基于tornado的爬虫并发问题
tornado中的coroutine是python中真正意义上的协程,与python3中的asyncio几乎是完全一样的,而且两者之间的future是可以相互转换的,tornado中有与asyncio相兼容的接口。
下面是利用tornado中的coroutine进行并发抓取的代码:
HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Accept-Encoding': 'gzip, deflate',}
URLS = ['http://www.cnblogs.com/moodlxs/p/3248890.html',
'https://www.zhihu.com/topic/19804387/newest',
'http://blog.csdn.net/yueguanghaidao/article/details/24281751',
'https://my.oschina.net/visualgui823/blog/36987',
'http://blog.chinaunix.net/uid-9162199-id-4738168.html',
'http://www.tuicool.com/articles/u67Bz26',
'http://rfyiamcool.blog.51cto.com/1030776/1538367/',
'http://itindex.net/detail/26512-flask-tornado-gevent']
from tornado.gen import coroutine
from tornado.ioloop import IOLoop
from tornado.httpclient import AsyncHTTPClient, HTTPError
from tornado.httpclient import HTTPRequest #urls与前面相同
class MyClass(object): def __init__(self):
#AsyncHTTPClient.configure("tornado.curl_httpclient.CurlAsyncHTTPClient")
self.http = AsyncHTTPClient() @coroutine
def get(self, url):
#tornado会自动在请求首部带上host首部
request = HTTPRequest(url=url,
method='GET',
headers=HEADERS,
connect_timeout=2.0,
request_timeout=2.0,
follow_redirects=False,
max_redirects=False,
user_agent="Mozilla/5.0+(Windows+NT+6.2;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/45.0.2454.101+Safari/537.36",)
yield self.http.fetch(request, callback=self.find, raise_error=False) def find(self, response):
if response.error:
print(response.error)
print(response.code, response.effective_url, response.request_time) class Download(object): def __init__(self):
self.a = MyClass()
self.urls = URLS @coroutine
def d(self):
print(u'基于tornado的并发抓取')
t1 = time.time()
yield [self.a.get(url) for url in self.urls]
t = time.time() - t1
print(t) if __name__ == '__main__':
dd = Download()
loop = IOLoop.current()
loop.run_sync(dd.d)
利用coroutine编写并发略显复杂,但这是推荐的写法,如果你使用的是python3,强烈建议你使用coroutine来编写并发抓取。
下面是测试结果:
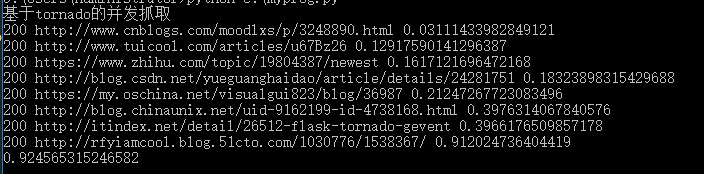
可以看到总共花费了0.92456秒,而这所花费的时间恰恰就是最后一个url抓取所需要的时间,tornado中自带了查看每个请求的相应时间。我们可以从图中看到,最后一个url抓取总共花了0.912秒,相较于其他时间大大的增加,这也是导致我们消耗时间过长的原因。那可以推断出,前面的并发抓取,也在这个url上花费了较多的时间。
转载:https://blog.csdn.net/hjhmpl123/article/details/53378068
基于tornado的爬虫并发问题的更多相关文章
- 基于tornado的文件上传demo
这里,web框架是tornado的4.0版本,文件上传组件,是用的bootstrap-fileinput. 这个小demo,是给合作伙伴提供的,模拟APP上摄像头拍照,上传给后台服务进行图像识别用,识 ...
- 基于golang分布式爬虫系统的架构体系v1.0
基于golang分布式爬虫系统的架构体系v1.0 一.什么是分布式系统 分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统.简单来说就是一群独立计算机 ...
- 基于RTKLIB构建高并发通信测试工具
1. RTKLIB基础动态库生成 RTKLIB是全球导航卫星系统GNSS(global navigation satellite system)的标准&精密定位开源程序包,由日本东京海洋大学的 ...
- 基于tornado实现web camera
基于tornado实现web camera 近期在学习python.找了一个框架学习,我选择的是tornado.由于其不仅仅是一个web开发框架,其还是一个server,异步事件库,一举多得. 我一直 ...
- 基于socket 实现单线程并发
基于socket 实现单线程并发: 基于协程实现内IO的快速切换,我们必须提前导入from gevent import monkey;monkey pacth_all() 以为 gevent spaw ...
- 【redis】基于redis实现分布式并发锁
基于redis实现分布式并发锁(注解实现) 说明 前提, 应用服务是分布式或多服务, 而这些"多"有共同的"redis"; (2017-12-04) 笑哭, 写 ...
- 1.tornado实现高并发爬虫
from pyquery import PyQuery as pq from tornado import ioloop, gen, httpclient, queues from urllib.pa ...
- tornado实现高并发爬虫
from pyquery import PyQuery as pq from tornado import ioloop, gen, httpclient, queues from urllib.pa ...
- AssassinGo: 基于Go的高并发可拓展式Web渗透框架
转载自FreeBuf.COM AssassinGo是一款使用Golang开发,集成了信息收集.基础攻击探测.Google-Hacking域名搜索和PoC批量检测等功能的Web渗透框架,并且有着基于Vu ...
随机推荐
- vCenter 5.1 U1 Installation: Part 9 (vCenter SSO Configuration)
http://www.derekseaman.com/2012/09/vmware-vcenter-51-installation-part-9.html In this installment of ...
- Volume Shadow Copy Service(VSS)如何工作
VSS卷影拷贝服务其实不是一项新技术了,在2003年前后发布的Windows 2003和Windows XP SP1都提供了对VSS的支持.最近几年微软的一线产品对VSS支持的越来越多,包括Excha ...
- Mybatis 自动生成代码,数据库postgresql
最近做了一个项目,使用Mybatis自动生成代码,下面做一下总结,被以后参考: 一.提前准备: 1.工具类:mybatis-generator-core-1.3.2.jar 2.postgresql驱 ...
- NGINX proxy_pass 域名解析问题
前两天发现一个问题,当使用proxy_pass的时候,发现域名对应IP是缓存的,这样一旦VIP变化之后,就会报错,下面就来详细分析一下这个问题. 一.问题说明 location = /test { i ...
- NGINX源代码自我总结(一)
查看源代码入门 这是一篇关于NGINX的MAIN()函数入门说明文章,相比其他这篇十分枯燥,其实写的时候更是无聊,不过学了这么长时间的WEB开发,连NGINX源代码都没有读下来,总是觉得有些缺憾,希望 ...
- http 请求报文
1.报文 2.http请求方法 restful接口 post:创建 put:更新
- css 禁止录入中文
1.情景展示 如何禁止输入框,输入中文字符? 2.解决方案 IE浏览器,可以使用ime-mode来实现 UpdateTime--2016年12月15日19:52:16 /*屏蔽输入法,可以用来禁止 ...
- phoneGap+jquery mobile项目经验
最近一个月,一直在用phoneGap+jquery mobile来开发一项目. 下面谈谈自己在开发过程中遇到的一些问题以及解决方法. 开始选择框架时,曾试过采用其他框架做UI,例如chocol ...
- yum安装提示错误Thread/process failed: Thread died in Berkeley DB library
问题描述: yum 安装更新提示 rpmdb: Thread/process failed: Thread died in Berkeley DB library 问题解决: 01.删除yum临时库文 ...
- Centos7 修改终端文字显示颜色
Centos7的配色方案主要是以下几个文件 -rw-r--r--. root root 11月 /etc/DIR_COLORS -rw-r--r--. root root 10月 : /etc/DIR ...