Django框架----数据库表的单表查询
一、添加表记录
对于单表有两种方式
# 添加数据的两种方式
# 方式一:实例化对象就是一条表记录
Frank_obj = models.Student(name ="海东",course="python",birth="2000-9-9",fenshu=80)
Frank_obj.save()
# 方式二:
models.Student.objects.create(name ="海燕",course="python",birth="1995-5-9",fenshu=88)
二、查询表记录
查询相关API
# 查询相关API
# 1、all():查看所有
student_obj = models.Student.objects.all()
print(student_obj) #打印的结果是QuerySet集合
# 2、filter():可以实现且关系,但是或关系需要借助Q查询实现。。。
# 查不到的时候不会报错
print(models.Student.objects.filter(name="Frank")) #查看名字是Frank的
print(models.Student.objects.filter(name="Frank",fenshu=80)) #查看名字是Frank的并且分数是80的
# 3、get():如果找不到就会报错,如果有多个值,也会报错,只能拿有一个值的
print(models.Student.objects.get(name="Frank")) #拿到的是model对象
print(models.Student.objects.get(nid=2)) #拿到的是model对象
# 4、exclude():排除条件
print( models.Student.objects.exclude(name="海东")) #查看除了名字是海东的信息
# 5、values():是QuerySet的一个方法 (吧对象转换成字典的形式了,)
print(models.Student.objects.filter(name="海东").values("nid","course")) #查看名字为海东的编号和课程
#打印结果:<QuerySet [{'nid': 2, 'course': 'python'}, {'nid': 24, 'course': 'python'}]>
# 6、values_list():是queryset的一个方法 (吧对象转成元组的形式了)
print(models.Student.objects.filter(name="海东").values_list("nid", "course"))
#打印结果:< QuerySet[(2, 'python'), (24, 'python')] >
# 7、order_by():排序
print(models.Student.objects.all().order_by("fenshu"))
# 8、reverse():倒序
print(models.Student.objects.all().reverse())
# 9、distinct():去重(只要结果里面有重复的)
print(models.Student.objects.filter(course="python").values("fenshu").distinct())
# 10、count():查看有几条记录
print(models.Student.objects.filter(name="海东").count()) # 11、first()
# 12、last()
return render(request,"test.html",{"student_obj":student_obj})
# 13、esits:查看有没有记录,如果有返回True,没有返回False
# 并不需要判断所有的数据,
# if models.Book.objects.all().exists():
双下划线之单表查询
models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id小于1 且 大于10的值 models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据
models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in models.Tb1.objects.filter(name__contains="ven") #包括ven的
models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感 models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and startswith,istartswith, endswith, iendswith
对象可以调用自己的属性,用一个点就可以
还可以通过双下划线。。。
models.Book.objects.filter(price__gt=100) 价格大于100的书
models.Book.objects.filter(author__startwith= "张") 查看作者的名字是以张开头的
主键大于5的且小于2
price__gte=99大于等于
publishDate__year =2017,publishDate__month = 10 查看2017年10月份的数据
三、修改表记录
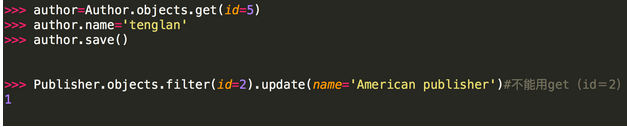
注意:
<1> 第二种方式修改不能用get的原因是:update是QuerySet对象的方法,get返回的是一个model对象,它没有update方法,而filter返回的是一个QuerySet对象(filter里面的条件可能有多个条件符合,比如name='alvin',可能有两个name='alvin'的行数据)。
<2>在“插入和更新数据”小节中,我们有提到模型的save()方法,这个方法会更新一行里的所有列。 而某些情况下,我们只需要更新行里的某几列。
此外,update()方法对于任何结果集(QuerySet)均有效,这意味着你可以同时更新多条记录update()方法会返回一个整型数值,表示受影响的记录条数。
注意,这里因为update返回的是一个整形,所以没法用query属性;对于每次创建一个对象,想显示对应的raw sql,需要在settings加上日志记录部分
四、删除表记录
删除方法就是 delete()。它运行时立即删除对象而不返回任何值。例如:e.delete()
def delstudent(request,id):
# 删除数据
models.Student.objects.filter(nid=id).delete()
return redirect("/test/")
你也可以一次性删除多个对象。每个 QuerySet 都有一个 delete() 方法,它一次性删除 QuerySet 中所有的对象。
例如,下面的代码将删除 pub_date 是2005年的 Entry 对象:
Entry.objects.filter(pub_date__year=2005).delete()
要牢记这一点:无论在什么情况下,QuerySet 中的 delete() 方法都只使用一条 SQL 语句一次性删除所有对象,而并不是分别删除每个对象。如果你想使用在 model 中自定义的 delete() 方法,就要自行调用每个对象的delete 方法。(例如,遍历 QuerySet,在每个对象上调用 delete()方法),而不是使用 QuerySet 中的 delete()方法。
在 Django 删除对象时,会模仿 SQL 约束 ON DELETE CASCADE 的行为,换句话说,删除一个对象时也会删除与它相关联的外键对象。例如:
b = Blog.objects.get(pk=1)
# This will delete the Blog and all of its Entry objects.
b.delete()
要注意的是: delete() 方法是 QuerySet 上的方法,但并不适用于 Manager 本身。这是一种保护机制,是为了避免意外地调用 Entry.objects.delete() 方法导致 所有的 记录被误删除。如果你确认要删除所有的对象,那么你必须显式地调用:
Entry.objects.all().delete()
五、编辑表格中的内容的涉及到的语法
编辑操作涉及到的语法 分析:
1、点击编辑,让跳转到另一个页面,拿到我点击的那一行
两种取id值的方式
方式一:
利用数据传参数(作为数据参数传过去了)
<a href="/edit/?book_id = {{book_obj.nid}}"></a> #相当于发了一个键值对
url里面就不用写匹配的路径了,
id = request.GET.get("book_id") #取值 方式二:
利用路径传参,得在url里面加上(\d+),就得给函数传个参数,无名分组从参数里面取值
<a href="/{{book_obj.nid}}"></a> 2、拿到id,然后在做筛选
id = request.GET.get("book_id")
book_obj = models.Book.objects.filter(nid=id) #拿到的是一个列表对象
注意:
1.取[0]就拿到对象了,,然后对象.属性就可以取到值了
2.用get,你取出来的数据必须只有一条的时候,,如果有多条用get就会报错,,,但是用get就不用加[0]了
book_obj = models.Book.objects.filter(nid=id)[0] 3、当点击编辑的时候怎么让input框里显示文本内容
value = "{{book_obj.title}}"
4、改完数据后重新提交
当提交的时候走action...../edit/}
隐藏一个input,
<input type="hidden" name = "book_id" value="{{book_obj.nid}}">
判断post的时候:
修改数据
方式一:save(这种方式效率是非常低的,不推荐使用,了解就行了)
修改的前提是先取(拿到要编辑的id值)
id = request.POST.get("book_id")
bk_obj = models.Book.objects.filter(nid=id)[0]
bk_obj.title = "hhhhhh" #这是写死了,不能都像这样写死了
bk_obj.save() 只要是用对象的这种都要.save
方式二:update
title = request.POST.get("title")
models.Book.objects.filter(nid=id).update(title=title,......)
跳转到index 如果是post请求的时候怎么找到id呢,
一、如果是数据传参:(也就是get请求的时候)
可以通过一个隐藏的input框,给这个框给一个name属性,value属性。通过request.POST.get("键"),,就可以得到id的值
二、如果是路径传参
可以通过传参的形式,当正则表达式写一个(\d+)的时候,就给函数传一个id,可通过这个id知道id.
六、进阶操作
# 获取个数
#
# models.Tb1.objects.filter(name='seven').count() # 大于,小于
#
# models.Tb1.objects.filter(id__gt=1) # 获取id大于1的值
# models.Tb1.objects.filter(id__gte=1) # 获取id大于等于1的值
# models.Tb1.objects.filter(id__lt=10) # 获取id小于10的值
# models.Tb1.objects.filter(id__lte=10) # 获取id小于10的值
# models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值 # in
#
# models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据
# models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in # isnull
# Entry.objects.filter(pub_date__isnull=True) # contains
#
# models.Tb1.objects.filter(name__contains="ven")
# models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感
# models.Tb1.objects.exclude(name__icontains="ven") # range
#
# models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and # 其他类似
#
# startswith,istartswith, endswith, iendswith, # order by
#
# models.Tb1.objects.filter(name='seven').order_by('id') # asc
# models.Tb1.objects.filter(name='seven').order_by('-id') # desc # group by
#
# from django.db.models import Count, Min, Max, Sum
# models.Tb1.objects.filter(c1=1).values('id').annotate(c=Count('num'))
# SELECT "app01_tb1"."id", COUNT("app01_tb1"."num") AS "c" FROM "app01_tb1" WHERE "app01_tb1"."c1" = 1 GROUP BY "app01_tb1"."id" # limit 、offset
#
# models.Tb1.objects.all()[10:20] # regex正则匹配,iregex 不区分大小写
#
# Entry.objects.get(title__regex=r'^(An?|The) +')
# Entry.objects.get(title__iregex=r'^(an?|the) +') # date
#
# Entry.objects.filter(pub_date__date=datetime.date(2005, 1, 1))
# Entry.objects.filter(pub_date__date__gt=datetime.date(2005, 1, 1)) # year
#
# Entry.objects.filter(pub_date__year=2005)
# Entry.objects.filter(pub_date__year__gte=2005) # month
#
# Entry.objects.filter(pub_date__month=12)
# Entry.objects.filter(pub_date__month__gte=6) # day
#
# Entry.objects.filter(pub_date__day=3)
# Entry.objects.filter(pub_date__day__gte=3) # week_day
#
# Entry.objects.filter(pub_date__week_day=2)
# Entry.objects.filter(pub_date__week_day__gte=2) # hour
#
# Event.objects.filter(timestamp__hour=23)
# Event.objects.filter(time__hour=5)
# Event.objects.filter(timestamp__hour__gte=12) # minute
#
# Event.objects.filter(timestamp__minute=29)
# Event.objects.filter(time__minute=46)
# Event.objects.filter(timestamp__minute__gte=29) # second
#
# Event.objects.filter(timestamp__second=31)
# Event.objects.filter(time__second=2)
# Event.objects.filter(timestamp__second__gte=31)
进阶操作
七、高级操作
# extra
# 在QuerySet的基础上继续执行子语句
# extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None) # select和select_params是一组,where和params是一组,tables用来设置from哪个表
# Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,))
# Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
# Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"])
# Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid']) 举个例子:
models.UserInfo.objects.extra(
select={'newid':'select count(1) from app01_usertype where id>%s'},
select_params=[1,],
where = ['age>%s'],
params=[18,],
order_by=['-age'],
tables=['app01_usertype']
)
"""
select
app01_userinfo.id,
(select count(1) from app01_usertype where id>1) as newid
from app01_userinfo,app01_usertype
where
app01_userinfo.age > 18
order by
app01_userinfo.age desc
""" # 执行原生SQL
# 更高灵活度的方式执行原生SQL语句
# from django.db import connection, connections
# cursor = connection.cursor() # cursor = connections['default'].cursor()
# cursor.execute("""SELECT * from auth_user where id = %s""", [1])
# row = cursor.fetchone()
高级操作
八、QuerySet相关方法
##################################################################
# PUBLIC METHODS THAT ALTER ATTRIBUTES AND RETURN A NEW QUERYSET #
################################################################## def all(self)
# 获取所有的数据对象 def filter(self, *args, **kwargs)
# 条件查询
# 条件可以是:参数,字典,Q def exclude(self, *args, **kwargs)
# 条件查询
# 条件可以是:参数,字典,Q def select_related(self, *fields)
性能相关:表之间进行join连表操作,一次性获取关联的数据。 总结:
1. select_related主要针一对一和多对一关系进行优化。
2. select_related使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化、提高性能。 def prefetch_related(self, *lookups)
性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。 总结:
1. 对于多对多字段(ManyToManyField)和一对多字段,可以使用prefetch_related()来进行优化。
2. prefetch_related()的优化方式是分别查询每个表,然后用Python处理他们之间的关系。 def annotate(self, *args, **kwargs)
# 用于实现聚合group by查询 from django.db.models import Count, Avg, Max, Min, Sum v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id'))
# SELECT u_id, COUNT(ui) AS `uid` FROM UserInfo GROUP BY u_id v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id')).filter(uid__gt=1)
# SELECT u_id, COUNT(ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1 v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id',distinct=True)).filter(uid__gt=1)
# SELECT u_id, COUNT( DISTINCT ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1 def distinct(self, *field_names)
# 用于distinct去重
models.UserInfo.objects.values('nid').distinct()
# select distinct nid from userinfo 注:只有在PostgreSQL中才能使用distinct进行去重 def order_by(self, *field_names)
# 用于排序
models.UserInfo.objects.all().order_by('-id','age') def extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
# 构造额外的查询条件或者映射,如:子查询 Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,))
Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"])
Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid']) def reverse(self):
# 倒序
models.UserInfo.objects.all().order_by('-nid').reverse()
# 注:如果存在order_by,reverse则是倒序,如果多个排序则一一倒序 def defer(self, *fields):
models.UserInfo.objects.defer('username','id')
或
models.UserInfo.objects.filter(...).defer('username','id')
#映射中排除某列数据 def only(self, *fields):
#仅取某个表中的数据
models.UserInfo.objects.only('username','id')
或
models.UserInfo.objects.filter(...).only('username','id') def using(self, alias):
指定使用的数据库,参数为别名(setting中的设置) ##################################################
# PUBLIC METHODS THAT RETURN A QUERYSET SUBCLASS #
################################################## def raw(self, raw_query, params=None, translations=None, using=None):
# 执行原生SQL
models.UserInfo.objects.raw('select * from userinfo') # 如果SQL是其他表时,必须将名字设置为当前UserInfo对象的主键列名
models.UserInfo.objects.raw('select id as nid from 其他表') # 为原生SQL设置参数
models.UserInfo.objects.raw('select id as nid from userinfo where nid>%s', params=[12,]) # 将获取的到列名转换为指定列名
name_map = {'first': 'first_name', 'last': 'last_name', 'bd': 'birth_date', 'pk': 'id'}
Person.objects.raw('SELECT * FROM some_other_table', translations=name_map) # 指定数据库
models.UserInfo.objects.raw('select * from userinfo', using="default") ################### 原生SQL ###################
from django.db import connection, connections
cursor = connection.cursor() # cursor = connections['default'].cursor()
cursor.execute("""SELECT * from auth_user where id = %s""", [1])
row = cursor.fetchone() # fetchall()/fetchmany(..) def values(self, *fields):
# 获取每行数据为字典格式 def values_list(self, *fields, **kwargs):
# 获取每行数据为元祖 def dates(self, field_name, kind, order='ASC'):
# 根据时间进行某一部分进行去重查找并截取指定内容
# kind只能是:"year"(年), "month"(年-月), "day"(年-月-日)
# order只能是:"ASC" "DESC"
# 并获取转换后的时间
- year : 年-01-01
- month: 年-月-01
- day : 年-月-日 models.DatePlus.objects.dates('ctime','day','DESC') def datetimes(self, field_name, kind, order='ASC', tzinfo=None):
# 根据时间进行某一部分进行去重查找并截取指定内容,将时间转换为指定时区时间
# kind只能是 "year", "month", "day", "hour", "minute", "second"
# order只能是:"ASC" "DESC"
# tzinfo时区对象
models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.UTC)
models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.timezone('Asia/Shanghai')) """
pip3 install pytz
import pytz
pytz.all_timezones
pytz.timezone(‘Asia/Shanghai’)
""" def none(self):
# 空QuerySet对象 ####################################
# METHODS THAT DO DATABASE QUERIES #
#################################### def aggregate(self, *args, **kwargs):
# 聚合函数,获取字典类型聚合结果
from django.db.models import Count, Avg, Max, Min, Sum
result = models.UserInfo.objects.aggregate(k=Count('u_id', distinct=True), n=Count('nid'))
===> {'k': 3, 'n': 4} def count(self):
# 获取个数 def get(self, *args, **kwargs):
# 获取单个对象 def create(self, **kwargs):
# 创建对象 def bulk_create(self, objs, batch_size=None):
# 批量插入
# batch_size表示一次插入的个数
objs = [
models.DDD(name='r11'),
models.DDD(name='r22')
]
models.DDD.objects.bulk_create(objs, 10) def get_or_create(self, defaults=None, **kwargs):
# 如果存在,则获取,否则,创建
# defaults 指定创建时,其他字段的值
obj, created = models.UserInfo.objects.get_or_create(username='root1', defaults={'email': '','u_id': 2, 't_id': 2}) def update_or_create(self, defaults=None, **kwargs):
# 如果存在,则更新,否则,创建
# defaults 指定创建时或更新时的其他字段
obj, created = models.UserInfo.objects.update_or_create(username='root1', defaults={'email': '','u_id': 2, 't_id': 1}) def first(self):
# 获取第一个 def last(self):
# 获取最后一个 def in_bulk(self, id_list=None):
# 根据主键ID进行查找
id_list = [11,21,31]
models.DDD.objects.in_bulk(id_list) def delete(self):
# 删除 def update(self, **kwargs):
# 更新 def exists(self):
# 是否有结果 其他操作
QuerySet方法大全
Django框架----数据库表的单表查询的更多相关文章
- Django框架(八)--单表增删改查,在Python脚本中调用Django环境
一.数据库连接配置 如果连接的是pycharm默认的Sqlite,不用改动,使用默认配置即可 如果连接mysql,需要在配置文件中的setting中进行配置: 将DATABASES={} 更新为 DA ...
- Django框架(九)—— 单表增删改查,在Python脚本中调用Django环境
目录 单表增删改查,在Python脚本中调用Django环境 一.数据库连接配置 二.orm创建表和字段 三.单表增删改查 1.增加数据 2.删除数据 3.修改数据 4.查询数据 四.在Python脚 ...
- MSSQL·备份数据库中的单表
阅文时长 | 0.11分钟 字数统计 | 237.6字符 主要内容 | 1.引言&背景 2.声明与参考资料 『MSSQL·备份数据库中的单表』 编写人 | SCscHero 编写时间 | 20 ...
- ActiveRecord-连接多张表之单表继承
ActiveRecord-连接多张表之单表继承 1. 基本概念 Rails提供了两种机制,可以将复杂的面向对象模型映射为关系模型,即所谓的单表继承(single-table inheritance)和 ...
- django之数据库表的单表查询
一.添加表记录 对于单表有两种方式 # 添加数据的两种方式 # 方式一:实例化对象就是一条表记录 Frank_obj = models.Student(name ="海东",cou ...
- django(七)之数据库表的单表-增删改查QuerySet,双下划线
https://www.cnblogs.com/haiyan123/p/7738435.html https://www.cnblogs.com/yuanchenqi/articles/6083427 ...
- Django学习笔记--数据库中的单表操作----增删改查
1.Django数据库中的增删改查 1.添加表和字段 # 创建的表的名字为app的名称拼接类名 class User(models.Model): # id字段 自增 是主键 id = models. ...
- python实现简易数据库之二——单表查询和top N实现
上一篇中,介绍了我们的存储和索引建立过程,这篇将介绍SQL查询.单表查询和TOPN实现. 一.SQL解析 正规的sql解析是用语法分析器,但是我找了好久,只知道可以用YACC.BISON等,sqlit ...
- 数据库——SQL数据单表查询
数据查询 语句格式 SELECT [ALL|DISTINCT] <目标列表达式> [,<目标列表达式>] … FROM <表或视图名>[,<表或视图名&g ...
随机推荐
- Equinox P2 介绍(一)Getting Start
一直觉得 Equinox 的 P2 是个神秘的东西,常常使得 Eclipse 或 Equinox 表现出一些奇怪的行为,于是找来官方文档读一读,试图更好地理解与应用 Equinox . 官方文档很多, ...
- 分布式存储中HDFS与Ceph两者的区别是什么,各有什么优势?
过去两年,我的主要工作都在Hadoop这个技术栈中,而最近有幸接触到了Ceph.我觉得这是一件很幸运的事,让我有机会体验另一种大型分布式存储解决方案,可以对比出HDFS与Ceph这两种几乎完全不同的存 ...
- JPA的锁机制
JPA 各种实体锁模式的区别 字数2084 阅读304 评论0 喜欢4 为了能够同步访问实体,JPA提供了2种锁机制.这两种机制都可以避免两个事务中的其中一个,在不知情的情况下覆盖另一个事务的数据. ...
- 推荐两个国外网站-帮你优化网站SEO和预测下期的PR值
第一个:http://www.domaintools.com/ (谷歌SEO网站优化伴侣)可以测试你优化网站的分数. 这里使用说明,简单说一下吧: 打开网站后输入自己的域名,点击搜索按钮 第二个查看分 ...
- 你可能用得到的9段CSS代码
一.opacity兼容 .transparent { filter: alpha(opacity=50);/* internet explorer */ -khtml-opacity: 0 ...
- javaScript高级教程(八)-----正则表达式温故知新
1.RegExp对象:五个属性二个方法 五个属性:global, ignoreCase,multiline,lastIndex,source 二个方法: exec()--模式匹配 test()--检测 ...
- 非极大值抑制(NMS)
非极大值抑制顾名思义就是抑制不是极大值的元素,搜索局部的极大值.这个局部代表的是一个邻域,邻域有两个参数可变,一个是邻域的维数,二是邻域的大小.这里不讨论通用的NMS算法,而是用于在目标检测中提取分数 ...
- redis连接池的标准用法:
from .conf import HOST, PORT, POOL_NAME import redis redis_pool = redis.ConnectionPool(host=HOST, po ...
- idong常用js总结
1.判断屏幕高度 $(document).ready(function() { $("#left").height($(window).height()); $(&qu ...
- 003-spring cloud gateway-概述、Route模型、网关初始化配置过程、基本原理
一.概述 网关服务核心是将进入的请求正确合理的路由到下层具体的服务进行业务处理,由此可见网关服务的核心就是路由信息的构建. Spring Cloud Gateway旨在提供一种简单而有效的方式来路由到 ...