深蓝色 --ppt
Deep Learning of Binary Hash Codes for Fast Image Retrieval
1. 摘要
- 针对图像检索问题,提出简单有效的监督学习框架
- CNN网络结构能同时学习图像特征表示以及 hash-like 编码函数集合
- 利用深度学习以逐点(point-wise)的方式,得到二值哈希编码(binary hash codes),以快速检索图像;对比卷积pair-wised方法,在数据大小上具好的扩展性.
- 论文思想,当数据标签可用时,可以利用隐层来学习能够表示图像类别标签的潜在语义的二值编码
2. 方法
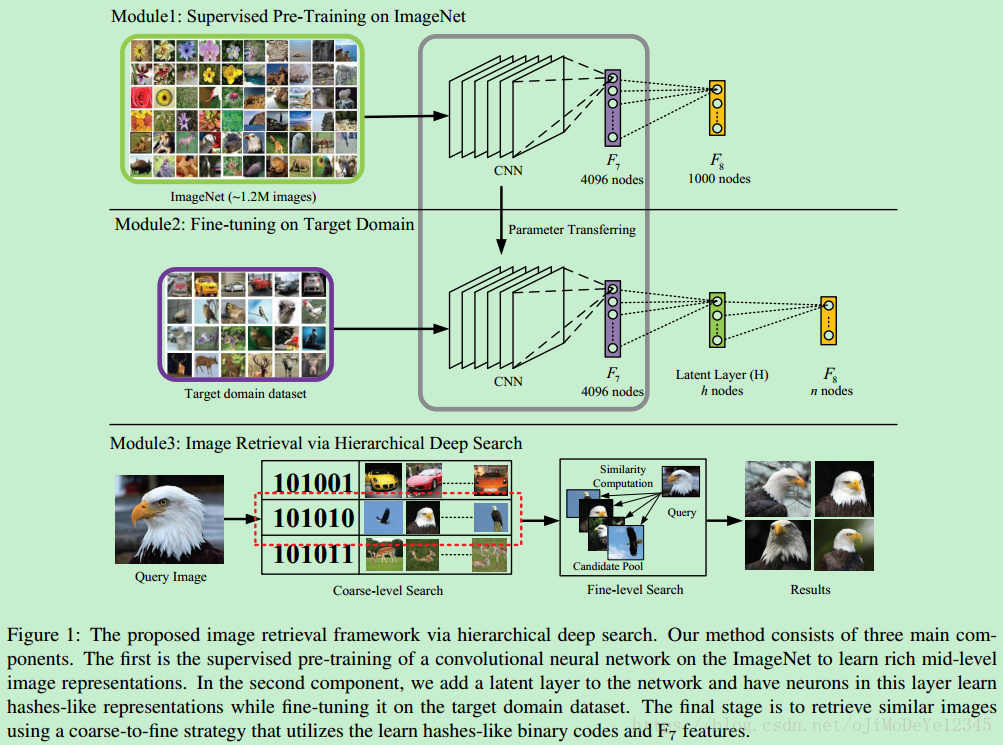
Figure 1: 基于分层深度搜索的图像检索框架.
方法主要包括三部分:
- Module1 - 在ImageNet上有监督地预训练CNN网络,以学习得到丰富的mid-level图像表示特征;
- Module2 - 添加隐层(latent) 网络层,通过在目标图像数据集finetuning网络,该隐层可以学习得到图像的 hashes-like 编码表示;
- Module3 - 利用 hashes-like 二值编码和 F7 层特征,采用 coarse粗-to-fine 策略检索相似图片.
2.1 Hash-like 二值编码学习
假设网络的最终输出分类层 F8 依赖于 h 个hidden attributes,各属性是 0 或 1(0表示不存在,1表示存在).
如果图像的二值激活编码相似,其应该具有相同标签.
如Figure 1所示,这里在 F7 和 F8 层间嵌入一个隐层 H.
- 该隐层H 是一个全连接层,其 层来控制,F8层编码了图像语义并用于最终分类.
- 层丰富特征的抽象表示,还联系着 mid-level 特征和 high-level 语义.
- 该隐层H采用的是Sigmoid函数,以使激活值在 {0, 1} 之间.
为了适应数据集,在目标数据集 fine-tune CNN网络.
- 初始权重设为ImageNet数据集预训练的CNN权重;
- 隐层H和最终分类层8F8的权重采用随机初始化.
无需对深度CNN模型修改太多,即可同时学习得到图像的视觉特征描述子,和 hashing-like 函数,以进行有效的图像检索.
2.2 基于分层深度搜索的图像检索
采用 coarse-to-fine 搜索策略进行快速精确的图像检索.
- 首先,检索得到相似 high-level 语义特征的候选图片集,即,具有隐层得到隐含二值激活值相似;
- 然后,进一步过滤具有相似外表的图片,主要是基于最深的 mid-level 图像特征表示进行相似性排名.
2.2.1 Coarse-level 搜索
给定图像 I, 首先提取隐层输出作为图像特征,记为Out(H).
通过设定阈值,即可以得到其二值编码.
即,对于二值激活的每一个字节j=1,2,...,h(h为隐层的节点数), H的输出二值编码:
Hj=1,if Outj(H)≥0.5;otherwise Hj=0
记 Γ=I1,I2,...,In表示用于检索的 n张图片组成数据集,其每张图片对应的二值编码记为ΓH=H1,H2,...,Hn , 其中 Hi∈{0,1}
给定待查询图片 Iq 及其二值编码 Hq, 如果 Hq 和 Hi∈ΓH的Hamming 距离小于阈值,得到一个有 m 张候选图片的图片池,P={Ic1,Ic2,...,Icm}
2.2.2 Fine-level 检索
给定待查询图片 Iq 及候选图片池 P={Ic1,Ic2,...,Icm},采用 F7 层提取的图片特征来从候选图片池 P 中确认前 k 张图片.
记 Vq 和 VPi 分别表示待查询图片 q 和图片池中候选图片 Ici的特征向量 (矩阵),则其欧氏距离相似性计算为:
si=||Vq−VPi||
如果欧氏距离越大,则两张图片的相似性越强. 通过对候选图片进行排序,即可得到最终的检索图片.
3. 实验结果
3.1 数据集
MNIST Dataset - 10类手写数字,0~9,共 60000张训练图片,10000测试图片,每张数字图片都归一化为 28×2828×28 的灰度图片.
CIFAR-10 Dataset - 10类物体,每一类有 6000 张图片,一种60000张图片,其中50000张作训练,10000张作测试.
Yahoo-1M Dataset - 一共1124087张商品图片,116类服装类别,如 TOP,Dress,Skirt等. 如Figure2.

3.2 检索结果
假设某层网络权重为 ,输入为
,输出为
,经过
激活后为
。
首先复习一下神经网络的前向传播公式和反向传播公式。对反向传播公式,记忆方法是根据维度法,即求某个向量或矩阵的导数,乘完后看看这个导数的维度是否和原向量/矩阵相同。
前向传播公式为:
设损失函数为 ,反向传播公式为:WT代表 倒数
对固定的学习率 ,梯度
越大,权重
更新的越多:
如果梯度太大,而学习率又不小心设置得太大,就会导致权重一下子更新过多,就有可能出现这种情况:对于任意训练样本 ,网络的输出都是小于0的
1.引言
本系统是基于CVPR2015的论文《Deep Learning of Binary Hash Codes for Fast Image Retrieval》实现的海量数据下的基于内容图片检索系统,250w图片下,对于给定图片,检索top 1000相似时间约为1s,其基本背景和原理会在下文提到。
2.基本问题与技术
大家都知道,基于内容的图像检索系统是根据图像的内容,在已有图像集中找到最『相近』的图片。而这类系统的效果(精准度和速度)和两个东西直接相关:
图片特征的表达能力
近似最近邻的查找
根据我们这个简单系统里的情况粗浅地谈谈这两个点。
首先说图像特征的表达能力,这一直是基于内容的图像检索最核心却又困难的点之一,计算机所『看到』的图片像素层面表达的低层次信息与人所理解的图像多维度高层次信息内容之间有很大的差距,因此我们需要一个尽可能丰富地表达图像层次信息的特征。
我们前面的博客也提到了,deep learning是一个对于图像这种层次信息非常丰富的数据,有更好表达能力的框架,其中每一层的中间数据都能表达图像某些维度的信息,相对于传统的Hist,Sift和Gist,表达的信息可能会丰富一下,因此这里我们用deep learning产出的特征来替代传统图像特征,希望能对图像有更精准的描绘程度。
再说『近似最近邻』,ANN(Approximate Nearest Neighbor)/近似最近邻一直是一个很热的研究领域。
因为在海量样本的情况下,遍历所有样本,计算距离,精确地找出最接近的Top K个样本是一个非常耗时的过程,尤其有时候样本向量的维度也相当高,因此有时候我们会牺牲掉一小部分精度,来完成在很短的时间内找到近似的top K个最近邻,也就是ANN,
最常见的ANN算法包括局部敏感度哈希/locality-sensitive hashing,最
优节点优先/best bin first和Balanced box-decomposition tree等,
我们系统中将采用LSH/局部敏感度哈希来完成这个过程。有
一些非常专业的ANN库,比如FLANN,有兴趣的同学可以了解一下。
本文主要介绍一种用于海量高维数据的近似最近邻快速查找技术——局部敏感哈希(Locality-Sensitive Hashing, LSH),内容包括了LSH的原理、LSH哈希函数集、以及LSH的一些参考资料。
一、局部敏感哈希LSH
在很多应用领域中,我们面对和需要处理的数据往往是海量并且具有很高的维度,怎样快速地从海量的高维数据集合中找到与某个数据最相似(距离最近)的一个数据或多个数据成为了一个难点和问题。如果是低维的小数据集,我们通过线性查找(Linear Search)就可以容易解决,但如果是对一个海量的高维数据集采用线性查找匹配的话,会非常耗时,因此,为了解决该问题,我们需要采用一些类似索引的技术来加快查找过程,通常这类技术称为最近邻查找(Nearest Neighbor,AN),例如K-d tree;或近似最近邻查找(Approximate Nearest Neighbor, ANN),例如K-d tree with BBF, Randomized Kd-trees, Hierarchical K-means Tree。而LSH是ANN中的一类方法。
我们知道,通过建立Hash Table的方式我们能够得到O(1)的查找时间性能,其中关键在于选取一个hash function,将原始数据映射到相对应的桶内(bucket, hash bin),例如对数据求模:h = x mod w,w通常为一个素数。
在对数据集进行hash 的过程中,会发生不同的数据被映射到了同一个桶中(即发生了冲突collision),这一般通过再次哈希将数据映射到其他空桶内来解决。这是普通Hash方法或者叫传统Hash方法,其与LSH有些不同之处。
局部敏感哈希示意图(from: Piotr Indyk)

LSH的基本思想是:
将原始数据空间中的两个相邻数据点通过相同的映射或投影变换(projection)后,这两个数据点在新的数据空间中仍然相邻的概率很大,
而不相邻的数据点被映射到同一个桶的概率很小
。也就是说,如果我们对原始数据进行一些hash映射后,
我们希望原先相邻的两个数据能够被hash到相同的桶内,
具有相同的桶号。
对原始数据集合中所有的数据都进行hash映射后,我们就得到了一个hash table,
这些原始数据集被分散到了hash table的桶内,
每个桶会落入一些原始数据,
属于同一个桶内的数据就有很大可能是相邻的,
当然也存在不相邻的数据被hash到了同一个桶内
。因此,如果我们能够找到这样一些hash functions,使得经过它们的哈希映射变换后,原始空间中相邻的数据落入相同的桶内的话
,那么我们在该数据集合中进行近邻查找就变得容易了,
我们只需要将查询数据进行哈希映射得到其桶号,
然后取出该桶号对应桶内的所有数据,
再进行线性匹配即可查找到与查询数据相邻的数据。
换句话说,我们通过hash function映射变换操作
,将原始数据集合分成了多个子集合,
而每个子集合中的数据间是相邻的且该子集合中的元素个数较小,
因此将一个在超大集合内查找相邻元素的问题转化为了在一个很小的集合内查找相邻元素的问题,
显然计算量下降了很多。
那具有怎样特点的hash functions才能够使得原本相邻的
两个数据点经过hash变换后会落入相同的桶内?
这些hash function需要满足以下两个条件:
1)如果d(x,y) ≤ d1, 则h(x) = h(y)的概率至少为p1;
2)如果d(x,y) ≥ d2, 则h(x) = h(y)的概率至多为p2;
其中d(x,y)表示x和y之间的距离,d1 < d2,
h(x)和h(y)分别表示对x和y进行hash变换。
满足以上两个条件的hash functions称为(d1,d2,p1,p2)-sensitive。
而通过一个或多个(d1,d2,p1,p2)-sensitive的hash function对原始数据集合进行hashing生成一个或多个hash table
的过程称为Locality-sensitive Hashing。
使用LSH进行对海量数据建立索引(Hash table)并通过索引来进行近似最近邻查找的过程如下:
1. 离线建立索引
(1)选取满足(d1,d2,p1,p2)-sensitive的LSH hash functions;
(2)根据对查找结果的准确率(即相邻的数据被查找到的概率)确定hash table的个数L,每个table内的hash functions的个数K,以及跟LSH hash function自身有关的参数;
(3)将所有数据经过LSH hash function哈希到相应的桶内,构成了一个或多个hash table;
2. 在线查找
(1)将查询数据经过LSH hash function哈希得到相应的桶号;
(2)将桶号中对应的数据取出;(为了保证查找速度,通常只需要取出前2L个数据即可);
(3)计算查询数据与这2L个数据之间的相似度或距离,返回最近邻的数据;
LSH在线查找时间由两个部分组成:
(1)通过LSH hash functions计算hash值(桶号)的时间;(2)将查询数据与桶内的数据进行比较计算的时间。因此,LSH的查找时间至少是一个sublinear时间(
)。为什么是“至少”?因为我们可以通过对桶内的属于建立索引来加快匹配速度,这时第(2)部分的耗时就从O(N)变成了O(logN)或O(1)(取决于采用的索引方法)。
LSH为我们提供了一种在海量的高维数据集中查找与查询数据点(query data point)近似最相邻的某个或某些数据点。需要注意的是,LSH并不能保证一定能够查找到与query data point最相邻的数据,而是减少需要匹配的数据点个数的同时保证查找到最近邻的数据点的概率很大。
二、LSH的应用
LSH的应用场景很多,凡是需要进行大量数据之间的相似度(或距离)计算的地方都可以使用LSH来加快查找匹配速度,下面列举一些应用:
(1)查找网络上的重复网页
互联网上由于各式各样的原因(例如转载、抄袭等)会存在很多重复的网页,因此为了提高搜索引擎的检索质量或避免重复建立索引,需要查找出重复的网页,以便进行一些处理。其大致的过程如下:将互联网的文档用一个集合或词袋向量来表征,然后通过一些hash运算来判断两篇文档之间的相似度,常用的有minhash+LSH、simhash。
(2)查找相似新闻网页或文章
与查找重复网页类似,可以通过hash的方法来判断两篇新闻网页或文章是否相似,只不过在表达新闻网页或文章时利用了它们的特点来建立表征该文档的集合。
(3)图像检索
在图像检索领域,每张图片可以由一个或多个特征向量来表达,为了检索出与查询图片相似的图片集合,我们可以对图片数据库中的所有特征向量建立LSH索引,然后通过查找LSH索引来加快检索速度。目前图像检索技术在最近几年得到了较大的发展,有兴趣的读者可以查看基于内容的图像检索引擎的相关介绍。
(4)音乐检索
对于一段音乐或音频信息,我们提取其音频指纹(Audio Fingerprint)来表征该音频片段,采用音频指纹的好处在于其能够保持对音频发生的一些改变的鲁棒性,例如压缩,不同的歌手录制的同一条歌曲等。为了快速检索到与查询音频或歌曲相似的歌曲,我们可以对数据库中的所有歌曲的音频指纹建立LSH索引,然后通过该索引来加快检索速度。
(5)指纹匹配
一个手指指纹通常由一些细节来表征,通过对比较两个手指指纹的细节的相似度就可以确定两个指纹是否相同或相似。类似于图片和音乐检索,我们可以对这些细节特征建立LSH索引,加快指纹的匹配速度。
3. 本检索系统原理
图像检索系统和关键环节如下图所示:
图像检索过程简单说来就是对图片数据库的每张图片抽取特征(一般形式为特征向量),存储于数据库中,对于待检索图片,抽取同样的特征向量,然后并对该向量和数据库中向量的距离,找出最接近的一些特征向量,其对应的图片即为检索结果。
基于内容的图像检索系统最大的难点在上节已经说过了,其一为大部分神经网络产出的中间层特征维度非常高,比如Krizhevsky等的在2012的ImageNet比赛中用到的AlexNet神经网,第7层的输出包含丰富的图像信息,但是维度高达4096维。
4096维的浮点数向量与4096维的浮点数向量之间求相似度,运算量较大
,因此Babenko等人在论文Neural codes for image retrieval中提出用PCA对4096维的特征进行PCA降维压缩,
然后用于基于内容的图像检索,
此场景中效果优于大部分传统图像特征。
同时因为高维度的特征之间相似度运算会消耗一定的时间,因此线性地逐个比对数据库中特征向量是显然不可取的。
大部分的ANN技术都是将高维特征向量压缩到低维度空间,并且以01二值的方式表达,因为在低维空间中计算两个二值向量的汉明距离速度非常快,因此可以在一定程度上缓解时效问题。
ANN的这部分hash映射是在拿到特征之外做的(那我们这个论文就是用ANN这样的思想做的),本系统框架试图让卷积神经网在训练过程中学习出对应的『二值检索向量』,或者我们可以理解成对全部图先做了一个分桶操作,每次检索的时候只取本桶和临近桶的图片作比对,而不是在全域做比对,以提高检索速度。
论文是这样实现『二值检索向量』的:
在Krizhevsky等2012年用于ImageNet中的卷积神经网络结构基础上,在第7层(4096个神经元)和output层之间多加了一个隐层(全连接层)。
隐层的神经元激励函数,可以选用sigmoid,这样输出值在0-1之间值,可以设定阈值(比如说0.5)之后,将这一层输出变换为01二值向量作为『二值检索向量』,这样在使用卷积神经网做图像分类训练的过程中,会『学到』和结果类别最接近的01二值串,也可以理解成,我们把第7层4096维的输出特征向量,通过神经元关联压缩成一个低维度的01向量,但不同于其他的降维和二值操作,这是在一个神经网络里完成的,
每对图片做一次完整的前向运算拿到类别,
就产出了表征图像丰富信息的第7层output(4096维)和代表图片分桶的第8层output(神经元个数自己指定,一般都不会很多,因此维度不会很高)。引用论文中的图例解释就是如下的结构:
上方图为ImageNet比赛中使用的卷积神经网络;
中间图为调整后,在第7层和output层之间添加隐层(假设为128个神经元)后的卷积神经网络,
我们将复用ImageNet中得到最终模型的前7层权重做fine-tuning,得到第7层、8层和output层之间的权重
。
下方图为实际检索过程,
对于所有的图片做卷积神经网络前向运算得到第7层4096维特征向量和第8层128维输出(设定阈值0.5之后可以转成01二值检索向量),
对于待检索的图片,同样得到4096维特征向量和128维01二值检索向量,
粗检索:在数据库中查找二值检索向量对应『桶』内图片(得到池中的图片集合)
细检索:比对4096维特征向量之间距离(fine-level),
做重拍即得到最终结果。
图上的检索例子比较直观,对于待检索的”鹰”图像,算得二值检索向量为101010,取出桶内图片(可以看到基本也都为鹰),比对4096维特征向量之间距离,重新排序拿得到最后的检索结果。
4. 预训练好的模型
一般说来,在自己的图片训练集上,针对特定的场景进行图像类别训练,得到的神经网络,中间层特征的表达能力会更有针对性一些。具体训练的过程可以第3节中的说明。对于不想自己重新费时训练,或者想快速搭建一个基于内容的图片检索系统的同学,这里也提供了100w图片上训练得到的卷积神经网络模型供大家使用。
这里提供了2个预先训练好的模型
,供大家提取『图像特征』和『二值检索串』用
。2个模型训练的数据集一致,卷积神经网络搭建略有不同。
对于几万到十几万级别的小量级图片建立检索系统,请使用模型Image_Retrieval_20_hash_code.caffemodel,对于百万以上的图片建立检索系统,请使用模型Image_Retrieval_128_hash_code.caffemodel。
对于同一张图片,两者产出的特征均为4096维度,但用作分桶的『二值检索向量』长度,前者为20,后者为128。
1、基于内容的图像检索
1.1、基于内容的图像检索
基于内容的图像检索(Content-based Image Retrieval,CBIR)旨在通过对图像内容的分析搜索出相似的图像,其主要的工作有如下两点:
- 图像表示(image representation)
- 相似性度量(similarity measure)
1.2、基于CNN的图像内容提取
以AlexNet卷积神经网络为例,AlexNet的网络结构如下图所示:

(图片来源:ImageNet Classification with Deep Convolutional Neural Networks)
将最终的4096维向量作为最终图像的特征向量。这样的向量是一些高维向量,不利于计算。
2、二进制哈希编码的深度学习方法
2.1、模型结构
模型结构如下图所示:
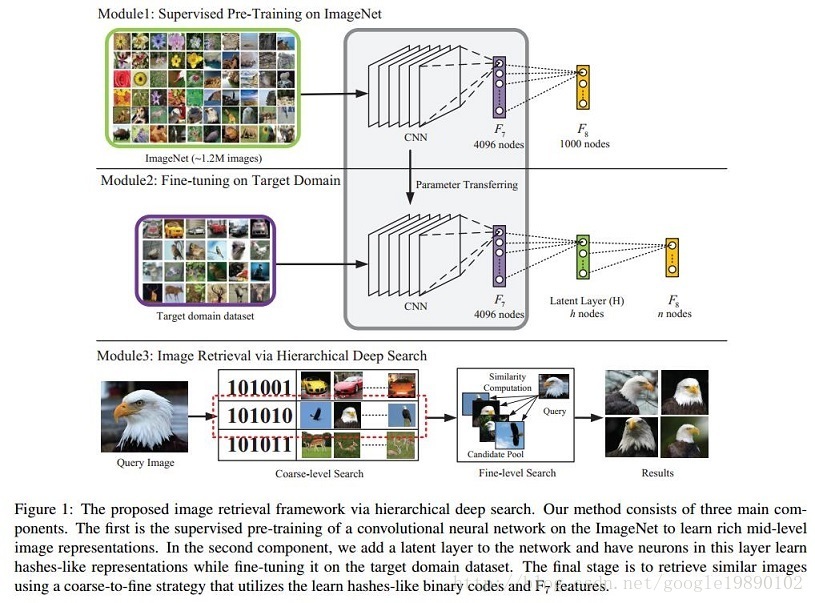
在文章中,作者指出,该模型主要有三个主要的部分:
- 在大规模的ImageNet数据集上进行有监督的预训练;
- 在目标数据集上对模型进行微调,同时增加隐含层;
- 接收query,提取query的hash编码,同时查找相似的图像。
2.2、对hash的二进制编码的学习
本人认为在上图中,F7F7F_7与F8F8F_8之间会存在一个隐层,这一点不影响对Latent Layer的构造。
如上所述,我们可以使用F7F7F_7的结构作为图像的特征,但是这样的向量是一个高维的向量(4096维),这样的向量不利于计算。解决的方法有:降维(如PCA,Hash等方法)。通过Hash的方法构造出来的二进制的编码形式,可以利用hashing和Hamming距离计算相似度,那么能否通过模型学习到最好的Hash方法?
解决的方法是在F7F7F_7和F8F8F_8之间增加一个映射层(Latent Layer)H,那么如果两个图片生成的二进制编码相似,那么这两张图片也应该具有相同的标签。在H层的激活函数为Sigmoid函数。
2.3、检索
在深层的卷积神经网络中,浅层可以学习到局部的视觉表征(mid-level),而深层可以捕获到适合识别的语义信息。
在检索阶段,作者采用了由粗到精的搜索策略(coarse-to-fine search strategy):
- 首先从Latent layer中检索出一批相似的候选集
2.3.1、粗粒度检索

2.3.2、细粒度检索

先说说整个流程,一般的步骤是先把数据点(可以是原始数据,或者提取到的特征向量)组成矩阵,然后通过第一步的hash functions(有多个哈希函数,是从某个哈希函数族中选出来的)哈希成一个叫“签名矩阵(Signature Matrix)”的东西,这个矩阵可以直接理解为是降维后的数据,然后再通过LSH把Signature Matrix哈希一下,就得到了每个数据点最终被hash到了哪个bucket里,
如果新来一个数据点,假如是一个网页的特征向量,我想找和这个网页相似的网页,那么把这个网页对应的特征向量hash一下,看看它到哪个桶里了,
于是bucket里的网页就是和它相似的一些候选网页,
这样就大大减少了要比对的网页数,极大的提高了效率。
注意上句为什么说是“候选网页”,也就是说,在那个bucket里,也有可能存在和被hash到这个bucket的那个网页不相似的网页,原因请回忆前面讲的“降维”问题。。但LSH的巧妙之处在于可以控制这种情况发生的概率,这一点实在是太牛了,下面会介绍。
由于采用不同的相似性度量时,第一步所用的hash functions是不一样的,并没有通用的hash functions,因此下面主要介绍两种情况:
(1)用Jaccard相似性度量时,(
2)用Cosine相似性度量时。在第一步之后得到了Signature Matrix后,第二步就都一样了。
先来看看用Jaccard相似性度量时第一步的hash functions。
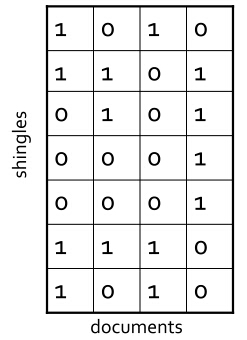
假设现在有4个网页(看成是document),页面中词项的出现情况用以下矩阵来表示,1表示对应词项出现,0则表示不出现,这里并不用去count出现了几次,因为是用Jaccard去度量的嘛,原因就不用解释了吧。
好,接下来我们就要去找一种hash function,使得在hash后尽量还能保持这些documents之间的Jaccard相似度
目标就是找到这样一种哈希函数h(),如果原来documents的Jaccard相似度高,那么它们的hash值相同的概率高,如果原来documents的Jaccard相似度低,那么它们的hash值不相同的概率高。这玩意叫Min-Hashing。
Min-Hashing是怎么做的呢?请看下图:

首先生成一堆随机置换,把Signature Matrix的每一行进行置换,然后hash function就定义为把一个列C hash成一个这样的值:就是在置换后的列C上,第一个值为1的行的行号。呼,听上去好抽象,下面看列子:
图中展示了三个置换,就是彩色的那三个,我现在解释其中的一个,另外两个同理。比如现在看蓝色的那个置换,置换后的Signature Matrix为:
然后看第一列的第一个是1的行是第几行,是第2行,同理再看二三四列,分别是1,2,1,因此这四列(四个document)在这个置换下,被哈希成了2,1,2,1,就是右图中的蓝色部分,也就相当于每个document现在是1维。再通过另外两个置换然后再hash,又得到右边的另外两行,于是最终结果是每个document从7维降到了3维。我们来看看降维后的相似度情况,就是右下角那个表,给出了降维后的document两两之间的相似性。可以看出,还是挺准确的,回想一下刚刚说的:希望原来documents的Jaccard相似度高,那么它们的hash值相同的概率高,如果原来documents的Jaccard相似度低,那么它们的hash值不相同的概率高,如何进行概率上的保证?Min-Hashing有个惊人的性质:
就是说,对于两个document,在Min-Hashing方法中,它们hash值相等的概率等于它们降维前的Jaccard相似度。下面来看看这个性质的Proof:
设有一个词项x(就是Signature Matrix中的行),它满足下式:
就是说,词项x被置换之后的位置,和C1,C2两列并起来(就是把两列对应位置的值求或)的结果的置换中第一个是1的行的位置相同。那么有下面的式子成立:
就是说x这个词项要么出现在C1中(就是说C1中对应行的值为1),要么出现在C2中,或者都出现。这个应该很好理解,因为那个1肯定是从C1,C2中来的。
那么词项x同时出现在C1,C2中(就是C1,C2中词项x对应的行处的值是1)的概率,就等于x属于C1与C2的交集的概率,这也很好理解,属于它们的交集,就是同时出现了嘛。那么现在问题是:已知x属于C1与C2的并集,那么x属于C1与C2的交集的概率是多少?其实也很好算,就是看看它的交集有多大,并集有多大,那么x属于并集的概率就是交集的大小比上并集的大小,而交集的大小比上并集的大小,不就是Jaccard相似度吗?于是有下式:
又因为当初我们的hash function就是
往上面一代,不就是下式了吗?
这就证完了,这标志着我们找到了第一步中所需要的hash function,再注意一下,现在这个hash function只适用于Jaccard相似度,并没有一个万能的hash function。有了hash functions,就可以求Signature Matrix了,求得Signature Matrix之后,就要进行LSH了。
首先将Signature Matrix分成一些bands,每个bands包含一些rows,如下图所示:
然后把每个band哈希到一些bucket中,如下图所示:
注意bucket的数量要足够多,使得两个不一样的bands被哈希到不同的bucket中,这样一来就有:如果两个document的bands中,至少有一个share了同一个bucket,那这两个document就是candidate pair,也就是很有可能是相似的。
下面来看看一个例子,来算一下概率,假设有两个document,它们的相似性是80%,它们对应的Signature Matrix矩阵的列分别为C1,C2,又假设把Signature Matrix分成20个bands,每个bands有5行,那么C1中的一个band与C2中的一个band完全一样的概率就是0.8^5=0.328,那么C1与C2在20个bands上都没有相同的band的概率是(1-0.328)^20=0.00035,这个0.00035概率表示什么?它表示,如果这两个document是80%相似的话,LSH中判定它们不相似的概率是0.00035,多么小的概率啊!
再看先一个例子,假设有两个document,它们的相似性是30%,它们对应的Signature Matrix矩阵的列分别为C1,C2,Signature Matrix还是分成20个bands,每个bands有5行,那么C1中的一个band与C2中的一个band完全一样的概率就是0.3^5=0.00243,那么C1与C2在20个bands至少C1的一个band和C2的一个band一样的概率是1-(1-0.00243)……20=0.0474,换句话说就是,如果这两个document是30%相似的话,LSH中判定它们相似的概率是0.0474,也就是几乎不会认为它们相似,多么神奇。
更为神奇的是,这些概率是可以通过选取不同的band数量以及每个band中的row的数量来控制的:
除此之外,还可以通过AND和OR操作来控制,就不展开了。
呼,LSH的核心内容算是介绍完了,下面再简单补充一下当相似性度量是Cosine相似性的时候,第一步的hash function是什么。它是用了一个叫随机超平面(Random Hyperplanes)的东西,就是说随机生成一些超平面,哈希方法是看一个特征向量对应的点,它是在平台的哪一侧:
这个可以直观地想象一下,假设有两个相交的超平面,把空间分成了4个区域,如果两个特征向量所对应的点在同一域中,那么这两个向量是不是挨得比较近?因此夹角就小,Cosine相似度就高。对比一下前面用Jaccard相似度时Signature Matrix的生成方法,那里是用了三个转换,在这里对应就是用三个随机超平面,生成方法是:对于一个列C(这里因为是用Cosine相似度,所以列的值就不一定只是0,1了,可以是其它值,一个列就对应一个特征向量),算出该列对应的特征向量的那个点,它是在超平面的哪个侧,从而对于每个超平面,就得到+1或者-1,对于三个超平面,就得到三个值,就相当于把原来7维的数据降到三维,和前面用Jaccard相似度时的情况是不是很像?得到Signature Matrix后,就进行LSH,步骤是一样的~~~~~~~
---------------------
作
PointWise
单文档方法的处理对象是单独的一篇文档,将文档转换为特征向量后,机器学习系统根据从训练数据中学习到的分类或者回归函数对文档打分,打分结果即是搜索结果

PointWise方法很好理解,即使用传统的机器学习方法对给定查询下的文档的相关度进行学习,比如CTR就可以采用PointWise的方法学习,但是有时候排序的先后顺序是很重要的,而PointWise方法学习到全局的相关性,并不对先后顺序的优劣做惩罚。
PairWise
对于搜索系统来说,系统接收到用户査询后,返回相关文档列表,所以问题的关键是确定文档之间的先后顺序关系。单文档方法完全从单个文档的分类得分角度计算,没有考虑文档之间的顺序关系。文档对方法将排序问题转化为多个pair的排序问题,比较不同文章的先后顺序。

但是文档对方法也存在如下问题:
文档对方法考虑了两个文档对的相对先后顺序,却没有考虑文档出现在搜索列表中的位置,排在搜索结果前面的文档更为重要,如果靠前的文档出现判断错误,代价明显高于排在后面的文档。
同时不同的査询,其相关文档数量差异很大,所以转换为文档对之后, 有的查询对能有几百个对应的文档对,而有的查询只有十几个对应的文档对,这对机器学习系统的效果评价造成困难
常用PairWise实现:
- SVM Rank
- RankNet(2007)
- RankBoost(2003)
作者:y_felix
链接:https://www.jianshu.com/p/aab1bf1307fd
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
作者:y_felix
链接:https://www.jianshu.com/p/aab1bf1307fd
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
深蓝色 --ppt的更多相关文章
- 蓝色大气简约立体答辩ppt模板推荐
小编个人非常喜欢这个模版,大气深蓝色,具有科技感,非常适合学生的毕业答辩PPT模板. 模版来源:http://ppt.dede58.com/gongzuohuibao/26496.html
- 46张PPT讲述JVM体系结构、GC算法和调优
本PPT从JVM体系结构概述.GC算法.Hotspot内存管理.Hotspot垃圾回收器.调优和监控工具六大方面进行讲述.(内嵌iframe,建议使用电脑浏览) 好东西当然要分享,PPT已上传可供下载 ...
- C#向PPT文档插入图片以及导出图片
PowerPoint演示文稿是我们日常工作中常用的办公软件之一,而图片则是PowerPoint文档的重要组成部分,那么如何向幻灯片插入图片以及导出图片呢?本文我将给大家分享如何使用一个免费版Power ...
- Impress.js上手 - 抛开PPT、制作Web 3D幻灯片放映
前言: 如果你已经厌倦了使用PPT设置路径.设置时间.设置动画方式来制作动画特效.那么Impress.js将是你一个非常好的选择. 用它制作的PPT将更加直观.效果也是嗷嗷美观的. 当然,如果用它来装 ...
- Linux环境下常见漏洞利用技术(培训ppt+实例+exp)
记得以前在drops写过一篇文章叫 linux常见漏洞利用技术实践 ,现在还可以找得到(https://woo.49.gs/static/drops/binary-6521.html), 不过当时开始 ...
- 《学技术练英语》PPT分享
之前做的一个PPT,分享给博客园的同学. 下载地址: 学技术练英语.pdf 技术是靠自己去学的,学技术不能仅仅是看书看博客,最好是有实践,不管是做实验去验证,还是写各种代码去玩各种特性,还是造轮子都是 ...
- Cleaver快速制作网页PPT
原文首发链接:http://www.jeffjade.com/2015/10/15/2015-10-16-cleaver-make-ppt/ 写在开始之前 互联网时代,以浏览器作为入口,已经有越来越多 ...
- 微软Ignite大会我的Session(SQL Server 2014 升级面面谈)PPT分享
我在首届微软技术大会的Session分享了一个关于SQL Server升级的主题,现在将PPT分享出来. 您可以点击这里下载PPT. 也非常感谢微软中国邀请我进行这次分享.
- C# 复制幻灯片(包括格式、背景、图片等)到同/另一个PPT文档
C# 复制幻灯片(包括格式.背景.图片等)到同/另一个PPT文档 复制幻灯片是使用PowerPoint过程中的一个比较常见的操作,在复制一张幻灯片时一般有以下两种情况: 在同一个PPT文档内复制 从一 ...
随机推荐
- Word转换为markdown
Word转换为markdown 首先你的电脑要有office word 1 安装pandoc https://github.com/jgm/pandoc/releases,可以找到最新的pando ...
- 搭建本地离线yum仓库
目录 前言 把rpm包下载到本地 配置本地yum仓库信息 生成repodata信息 检查以及使用 对本地仓库进行更新 参考资料 修改记录 环境:VMware-Workstation-12-Pro,Wi ...
- PAT Counting Leaves[一般]
1004 Counting Leaves (30)(30 分) A family hierarchy is usually presented by a pedigree tree. Your job ...
- 2:2 strus2的配置文件
strus2 的xml配置文件主要负责Action的管理,常放在WEB-INF/classes目录下,被自动加载 在strus-core jar包下找dtd文件,里面有xml的头信息.也有contan ...
- 20155334 2016-2017-2 《Java程序设计》第八周学习总结
20155334 2016-2017-2 <Java程序设计>第八周学习总结 教材学习内容总结 第十四章:NIO与NIO2 NIO的定义: InputStream.OutputStream ...
- CAScrollLayer
CAScrollLayer 对于一个未转换的图层,它的bounds和它的frame是一样的,frame属性是由bounds属性自动计算而出的,所以更改任意一个值都会更新其他值. 但是如果你只想显示一个 ...
- 远程登录 dos命令
1.桌面连接命令 mstsc /v: 192.168.1.250 /console 2.若需要远程启动所有Internet服务,可以使用iisreset命令来实现. 进入“命令提示符”窗口.在提示符后 ...
- Redis 如何保持和MySQL数据一致【一】
1. MySQL持久化数据,Redis只读数据redis在启动之后,从数据库加载数据.读请求:不要求强一致性的读请求,走redis,要求强一致性的直接从mysql读取写请求:数据首先都写到数据库,之后 ...
- php多进程结合Linux利器split命令实现把大文件分批高效处理
有时候会遇到这样的需求,比如log日志文件,这个文件很大,甚至上百M,需要把所有的日志拿来做统计,这时候我们如果用单进程来处理,效率会很慢.如果我们想要快速完成这项需求,我们可以利用Linux的一个利 ...
- 01: 重写Django admin
目录: 1.1 重写Django admin项目各文件作用# 1.2 重写Django admin用户认证 1.3 将要显示的表注册到我们自己的kind_admin.py中 1.4 项目首页:显示注册 ...