几种梯度下降方法对比(Batch gradient descent、Mini-batch gradient descent 和 stochastic gradient descent)
https://blog.csdn.net/u012328159/article/details/80252012
我们在训练神经网络模型时,最常用的就是梯度下降,这篇博客主要介绍下几种梯度下降的变种(mini-batch gradient descent和stochastic gradient descent),关于Batch gradient descent(批梯度下降,BGD)就不细说了(一次迭代训练所有样本),因为这个大家都很熟悉,通常接触梯队下降后用的都是这个。这里主要介绍Mini-batch gradient descent和stochastic gradient descent(SGD)以及对比下Batch gradient descent、mini-batch gradient descent和stochastic gradient descent的效果。
一、Batch gradient descent
Batch gradient descent 就是一次迭代训练所有样本,就这样不停的迭代。整个算法的框架可以表示为:
X = data_input
Y = labels
parameters = initialize_parameters(layers_dims)
for i in range(0, num_iterations): #num_iterations--迭代次数
# Forward propagation
a, caches = forward_propagation(X, parameters)
# Compute cost.
cost = compute_cost(a, Y)
# Backward propagation.
grads = backward_propagation(a, caches, parameters)
# Update parameters.
parameters = update_parameters(parameters, grads)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Batch gradient descent的优点是理想状态下经过足够多的迭代后可以达到全局最优。但是缺点也很明显,就是如果你的数据集非常的大(现在很常见),根本没法全部塞到内存(显存)里,所以BGD对于小样本还行,大数据集就没法娱乐了。而且因为每次迭代都要计算全部的样本,所以对于大数据量会非常的慢。
二、stochastic gradient descent
为了加快收敛速度,并且解决大数据量无法一次性塞入内存(显存)的问题,stochastic gradient descent(SGD)就被提出来了,SGD的思想是每次只训练一个样本去更新参数。具体的实现代码如下:
X = data_input
Y = labels
permutation = list(np.random.permutation(m))
shuffled_X = X[:, permutation]
shuffled_Y = Y[:, permutation].reshape((1, m))
for i in range(0, num_iterations):
for j in range(0, m): # 每次训练一个样本
# Forward propagation
AL,caches = forward_propagation(shuffled_X[:, j].reshape(-1,1), parameters)
# Compute cost
cost = compute_cost(AL, shuffled_Y[:, j].reshape(1,1))
# Backward propagation
grads = backward_propagation(AL, shuffled_Y[:,j].reshape(1,1), caches)
# Update parameters.
parameters = update_parameters(parameters, grads, learning_rate)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
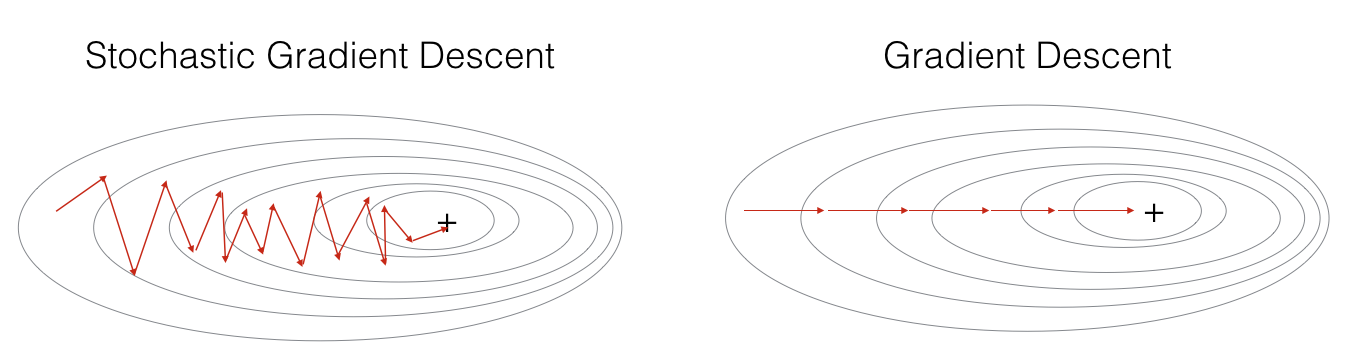
如果我们的数据集很大,比如几亿条数据,num_iterationsnum_iterations 基本上 设置1,2,(10以内的就足够了)就可以。但是SGD也有缺点,因为每次只用一个样本来更新参数,会导致不稳定性大些(可以看下图(图片来自ng deep learning 课),每次更新的方向,不想batch gradient descent那样每次都朝着最优点的方向逼近,会在最优点附近震荡)。因为每次训练的都是随机的一个样本,会导致导致梯度的方向不会像BGD那样朝着最优点。
注意:代码中的随机把数据打乱很重要,因为这个随机性相当于引入了“噪音”,正是因为这个噪音,使得SGD可能会避免陷入局部最优解中。
下面来对比下SGD和BGD的代价函数随着迭代次数的变化图:
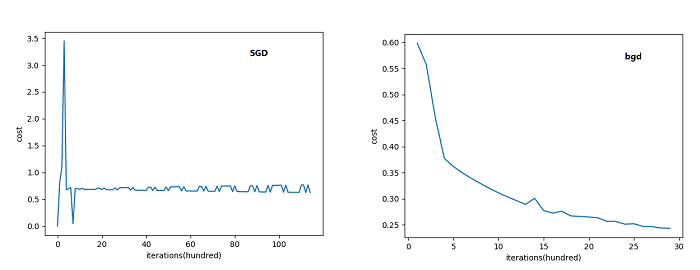
可以看到SGD的代价函数随着迭代次数是震荡式的下降的(因为每次用一个样本,有可能方向是背离最优点的)
三、Mini-batch gradient descent
mini-batch gradient descent 是batch gradient descent和stochastic gradient descent的折中方案,就是mini-batch gradient descent每次用一部分样本来更新参数,即 batch_sizebatch_size。因此,若batch_size=1batch_size=1 则变成了SGD,若batch_size=mbatch_size=m 则变成了batch gradient descent。batch_sizebatch_size通常设置为2的幂次方,通常设置2,4,8,16,32,64,128,256,5122,4,8,16,32,64,128,256,512(很少设置大于512)。因为设置成2的幂次方,更有利于GPU加速。现在深度学习中,基本上都是用 mini-batch gradient descent,(在深度学习中,很多直接把mini-batch gradient descent(a.k.a stochastic mini-batch gradient descent)简称为SGD,所以当你看到深度学习中的SGD,一般指的就是mini-batch gradient descent)。下面用几张图来展示下mini-batch gradient descent的原理(图片来自ng deep learning 课):
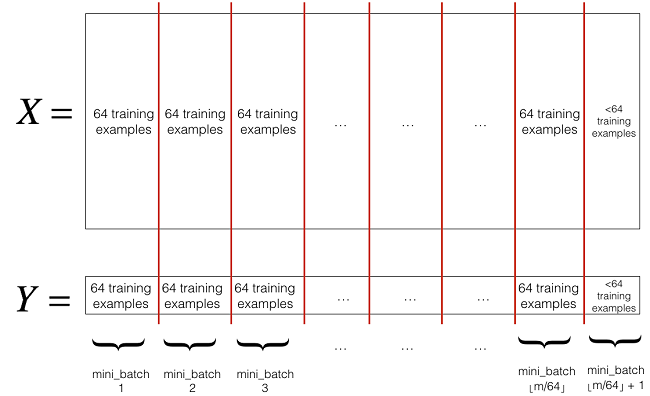
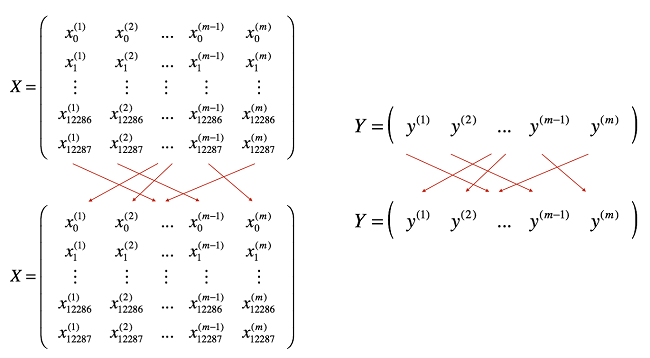
下面直接给出mini-batch gradient descent的代码实现:
1.首先要把训练集分成多个batch
# GRADED FUNCTION: random_mini_batches
def random_mini_batches(X, Y, mini_batch_size = 64, seed = 0):
"""
Creates a list of random minibatches from (X, Y)
Arguments:
X -- input data, of shape (input size, number of examples)
Y -- true "label" vector (1 for blue dot / 0 for red dot), of shape (1, number of examples)
mini_batch_size -- size of the mini-batches, integer
Returns:
mini_batches -- list of synchronous (mini_batch_X, mini_batch_Y)
"""
np.random.seed(seed) # To make your "random" minibatches the same as ours
m = X.shape[1] # number of training examples
mini_batches = []
# Step 1: Shuffle (X, Y)
permutation = list(np.random.permutation(m))
shuffled_X = X[:, permutation]
shuffled_Y = Y[:, permutation].reshape((1,m))
# Step 2: Partition (shuffled_X, shuffled_Y). Minus the end case.
num_complete_minibatches = m//mini_batch_size # number of mini batches
for k in range(0, num_complete_minibatches):
mini_batch_X = shuffled_X[:, k * mini_batch_size: (k + 1) * mini_batch_size]
mini_batch_Y = shuffled_Y[:, k * mini_batch_size: (k + 1) * mini_batch_size]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
# Handling the end case (last mini-batch < mini_batch_size)
if m % mini_batch_size != 0:
mini_batch_X = shuffled_X[:, num_complete_minibatches * mini_batch_size : m]
mini_batch_Y = shuffled_Y[:, num_complete_minibatches * mini_batch_size : m]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
return mini_batches- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
2.下面是在model中使用mini-batch gradient descent 进行更新参数
seed = 0
for i in range(0, num_iterations):
# Define the random minibatches. We increment the seed to reshuffle differently the dataset after each epoch
seed = seed + 1
minibatches = random_mini_batches(X, Y, mini_batch_size, seed)
for minibatch in minibatches:
# Select a minibatch
(minibatch_X, minibatch_Y) = minibatch
# Forward propagation
AL, caches = forward_propagation(minibatch_X, parameters)
# Compute cost
cost = compute_cost(AL, minibatch_Y)
# Backward propagation
grads = backward_propagation(AL, minibatch_Y, caches)
parameters = update_parameters(parameters, grads, learning_rate)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
下面来看mini-batch gradient descent 和 stochastic gradient descent 在下降时的对比图:
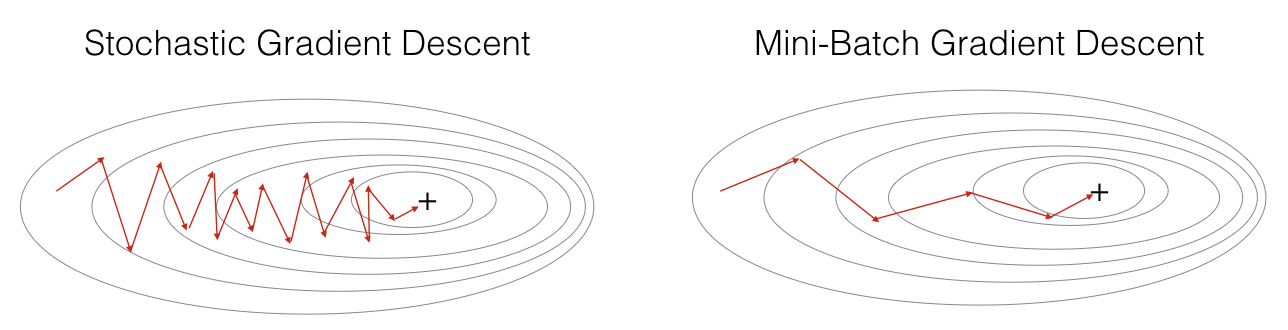
下面是mini-batch gradient descent的代价函数随着迭代次数的变化图:
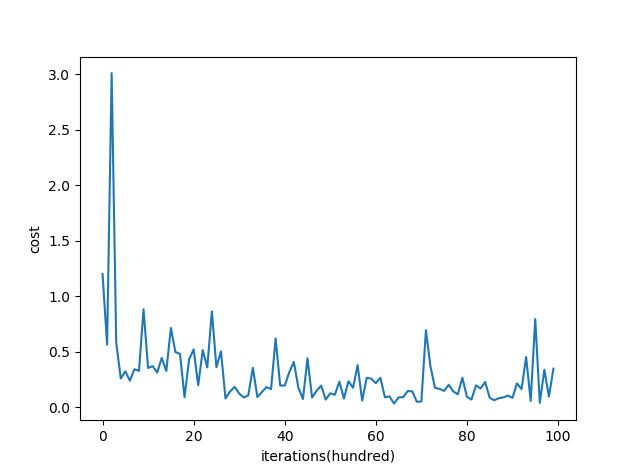
从图中能够看出,mini-batch gradient descent 相对SGD在下降的时候,相对平滑些(相对稳定),不像SGD那样震荡的比较厉害。mini-batch gradient descent的一个缺点是增加了一个超参数 batch_sizebatch_size ,要去调这个超参数。
以上就是关于batch gradient descent、mini-batch gradient descent 和 stochastic gradient descent的内容。
完整的代码放到github上了:deep_neural_network_with_gd.py
几种梯度下降方法对比(Batch gradient descent、Mini-batch gradient descent 和 stochastic gradient descent)的更多相关文章
- [LNU.Machine Learning.Question.1]梯度下降方法的一些理解
曾经学习machine learning,在regression这一节,对求解最优化问题的梯度下降方法,理解总是处于字面意义上的生吞活剥. 对梯度的概念感觉费解?到底是标量还是矢量?为什么沿着负梯度方 ...
- iPhone开发 数据持久化总结(终结篇)—5种数据持久化方法对比
iPhone开发 数据持久化总结(终结篇)—5种数据持久化方法对比 iphoneiPhoneIPhoneIPHONEIphone数据持久化 对比总结 本篇对IOS中常用的5种数据持久化方法进行简单 ...
- 三种梯度下降法的对比(BGD & SGD & MBGD)
常用的梯度下降法分为: 批量梯度下降法(Batch Gradient Descent) 随机梯度下降法(Stochastic Gradient Descent) 小批量梯度下降法(Mini-Batch ...
- 梯度下降(Gradient Descent)小结 -2017.7.20
在求解算法的模型函数时,常用到梯度下降(Gradient Descent)和最小二乘法,下面讨论梯度下降的线性模型(linear model). 1.问题引入 给定一组训练集合(training se ...
- [Python]数据挖掘(1)、梯度下降求解逻辑回归——考核成绩分类
ps:本博客内容根据唐宇迪的的机器学习经典算法 学习视频复制总结而来 http://www.abcplus.com.cn/course/83/tasks 逻辑回归 问题描述:我们将建立一个逻辑回归模 ...
- Stanford大学机器学习公开课(二):监督学习应用与梯度下降
本课内容: 1.线性回归 2.梯度下降 3.正规方程组 监督学习:告诉算法每个样本的正确答案,学习后的算法对新的输入也能输入正确的答案 1.线性回归 问题引入:假设有一房屋销售的数据如下: 引 ...
- ML(附录1)——梯度下降
梯度下降是迭代法的一种,可以用于求解最小二乘问题(线性和非线性都可以).在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的 ...
- 改善深层神经网络_优化算法_mini-batch梯度下降、指数加权平均、动量梯度下降、RMSprop、Adam优化、学习率衰减
1.mini-batch梯度下降 在前面学习向量化时,知道了可以将训练样本横向堆叠,形成一个输入矩阵和对应的输出矩阵: 当数据量不是太大时,这样做当然会充分利用向量化的优点,一次训练中就可以将所有训练 ...
- batch gradient descent(批量梯度下降) 和 stochastic gradient descent(随机梯度下降)
批量梯度下降是一种对参数的update进行累积,然后批量更新的一种方式.用于在已知整个训练集时的一种训练方式,但对于大规模数据并不合适. 随机梯度下降是一种对参数随着样本训练,一个一个的及时updat ...
随机推荐
- Codeforces Round #396 (Div. 2) D. Mahmoud and a Dictionary 并查集
D. Mahmoud and a Dictionary 题目连接: http://codeforces.com/contest/766/problem/D Description Mahmoud wa ...
- CAP原则(CAP定理)、BASE理论
CAP原则又称CAP定理,指的是在一个分布式系统中, Consistency(一致性). Availability(可用性).Partition tolerance(分区容错性),三者不可得兼. CA ...
- [原创]App性能测试指标篇
[原创]App性能测试指标篇 目前由于苹果,三星等大厂对智能手机的研发及投入,使的智能手机发展非常迅速,每个人手中都有一些离不开生活的App,如:微信,微博,百度或是各游戏App等,但是到底App性能 ...
- .net core中的System.Buffers名字空间
最近研究了一下.net core 2.1的基础类库,发现它引入了一个System.Buffers名字空间,里面提供了一系列比较实用的对象,便简单的管中窥豹浏览一下. ArrayPool<T> ...
- 关于MongoDB时区问题
由于MongoDb存储时间按照UTC时间存储的,其官方驱动MongoDB.driver存储时间的时候将本地时间转换为了utc时间,但它有个蛋疼的bug,读取的时候非常蛋疼的是返回的是utc使时间.一个 ...
- PHP 依赖注入(DI) 和 控制反转(IoC)
要想理解 PHP 依赖注入 和 控制反转 两个概念,就必须搞清楚如下的两个问题: DI —— Dependency Injection 依赖注入 IoC —— Inversion of Control ...
- 在触屏设备上面利用html5裁剪图片
前言 如今触屏设备越来越流行,并且大多数已经支持html5了.针对此.对触屏设备开发图片裁剪功能, 让其能够直接处理图片.减轻服务端压力. 技术点 浏览器必须支持html5,包含fileReader. ...
- WCF中修改接口或方法名称而不影响客户端程序
本篇接着"从Web Service和Remoting Service引出WCF服务"中有关WCF的部分. 运行宿主应用程序. 运行Web客户端中的网页. 输入内容,点击按钮,能获取 ...
- sql 注释 语法
mysql 服务器支持 # 到该行结束.-- 到该行结束 以及 /* 行中间或多个行 */ 的注释方格: mysql> SELECT 1+1; # 这个注释直到该行结束mysql> SEL ...
- arcgis10.5.1 对齐要素
许可级别:BasicStandardAdvanced 摘要 标识地理处理工具用于标识搜索距离中输入要素与目标要素的不一致部分并使其与目标要素一致. 插图 用法 警告: 此工具用于修改输入数据.有关详细 ...