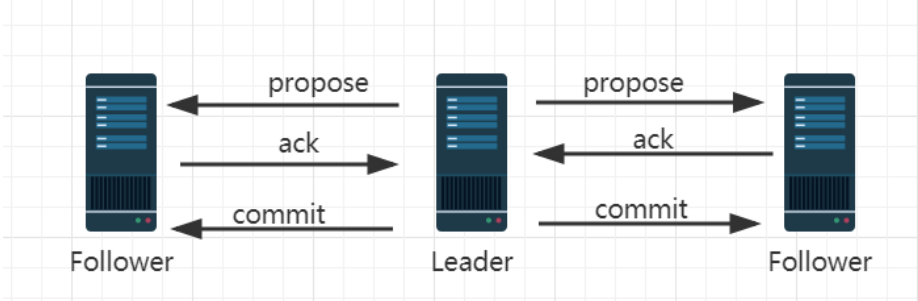
1. leader 接收到消息请求后,将消息赋予一个全局唯一的64 位自增 id,叫:zxid,通过 zxid 的大小比较既可以实现因果有序这个特征
2. leader 为每个 follower 准备了一个 FIFO 队列(通过 TCP协议来实现,以实现了全局有序这一个特点)将带有 zxid的消息作为一个提案(proposal)分发给所有的 follower
3. 当 follower 接收到 proposal,先把 proposal 写到磁盘,写入成功以后再向 leader 回复一个 ack
4. 当 leader 接收到合法数量(超过半数节点)的 ACK 后,leader 就会向这些 follower 发送 commit 命令,同时会在本地执行该消息
5. 当 follower 收到消息的 commit 命令以后,会提交该消息。
leader 的投票过程,不需要 Observer 的 ack,也就是Observer 不需要参与投票过程,但是 Observer 必须要同步 Leader 的数据从而在处理请求的时候保证数据的一致性
崩溃恢复(数据恢复):
ZAB 协议的这个基于原子广播协议的消息广播过程,在正常情况下是没有任何问题的,但是一旦 Leader 节点崩溃,或者由于网络问题导致 Leader 服务器失去了过半的Follower 节点的联系(leader 失去与过半 follower 节点联系,可能leader 节点和 follower 节点之间产生了网络分区,那么此时的 leader 不再是合法的 leader 了),那么就会进入到崩溃恢复模式。在 ZAB 协议中,为了保证程序的正确运行,整个恢复过程结束后需要选举出一个新的Leader为了使 leader 挂了后系统能正常工作,需要解决以下两个问题
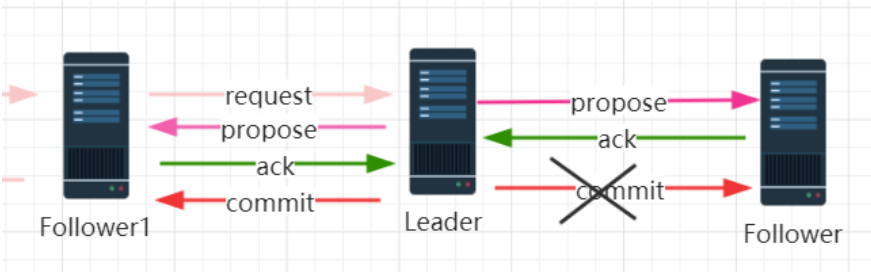
1. 已经被处理的消息不能丢失:当 leader 收到合法数量 follower 的 ACKs 后,就向各个 follower 广播 COMMIT 命令,同时也会在本地执行 COMMIT 并向连接的客户端返回「成功」。但是如果在各个 follower 在收到 COMMIT 命令前leader就挂了,导致剩下的服务器并没有执行都这条消息。leader 对事务消息发起 commit 操作,但是该消息在follower1 上执行了,但是 follower2 还没有收到 commit,就已经挂了,而实际上客户端已经收到该事务消息处理成功的回执了。所以在 zab 协议下需要保证所有机器都要执行这个事务消息
2. 被丢弃的消息不能再次出现:当 leader 接收到消息请求生成 proposal 后就挂了,其他 follower 并没有收到此 proposal,因此经过恢复模式重新选了 leader 后,这条消息是被跳过的。 此时,之前挂了的 leader 重新启动并注册成了follower,他保留了被跳过消息的 proposal 状态,与整个系统的状态是不一致的,需要将其删除。
ZAB 协议需要满足上面两种情况,就必须要设计一个leader 选举算法:能够确保已经被 leader 提交的事务Proposal能够提交、同时丢弃已经被跳过的事务Proposal。针对这个要求
1. 如果 leader 选举算法能够保证新选举出来的 Leader 服务器拥有集群中所有机器最高编号(ZXID 最大)的事务Proposal,那么就可以保证这个新选举出来的 Leader 一定具有已经提交的提案。因为所有提案被 COMMIT 之前必须有超过半数的 follower ACK,即必须有超过半数节点的服务器的事务日志上有该提案的 proposal,因此,只要有合法数量的节点正常工作,就必然有一个节点保存了所有被 COMMIT 消息的 proposal 状态另外一个,zxid 是 64 位,高 32 位是 epoch 编号,每经过一次 Leader 选举产生一个新的 leader,新的 leader 会将epoch 号+1,低 32 位是消息计数器,每接收到一条消息这个值+1,新 leader 选举后这个值重置为 0.这样设计的好处在于老的 leader 挂了以后重启,它不会被选举为 leader,因此此时它的 zxid 肯定小于当前新的 leader。当老的leader 作为 follower 接入新的 leader 后,新的 leader 会让它将所有的拥有旧的 epoch 号的未被 COMMIT 的proposal 清除
关于 ZXID :
zxid,也就是事务 id,为了保证事务的顺序一致性,zookeeper 采用了递增的事务 id 号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了 zxid。实现中 zxid 是一个 64 位的数字,它高 32 位是 epoch(ZAB 协议通过epoch 编号来区分 Leader 周期变化的策略)用来标识 leader 关系是否改变,每次一个 leader 被选出来,它都会有一个新的epoch=(原来的 epoch+1),标识当前属于那个 leader 的统治时期。低 32 位用于递增计数。epoch:可以理解为当前集群所处的年代或者周期,每个leader 就像皇帝,都有自己的年号,所以每次改朝换代,leader 变更之后,都会在前一个年代的基础上加 1。这样就算旧的 leader 崩溃恢复之后,也没有人听他的了,因为follower 只听从当前年代的 leader 的命令。epoch 的变化大家可以做一个简单的实验,
1. 启动一个 zookeeper 集群。
2. 在 /"dataDir"/zookeeper/VERSION-2 路 径 下 会 看 到 一 个currentEpoch 文件。文件中显示的是当前的 epoch
3. 把 leader 节点停机,这个时候在看 currentEpoch 会有变化。 随着每次选举新的 leader,epoch 都会发生变化
leader 选举:
Leader 选举会分两个过程启动的时候的 leader 选举、 leader 崩溃的时候的的选举服务器启动时的 leader 选举每个节点启动的时候状态都是 LOOKING,处于观望状态,接下来就开始进行选主流程进行 Leader 选举,至少需要两台机器,我们选取 3 台机器组成的服务器集群为例。在集群初始化阶段,当有一台服务器 Server1 启动时,它本身是无法进行和完成 Leader 选举,当第二台服务器 Server2 启动时,这个时候两台机器可以相互通信,每台机器都试图找到 Leader,于是进入 Leader 选举过程。选举过程如下:
(1) 每个 Server 发出一个投票。由于是初始情况,Server1和 Server2 都会将自己作为 Leader 服务器来进行投票,每次投票会包含所推举的服务器的 myid 和 ZXID、epoch,使用(myid, ZXID,epoch)来表示,此时 Server1的投票为(1, 0),Server2 的投票为(2, 0),然后各自将这个投票发给集群中其他机器。
(2) 接受来自各个服务器的投票。集群的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票(epoch)、是否来自LOOKING状态的服务器。
(3) 处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行 PK,PK 规则如下
i. 优先检查 ZXID。ZXID 比较大的服务器优先作为Leader
ii. 如果 ZXID 相同,那么就比较 myid。myid 较大的服务器作为 Leader 服务器。
对于 Server1 而言,它的投票是(1, 0),接收 Server2的投票为(2, 0),首先会比较两者的 ZXID,均为 0,再比较 myid,此时 Server2 的 myid 最大,于是更新自己的投票为(2, 0),然后重新投票,对于 Server2 而言,它不需要更新自己的投票,只是再次向集群中所有机器发出上一次投票信息即可。
(4) 统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息,对于 Server1、Server2 而言,都统计出集群中已经有两台机器接受了(2, 0)的投票信息,此时便认为已经选出了 Leader。
(5) 改变服务器状态。一旦确定了 Leader,每个服务器就会更新自己的状态,如果是 Follower,那么就变更为FOLLOWING,如果是 Leader,就变更为 LEADING。
运行过程中的 leader 选举:
当集群中的 leader 服务器出现宕机或者不可用的情况时,那么整个集群将无法对外提供服务,而是进入新一轮的Leader 选举,服务器运行期间的 Leader 选举和启动时期的 Leader 选举基本过程是一致的。
(1) 变更状态。Leader 挂后,余下的非 Observer 服务器都会将自己的服务器状态变更为 LOOKING,然后开始进入 Leader 选举过程。
(2) 每个 Server 会发出一个投票。在运行期间,每个服务器上的 ZXID 可能不同,此时假定 Server1 的 ZXID 为123,Server3的ZXID为122;在第一轮投票中,Server1和 Server3 都会投自己,产生投票(1, 123),(3, 122),然后各自将投票发送给集群中所有机器。接收来自各个服务器的投票。与启动时过程相同。
(3) 处理投票。与启动时过程相同,此时,Server1 将会成为 Leader。
(4) 统计投票。与启动时过程相同。
(5) 改变服务器的状态。与启动时过程相同
Leader 选举源码分析:
有了理论基础以后,我们先读一下源码(zookeeper-3.4.12),看看他的实现逻辑。首先我们需要知道源码入口,也就是Zookeeper启动的主类: QuorumPeerMain 类的 main 方法开始:
public static void main(String[] args) {
QuorumPeerMain main = new QuorumPeerMain();
try {//初始化主要逻辑
main.initializeAndRun(args);
}
//...异常捕获
LOG.info("Exiting normally");
System.exit();
}
进入 main.initializeAndRun(args) 可以看到:
protected void initializeAndRun(String[] args)
throws ConfigException, IOException
{
QuorumPeerConfig config = new QuorumPeerConfig();
if (args.length == ) {
config.parse(args[]);
}
// 启动后台定时任务异步执行清除任务,删除垃圾数据
// Start and schedule the the purge task
DatadirCleanupManager purgeMgr = new DatadirCleanupManager(config
.getDataDir(), config.getDataLogDir(), config
.getSnapRetainCount(), config.getPurgeInterval());
purgeMgr.start();
//判断是集群还是单机
if (args.length == && config.servers.size() > ) {
// 集群
runFromConfig(config);
} else {
LOG.warn("Either no config or no quorum defined in config, running "
+ " in standalone mode");
// there is only server in the quorum -- run as standalone
//单机
ZooKeeperServerMain.main(args);
}
}
进入 runFromConfig():
public void runFromConfig(QuorumPeerConfig config) throws IOException {
try {
ManagedUtil.registerLog4jMBeans();
} catch (JMException e) {
LOG.warn("Unable to register log4j JMX control", e);
}
LOG.info("Starting quorum peer");
try {// 初始化NIOServerCnxnFactory
ServerCnxnFactory cnxnFactory = ServerCnxnFactory.createFactory();
cnxnFactory.configure(config.getClientPortAddress(),
config.getMaxClientCnxns());
// 逻辑主线程 进行投票,选举
quorumPeer = getQuorumPeer();
// 进入一系列的配置
quorumPeer.setQuorumPeers(config.getServers());
quorumPeer.setTxnFactory(new FileTxnSnapLog(
new File(config.getDataLogDir()),
new File(config.getDataDir())));
quorumPeer.setElectionType(config.getElectionAlg());
quorumPeer.setMyid(config.getServerId()); //配置 myid
quorumPeer.setTickTime(config.getTickTime());
quorumPeer.setInitLimit(config.getInitLimit());
quorumPeer.setSyncLimit(config.getSyncLimit());
quorumPeer.setQuorumListenOnAllIPs(config.getQuorumListenOnAllIPs());
quorumPeer.setCnxnFactory(cnxnFactory);
quorumPeer.setQuorumVerifier(config.getQuorumVerifier());
// 为客户端提供写的server 即2181访问端口的访问功能
quorumPeer.setClientPortAddress(config.getClientPortAddress());
quorumPeer.setMinSessionTimeout(config.getMinSessionTimeout());
quorumPeer.setMaxSessionTimeout(config.getMaxSessionTimeout());
quorumPeer.setZKDatabase(new ZKDatabase(quorumPeer.getTxnFactory()));
quorumPeer.setLearnerType(config.getPeerType());
quorumPeer.setSyncEnabled(config.getSyncEnabled());
// sets quorum sasl authentication configurations
quorumPeer.setQuorumSaslEnabled(config.quorumEnableSasl);
if(quorumPeer.isQuorumSaslAuthEnabled()){
quorumPeer.setQuorumServerSaslRequired(config.quorumServerRequireSasl);
quorumPeer.setQuorumLearnerSaslRequired(config.quorumLearnerRequireSasl);
quorumPeer.setQuorumServicePrincipal(config.quorumServicePrincipal);
quorumPeer.setQuorumServerLoginContext(config.quorumServerLoginContext);
quorumPeer.setQuorumLearnerLoginContext(config.quorumLearnerLoginContext);
}
quorumPeer.setQuorumCnxnThreadsSize(config.quorumCnxnThreadsSize);
// 初始化的工作
quorumPeer.initialize();
// 启动主线程,QuorumPeer 重写了 Thread.start 方法
quorumPeer.start();
quorumPeer.join();//使得线程之间的并行执行变为串行执行
} catch (InterruptedException e) {
// warn, but generally this is ok
LOG.warn("Quorum Peer interrupted", e);
}
}
调用 QuorumPeer 的 start 方法:
@Override
public synchronized void start() {
//载入本地DB数据 主要还是epoch
loadDataBase();
//启动ZooKeeperThread线程
cnxnFactory.start();
//启动leader选举线程
startLeaderElection();
super.start();
}
loadDataBase() 主要是从本地文件中恢复数据,以及获取最新的 zxid。
private void loadDataBase() {
File updating = new File(getTxnFactory().getSnapDir(),
UPDATING_EPOCH_FILENAME);
try {//载入本地数据
zkDb.loadDataBase();
// load the epochs 加载ZXID
long lastProcessedZxid = zkDb.getDataTree().lastProcessedZxid;
// 根据zxid的高32位是epoch号,低32位是事务id进行抽离epoch号
long epochOfZxid = ZxidUtils.getEpochFromZxid(lastProcessedZxid);
try {//从${data}/version-2/currentEpochs文件中加载当前的epoch号
currentEpoch = readLongFromFile(CURRENT_EPOCH_FILENAME);
//从 zxid中提取的epoch比文件里的epoch要大的话,并且没有正在修改epoch
if (epochOfZxid > currentEpoch && updating.exists()) {
setCurrentEpoch(epochOfZxid);//设置位大的epoch
if (!updating.delete()) {
throw new IOException("Failed to delete " +
updating.toString());
}
}
}
// ........
//如果如果还比他大 抛出异常
if (epochOfZxid > currentEpoch) {
throw new IOException("The current epoch, " + ZxidUtils.zxidToString(currentEpoch) + ", is older than the last zxid, " + lastProcessedZxid);
}
try {//再比较 acceptedEpoch
acceptedEpoch = readLongFromFile(ACCEPTED_EPOCH_FILENAME);
}
// ........
if (acceptedEpoch < currentEpoch) {
throw new IOException("The accepted epoch, " + ZxidUtils.zxidToString(acceptedEpoch) + " is less than the current epoch, " + ZxidUtils.zxidToString(currentEpoch));
}
// .......
}
接下去就是初始化选举算法 leaderElection:
synchronized public void startLeaderElection() {
try { // 根据myid zxid epoch 3个选举参数创建Voto 对象,准备选举
currentVote = new Vote(myid, getLastLoggedZxid(), getCurrentEpoch());
} catch(IOException e) {
RuntimeException re = new RuntimeException(e.getMessage());
re.setStackTrace(e.getStackTrace());
throw re;
}
for (QuorumServer p : getView().values()) {
if (p.id == myid) {
myQuorumAddr = p.addr;
break;
}
}
if (myQuorumAddr == null) {
throw new RuntimeException("My id " + myid + " not in the peer list");
}
if (electionType == ) {//如果是这个选举策略,代表 LeaderElection选举策略
try {//创建 UDP Socket
udpSocket = new DatagramSocket(myQuorumAddr.getPort());
responder = new ResponderThread();
responder.start();
} catch (SocketException e) {
throw new RuntimeException(e);
}
}//根据类型创建选举算法
this.electionAlg = createElectionAlgorithm(electionType);
}
进入选举算法的初始化 createElectionAlgorithm():配置选举算法,选举算法有 3 种,可以通过在 zoo.cfg 里面进行配置,默认是 FastLeaderElection 选举
protected Election createElectionAlgorithm(int electionAlgorithm){
Election le=null;
// 选择选举策略
//TODO: use a factory rather than a switch
switch (electionAlgorithm) {
case :
le = new LeaderElection(this);
break;
case :
le = new AuthFastLeaderElection(this);
break;
case :
le = new AuthFastLeaderElection(this, true);
break;
case ://Leader选举IO负责类
qcm = createCnxnManager();
QuorumCnxManager.Listener listener = qcm.listener;
if(listener != null){
// 启动已绑定端口的选举线程,等待其他服务器连接
listener.start();
//基于 TCP的选举算法
le = new FastLeaderElection(this, qcm);
} else {
LOG.error("Null listener when initializing cnx manager");
}
break;
default:
assert false;
}
return le;
}
继续看 FastLeaderElection 的初始化动作,主要初始化了业务层的发送队列和接收队列 :
public FastLeaderElection(QuorumPeer self, QuorumCnxManager manager){
this.stop = false;
this.manager = manager;
starter(self, manager);
}
// ***********************************************
private void starter(QuorumPeer self, QuorumCnxManager manager) {
this.self = self;
proposedLeader = -;
proposedZxid = -;
// 投票 发送队列 阻塞
sendqueue = new LinkedBlockingQueue<ToSend>();
// 投票 接受队列 阻塞
recvqueue = new LinkedBlockingQueue<Notification>();
this.messenger = new Messenger(manager);
}
然后再 Messager 的构造函数里 初始化发送和接受两个线程并且启动线程。
Messenger(QuorumCnxManager manager) {//异步决策
// 创建 vote 发送线程
this.ws = new WorkerSender(manager);
Thread t = new Thread(this.ws,"WorkerSender[myid=" + self.getId() + "]");
t.setDaemon(true);
t.start();//启动
// 创建 vote 接受线程
this.wr = new WorkerReceiver(manager);
t = new Thread(this.wr,"WorkerReceiver[myid=" + self.getId() + "]");
t.setDaemon(true);
t.start();//启动
}
然后再回到 QuorumPeer.java。 FastLeaderElection 初始化完成以后,调用 super.start(),最终运行 QuorumPeer 的run 方法
public void run() {
setName("QuorumPeer" + "[myid=" + getId() + "]" +
cnxnFactory.getLocalAddress());
// 省略通过JMX初始化。来监控一些属性的代码
try {
// Main loop 主循环
while (running) {
switch (getPeerState()) {
case LOOKING: //LOOKING 状态,则进入选举
if (Boolean.getBoolean("readonlymode.enabled")) {
// 创建 ReadOnlyZooKeeperServer,但是不立即启动
final ReadOnlyZooKeeperServer roZk = new ReadOnlyZooKeeperServer(
logFactory, this,
new ZooKeeperServer.BasicDataTreeBuilder(),
this.zkDb);
//通过 Thread 异步解耦
Thread roZkMgr = new Thread() {
public void run() {
try {
// lower-bound grace period to 2 secs
sleep(Math.max(, tickTime));
if (ServerState.LOOKING.equals(getPeerState())) {
roZk.startup();
}
// .......
}
};
try {//启动
roZkMgr.start();
setBCVote(null);
// 通过策略模式来决定当前用那个算法选举
setCurrentVote(makeLEStrategy().lookForLeader());
// .........
} else {
try {
setBCVote(null);
setCurrentVote(makeLEStrategy().lookForLeader());
//........
}
break;
//****************************************************************************
case OBSERVING: // Observing 针对 Observer角色的节点
try {
LOG.info("OBSERVING");
setObserver(makeObserver(logFactory));
observer.observeLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception",e );
} finally {
observer.shutdown();
setObserver(null);
setPeerState(ServerState.LOOKING);
}
break;
//*****************************************************************************
case FOLLOWING:// 从节点状态
try {
LOG.info("FOLLOWING");
setFollower(makeFollower(logFactory));
follower.followLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
follower.shutdown();
setFollower(null);
setPeerState(ServerState.LOOKING);
}
break;
//**********************************************************************
case LEADING: // leader 节点
LOG.info("LEADING");
try {
setLeader(makeLeader(logFactory));
leader.lead();
setLeader(null);
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
if (leader != null) {
leader.shutdown("Forcing shutdown");
setLeader(null);
}
setPeerState(ServerState.LOOKING);
}
break;
}
}
}
// ..........
}
由于是刚刚启动,是 LOOKING 状态。所以走第一条分支。调用 setCurrentVote(makeLEStrategy().lookForLeader());,最终根据上一步选择的策略应该运行 FastLeaderElection 中的选举算法,看一下 lookForLeader();
//开始选举 Leader
public Vote lookForLeader() throws InterruptedException {
// ...省略一些代码
try {
// 收到的投票
HashMap<Long, Vote> recvset = new HashMap<Long, Vote>();
// 存储选举结果
HashMap<Long, Vote> outofelection = new HashMap<Long, Vote>(); int notTimeout = finalizeWait; synchronized(this){
logicalclock.incrementAndGet(); // 增加逻辑时钟
// 修改自己的zxid epoch
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
sendNotifications(); // 发送投票 // Loop in which we exchange notifications until we find a leader
while ((self.getPeerState() == ServerState.LOOKING) &&
(!stop)){ // 主循环 直到选举出leader
/*
* Remove next notification from queue, times out after 2 times
* the termination time
*/
//从IO进程里面 获取投票结果,自己的投票也在里面
Notification n = recvqueue.poll(notTimeout,TimeUnit.MILLISECONDS); // 如果没有获取到足够的通知久一直发送自己的选票,也就是持续进行选举
if(n == null){
// 如果空了 就继续发送 直到选举出leader
if(manager.haveDelivered()){
sendNotifications();
} else {
// 消息没发出去,可能其他集群没启动 继续尝试连接
manager.connectAll();
}
/// 延长超时时间
int tmpTimeOut = notTimeout*;
notTimeout = (tmpTimeOut < maxNotificationInterval?
tmpTimeOut : maxNotificationInterval);
LOG.info("Notification time out: " + notTimeout);
}
// 收到投票消息 查看是否属于本集群内的消息
else if(self.getVotingView().containsKey(n.sid)) {
switch (n.state) {// 判断收到消息的节点状态
case LOOKING:
// If notification > current, replace and send messages out
// 判断epoch 是否大于 logicalclock ,如是,则是新一轮选举
if (n.electionEpoch > logicalclock.get()) {
logicalclock.set(n.electionEpoch); // 更新本地logicalclock
recvset.clear(); // 清空接受队列
// 一次性比较 myid epoch zxid 看此消息是否胜出
if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, //此方法看下面代码
getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
//投票结束修改票据为 leader票据
updateProposal(n.leader, n.zxid, n.peerEpoch);
} else {//否则票据不变
updateProposal(getInitId(),
getInitLastLoggedZxid(),
getPeerEpoch());
}
sendNotifications(); // 继续广播票据,让其他节点知道我现在的投票
//如果是epoch小于当前 忽略
} else if (n.electionEpoch < logicalclock.get()) {
break;
//如果 epoch 相同 跟上面一样的比较 更新票据 广播票据
} else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
sendNotifications();
} // 把最终票据放进接受队列 用来做最后判断
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
// 判断选举是否结束 默认算法是否超过半数同意 见下面代码
if (termPredicate(recvset,
new Vote(proposedLeader, proposedZxid,
logicalclock.get(), proposedEpoch))) { // 一直等待 notification 到达 直到超时
while((n = recvqueue.poll(finalizeWait,
TimeUnit.MILLISECONDS)) != null){
if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)){
recvqueue.put(n);
break;
}
}
// 确定 leader
if (n == null) {
// 修改状态
self.setPeerState((proposedLeader == self.getId()) ?
ServerState.LEADING: learningState());
//返回最终投票结果
Vote endVote = new Vote(proposedLeader,
proposedZxid,
logicalclock.get(),
proposedEpoch);
leaveInstance(endVote);
return endVote;
}
}
break;
// 如果收到的选票状态 不是LOOKING 比如己气刚刚加入已经选举好的集群
// Observer 不参与选举
case OBSERVING:
LOG.debug("Notification from observer: " + n.sid);
break; case FOLLOWING:
case LEADING:
// 判断 epoch 是否相同
if(n.electionEpoch == logicalclock.get()){
recvset.put(n.sid, new Vote(n.leader,
n.zxid,
n.electionEpoch,
n.peerEpoch));
// 投票是否结束 结束的话确认leader 是否有效
// 如果结束 修改自己的投票并且返回
if(ooePredicate(recvset, outofelection, n)) {
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING: learningState()); Vote endVote = new Vote(n.leader,
n.zxid,
n.electionEpoch,
n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
} //在加入一个已建立的集群之前,确认大多数人都在跟随同一个Leader。
outofelection.put(n.sid, new Vote(n.version,
n.leader,
n.zxid,
n.electionEpoch,
n.peerEpoch,
n.state)); if(ooePredicate(outofelection, outofelection, n)) {
synchronized(this){
logicalclock.set(n.electionEpoch);
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING: learningState());
}
Vote endVote = new Vote(n.leader,
n.zxid,
n.electionEpoch,
n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
break;
default:
LOG.warn("Notification state unrecognized: {} (n.state), {} (n.sid)",
n.state, n.sid);
break;
}
} else {
LOG.warn("Ignoring notification from non-cluster member " + n.sid);
}
}
return null;
}
// .......
}
上述选举中是通过获取到选票,然后根据选票中的3大元素跟本地进行比对。进入 totalOrderPredicate :
protected boolean totalOrderPredicate(long newId, long newZxid, long newEpoch, long curId, long curZxid, long curEpoch) {
LOG.debug("id: " + newId + ", proposed id: " + curId + ", zxid: 0x" +
Long.toHexString(newZxid) + ", proposed zxid: 0x" + Long.toHexString(curZxid));
if(self.getQuorumVerifier().getWeight(newId) == ){
return false;
}
/*如果以下三种情况之一成立,则返回true:
* 1-选票中epoch更高
* 2-选票中epoch与当前epoch相同,但新zxid更高
* 3-选票中epoch与当前epoch相同,新zxid与当前zxid相同服务器id更高。
*/
//这里判断规则很明显,先比较epoch 如果相等比较 zxid 继续想等继续比较 myid 大的为leader
return ((newEpoch > curEpoch) ||
((newEpoch == curEpoch) &&
((newZxid > curZxid) || ((newZxid == curZxid) && (newId > curId)))));
}
选票方法,便利选票集合,查看是否有人选票超过一半,其实就是判断是否选出了leader:
protected boolean termPredicate(HashMap<Long, Vote> votes,Vote vote) {
HashSet<Long> set = new HashSet<Long>();
/*
* First make the views consistent. Sometimes peers will have
* different zxids for a server depending on timing.
*/
// 遍历接收到的集合 把符合当前投票的 放入 Set
for (Map.Entry<Long,Vote> entry : votes.entrySet()) {
if (vote.equals(entry.getValue())){
set.add(entry.getKey());
}
}
// 统计票据,看是否过半
return self.getQuorumVerifier().containsQuorum(set);
}
到这里为止,Leader选举就结束了。我们再来看看消息如何广播,看 sendNotifications:
private void sendNotifications() {
for (QuorumServer server : self.getVotingView().values()) {// 循环发送
long sid = server.id;
// 准备发送的消息实体
ToSend notmsg = new ToSend(ToSend.mType.notification,
proposedLeader,
proposedZxid,
logicalclock.get(),
QuorumPeer.ServerState.LOOKING,
sid,
proposedEpoch);
if(LOG.isDebugEnabled()){
LOG.debug("Sending Notification: " + proposedLeader + " (n.leader), 0x" +
Long.toHexString(proposedZxid) + " (n.zxid), 0x" + Long.toHexString(logicalclock.get()) +
" (n.round), " + sid + " (recipient), " + self.getId() +
" (myid), 0x" + Long.toHexString(proposedEpoch) + " (n.peerEpoch)");
}
sendqueue.offer(notmsg); // 使用offer 添加到队列 会被sendWorker线程消费
}
}
FastLeaderElection 选举过程:
其实在这个投票过程中就涉及到几个类,FastLeaderElection:FastLeaderElection 实现了 Election 接口,实现各服务器之间基于 TCP 协议进行选举Notification:内部类,Notification 表示收到的选举投票信息(其他服务器发来的选举投票信息),其包含了被选举者的 id、zxid、选举周期等信息ToSend:ToSend表示发送给其他服务器的选举投票信息,也包含了被选举者的 id、zxid、选举周期等信息Messenger : Messenger 包 含 了 WorkerReceiver 和WorkerSender 两个内部类;WorkerReceiver 实现了 Runnable 接口,是选票接收器。其会不断地从 QuorumCnxManager 中获取其他服务器发来的选举消息,并将其转换成一个选票,然后保存到recvqueue 中WorkerSender 也实现了 Runnable 接口,为选票发送器,其会不断地从 sendqueue 中获取待发送的选票,并将其传递到底层 QuorumCnxManager 中
至于 Zookeeper是真么接受请求的,其实我们可以看一下代码:
@Override
public synchronized void start() {
//载入本地DB数据 主要还是epoch
loadDataBase();
//启动ZooKeeperThread线程
cnxnFactory.start();
//启动leader选举线程
startLeaderElection();
super.start();
}
其中 cnxnFactory.start(); 就是启动了服务端的接受请求的线程,默认实现有两个 NIO 及 Netty:

至于怎么设置请看如下代码:
//这个是我们需要配置的属性key
public static final String ZOOKEEPER_SERVER_CNXN_FACTORY = "zookeeper.serverCnxnFactory";
static public ServerCnxnFactory createFactory() throws IOException {
String serverCnxnFactoryName =
System.getProperty(ZOOKEEPER_SERVER_CNXN_FACTORY);
if (serverCnxnFactoryName == null) {//默认是NIO
serverCnxnFactoryName = NIOServerCnxnFactory.class.getName();
}
try {//这里配置的类即Netty
ServerCnxnFactory serverCnxnFactory = (ServerCnxnFactory) Class.forName(serverCnxnFactoryName)
.getDeclaredConstructor().newInstance();
LOG.info("Using {} as server connection factory", serverCnxnFactoryName);
return serverCnxnFactory;
} catch (Exception e) {
IOException ioe = new IOException("Couldn't instantiate "
+ serverCnxnFactoryName);
ioe.initCause(e);
throw ioe;
}
}
至于接下去的接受请求这里就不展开了,无非是通过NIO 或者Netty去处理请求。操作节点。
深入分析Zookeeper的实现原理的更多相关文章
- zookeeper(2) zookeeper的核心原理
zookeeper 的前世今生 分布式系统的很多难题,都是由于缺少协调机制造成的.在分布式协调这块做得比较好的,有 Google 的 Chubby 以及 Apache 的 Zookeeper. Goo ...
- 从Paxos到Zookeeper 分布式一致性原理与实践读书心得
一 本书作者介绍 此书名为从Paxos到ZooKeeper分布式一致性原理与实践,作者倪超,阿里巴巴集团高级研发工程师,国家认证系统分析师,毕业于杭州电子科技大学计算机系.2010年加入阿里巴巴中间件 ...
- zookeeper初识之原理
ZooKeeper 是一个分布式的,开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等. Zookeeper是hadoop的一个子项目 ...
- zookeeper使用跟原理
zookeeper使用和原理 zookeeper介绍zookeeper是一个为分布式应用提供一致性服务的软件,它是开源的Hadoop项目中的一个子项目,并且根据google发表的<The Chu ...
- 聊聊并发(一)深入分析Volatile的实现原理
本文属于作者原创,原文发表于InfoQ:http://www.infoq.com/cn/articles/ftf-java-volatile 引言 在多线程并发编程中synchronized和Vola ...
- zookeeper 分布式锁原理
zookeeper 分布式锁原理: 1 大家也许都很熟悉了多个线程或者多个进程间的共享锁的实现方式了,但是在分布式场景中我们会面临多个Server之间的锁的问题,实现的复杂度比较高.利用基于googl ...
- zookeeper应用与原理学习总结
一.什么是zookeeper Zookeeper 分布式服务框架是Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务.状态同步服务.集群 ...
- Hadoop生态圈-Zookeeper的工作原理分析
Hadoop生态圈-Zookeeper的工作原理分析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 无论是是Kafka集群,还是producer和consumer都依赖于Zoo ...
- Zookeeper选举算法原理
Zookeeper选举算法原理 Leader选举 Leader选举是保证分布式数据一致性的关键所在.当Zookeeper集群中的一台服务器出现以下两种情况之一时,需要进入Leader选举. (1) 服 ...
随机推荐
- Hadoop之MapReduce思维导图
- 浅谈linux线程切换问题
http://www.jb51.net/article/102059.htm 处理器总处于以下状态中的一种: 1.内核态,运行于进程上下文,内核代表进程运行于内核空间 2.内核态,运行于中断上下文,内 ...
- 异步Async
1.c#异步介绍 异步必须基于委托,有委托才有异步 新建一个window Form程序MyAsync,添加一个按钮,(name)=btnAsync 后台代码如下: using System;using ...
- j假设程序需要要一个int烈血的刀变量来保存1英里所包含的步数(5280)为该变量编写一条声明语句。
j假设程序需要要一个int烈血的刀变量来保存1英里所包含的步数(5280)为该变量编写一条声明语句. final intFT_PER_MILE =5280
- 【VMware vSphere】ESXi系统设置静态IP
写在前面: 为了方便管理,一般将ESXi系统的IP设置为静态 ESXi6.5系统和6.0系统类似,这里以ESXi6.0系统为例 1, 进入系 ...
- ethtool 解决网卡丢包严重和网卡原理【转】
转自:https://blog.csdn.net/u011857683/article/details/83758869 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog ...
- xv6 + Qemu 在Ubuntu下编译运行教程【转】
转自:https://blog.csdn.net/yinglang19941010/article/details/49310111 如果想要离线看教程,可以下载该 文档 一.使用工具说明 1. ...
- Windows PowerShell 入門(5)-制御構文
Windows PowerShellにおける制御構文について学びます.数ある制御構文の中でもSwitch文は.他の言語に比べ豊富な機能が用意されています. 対象読者 Windows PowerShel ...
- 虚拟化之kvm --(vnc控制台)
作者:邓聪聪 随着日益不同的需求增多,为了满足主机供求,get到这一招虚拟化技术,以增加点见识! 1.使用yum安装: yum -y install qemu-kvm libvirt python-v ...
- C# 基础之string[,] 和string[][]
昨天做项目时碰到一个问题,后台返回一张关系表,里面就两个字段,简化为A,B字段(1:N的关系),一个A对应多个B字段. 由于对于string[,] 和string[][] 的认识不到位,刚开始搞错了数 ...