异常检测(anomaly detection)
版权声明:本文为博主原创文章,转载或者引用请务必注明作者和出处,尊重原创,谢谢合作 https://blog.csdn.net/u012328159/article/details/51462942
异常检测(anomaly detection)
- 异常检测定义及应用领域
- 常见的异常检测算法
- 高斯分布(正态分布)
- 异常检测算法
- 评估异常检测算法
- 异常检测VS监督学习
- 如何设计选择features
- 多元高斯分布
- 多元高斯分布在异常检测上的应用
- 欺诈检测:主要通过检测异常行为来检测是否为盗刷他人信用卡。
- 入侵检测:检测入侵计算机系统的行为
- 医疗领域:检测人的健康是否异常
- 基于模型的技术:许多异常检测技术首先建立一个数据模型,异常是那些同模型不能完美拟合的对象。例如,数据分布的模型可以通过估计概率分布的参数来创建。如果一个对象不服从该分布,则认为他是一个异常。
- 基于邻近度的技术:通常可以在对象之间定义邻近性度量,异常对象是那些远离大部分其他对象的对象。当数据能够以二维或者三维散布图呈现时,可以从视觉上检测出基于距离的离群点。
- 基于密度的技术:对象的密度估计可以相对直接计算,特别是当对象之间存在邻近性度量。低密度区域中的对象相对远离近邻,可能被看做为异常。
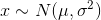 。其中
。其中 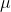 为数学期望,
为数学期望,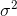 为方差,其概率密度函数为:
为方差,其概率密度函数为: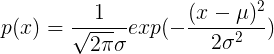
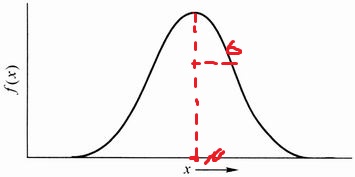 决定了其中心位置,标准差 决定了其宽度。如果
决定了其中心位置,标准差 决定了其宽度。如果 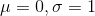 ,则称为标准正态分布,其图像如下图所示:
,则称为标准正态分布,其图像如下图所示: , 对图像的影响:
, 对图像的影响: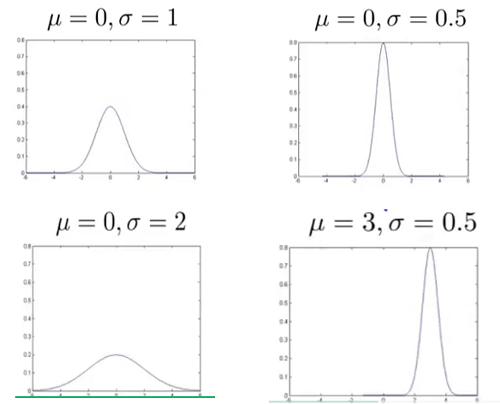
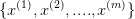 ,已知数据集中样本服从正态分布,即
,已知数据集中样本服从正态分布,即 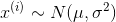 ,那么该如何求出参数 和
,那么该如何求出参数 和 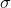 呢?这便是参数估计。我们有如下公式来估计 ,:
呢?这便是参数估计。我们有如下公式来估计 ,: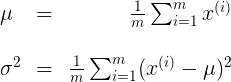
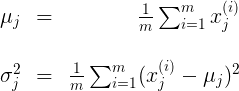 ,对于每一个样本x都有
,对于每一个样本x都有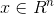 ,即每个样本都是一个n维向量,那么可以建立一个概率模型来估计每个样本的概率密度:
,即每个样本都是一个n维向量,那么可以建立一个概率模型来估计每个样本的概率密度: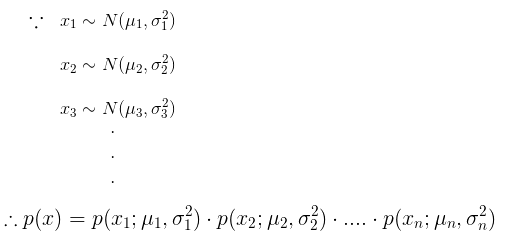

 值是怎么确定的?其实这个 是个经验值,NG给出的方法是选择在验证集上使评估指标(如F-measure)值最大的那个 。
值是怎么确定的?其实这个 是个经验值,NG给出的方法是选择在验证集上使评估指标(如F-measure)值最大的那个 。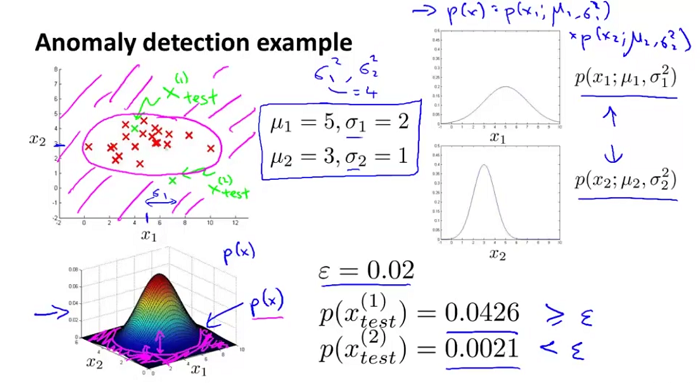
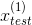 、
、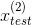 ,可以分别计算出它们的概率密度,分别为0.0426,0.0021,然后分别和给定的 值比较,能够得出为离群点。
,可以分别计算出它们的概率密度,分别为0.0426,0.0021,然后分别和给定的 值比较,能够得出为离群点。


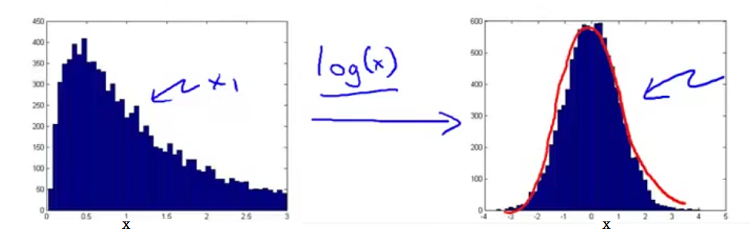

 能够更好的反应出网络的异常情况。
能够更好的反应出网络的异常情况。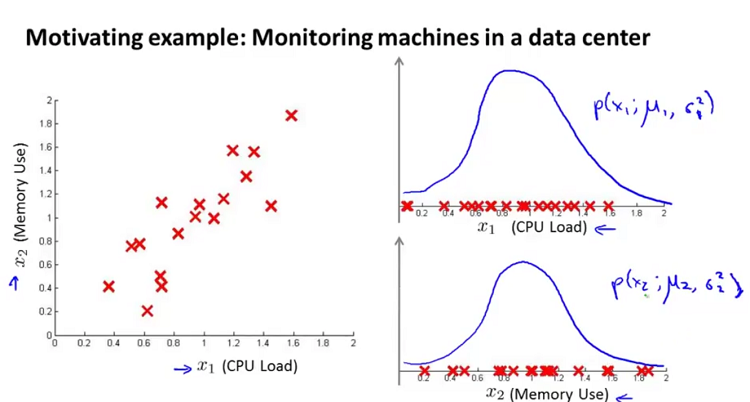
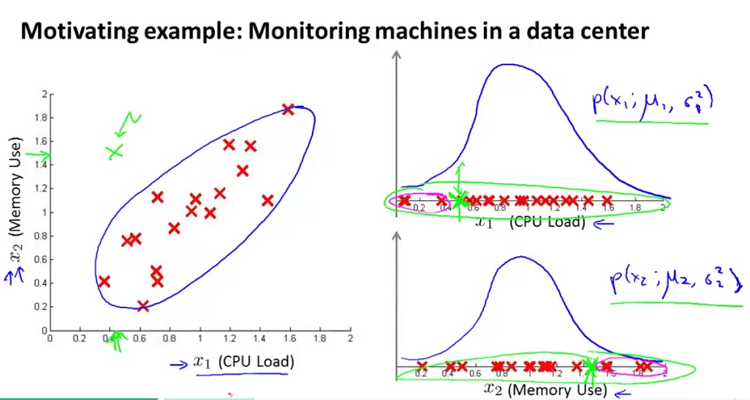
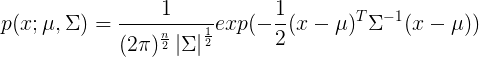
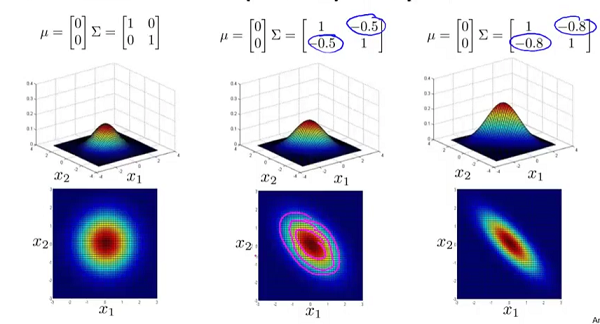
 为n*n维协方差矩阵,
为n*n维协方差矩阵, 为矩阵 的行列式。 和矩阵 对概率密度函数的影响。 的影响:
为矩阵 的行列式。 和矩阵 对概率密度函数的影响。 的影响: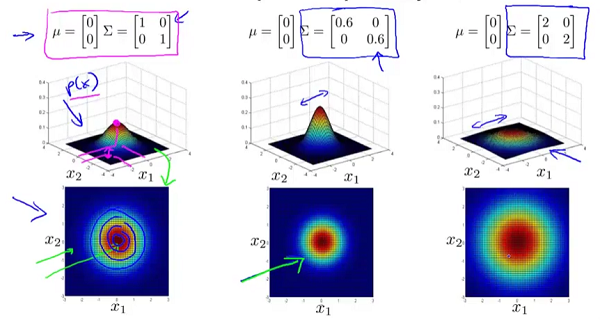
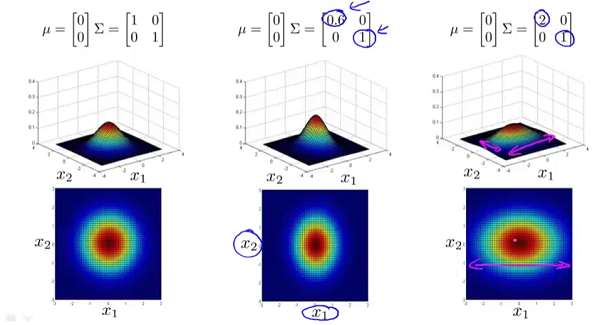
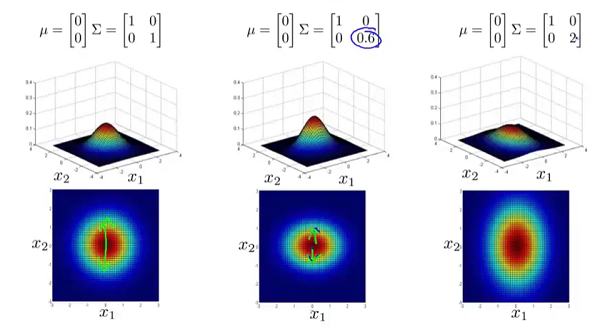 的副对角线都为0时,主对角线上的元素大小控制着概率密度函数俯瞰图的形状大小,至于具体到数字大小对应的形状,大家自己观察便知。
的副对角线都为0时,主对角线上的元素大小控制着概率密度函数俯瞰图的形状大小,至于具体到数字大小对应的形状,大家自己观察便知。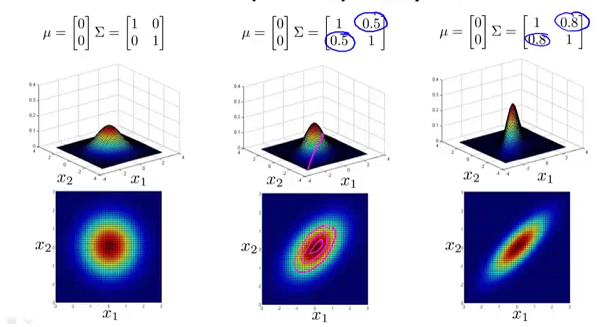
 对概率密度函数的影响:
对概率密度函数的影响: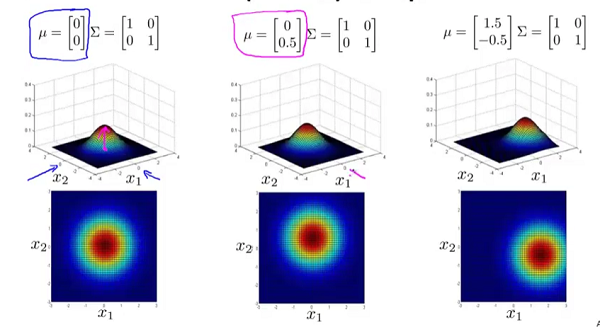 控制着图形的位置变化。
控制着图形的位置变化。
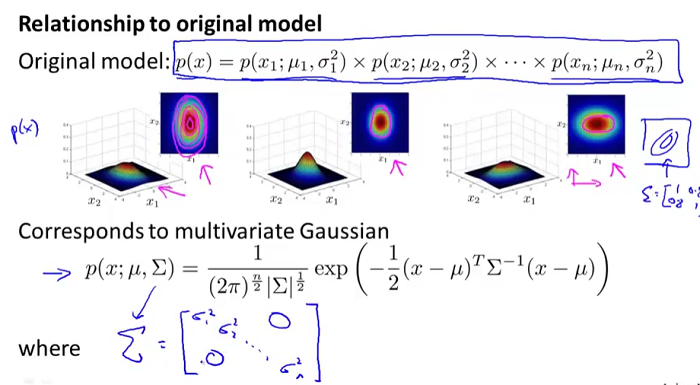 为对角矩阵,且对角线上的元素为各自一元高斯分布模型的方差时,二者是等价的。
为对角矩阵,且对角线上的元素为各自一元高斯分布模型的方差时,二者是等价的。
异常检测(anomaly detection)的更多相关文章
- 异常检测(Anomaly Detection)
十五.异常检测(Anomaly Detection) 15.1 问题的动机 参考文档: 15 - 1 - Problem Motivation (8 min).mkv 在接下来的一系列视频中,我将向大 ...
- [C10] 异常检测(Anomaly Detection)
异常检测(Anomaly Detection) 问题的动机 (Problem Motivation) 异常检测(Anomaly detection)问题是机器学习算法中的一个常见应用.这种算法的有趣之 ...
- 机器学习(十一)-------- 异常检测(Anomaly Detection)
异常检测(Anomaly Detection) 给定数据集
- 吴恩达机器学习笔记(九) —— 异常检测(Anomaly detection)
主要内容: 一.模型介绍 二.算法过程 三.算法性能评估及ε(threshold)的选择 四.Anomaly detection vs Supervised learning 五.Multivaria ...
- 基于高斯分布的异常检测(Anomaly Detection)算法
记得在做电商运营初期,每每为我们频道的促销活动锁取得的“超高”销售额感动,但后来随着工作的深入,我越来越觉得这里面水很深.商家运营.品类运营不断的通过刷单来获取其所需,或是商品搜索排名,或是某种kpi ...
- 异常检测(Anomaly detection): 什么是异常检测及其一些应用
异常检测的例子: 如飞机引擎的两个特征:产生热量与振动频率,我们有m个样本画在图中如上图的叉叉所示,这时来了一个新的样本(xtest),如果它落在上面,则表示它没有问题,如果它落在下面(如上图所示), ...
- Ng第十五课:异常检测(Anomaly Detection)
15.1 问题的动机 15.2 高斯分布 15.3 算法 15.4 开发和评价一个异常检测系统 15.5 异常检测与监督学习对比 15.6 选择特征 15.7 多元高斯分布(可选) 15 ...
- 异常检测(Anomaly detection): 异常检测算法(应用高斯分布)
估计P(x)的分布--密度估计 我们有m个样本,每个样本有n个特征值,每个特征都分别服从不同的高斯分布,上图中的公式是在假设每个特征都独立的情况下,实际无论每个特征是否独立,这个公式的效果都不错.连乘 ...
- 异常检测(Anomaly detection): 高斯分布(正态分布)
高斯分布 高斯分布也称为正态分布,μ为平均值,它描述了正态分布概率曲线的中心点.σ为标准差,σ2为方差,σ描述了曲线的宽度.在中心点附近概率密度大,远离中心点概率密度小. 高斯分布图 概率曲线下方的面 ...
- Coursera在线学习---第九节(1).异常数据检测(Anomaly Detection)
一.如何构建Anomaly Detection模型? 二.如何评估Anomaly Detection系统? 1)将样本分为6:2:2比例 2)利用交叉验证集计算出F1值,可以用F1值选取概率阈值ξ,选 ...
随机推荐
- 读书笔记(06) - 语法基础 - JavaScript高级程序设计
写在开头 本篇是小红书笔记的第六篇,也许你会奇怪第六篇笔记才写语法基础,笔者是不是穿越了. 答案当然是没有,笔者在此分享自己的阅读心得,不少人翻书都是从头开始,结果永远就只在前几章. 对此,笔者换了随 ...
- JAR(Spring Boot)应用的后台运行配置
酱油一篇,整理一下关于Spring Boot后台运行的一些配置方式.在介绍后台运行配置之前,我们先回顾一下Spring Boot应用的几种运行方式: 运行Spring Boot的应用主类 使用Mave ...
- 从零开始学 Web 之 jQuery(四)元素的创建添加与删除,自定义属性
大家好,这里是「 从零开始学 Web 系列教程 」,并在下列地址同步更新...... github:https://github.com/Daotin/Web 微信公众号:Web前端之巅 博客园:ht ...
- springboot json返回null问题处理
在开发过程中,我们需要统一返回前端json格式的数据,但有些接口的返回值存在 null或者""这种没有意义的字段.以上不仅影响理解,还浪费带宽,这时我们可以统一做一下处理:不返回空 ...
- Kafka命令清单
一.队列常用命令 #创建topics $ ./kafka-topics.sh --create --zookeeper chenx02:2181 --replication-factor 1 --pa ...
- [Luogu1365] WJMZBMR打osu! / Easy
Description 某一天WJMZBMR在打osu~~~但是他太弱逼了,有些地方完全靠运气:( 我们来简化一下这个游戏的规则 有 \(n\) 次点击要做,成功了就是o,失败了就是x,分数是按com ...
- Spring JDBCTemplate连接SQL Server之初体验
前言 在没有任何框架的帮助下我们操作数据库都是用jdbc,耗时耗力,那么有了Spring,我们则不用重复造轮子了,先来试试Spring JDBC增删改查,其中关键就是构造JdbcTemplate类. ...
- Python 的几种推导式
推导式 comprehensions(又称解析式):是 Python 中很强大的.很受欢迎的特性,具有语言简洁,速度快等优点.推导式包括: 1. 列表推导式 2. 字典推导式 3. 集合推导式 对以上 ...
- Shell 数组定义与获取
Shell 数组 bash支持一维数组(不支持多维数组),并且没有限定数组的大小. 类似与 C 语言,数组元素的下标由 0 开始编号.获取数组中的元素要利用下标,下标可以是整数或算术表达式,其值应大于 ...
- webpack4 系列教程(十): 图片处理汇总
多图预警!!! 此篇博文共 5 张图(托管在 GitHub),国内用户请移步>>>原文. 或者来我的小站哦 0. 课程源码和资料 本次课程的代码目录(如下图所示): >> ...