SnowFlake学习
分布式系统中生成全局唯一且趋势递增ID
UUID - 太长,无序,数据库插入分裂性能不行
利用数据库自增序列,等步长生成 - 依赖数据库
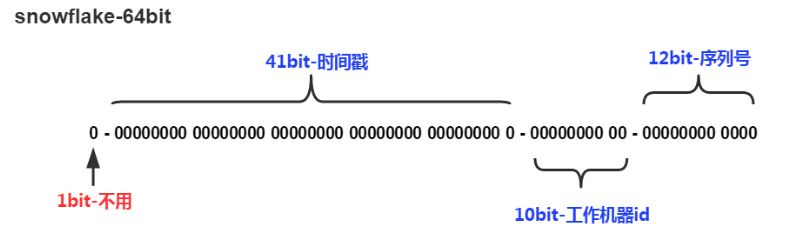
SnowFlake:使用见下图
抄代码 https://www.cnblogs.com/relucent/p/4955340.html
/**
* Twitter_Snowflake<br>
* SnowFlake的结构如下(每部分用-分开):<br>
* 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000 <br>
* 1位标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0<br>
* 41位时间截(毫秒级),注意,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截)
* 得到的值),这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的(如下下面程序IdWorker类的startTime属性)。41位的时间截,可以使用69年,年T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69<br>
* 10位的数据机器位,可以部署在1024个节点,包括5位datacenterId和5位workerId<br>
* 12位序列,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号<br>
* 加起来刚好64位,为一个Long型。<br>
* SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,经测试,SnowFlake每秒能够产生26万ID左右。
*/
public class SnowflakeIdWorker { // ==============================Fields===========================================
/** 开始时间截 (2015-01-01) */
private final long twepoch = 1420041600000L; /** 机器id所占的位数 */
private final long workerIdBits = 5L; /** 数据标识id所占的位数 */
private final long datacenterIdBits = 5L; /** 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数) */
private final long maxWorkerId = -1L ^ (-1L << workerIdBits); /** 支持的最大数据标识id,结果是31 */
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits); /** 序列在id中占的位数 */
private final long sequenceBits = 12L; /** 机器ID向左移12位 */
private final long workerIdShift = sequenceBits; /** 数据标识id向左移17位(12+5) */
private final long datacenterIdShift = sequenceBits + workerIdBits; /** 时间截向左移22位(5+5+12) */
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits; /** 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095) */
private final long sequenceMask = -1L ^ (-1L << sequenceBits); /** 工作机器ID(0~31) */
private long workerId; /** 数据中心ID(0~31) */
private long datacenterId; /** 毫秒内序列(0~4095) */
private long sequence = 0L; /** 上次生成ID的时间截 */
private long lastTimestamp = -1L; //==============================Constructors=====================================
/**
* 构造函数
* @param workerId 工作ID (0~31)
* @param datacenterId 数据中心ID (0~31)
*/
public SnowflakeIdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
} // ==============================Methods==========================================
/**
* 获得下一个ID (该方法是线程安全的)
* @return SnowflakeId
*/
public synchronized long nextId() {
long timestamp = timeGen(); //如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
} //如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出
if (sequence == 0) {
//阻塞到下一个毫秒,获得新的时间戳
timestamp = tilNextMillis(lastTimestamp);
}
}
//时间戳改变,毫秒内序列重置
else {
sequence = 0L;
} //上次生成ID的时间截
lastTimestamp = timestamp; //移位并通过或运算拼到一起组成64位的ID
return ((timestamp - twepoch) << timestampLeftShift) //
| (datacenterId << datacenterIdShift) //
| (workerId << workerIdShift) //
| sequence;
} /**
* 阻塞到下一个毫秒,直到获得新的时间戳
* @param lastTimestamp 上次生成ID的时间截
* @return 当前时间戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
} /**
* 返回以毫秒为单位的当前时间
* @return 当前时间(毫秒)
*/
protected long timeGen() {
return System.currentTimeMillis();
} //==============================Test=============================================
/** 测试 */
public static void main(String[] args) {
SnowflakeIdWorker idWorker = new SnowflakeIdWorker(0, 0);
for (int i = 0; i < 1000; i++) {
long id = idWorker.nextId();
System.out.println(Long.toBinaryString(id));
System.out.println(id);
}
}
}
特别 from:https://blog.csdn.net/bjweimengshu/article/details/80162731
1.获得单一机器的下一个序列号,使用Synchronized控制并发,而非CAS的方式,是因为CAS不适合并发量非常高的场景。
2.如果当前毫秒在一台机器的序列号已经增长到最大值4095,则使用while循环等待直到下一毫秒。
3.如果当前时间小于记录的上一个毫秒值,则说明这台机器的时间回拨了,抛出异常。但如果这台机器的系统时间在启动之前回拨过,那么有可能出现ID重复的危险
好处:
1.生成ID时不依赖于DB,完全在内存生成,高性能高可用。
2.ID呈趋势递增,后续插入索引树的时候性能较好。
缺点:
依赖时钟,可能回拨
可以根据自己的系统定制,大同小异
SnowFlake学习的更多相关文章
- [C#] 分布式ID自增算法 Snowflake
最近在尝试EF的多数据库移植,但是原始项目中主键用的Sqlserver的GUID.MySQL没法移植了. 其实发现GUID也没法保证数据的递增性,又不太想使用int递增主键,就开始探索别的ID形式. ...
- 分布式唯一id:snowflake算法思考
匠心零度 转载请注明原创出处,谢谢! 缘起 为什么会突然谈到分布式唯一id呢?原因是最近在准备使用RocketMQ,看看官网介绍: 一句话,消息可能会重复,所以消费端需要做幂等.为什么消息会重复后续R ...
- .Net Core ORM选择之路,哪个才适合你 通用查询类封装之Mongodb篇 Snowflake(雪花算法)的JavaScript实现 【开发记录】如何在B/S项目中使用中国天气的实时天气功能 【开发记录】微信小游戏开发入门——俄罗斯方块
.Net Core ORM选择之路,哪个才适合你 因为老板的一句话公司项目需要迁移到.Net Core ,但是以前同事用的ORM不支持.Net Core 开发过程也遇到了各种坑,插入条数多了也特别 ...
- zookeeper snowflake 实战
目录 写在前面 1.1.1. 集群节点的命名服务 1.1.2. snowflake 的ID算法改造 SnowFlake算法的优点: SnowFlake算法的缺点: 写在最后 疯狂创客圈 亿级流量 高并 ...
- snowflake算法
snowflake算法思考 缘起 为什么会突然谈到分布式唯一id呢?原因是最近在准备使用RocketMQ,看看官网介绍: 一句话,消息可能会重复,所以消费端需要做幂等.为什么消息会重复后续Rocket ...
- 一篇文章彻底搞懂snowflake算法及百度美团的最佳实践
写在前面的话 一提到分布式ID自动生成方案,大家肯定都非常熟悉,并且立即能说出自家拿手的几种方案,确实,ID作为系统数据的重要标识,重要性不言而喻,而各种方案也是历经多代优化,请允许我用这个视角对分布 ...
- 深入学习 OLED Adafruit_SSD1306库(8266+arduino)
QQ技术互动交流群:ESP8266&32 物联网开发 群号622368884,不喜勿喷 单片机菜鸟博哥CSDN 1.前言 SSD1306屏幕驱动库,最出名应该就是u8g2,读者可以参考 玩转u ...
- Dubbo学习系列之七(分布式订单ID方案)
既然选择,就注定风雨兼程! 开始吧! 准备:Idea201902/JDK11/ZK3.5.5/Gradle5.4.1/RabbitMQ3.7.13/Mysql8.0.11/Lombok0.26/Erl ...
- 学习笔记之Coding / Design / Tool
CODING 学习笔记之代码大全2 - 浩然119 - 博客园 https://www.cnblogs.com/pegasus923/p/5301123.html 学习笔记之编程珠玑 Programm ...
随机推荐
- maya_help()验证编程过程中模块导入的情况
import rigLib reload(rigLib.base.control)spine = rigLib.base.control.Control( prefix = 'spine1') hel ...
- Python(五) —— 内置模块
文档参考:https://docs.python.org/zh-cn/3.7/library/index.html 随机模块——random 这里我们介绍几种常用 random 的操作 名称 功能 ...
- haproxy反向代理
haproxy是个高性能的tcp和http的反向代理.它就是个代理.不像nginx还做web服务器 官网地址为www.haproxy.org nginx的优点和缺点 优点: 1.web服务器,应用比较 ...
- 弹出的 Dialog 里,包含 Form,如何在关闭 Dialog 时,执行 resetFields(对整个表单进行重置,将所有字段值重置为初始值并移除校验结果)
做法: before-close 事件中,调用 resetFields 取消按钮事件中,调用 resetFields <el-dialog title="弹出窗口" :vis ...
- wakatime记录 coding时间的工具
想记录下自己每天coding 的时间以及每个在各个项目上coding的时间,之前一直也没有什么好的办法,无意之间发现wakatime这个插件可以记录自己每天有效的coding时间. wakatime ...
- win10自动更新后SQLServer无法启动的问题排查
今天中午windows提示更新系统补丁并重启后发现,本地的SQL Server服务器没有正常启动,手工启动sqlserver也失败了,报错:找不到ERRORLOG文件及相应目录. 很是奇怪.强制创建该 ...
- MQTT研究之EMQ:【wireshark抓包分析】
基于上篇博文[SSL双向验证]的环境基础,进行消息的具体梳理. 环境基础信息: . 单台Linux CentOS7.2系统,安装一个EMQTTD的实例broker. . emq的版本2.3.11. . ...
- jmeter问题
1.使用jmeter传入json参数报错 具体场景:使用python+request执行接口测试,正常:把python的参数直接复制,使用jmeter执行接口测试,提示json格式错误. {...,& ...
- kafka性能调优(转)
原文 https://blog.csdn.net/weixin_39478115/article/details/79155287 Broker参数配置 1.网络和io操作线程配置优化 # brok ...
- Linux运维宝典:最常用的150个命令汇总
一.线上查询及帮助命令(2个) 二.文件和目录操作命令(18个) 三.查看文件及内容处理命令(21个) 四.文件压缩及解压缩命令(4个) 五.信息显示命令(11个) 六.搜索文件命令(4个) 七.用户 ...