linux安装elasticsearch-head和elasticsearch-analysis-ik及遇到的各种问题
1.获取elasticsearch-head
http://mobz.github.io/elasticsearch-head/
下载并解压
wget https://github.com/mobz/elasticsearch-head/archive/master.zip
unzip master.zip
2.安装node,使用head 插件,需要node.js的支持,所以先安装node.js
下载并解压
wget https://npm.taobao.org/mirrors/node/latest-v9.x/node-v9.0.0-linux-x64.tar.gz
tar -zxvf tar -zxvf node-v9.0.0-linux-x64.tar.gz
配置环境变量
vim /etc/profile
#添加
export NODE_HOME=/usr/local/node-v9.0.0-linux-x64
export PATH=$PATH:$NODE_HOME/bin/
export NODE_PATH=$NODE_HOME/lib/node_modules
3.安装
npm install
NPM是随同NodeJS一起安装的包管理工具,能解决NodeJS代码部署上的很多问题,常见的使用场景有以下几种:
- 允许用户从NPM服务器下载别人编写的第三方包到本地使用。
- 允许用户从NPM服务器下载并安装别人编写的命令行程序到本地使用。
- 允许用户将自己编写的包或命令行程序上传到NPM服务器供别人使用。
由于新版的nodejs已经集成了npm,所以之前npm也一并安装好了。同样可以通过输入 "npm -v" 来测试是否成功安装。命令如下,出现版本提示表示安装成功:
v9.0.0
4.安装中文分词插件ik
下载并解压至elasticsearch的插件目录下
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.3.2/elasticsearch-analysis-ik-6.3.2.zip
unzip elasticsearch-analysis-ik-6.3.2.zip
5.启动
启动elasticsearch
sh ./elasticsearch-6.3.2/bin/elasticsearch -d
启动node插件
npm run start
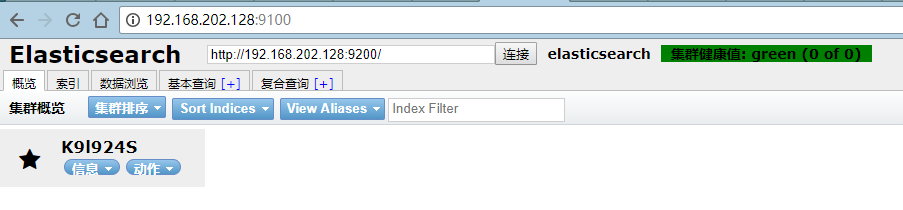
效果
安装elasticsearch-analysis-ik中文分词插件
1.在elasticsearch下的plugins文件夹中创建ik文件夹 下载并解压ik至
mkdir ik
2.下载并解压ik到ik文件夹
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.3.2/elasticsearch-analysis-ik-6.3.2.zip
unzip elasticsearch-analysis-ik-6.3..zip -d /elasticsearch-6.3./plugins/ik
3.重启elasticsearch,可以看到启动信息中有加载插件ik

4.测试ik提供的简单案例
.create a index curl -XPUT http://localhost:9200/index
.create a mapping curl -XPOST http://localhost:9200/index/fulltext/_mapping -H 'Content-Type:application/json' -d'
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
} }'
.index some docs curl -XPOST http://localhost:9200/index/fulltext/1 -H 'Content-Type:application/json' -d'
{"content":"美国留给伊拉克的是个烂摊子吗"}
'
curl -XPOST http://localhost:9200/index/fulltext/2 -H 'Content-Type:application/json' -d'
{"content":"公安部:各地校车将享最高路权"}
'
curl -XPOST http://localhost:9200/index/fulltext/3 -H 'Content-Type:application/json' -d'
{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}
'
curl -XPOST http://localhost:9200/index/fulltext/4 -H 'Content-Type:application/json' -d'
{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}
'
.query with highlighting curl -XPOST http://localhost:9200/index/fulltext/_search -H 'Content-Type:application/json' -d'
{
"query" : { "match" : { "content" : "中国" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}
'
Result {
"took": ,
"timed_out": false,
"_shards": {
"total": ,
"successful": ,
"failed":
},
"hits": {
"total": ,
"max_score": ,
"hits": [
{
"_index": "index",
"_type": "fulltext",
"_id": "",
"_score": ,
"_source": {
"content": "中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
},
"highlight": {
"content": [
"<tag1>中国</tag1>驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首 "
]
}
},
{
"_index": "index",
"_type": "fulltext",
"_id": "",
"_score": ,
"_source": {
"content": "中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"
},
"highlight": {
"content": [
"均每天扣1艘<tag1>中国</tag1>渔船 "
]
}
}
]
}
}
注意事项及遇到的问题
1.显示集群健康值:未连接
修改配置文件 vim /elasticsearch-5.6.3 /config/elasticsearch.yml 添加配置
#如果启用了 HTTP 端口,那么此属性会指定是否允许跨源 REST 请求
http.cors.enabled: true
#如果 http.cors.enabled 的值为 true,那么该属性会指定允许 REST 请求来自何处
http.cors.allowed.origin: "*"
2.ik的
在ik提供的案例中,第一步创建了索引后,第二步一直提示错误
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "Mapper for [content] conflicts with existing mapping in other types:\n[mapper [content] has different [analyzer]]"
}
],
"type": "illegal_argument_exception",
"reason": "Mapper for [content] conflicts with existing mapping in other types:\n[mapper [content] has different [analyzer]]"
},
"status":
}
从错误提示上来看是说要创建的映射已经存在了,问题的关键就在于我没有创建过叫index的索引.中文站是废了,最终老歪给出了回复,大致原因应该是我在创建了索引后,没有创建mapping前查询过该索引,那么es就会自动为该索引创建一个mapping.
| 属性 | 缺省值 | 描述 |
|---|---|---|
| cluster.name | federated_cluster | Elasticsearch 集群名称。使用集群可将单独 Process Federation Server 绑定到单个分布式系统中。参与集群的所有服务器都必须具有相同的集群名称。 |
| node.name | node1 | Elasticsearch 节点名。集群中的每个 Process Federation Server 都必须具有唯一节点名。 |
| node.master | true | 指示某个节点是否符合成为主节点的条件。主节点管理 Elasticsearch 集群的状态。在运行时,Elasticsearch 服务会自动提名某一个合格的集群成员成为主节点。
仅当您想要对专用主节点和数据节点采用高级配置时,才将该值设置为 false。此类型的配置并不常用。 |
| node.data | true | 指示节点是否为数据节点。数据节点包含并管理索引的一部分。
仅当您想要对专用主节点和数据节点采用高级配置时,才将该值设置为 false。此类型的配置并不常用。 |
| http.enabled | false | 指示是否为 Elasticsearch 服务启用 HTTP。如果您要通过使用 Elasticsearch REST 请求来直接查询 Elasticsearch 数据,那么可以启用 HTTP 端口。
限制:Elasticsearch HTTP 端口不支持安全连接。
|
| htttp.port | 9200 | 如果启用了 HTTP 端口,那么此属性指定由 Elasticsearch 服务使用的端口。 |
| http.cors.enabled | true | 如果启用了 HTTP 端口,那么此属性会指定是否允许跨源 REST 请求。 |
| http.cors.allowed.origin | localhost | 如果 http.cors.enabled 的值为 true,那么该属性会指定允许 REST 请求来自何处。 |
| transport.tcp.port | 9300 | 用于某个集群中 Elasticsearch 节点之间的通信的端口。 |
| discovery.zen.minimum_master_nodes | 1 | 指示某个集群定额所需的 Process Federation Server 的数量。
缺省值为 1 表示单服务器环境。对于生产环境,请将该值设置为组成定额所需的 Process Federation Server 的数量。例如,如果在集群中总计有三个 Process Federation Server,请将该值设置为“2”,如果在集群中总计有五个 Process Federation Server,请将该值设置为“3”。 有关更多信息,请参阅 Elasticsearch 文档。 |
| discovery.zen.ping.multicast.enabled | false | 通过发送节点所接收和响应的一个或多个多点广播请求来提供对其他 Elasticsearch 服务节点的多点广播 ping 发现功能。有关更多信息,请参阅 Elasticsearch 文档。 |
| discovery.zen.ping.unicasts.hosts | localhost | 提供其他 Elasticsearch 服务节点的单点广播发现功能。配置集群中基于主机 TCP 端口的其他 Elasticsearch 服务的逗号分隔列表。
例如:
有关更多信息,请参阅 Elasticsearch 文档 。 |
| discovery.zen.ping.timeout | 3s | Elastic 搜索节点等待加入 Elasticsearch 集群的时间。 |
linux安装elasticsearch-head和elasticsearch-analysis-ik及遇到的各种问题的更多相关文章
- Linux下,非Docker启动Elasticsearch 6.3.0,安装ik分词器插件,以及使用Kibana测试Elasticsearch,
Linux下,非Docker启动Elasticsearch 6.3.0 查看java版本,需要1.8版本 java -version yum -y install java 创建用户,因为elasti ...
- Linux安装Elasticsearch
本文介绍Linux环境如何安装Elasticsearch. 本文环境是在腾讯云服务器CentOS7.2搭建的,JDK1.8,elasticsearch-5.4.2. 1 安装JDK 网上教程很多,也可 ...
- Linux 安装elasticsearch、node.js、elasticsearch-head
前提:下载es的安装包 官网可以下载 es官网 安装elasticsearch 1 新建两个文件夹 一个存放安装文件,一个存放解压后的文件 mkdir -p /export/software //存放 ...
- docker 安装ElasticSearch的中文分词器IK
首先确保ElasticSearch镜像已经启动 安装插件 方式一:在线安装 进入容器 docker exec -it elasticsearch /bin/bash 在线下载并安装 ./bin/ela ...
- Linux安装ElasticSearch启动报错的解决方法
Linux安装ElasticSearch后,ElasticSearch是不能用root用户启动的,以root用户启动会报错Refer to the log for complete error det ...
- elasticsearch在linux上的安装,Centos7.X elasticsearch 7.6.2
本文环境:Elasticsearch7.6.2目前最先版本 centos7.X JDK1.8 elasticsearch介绍 官网:https://www.elastic.co/cn/pr ...
- elasticsearch在linux上的安装,Centos7.X elasticsearch 7.6.2安装
本文环境:Elasticsearch7.6.2目前最先版本 centos7.X JDK1.8 elasticsearch介绍 官网:https://www.elastic.co/cn/pr ...
- linux安装elasticsearch及遇到的各种问题
1.获取elasticsearch https://www.elastic.co/downloads/elasticsearch 终端输入赋值的下载链接进行下载 wget https://artifa ...
- linux 安装elasticsearch
一.检测是否已经安装的elasticsearch ps aux|grep elasticsearch. 二.下载elasticsearch.tar.gz并上传至服务器usr/local/文件夹下 三. ...
- linux安装Elasticsearch详细步骤
坑都已经踩好了 照着步骤一次成功 不多废话 走起 # ## 安装java运行环境 elasticsearch是用Java实现的 跑elasticsearch必须要有jre支持 所以必须先安装jre ...
随机推荐
- 《Java程序设计》 第五周学习总结
学号 20175313 <Java程序设计>第五周学习总结 教材学习内容总结 第六章主要内容 掌握接口的定义 接口声明:interface 接口名 接口体:包含常量的声明和抽象方法. 接口 ...
- cocos2d-js:游戏进入后台和返回游戏的事件捕获和处理
cocos2d-js 3.x处理 游戏置入后台和返回游戏的事件处理很方便 只需通过事件管理类cc.eventManager,自定义一个监听事件即可 代码如下 cc.eventManager.addCu ...
- .net core 配置
.net core 配置包括很多种 例如内存变量.命令行参数.环境变量以及物理文件配置和自定义配置 物理文件配置主要有三种,它们分别是JSON.XML和INI,对应的配置源类型分别是JsonConfi ...
- WebForm内置对象:Application和ViewState、Repeater的Command用法
一.内置对象 1.Application 存贮在服务器端,占用服务器内存生命周期:永久 所有人访问的都是这一个对象 传值:传的是object类型可以传对象. string s =TextBox1.Te ...
- pypi上传问题
pypi上传过程中报错403 windows 解决办法: 1.建一个新的记事本编辑内容 [distutils]index-servers = pypi [pypi]repository:https:/ ...
- Grunt: 拼接代码,js丑化(压缩),css压缩,html压缩,观察文件,拷贝文件,删除文件,压缩文件
准备工作 grunt 基于nodeJs所以 nodeJs需要的基础配置都需要安装 1.Grunt 安装 npm install -g grunt-cli 这是全局安装 2.在当前文件下npm init ...
- IDEA循环依赖报错解决方案
step1.查找循环依赖 step2.在IDEA菜单栏中打开Analyze->Analyze Module Dependencies...看到有的模块被红色的标出来了,此时右边显示了循环依赖,那 ...
- LNMP 如何安装mongodb
wget -c http://fastdl.mongodb.org/linux/mongodb-linux-x86_64-2.6.4.tgztar -zxvf mongodb-linux-x86_64 ...
- Python 事件驱动了解
事件驱动 gevent协程可实现自动切换,协程在遇到IO时会进行切换,到另外一个请求,那协程是如何得知在什么时候在切换回去呢? 通常,我们写服务器处理模型的程序时,有以下几种模型: (1)每收到一 ...
- Linux 查看网卡流量、网络端口
查看网络流量 # 查看网卡流量 命令:sar -n DEV 1 10 注:每1秒 显示 1次 显示 10次 平均时间: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcm ...